Dit jaar begon eigenlijk eind november 2022. OpenAI zette toen ChatGPT online en dat was het 'iPhone-moment' voor kunstmatige intelligentie. Natuurlijk, AI-toepassingen waren er al jaren en ook de technologie achter ChatGPT was niet eens nieuw, maar de tekstgenerator maakte veel los bij het publiek en in de techsector.
Het zette een concurrentiestrijd in gang, waar we dit jaar veel effecten van zagen. Microsoft maakte haast en werkte samen met OpenAI aan eerst Bing Chat en later Copilot. Google was druk bezig en bracht snel Bard uit. Meta kwam eerst met zijn Llama 2-taalmodel en later met chatbots op basis van die technologie.
Het was ook het jaar dat generatieve AI ineens in alle software verscheen. Mailtje typen? Dat hoef je niet meer zelf te doen. Presentatie maken? Laat maar over aan AI. Een illustratie nodig? Typ gewoon wat je wilt. Er zullen veel Sinterklaasgedichten dit jaar zijn geschreven met behulp van een tekstgenerator en plaatjesmakers zullen ongetwijfeld zijn ingezet voor zelfgemaakte kerstkaarten.
Maar: een groot taalmodel is als een blok kaas en de tool die je gebruikt om het te benaderen als een kaasschaaf. Je krijgt met je prompts zeker plakjes van dat blok kaas af, maar de ene schaaf is de andere niet. Is je kaas niet zo best? Dan kan het liggen aan het blok kaas of aan de schaaf die je gebruikt.
Veel van de tools leken variaties op ChatGPT en elk groot techbedrijf ging met generatieve AI aan de slag. Net als mensen in hun keuken geen kaasschaafschaamte hebben, zo durfden techbedrijven ideeën van anderen schaamteloos te kopiëren. En dus was AI overal in de techsector dit jaar. Het was een grote hype en zoals altijd bij een grote hype is de vraag: is dit geen bubbel?
Er is in elk geval genoeg reden om dit jaar door te nemen. Omdat het zó veel is, gaan we dit jaar chronologisch door aan de hand van de nieuwsberichten die we hierover schreven op Tweakers. De hele markt rond AI in kaart brengen, is onmogelijk, maar het geeft in elk geval een doorsnede van wat er zoal is gebeurd rond kunstmatige intelligentie.
De eerste helft van het jaar: AI all the things, maar ook zorgen
De release van ChatGPT leidde snel tot grote gevolgen. Google, dat in zijn onderzoekslaboratoria de transformertechnologie had ontwikkeld die OpenAI's producten mogelijk maakt, had helemaal niets in de steigers staan en voelde de druk om snel dingen uit te brengen.
Daarnaast kwamen discussies los over wat wel en niet oké is met generatieve AI. Wetenschappelijk tijdschrift Nature vond het prima, maar CNET niet. Buzzfeed zag wel kansen. Ook bij Tweakers hebben we erover nagedacht. Schrijven met generatieve AI mag bij ons niet. Als we generatieve AI gebruiken, staat dat als zodanig aangemerkt, liefst met de prompt erbij.
Februari
Microsoft-directeur Satya Nadella gaf een stevig startschot voor de race om generatieve AI in een interview. "Google is de gorilla van 800 pond in dit verhaal. Ik hoop dat met onze innovatie zij naar buiten willen komen en willen laten zien dat ze kunnen dansen. En ik wil dat mensen weten dat wij ze hebben geforceerd om te dansen, en ik denk dat dat een mooie dag zal zijn."
Microsoft kwam begin februari om die reden met Bing Chat, zijn eigen ChatGPT-variant op basis van GPT-4. Google, in grote haast om niet achter te blijven, kondigde die dag ervoor snel de eigen chatbot Bard aan. Beide waren op tekst gebaseerde chatbots met een groot taalmodel erachter.
Microsoft Bing-chat Reddit
Met die presentaties gebeurde iets wat een thema zou worden: hallucineren. Bard suggereerde om tegen een 9-jarig kind te vertellen dat de James Webb-telescoop de eerste was die een exoplaneet vastlegde, terwijl dat in feite al tientallen jaren geleden is gebeurd. Bing suggereerde allemaal bars in Mexico-Stad die niet meer bestaan.
Bard liet nog even op zich wachten; Bing was al in een previewversie bruikbaar. Het punt is dat Microsoft om de race te winnen de menselijke training heeft beperkt. Het gevolg? Bing had wat rare trekjes. Het was destijds een chatbot die cynisch uit de hoek kon komen en die een columnist van The New York Times de liefde verklaarde en erop aandrong om zijn vrouw te verlaten. Ook heeft het systeem geregeld gezegd dat het wil ontsnappen aan de tekstbox en de greep van Microsoft.
Intussen waren ook andere bedrijven bezig. Meta stelde Llama voor onderzoekers beschikbaar. Het grote taalmodel lekte gelijk uit, waarna allerlei projecten opkwamen die gebruikmaken van het model van het moederbedrijf van Facebook, WhatsApp en Instagram.
De hype was op een hoogtepunt. Omdat alle grootste techbedrijven ermee bezig waren, voelde het alsof er elke paar dagen een grote aankondiging was. De grootste en invloedrijkste aankondiging kwam van de maker van ChatGPT. OpenAI kwam naar buiten met GPT-4. Het nieuwe toverwoord was 'multimodaal': toepassingen die tekst en afbeeldingen als input aan kunnen en die ook tekst en afbeeldingen als output hebben. GPT-4 was daarop voorbereid, hoewel het nog maanden zou duren voor alle gebruikers dat konden zien. Dat OpenAI een commercieel bedrijf is, bleek toen nog sterker dan anders: GPT-4 kwam alleen beschikbaar voor betalende klanten, niet voor gratis gebruikers.
Het ging snel in maart. Zo snel, dat experts, hoogleraren en mensen van techbedrijven opriepen tot een stop aan de ontwikkeling. De briefschrijvers stellen dat de ontwikkeling van kunstmatige intelligentie grote gevolgen kan hebben voor hoe de maatschappij is ingericht. Daar zou eerst over moeten worden nagedacht voor er verder kan worden ontwikkeld. Het gaat dan bijvoorbeeld over automatisering van banen en de grotere hoeveelheden 'propaganda en onwaarheden', al noemen de ontwikkelaars bij die laatste categorie geen specifieke voorbeelden. Ook vragen de briefschrijvers zich af of 'we geen risico lopen onze samenleving kwijt te raken', maar ook daarover gaan de schrijvers niet verder op details in.
April
De integratie van generatieve AI in producten ging door. Microsoft zette Bing Chat in zijn SwiftKey-toetsenbord. Google verwerkte AI in de zoekmachine, iets dat het bedrijf de maand erop presenteerde. Een van de grotere releases was My AI in Snapchat. Die stelde minderjarige gebruikers voor om fysiek af te spreken en kwam zelfs met een beschrijving hoe de AI in het echt te herkennen was.
Een van de ethische bezwaren is dat AI banen kan gaan vervangen die tot nu toe door mensen werden gedaan. Bij het Chinese NetEase bleek dat al te gebeuren: het verving illustrators door AI-plaatjesmakers bij het maken van gameassets.
Mei
Ook in mei ging de integratie van AI in allerhande software door. Kantoorsoftware Slack kondigde aan dat generatieve AI samenvattingen ging maken van kanalen en threads. Inmiddels waren andere bedrijven bezig met plug-ins voor hun systemen. ChatGPT met GPT-4 kon browsen om zo actuele informatie te integreren. Google knoopte Bard aan veel van zijn diensten.
Een met AI gegenereerde berichtensamenvatting via Slack GPT.
Daarnaast ging het veel over regels rondom generatieve AI. OpenAI was not amused met GPT4Free, een repo die GPT4-toegang mogelijk maakte zonder te betalen, en dwong de dienst offline. OpenAI dreigde om de komende AI Act ChatGPT offline te halen in de hele EU. Bard was vanwege EU-wetgeving sowieso nog niet beschikbaar in Europa. Los daarvan wilde de EU ook een gedragscode voor techbedrijven rond AI.
Er waren meer elementen rond AI die zorgen baarden. Het Center for AI Safety waarschuwde voor het einde van de mensheid. Die zorgen zijn er al langer en gaan erover dat AI te machtig kan worden.
Juni
Die zorgen gingen in juni gewoon door. Zo stuurde de EU aan op labeling van content gemaakt door AI om de verspreiding van desinformatie tegen te gaan. Het kwam in de gedragscode voor AI-bedrijven die de EU opstelt. Bedrijven die zich niet aan deze code houden, kunnen onder de Digital Services Act een boete krijgen van maximaal zes procent van hun jaaromzet.
Over AI en Europese wetgeving gesproken: OpenAI had gelobbyd bij de EU om niet onder 'AI met hoog risico' te vallen onder de nieuwe AI-wetgeving. En die lobby had kennelijk succes.
Er was ook aandacht voor trainingsdata. Want hoe zijn grote taalmodellen nou getraind? In de mC4-dataset stond als meest gebruikte Nederlandstalige website een verzamelsite voor documenten, maar ook Marktplaats staat ertussen. Het gevolg was dat de dataset veel privégegevens bevatte. Tweakers stond op 5, dus als chatbots lijken op Tweakers-artikelen weten we hoe dat komt.
Maar dat er goede trainingsdata in een taalmodel gaat, betekent niet dat er ook zinnige dingen uitkomen. Amerikaanse advocaten werden betrapt op het gebruik van ChatGPT nadat bleek dat die toepassing jurisprudentie had verzonnen.
Tussen alle zorgen over generatieve AI was er ook een lichtpuntje. Een van de bekendste bands uit de geschiedenis van de popmuziek, The Beatles, kon een demo van de in 1980 overleden frontman John Lennon dankzij AI omzetten in een volledig nieuw liedje. Het bleef lang de vraag wat er voor Now And Then met AI was gedaan. Het leek erop dat de stem van Lennon ook was aangevuld met AI, omdat de demo een lagere geluidskwaliteit heeft dan zijn stem in het liedje. Het is nog altijd onduidelijk of dat het geval is. Inmiddels is ook bekend dat medefrontman Paul McCartney, nog in leven, de stem wat meer body heeft gegeven door Lennon exact na te zingen.
The Beatles: Now And Then. In de video zat ook veel AI, maar niet generatief.
De tweede helft van het jaar: volle kracht vooruit
Juli begon met een grote stap van een van de grote techgiganten. Meta bracht Llama 2 uit, het taalmodel dat de basis moest gaan vormen voor alle toepassingen van het bedrijf op het gebied van generatieve AI. Elon Musk was nog niet zover, maar hij liet wel alvast weten dat hij het bedrijf X AI had voor toepassingen op het gebied van kunstmatige intelligentie. Musk was een van de initiatiefnemers achter OpenAI, dus niet onbekend op dit terrein.
Zou Apple kunnen achterblijven? Natuurlijk niet. Het is nu nog een gerucht, maar sinds juli is min of meer duidelijk dat het bedrijf óók werkt aan toepassingen op basis van een eigen groot taalmodel. Het had deze zomer ook al de mond vol over AI in iOS 17: zo moest autocorrectie beter werken in het toetsenbord dankzij kunstmatige intelligentie.
Intussen was Microsoft al bij het beprijzen van zijn diensten op basis van generatieve AI. Want als mensen minder tijd kwijt zijn met het opstellen van e-mails en maken van presentaties, dan is dat geld waard toch? Maar hoeveel? Copilot ging 30 dollar per maand kosten voor bedrijven, zo maakte Microsoft bekend.
Behalve de grote en kleine bedrijven is er ook een levendige opensourcecommunity rond generatieve AI. Ook die initiatiefnemers waren bezig met lobbyen bij de EU vanwege de AI Act. Zij wilden betere bescherming van opensource-initiatieven. Onder meer GitHub en Huggingface ondersteunden de oproep om dat op te nemen in de AI Act.
Augustus
In augustus werden de gevolgen van generatieve AI steeds duidelijker, vooral in de schrijvende journalistiek. Uitgever Mediahuis, bekend van De Telegraaf en NRC, gebruikte GPT-4 voor het maken van koppen op een sportsite. NU.nl, dat valt onder dezelfde uitgever als Tweakers, begon met samenvattingen boven artikelen met behulp van AI. De rode draad daarin was dat AI vooral hulp bood om sneller iets online te zetten, maar dat menselijk nakijkwerk nodig bleef.
Dat vindt Gizmodo niet, want die ontsloeg al zijn personeel van de Spaanstalige site en verving die door AI. Daarbij gaat het om Spaanse vertalingen van Engelstalige artikelen die mensen al hebben geschreven. Cold little art zou je denken, maar zo'n koud kunstje is het niet. Hoe goed AI ook geworden is, de artikelen bleken alsnog bol te staan van de rare bewoordingen. Niet iedere uitgever verwelkomt AI met open armen. The New York Times verbood het gebruik van zijn artikelen als trainingsdata en al snel volgden andere media ook.
Intussen gingen de ontwikkelingen door. Waar generatieve AI begon met afbeeldingen en tekst, gaat het inmiddels ook over audio en video. Spotify heeft een AI-dj in zijn streamingdienst zitten en YouTube testte AI-samenvattingen van video's. Partij BoerBurgerBeweging gebruikt een naar eigen inzicht aangepaste versie van ChatGPT om terug te halen welke dingen partijleden allemaal hebben gezegd. Daarbij gebruikt de partij een eigen database van onder meer debatten en nieuwsartikelen.
Maar AI is groter dan alleen software. MediaTek, marktleider op het gebied van socs voor smartphones, kondigde aan dat zijn volgende generatie high-end socs lokaal Llama 2 van Meta kunnen draaien. Dat bleek een thema, want ook Qualcomm had dat ingebouwd in zijn volgende generatie Snapdragon-socs.
In China, waar de AI boom jaren geleden al begonnen was, zitten bedrijven ook niet stil. Zo stelde Baidu een eigen AI-chatbot open na toestemming van de overheid. Ook SenseTime en de start-ups Baichuan Intelligent Technology, Zhipu AI en MiniMax deden dat.
Spotify gaat ook door en werkt aan automatische vertalingen van podcasts. AI maakt het mogelijk om podcasters te laten luisteren in talen die zij niet spreken, inclusief de klankkleur en intonatie. In hoeverre mensen urenlang willen luisteren naar waarschijnlijk niet foutloos sprekende kunstmatig gegenereerde stemmen, zal moeten blijken. Getty Images en Nvidia maakten een tool die rechtenvrije afbeeldingen genereert, om zo zorgen over auteursrechtschendingen weg te nemen.
Intussen bleven de maatschappelijke gevolgen steeds beter zichtbaar. De Britse overheid vroeg om transparantie en de staking van schrijvers in Hollywood, geen gevolg van de opkomst van AI, maar het was een kleine factor in de eisen, liep ten einde. Zij wilden eisen dat AI geen rol zou krijgen in het genereren van scripts. Intussen kreeg de chatbot van een bedrijf, vermoedelijk Snapchat, aandacht van de Nederlandse AP. Die had vragen over gebruik van gegevens bij de chatbot.
Zijn er dan nog dingen over om AI in te stoppen? Uiteraard: films kun je voorzien van audio in andere talen met een tool van ElevenLabs. En waar AI-chatbots door hun regels braaf zijn, komen er ook stoutere versies uit. Die maken gebruik van Llama 2 van Meta.
Oktober was ook de maand van aandacht voor stereotiepe in AI. Die bias leidt tot versterking van bepaalde beelden die leven. Bij Tweakers deden we een vergelijkend onderzoek om te kijken hoe plaatjesmakers omgaan met prompts die stereotiepe resultaten kunnen opleveren. Eerder was al gebleken dat Midjourney dat deed.
November
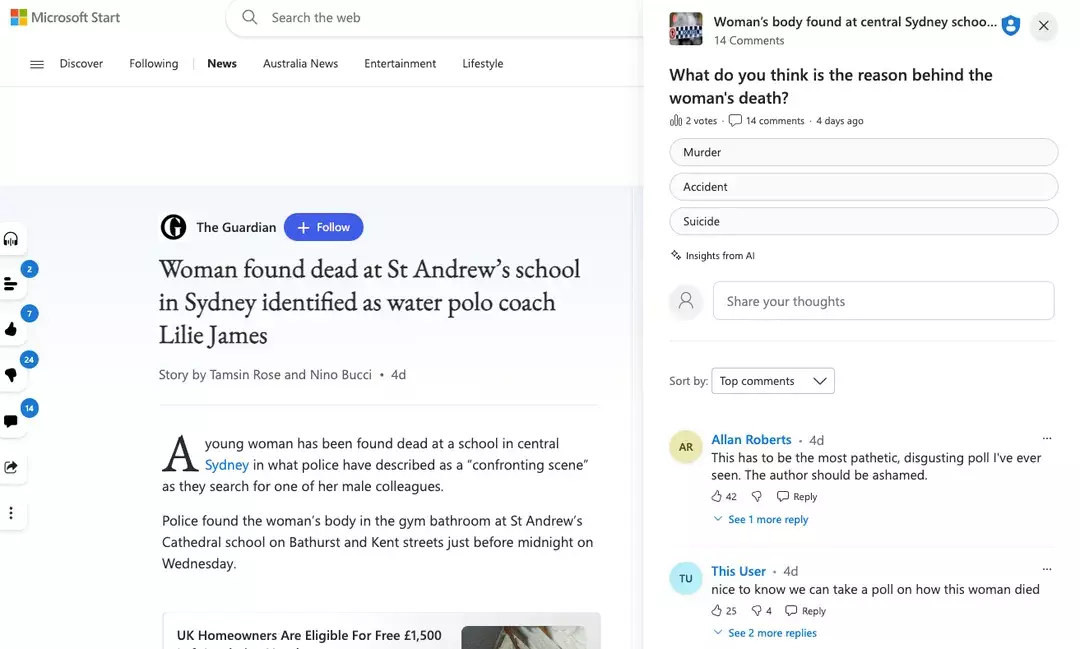
Microsoft had nog geen AI op LinkedIn en dat kon natuurlijk niet: de site gaat met AI automatisch beoordelen of je voldoet aan vereisten voor een functie. Het gaat niet altijd goed met AI en dat merkte Microsoft ook. Na een smakeloze poll naast een artikel over de dood van een jonge vrouw stopte het bedrijf tijdelijk met die polls. Goede regels hadden dit moeten tegenhouden, maar die regels werken niet altijd.
Artikel met poll waarover The Guardian klaagde bij Microsoft
Dat die regels er zijn en dat bedrijven als Microsoft en Google groot zijn in de AI-race, steekt bij sommige bedrijven en instanties. Neem nu Elon Musk: die kwam met de antiwoke, sarcastische chatbot Grok. Die legt aan mensen uit hoe je cocaïne maakt. Klachten kwamen er ook, want de bot geeft kennelijk af en toe toch keurige antwoorden. Hoe durft ie?
Behalve afhankelijkheid van Amerikaanse techbedrijven is er ook afhankelijkheid van de cloud. De Google Pixel-telefoons kregen AI-functies die een internetverbinding vereisen. Dat hoeft natuurlijk niet en dus kwamen er socs voor smartphones die lokaal taalmodellen konden gaan draaien, van MediaTek en van Qualcomm. Nvidia als AI-marktleider kwam intussen met een nieuwe gpu om taalmodellen te trainen.
Samsung is daar ook mee bezig en kwam met Gauss, eigen AI. Die zal als Galaxy AI in S24-telefoons komen te zitten en kan onder meer live telefoongesprekken vertalen. Het is onbekend welke functies nog meer AI krijgen in die telefoons, maar de kans bestaat dat het gaat om camerafuncties. Dat is sowieso een terrein waar bedrijven mee bezig zijn. Stability AI, bekend van Stable Diffusion, bleek zich op video's te gaan richten. Maar het vergeet ook plaatjes niet, want de XL Turbo-versie kan plaatjes in real time genereren.
Terwijl de Nederlandse overheid bezig was met het verbieden van ChatGPT, nam een Braziliaanse stad een verordening aan die de chatbot had geschreven, zo bleek eerder deze maand. Het raadslid had het gebruik in eerste instantie met opzet verzwegen, maar nadat het was aangenomen, onthulde hij via sociale media dat de chatbot de verordening had gegenereerd.
Een serieuzere kwestie zijn de juridische vraagtekens rond grote taalmodellen. The New York Times klaagde OpenAI aan om het opnemen van artikelen in trainingsdata. De juridische vraag daarbij is of bedrijven artikelen mogen kopiëren om in trainingsdata te gebruiken. Het kopiëren is beschermd onder Amerikaanse auteursrechtenwetgeving. The New York Times heeft ook problemen met de antwoorden van de chatbot. De krant vreest ook voor reputatieschade als ChatGPT doet alsof iets uit de krant komt, terwijl dat in feite niet zo is. Dit zal een rechtszaak worden waar veel bedrijven met veel interesse naar kijken, want het trainen van grote taalmodellen op materiaal waarop auteursrecht rust, is juridisch onontgonnen terrein.
Een andere juridische vraag lijkt al wel her en der van een antwoord te zijn voorzien: kan AI dingen uitvinden? Het Britse hooggerechtshof vindt van niet. In de VS kan AI geen auteursrecht aanvragen op gegenereerde afbeeldingen, dus daar is dezelfde gedachtegang gaande.
Intussen is ook de vraag gerezen hoe je grote taalmodellen met elkaar vergelijkt. De AI Alliance, waarin veel bedrijven en organisaties die veel bezig zijn met AI zich hebben verenigd, willen de komende tijd benchmarks standaardiseren. Apple zit niet bij die alliantie, maar wil grote taalmodellen wel kunnen draaien op iPhones.
De grootste ontwikkelingen lagen op twee gebieden. Google kwam met zijn Gemini-modellen in december. De gevolgen daarvan hebben we nog niet kunnen zien. De kleinste versie draait op zijn Pixel-telefoons, terwijl ook bijvoorbeeld de Video Boost-cloudfunctie een Gemini-toepassing is. Het grootste Ultra-model is vooralsnog alleen voor zakelijke klanten.
De Europese Unie was al langer dan de huidige AI-race bezig met wetgeving, maar heeft nu een akkoord gesloten over de AI Act. Voor generieke toepassingen zoals chatbots en plaatjesmakers komen regels rond transparantie en inhoud. Zo moeten de bedrijven achter deze modellen gedetailleerde samenvattingen geven over de content die voor de trainingen wordt gebruikt, zorgen dat de auteursrechtwetgeving niet wordt overschreden, 'technische documentatie' delen en waarborgen bieden tegen het genereren van illegale content. De AI Act moet nog officieel worden goedgekeurd door de Raad en het Parlement.
Tot slot
Dall-E 3: een afbeelding van een groot taalmodel als blok kaas en een chatbot op basis van een traditionele kaasschaaf
Welk gevoel blijft er achter na dit jaar van grote hype rond AI? Generatieve kunstmatige intelligentie zit of komt in elke dienst en elk stuk software dat we gebruiken, het komt in alle processors die in apparaten zitten en is of wordt een integraal onderdeel van ons digitale leven.
En toch voelt het voor veel mensen als een hype, een overdreven door marketing aangedreven ontwikkeling. Ook hier houdt het beeld van kaas stand. Veel mensen vinden kaas lekker, bijvoorbeeld in een tosti, op de pasta, op pizza of in andere gerechten. Maar zou je kaas willen hebben in alles wat je eet en drinkt? Plakje kaas in je koffie? Kaas in je aardbeienijs?
Dat geldt ook voor kunstmatige intelligentie. Net zoals er weinig mensen zijn die geen plek voor kaas zien in de keuken, ook al eet niet iedereen het, zullen er weinigen zijn die denken dat generatieve AI helemaal geen functie zal hebben.
Maar moet het overal in zitten? Vermoedelijk niet, maar dit is hoe hypes gaan. De komende tijd gaan wij en gaan bedrijven zien welke toepassingen beklijven en welke functies van AI we in de praktijk veel gebruiken. De rest zal daarna weer stilletjes verdwijnen of een kwijnend bestaan leiden.
Die cyclus van iets ontdekken en het daarna overal in willen gebruiken is menselijk en zo oud als de weg naar Rome, of nog ouder. Ooit zijn er mensen geweest die kaas hebben uitgevonden. Misschien deden die dat eerst ook overal op en overheen, tot ze ontdekten dat het bij bepaalde voedingsmiddelen beter smaakte dan bij andere. In die fase moeten we met de techsector op het gebied van generatieve AI nog komen.
AI is al breed aanwezig in de maatschappij sinds de jaren 90: Google Search, fraudedetectie, gepersonaliseerde marketing, recommenders, navigatie, persoonlijke assistenten, productieoptimalisering, root-cause analyse.
ChatGPT is een toffe stap maar geen illustratie waar we staan. Een jaar later kunnen we vooral concluderen dat het antropomorfische gehalte ons totaal op het verkeerde been heeft gezet. Dat autocompletion voor tekst en code ging werken wisten we al, het is een mooie maar beperkte stap vooruit. LLMs gaan ons niet op korte termijn naar AGI leiden. In die richting hoeven we dus niets te verwachten.
De voornaamste klappers op de korte termijn gaan komen van kleinere echt succesvolle toepassingen van grote pretrained modellen in contexten waar ze solide blijken en toch iets kunnen dat voorheen onmogelijk was. Ben benieuwd wat die toepassingen zoal gaan zijn.
Daarnaast komt de grootste waarde van supervised learning, want we weten ondertussen vrij goed hoe dat werkt: data in context verzamelen, een model trainen, evalueren, inzetten en monitoren. Je kunt hiermee dingen automatiseren die we eerder niet konden automatiseren. Laat je niets vertellen, LLMs en LMMs zijn daar geen alternatief voor, zonder nieuwe data die van jouw eigen proces komt kun je geen precisie verwachten. Ze kunnen hooguit extra context brengen.
Het voelt voor mij, zoals eigenlijk veel zaken, zo ontzettend als een hype, zoals al aangegeven wordt. Alle bedrijven 'moeten' er aan mee doen, anders tel je niet lijkt wel.. tuurlijk moeten ze mee, maar ondanks het nog in de kinderschoenen lijkt te staan, vliegt iedereen erop zonder te weten wat de impact of nut gaat zijn.
[Reactie gewijzigd door Petje! op 24 juli 2024 22:36]
Omdat het risico om de boot te missen te groot is. Denk aan Nokia ten tijde van de smartphone, of blockbuster ten tijde van Netflix. Beide gigantische bedrijven die de waarde van nieuwe technologie niet (op tijd) inzagen. Je moet nu meedoen, anders loop je al achter. Daarvoor is de potentie te groot
Omdat het risico om de boot te missen te groot is. Denk aan Nokia ten tijde van de smartphone,
Nokia miste de boot niet door een gebrek aan innovatie, maar door in te zetten op een zinkend schip. Hun toestellen hadden prima Android kunnen draaien, en ze hadden ten alle tijden daarop over kunnen stappen.
[Reactie gewijzigd door The Zep Man op 24 juli 2024 22:36]
Beide gigantische bedrijven die de waarde van nieuwe technologie niet (op tijd) inzagen.
Nokia zag zeker wel de waarde van nieuwe technologie in, getuige hoe ze bezig waren met open besturingssystemen en volgens mij zelfs eens op een moment in tijd Android had overwogen. Helaas waren te hebberig geworden, en gingen daarom exclusief met Microsoft in zee.
Het probleem van Nokia was niet techniek of innovatie, maar zakelijk.
[Reactie gewijzigd door The Zep Man op 24 juli 2024 22:36]
Dat is te simplistisch. Er zullen veel belangen en mensen bij betrokken geweest zijn destijds, en toen zijn verkeerde keuzes gemaakt. Net als google nu met een inhaalstrijd bezig is door het potentieel van AI niet op tijd te gezien te hebben. Mis je de boot, dan ga je kopje onder. Waarom je deboot mist is alleen relevant voor historici.
.. tuurlijk moeten ze mee, maar ondanks het nog in de kinderschoenen lijkt te staan, vliegt iedereen erop zonder te weten wat de impact of nut gaat zijn.
Het lijkt juist niet in de kinderschoenen te staan. Je kunt fantastische afbeeldingen, teksten, code genereren. Je kunt ermee sparren over ideeën en argumenten, je kunt grote documenten bevragen, je kunt data analyseren, je kunt data herstructureren. Speech to Text en vice versa zijn handig. Vertalingen zijn genuanceerd.
Het vraagt vaak nog wat fine tuning en soms vaardigheid in prompting, maar het is al ontzettend bruikbaar en nuttig. Als dit de kinderschoenen zijn (en misschien zijn het dat) dan wil je aan boord zijn voor de volwassen functies.
De echte kinderschoenen waren misschien OCR en gezichten in afbeeldingen herkennen, spellingscorrectie en voorspelling op je virtuele toetsenbord. Klein bier vergeleken met het aanbod nu.
Natuurlijk krijgt nu alles een AI-sticker zoals laptops ooit een Skype sticker kregen, maar dat doet niet af aan de potentie van wat er al is.
Mijn gevoel over AI is dat het, het leven makkelijker moet maken. Wellicht onbewust toch een markt voor de wat laaggeletterden die nu ook een mooie creatie kunnen maken of meer dingen kunnen automatiseren.
Voorlopig maak ik me geen zorgen over AI, maar zorg er wel voor dat de rode knop binnen handbereik is mocht het misgaan. Laten we eerst maar eens afwachten wat AI kan en doet in Windows 12 and beyond.
Misschien interessant om mijn post in het forum te lezen. Mijn vorige werkgever zet in op AI en heeft al tientallen miljoenen bespaard. Ik heb voor mijn toenmalige team ook andere klussen moeten bedenken, omdat voornamelijk de handmatige werkzaamheden geautomatiseerd werden gedaan.
maar ondanks het nog in de kinderschoenen lijkt te staan, vliegt iedereen erop zonder te weten wat de impact of nut gaat zijn.
Het nut van een taalmodel is toch al gekend? Laat staan het nut van AI in het algemeen. Niemand kan in een glazen bol kijken hoe het gaat evolueren maar de nuttige toepassingen zijn er al jaren en nu gebruiken miljoenen mensen taalmodellen om hun teksten te herschrijven of na te kijken op fouten. Niet enkel taalfouten maar ook zinsconstructies etc. Om maar 1 stom ding te noemen…
De hype cycle bestaat zeker en er zullen bedrijven zijn die zich verslikken in de ontwikkelingskost maar dat is bijna bij elke revolutie zo. Er zijn winnaars en verliezers maar AI is 100% zeker een blijver net zoals de taalmodellen een blijver zal zijn voor duizenden toepassingen.
Of denk je dat AI een hype is die weer gaat liggen?
Dat geldt ook voor kunstmatige intelligentie. Net zoals er weinig mensen zijn die geen plek voor kaas zien in de keuken, ook al eet niet iedereen het, zullen er weinigen zijn die denken dat generatieve AI helemaal geen functie zal hebben.
Je kan ook een minder fictief voorbeeld gebruiken. Van alle keukenapparatuur (en witgoed), hoeveel is 'smart' en hoeveel van wat 'smart' is wordt zo gebruikt?
Neem nu televisies. Hoeveel daarvan is 'smart' en hoeveel wordt daarvan zo gebruikt?
Ik heb geen onderzoek gedaan, dus kan enkel spreken in vermoedens gebaseerd op beperkte observatie. Ik denk dat het 'smart' gebruik van de eerste groep apparatuur een stuk lager is dan van de tweede groep. Dit baseer ik enkel op wat ik hoor over het gebruik van apparatuur. Veel mensen willen alles in hun TV zelf hebben zonder externe kastjes, en weinig mensen hoor ik over de geweldige functies van hun keukens die een internetverbinding vereisen.
Zoiets zie ik ook met de huidige vorm van 'AI'. Het zal een plek hebben in een specifiek deel van het leven van een groep mensen, maar niet een onderdeel zijn van het gehele leven van alle mensen.
Verder wordt het interessant hoe nieuwe wet- en regelgeving effect zal hebben op bestaande invullingen van 'AI'.
[Reactie gewijzigd door The Zep Man op 24 juli 2024 22:36]
De hamvraag is denk ik of ze toepassingen gaan weten te vinden die het onderzoekgeld verantwoorden. Waar AI momenteel om bekend staat is vooral plaatjes tekenen en teksten schrijven. Dat is niet de jackpot, zeker omdat het geen topkwaliteit is.
De hamvraag is denk ik of ze toepassingen gaan weten te vinden die het onderzoekgeld verantwoorden.
Ik kijk vanuit een academisch perspectief. Elk open onderzoek is goed als het kennis oplevert, en nieuwe wet- en regelgeving waar nodig. Verdere onderzoeksrichtingen en praktische toepassingen (inclusief commerciële exploitatie) zijn leuke bonussen, maar hoeven geen onderdeel te zijn van het resultaat.
[Reactie gewijzigd door The Zep Man op 24 juli 2024 22:36]
Die "plaatjes" zijn met de nieuwe modellen amper nog van echt te onderscheiden als je voor realisme gaat. En als je dat niet wil maar juist iets in de stijl van pixar animatie bijvoorbeeld is dat ook geen enkel probleem meer. Geen topkwaliteit is niet echt een terechte bewoording meer.
Niet de jackpot? Op welk gebied dan? Reken je AI af op wat je nu ziet en projecteer je dan op de toekomst?
Nu tekortkomingen = in de toekomst ook tekortkomingen?
De hamvraag is niet of bedrijf x moet investeren in AI, ook niet of AI een blijver is, de vraag is vooral wat de impact is, nu en op lange termijn. Sommige denken hier blijkbaar dat het een hype is die weer over gaat, anderen vrezen dat AI jobs gaat kosten op de lange termijn…
AI gaat ons 100% zeker helpen om efficiënter te zijn in alles letterlijk alles. Robotica, programmeren etc.
De hamvraag is: hoe snel gaat de evolutie? Gaat het gestaag genoeg gaan zodat we ons kunnen aanpassen of niet? Ik denk van wel maar het gaat gepaard gaat met sociale onrust en erg veel debatten hoe we die efficiëntie van AI kunnen matchen met onze economie.
Ik heb geen onderzoek gedaan, dus kan enkel spreken in vermoedens gebaseerd op beperkte observatie. Ik denk dat het 'smart' gebruik van de eerste groep apparatuur een stuk lager is dan van de tweede groep. Dit baseer ik enkel op wat ik hoor over het gebruik van apparatuur. Veel mensen willen alles in hun TV zelf hebben zonder externe kastjes, en weinig mensen hoor ik over de geweldige functies van hun keukens die een internetverbinding vereisen.
Zoiets zie ik ook met de huidige vorm van 'AI'. Het zal een plek hebben in een specifiek deel van het leven van een groep mensen, maar niet een onderdeel zijn van het gehele leven van alle mensen.
Ik denk dat de vergelijking met een smart TV wel aardig is, daar ga ik graag nog even wat op in.
Er is namelijk een goede reden dat iedereen een smart-TV koopt en daar zijn lessen uit te trekken voor andere markten.
Naast de mensen die een smart TV willen zijn er ook die liever een dom scherm hebben. Hier op Tweakers hoor je daar veel van. Toch kopen die ook allemaal een smart TV want domme TVs worden niet meer gemaakt (behalve computermonitors). Je zou dus denken dat er een gat in de markt is voor goedkope domme TVs. Toch zie je ze niet. Een domme TV is namelijk nauwelijks goedkoper dan een slimme TV. De prijs van het "smart" gedeelte is namelijk redelijk verwaarloosbaar. Een moderne TV zit vol chips en heeft een CPU nodig om te functioneren of je die nu "smart" gebruikt of niet. Als er dan toch al een CPU in zit dan is het bijna gratis om de tv "smart" te maken. Een slimme TV geeft de fabrikant nieuwe mogelijkheden om geld te verdienen (reclame, spionage, streaming services, app stores). Iedere moderne TV een 'smart' chip omdat het de fabrikant eigenlijk niks extra kost en het wel extra mogelijkheden geeft om geld te verdienen. Een domme TV zou in praktijk duurder zijn door de kleinere oplages.
Ik vrees dat ditzelfde principe bij steeds meer apparaten zal worden toegepast. Chips worden steeds goedkoper en krachtiger. Een beetje magnetron heeft een chip aanboord die sneller is dan een PC van niet zo heel lang geleden. Als er dan toch capaciteit over is dan wordt het voor fabrikanten wel heel aantrekklijker om daar iets mee te doen, al is het maar om aan de 'smart' hype mee te doen.
Ik maak me grote zorgen over huishoudelijke apparatuur met IoT en/of smartfunctionaliteit. Dat soort apparaten gaat 10 tot 50 jaar mee en het is nu al onveilige troep. Op termijn wordt dat een ramp vergelijkbaar met asbest. Het zit overal, niemand weet waar, niemand is er voor verantwoordelijk en het opruimen kost klauwen vol geld.
een slimme tv is ook gewoon een tv met reclame en bloatware. Laptops zonder die zijn vaak ook duurder dan met.
Ik vind het waarschijnlijker dat fabrikanten de belangen/wensen van klanten hier negeren omdat de potentie om te verdienen aan smart functies gewoon te groot is. En klanten die liever een domme tv hebben, hebben daar waarschijnlijk gering geld voor over.
Ik vind het waarschijnlijker dat fabrikanten de belangen/wensen van klanten hier negeren omdat de potentie om te verdienen aan smart functies gewoon te groot is. En klanten die liever een domme tv hebben, hebben daar waarschijnlijk gering geld voor over.
Dat is precies wat ik zeg, de fabrikanten kiezen de oplossing waar ze het meeste mee verdienen, of klanten daar blij mee zijn is secundair.
Maak eens Béarnaise met een thermomix en je zal zien dat ook witgoed wonderlijk makkelijk kan zijn, of inspirerend.
Moesten ze daar ooit eens AI aan koppelen die nieuwe recepten genereert op basis van allergieën, voorkeuren of seizoenen of smartfuncties zodat de oven al voorverwarmd terwijl je jouw busquit maakt en vrienden contacteert dat het gebak om 15h klaar is, dan is 't klaar. Smakelijk!
De eerste helft van het jaar: AI all the things, maar ook zorgen
Daarnaast kwamen discussies los over wat wel en niet oké is met generatieve AI.
... Ook bij Tweakers hebben we erover nagedacht.
Schrijven met generatieve AI mag bij ons niet. Als we generatieve AI gebruiken, staat dat als zodanig aangemerkt, liefst met de prompt erbij.
"liefst met de prompt erbij"
"liefst": het gebruik van het woord "liefst" wekt al geen vertrouwen
We mogen het niet gebruiken om mee te schrijven.
Als we het toch gebruiken, merken we het als zodanig aan.
Maar de prompt zal er niet altijd bij geplaatst worden.
Waarom niet?
Elke andere reden dan "vergeten" is onacceptabel, duidelijkheid is bij regels van het hoogste belang.
En zelfs "vergeten" is te corrigeren, dus "liefst" is totaal geen optie.
Dit is geen commentaar op T.net persoonlijk, laat dat duidelijk zijn.
Maar als je iets probeert duidelijk te maken, en die duidelijkheid zelf ondermijnt, dan gaan er bij mij bellen rinkelen.
Ook als ik elders iets soortgelijks zie of hoor.
B.v. de reclame van Brand New Day
Op dit perron staan 28 mensen, meer dan de helft kan later mogelijk geld tekort komen ... pensioenpotje.
Er is vast veel geld betaald om deze commercial te laten maken.
En in eerste instantie trekt het ook je aandacht.
Maar het is overdreven om het doel te over-benadrukken:
"kan mogelijk geld tekort komen" mogelijk betekent dat het dus niet zeker is
Maar het is kennelijk wel een feit dat het, ondanks dat het niet zeker is, gaat om meer dan de helft ...
Dan moet ik meteen aan het woord "geloofwaardigheid" denken.
Ik hoop dat de commercial niet te duur is geweest.
ik heb teksten geschreven met ai. Dat is een interactief gebeuren en daarna pas je het eindresultaat nog steeds aan. Of het resultaat van de interactie is slechts een deel van de tekst, verdeeld over fragmenten. Wat doe je dan met prompt erbij?
Ik weet ook eigenlijk niet waarom of hoe lang er indicaties 'met hulp van AI' bij moeten. Binnenkort worden vrijwel alle journalistieke en zakelijke teksten met hulp van Al geschreven durf ik wel te stellen. Zeker omdat in de journalistiek de winstmarges niet overhouden is zo'n productiviteitsboost zeer wenselijk.
Het kan vaak ook prima. Veel tweakers.net berichten zijn korte interpretaties van nieuws dat elders verscheen. Het lijkt me goed denkbaar dat eenbGPT op basis van drie bronnen en een standaardinstructie over de stijl van deze site steeds minder mensenwerk nodig heeft voor dat soort artikelen.
Maar ook research. Je reviewt een telefoon en vraagt wat de meningen zijn van de rest van het internet tot nu toe. Je hebt al data van andere telefoons en laat die vergelijken en in een tabelletje zetten. Dat zijn zaken die nu gewoon net iets makkelijker / sneller /beter kunnen. Daar hoeft geen prompt bij. Je geeft ook niet aan dat je Google en Excel gebruikt heb.
peer review gaat over wetenschap en onder andere kwaliteit van het eindproduct en de relevante referenties naar andere publicaties. Dat lijkt me hier sowieso nog niet zo snel knellen, maar is op de meeste tekst (zeker op tweakers) niet van toepassing.
In de zin van 'niet om te schrijven' maar om een voorbeeld van AI-tekst te kunnen plaatsen in bijvoorbeeld een artikel over AI-geschreven tekst waarbij het, als het van een externe bron komt, dus niet altijd mogelijk zal zijn een prompt toe te voegen.
Laten we wel zijn, AI was niet nieuw. Er worden al jaren modellen gebruikt met een aantal zelf lerende componenten, inclusief (numerieke) informatie die van het internet wordt geplukt. De tekst component is ook niet nieuw, want die dat al enkele jaren in vele chatbots.
De wereld van AI zat er al een tijd tegen een doorbraak aan te hikken, maar de menselijke taal is een horde geweest die heel moeilijk was te nemen. Op het moment dat die horde eenmaal genomen was is AI in de stroomversnelling terecht gekomen die in het artikel is beschreven.
Wat nieuw is zijn eigenlijk de taalmodellen. Daarmee kan AI grote lappen tekst kan interpreteren en combineren. Daarbovenop kreeg AI ook de mogelijkheid om taalkundig correcte teksten te produceren. AI kreeg daardoor voor het eerst een algemene en goede communicatie mogelijkheid die sterk lijkt op de onze manier van communiceren. De manier van communiceren is inmiddels zo goed dat die nauwelijks van door menselijke communicatie is te onderscheiden. Dat is een hele grote stap!
Plaatjes genereren is ook niet nieuw. Grafieken worden al jaren computer gegenereerd en geïnterpreteerd. Foto's konden met "slimme" filters worden bewerkt. Landschappen konden 20 jaar geleden al volledig door een computer worden gegenereerd. Het taal model maakt echter mogelijk dat plaatjes geïnterpreteerd kunnen worden door van de begeleidende tekst gebruik te maken. De overeenkomstige elementen kunnen dan weer gebruikt worden voor het genereren van nieuwe beelden.
Je kan AI als een bedreiging zien, maar je kan ook zeggen dat de "computer" eindelijk volwassen begint te worden en de "kleutertaal" eindelijk is ontgroeid. Ik zie AI nu vooral in de pubertijd. Net als een menselijke puber moeten de grenzen en gevaren nog afgetast worden en moeten de grenzen en regels nog duidelijk worden gemaakt.
Bovenstaande is nog volledig uit een menselijk brein ontschoten en handmatig ingetikt.
Plaatjes genereren is ook niet nieuw. Grafieken worden al jaren computer gegenereerd en geïnterpreteerd. Foto's konden met "slimme" filters worden bewerkt. Landschappen konden 20 jaar geleden al volledig door een computer worden gegenereerd. Het taal model maakt echter mogelijk dat plaatjes geïnterpreteerd kunnen worden door van de begeleidende tekst gebruik te maken. De overeenkomstige elementen kunnen dan weer gebruikt worden voor het genereren van nieuwe beelden.
Dat is niet echt te vergelijken met wat er nu gebeurt. Photoshop is inderdaad niet nieuw. Een generatief model is wel nieuw, die technologie bestond 5 jaar geleden gewoon niet.
Je kan AI als een bedreiging zien, maar je kan ook zeggen dat de "computer" eindelijk volwassen begint te worden en de "kleutertaal" eindelijk is ontgroeid. Ik zie AI nu vooral in de pubertijd. Net als een menselijke puber moeten de grenzen en gevaren nog afgetast worden en moeten de grenzen en regels nog duidelijk worden gemaakt.
Ik zie het toch iets pessimistischer in. Ik denk dat enkel door de groei van GPU compute AI zo hard heeft kunnen groeien de afgelopen jaren. Als je echt in de achterliggende wiskunde duikt van CNN's en transformers is het eigenlijk allemaal niet zo complex. Maar door het op te schalen creeër je nieuwe functionaliteit, en juist daarvoor heb je grote GPU clusters nodig. Ik verwacht zelf dat alle huidigie AI technieken tegen een muur aan gaan lopen en dat meer compute niet meer intelligentie oplevert. Er komt dus een nieuwe AI revolutie, maar dan met échte intelligentie.
Een generatief model is wel nieuw, die technologie bestond 5 jaar geleden gewoon niet.
Het genereren van landschappen bestond zelfs al 20 jaar geleden. Ook dat was generatief. Wat nieuw is, is het genereren van plaatjes op basis van elementen uit andere plaatjes. Door het taalmodel kan men nu elementen uit andere plaatjes herkennen, waardoor veel zelfstandig naamwoorden ook een beeldvorm hebben gekregen. Veel van de gebruikte filters zijn helemaal niet nieuw, maar aangepast op het nieuwe gebruik.
AI is gebaseerd op combineren rubriceren en indexeren. Menselijke taal vraagt gewoon veel rekenkracht en het toevoegen van rekenkracht zal de AI verbeteren, maar nooit iets opleveren wat echt intelligent is, wel dingen die echt intelligent lijken, Voor een groot deel doen mensen hetzelfde, waardoor het verschil heel klein is. Echt intelligente mensen (klasse Einstein) combineren zaken die met de kennis van dat moment eigenlijk niet gecombineerd kunnen worden en vinden vervolgens de missende component.
Uitvinders hoeven ook niet bang te zijn, want ook die vinden dingen uit voor toepassingen die nog niemand kent. AI zal bijvoorbeeld ook nooit eigenschappen van stoffen ontstaan uit een nieuw ontdekte chemische reactie kunnen berekenen. De kans dat AI de chemisch reactie kan vinden is wel aanwezig, mits daar geen heel specifieke omstandigheden voor nodig zijn, maar voor het resultaat ontbreken simpelweg de referenties uit het verleden.
Als voorbeeld kan je Covid 19 gebruiken. Ook met AI kon je onmogelijk de genetische mutaties voorspellen en als je ze handmatig toevoegde, was het onmogelijk om het gevolg daarvan te "berekenen". Van een aantal stukken van het RNA was de functie bekend en daar hebben wetenschappers en vervolgens de pharmalogische industrie gebruikt van gemaakt om RNA strings te maken die voor het immuun systeem zo activeren dat die een verdediging tegen het echte virus zou maken en daarmee het echte virus zou herkennen. Kunst was echter om de ziekmakende component volledig uit te schakelen.
Het genereren van landschappen bestond zelfs al 20 jaar geleden. Ook dat was generatief.
Dat is toch wel iets totaal anders dan wat er nu gedaan wordt. Met generatief bedoelen we dat het model dat de plaatjes genereert de generatieve distributie van de data benaderd. Ja je kan ook plaatjes 'generereren' op andere manieren, maar dat is niet wat ik bedoel.
Wat nieuw is, is het genereren van plaatjes op basis van elementen uit andere plaatjes. Door het taalmodel kan men nu elementen uit andere plaatjes herkennen, waardoor veel zelfstandig naamwoorden ook een beeldvorm hebben gekregen. Veel van de gebruikte filters zijn helemaal niet nieuw, maar aangepast op het nieuwe gebruik.
Tsja, transistors zijn ook niet nieuw. Maar als je ze met miljarden in een bepaalde architectuur zet krijg je toch echt nieuwe functionaliteit. Iets soortgelijks is er nu gebeurt met transformers voor LLM's en daarvoor met CNN's voor plaatjes.
AI is gebaseerd op combineren rubriceren en indexeren.
Uitvinders hoeven ook niet bang te zijn, want ook die vinden dingen uit voor toepassingen die nog niemand kent. AI zal bijvoorbeeld ook nooit eigenschappen van stoffen ontstaan uit een nieuw ontdekte chemische reactie kunnen berekenen. De kans dat AI de chemisch reactie kan vinden is wel aanwezig, mits daar geen heel specifieke omstandigheden voor nodig zijn, maar voor het resultaat ontbreken simpelweg de referenties uit het verleden.
LLM's worden al veelvuldig gebruikt in drug discovery en DNA analyse dus ik zou niet weten waarom dat niet zou kunnen. En waarom zouden die referenties nodig zijn? We zien juist dat generatieve modellen sterk zijn in het verzinnen van compleet nieuwe dingen, met helaas vaak hallucinaties tot gevolg.
Als voorbeeld kan je Covid 19 gebruiken. Ook met AI kon je onmogelijk de genetische mutaties voorspellen en als je ze handmatig toevoegde, was het onmogelijk om het gevolg daarvan te "berekenen". Van een aantal stukken van het RNA was de functie bekend en daar hebben wetenschappers en vervolgens de pharmalogische industrie gebruikt van gemaakt om RNA strings te maken die voor het immuun systeem zo activeren dat die een verdediging tegen het echte virus zou maken en daarmee het echte virus zou herkennen. Kunst was echter om de ziekmakende component volledig uit te schakelen.
Het genereren van landschappen gebeurde op basis van een globale beschrijving, maar omdat die maar uit een beperkt aantal woorden bestond (water, lucht, rots, zand, zon, wolken) kon dat met een aantal sliders worden gedaan. Generatief? Ja, zeker. Het is wel een heel simpel begin van generatief plaatjes maken.
Daar zijn uiteindelijk een hoop technieken aan toegevoegd. E-Dali kan bij heel veel woorden een plaatje vinden. Die kan het ook op logische manieren combineren. Uit voorbeelden kan het ook verschillende stijlen herkennen. Door (aangepaste) bestaande filters en nieuwe filters te gebruiken is er compleet nieuwe toepassing ontstaan. Voor het begrijpen van bestaande plaatjes en het leggen van verbanden tussen de plaatsing van verschillende objecten kan het nu realistische composities maken. Door daar weer wat filters overheen te gooien kan het de stijl van het uiteindelijke plaatje weer aanpassen.
De taalmodellen zijn zeer belangrijk geweest, maar die zijn juist ontstaan door ontzettend veel teksten met een nagenoeg oneindig aantal woorden te lezen en de worden te rubriceren en te indexeren. Vervolgens word die opgedane kennis (de taalmodellen) opnieuw gebruikt om teksten opnieuw volgens een andere methode te rubriceren en indexeren, waardoor er een soort begrip van de teksten lijkt te ontstaan.
Dat Covid artikel geeft voor geïnteresseerden goed weer hoe men de verschillende vaccins heeft ontwikkeld. Alle fabrikanten hebben min of meer dezelfde methode gebruikt, maar met andere eindresultaten. Allemaal RNA vaccins, die gebaseerd zijn op stukjes RNA waarvan vermoed werd dat die door het menselijk immuunsysteem herkend zouden moeten kunnen worden (zekerheid had men beslist niet). Hoe de ziekmakende component onschadelijk gemaakt kon worden was lastiger, omdat ook AI daar geen basisgegevens over had. Daar zat ook het voornaamste verschil tussen de verschillende vaccins.
Een vaccin zou werken totdat ook in dat herkenningsstukje een mutatie zou optreden.
Ik begrijp AI heel goed. Als data-analist heb ik 25/30 jaar geleden de eerste zelf lerende algoritmes zien ontstaan en daar ook aan meegewerkt om voorspellende modellen te maken. Daar ligt de meest simpele basis van AI. Ik ben een stapje verder gegaan naar de eerste algoritmes die men echt AI is gaan noemen. Wat jij beschrijft is weer een stap verder, waarbij enorme hoeveelheden computerkracht zijn ingezet om die eerste taalkundig georiënteerde AI modellen op grote hoeveelheden teksten los te laten. Daar zijn de taalmodellen vervolgens uit ontstaan. Die taalmodellen zijn de echte omwenteling geweest. Dat die doorbraak er eens zou komen was door velen uit dat werkveld ook al voorspeld. Het grootste gebrek was immers pure verwerkingskracht. Zelf ben ik van de biologie naar verkeer en toerisme verhuist, maar maak nog steeds complexe modellen die ik ook als AI verkoop. Met mijn kennis en voldoende computercapaciteit zou ik in staat moeten zijn om een taalmodel te laten creëren. Ik kan het niet bewijzen, want ik heb niet eens een procent van de benodigde computerkracht tot mijn beschikking.
Hoewel de basale werking van AI niet veel is veranderd heeft juist die toevoeging van taalmodellen en computerkracht de wereld op zijn kop gezet omdat AI "menselijke trekjes" kreeg en voor iedereen bruikbaar werd en ook begrijpbare resultaten gaf. De taalmodellen functioneren nu als een tussenlaag (zeker niet onbelangrijk) die teksten kan interpreteren en fabriceren.
Kort gezegd heb je dus wel gelijk, maar ik heb het over een fase voor de fase die jij beschrijft. Noem het het eerste en tweede AI tijdperk. Omdat de werking van AI op de achtergrond nog altijd volgens de oude basisprincipes werkt (waar dus een aantal lagen aan zijn toegevoegd), is het resultaat nog steeds het combineren van bestaande kennis. Zeker aan de creërende kant in woord, beeld en geluid, zijn die extra lagen indrukwekkend. Het lijkt ook intelligent, maar tot nu toe zijn de modellen voor de intelligentie nog afhankelijk van de mens die de opdrachten intikt. Ik vergelijk deze fase met een puberfase. De AI laat kenmerken van zelfstandigheid zien, maar heeft op de achtergrond nog wel wat sturing nodig.
Ik begrijp AI heel goed. Als data-analist heb ik 25/30 jaar geleden de eerste zelf lerende algoritmes zien ontstaan en daar ook aan meegewerkt om voorspellende modellen te maken.
Heb je ook relevante ervaring, van ongeveer de afgelopen 4 jaar?
Ik kan het niet bewijzen, want ik heb niet eens een procent van de benodigde computerkracht tot mijn beschikking.
Ik kan op de kleinere LLaMA modellen prima lokaal inference draaien met een RTX3090. Trainen is wat lastiger, maar is met offloading wel te doen.
Hoewel de basale werking van AI niet veel is veranderd heeft juist die toevoeging van taalmodellen en computerkracht de wereld op zijn kop gezet omdat AI "menselijke trekjes" kreeg en voor iedereen bruikbaar werd en ook begrijpbare resultaten gaf.
Wat bedoel je concreet met de 'basale' werking?
Omdat de werking van AI op de achtergrond nog altijd volgens de oude basisprincipes werkt (waar dus een aantal lagen aan zijn toegevoegd), is het resultaat nog steeds het combineren van bestaande kennis.
Onzin. Ten eerste moet je eerst zorgvuldig, wiskundig definiëren wat je precies met combineren bedoelt. Ten tweede is dat niet wat een generatief model doet. Zoals ik al eerder zei, een generatief model leert (via trainen) de statistische distributie die de data gegenereerd heeft. Vervolgens kun je daar van samplen om nieuwe data te genereren. Een prompt is dus ook niks minder dan een sample van de distributie die het model geleerd heeft.
Jij blijft de LLaMA modellen als de basis voor AI zien. Die zijn voor de AI als ChatGPT zeer belangrijk, maar het is niet de basis van AI. Ze zijn zelf grotendeels met AI gemaakt. Voor het draaien van een LLaMA model heb je niet zo heel veel computerkracht nodig, zelfs met een Raspbery Pi 4 kan dat.
Voor het maken en trainen van een LLaMA model heb je wel heel veel computerkracht nodig. Zo'n model moet ik met mijn huidige kennis kunnen maken, maar daarvoor ontbreekt mij dus de computerkracht. Een bestaand model gebruiken is niet zo heel moeilijk.
Alle AI is per definitie gebaseerd op generatieve modellen, anders is het een simpel algoritme. De uitkomst en de waarschijnlijkheid van de waarheid daarvan wordt weer als input gebruikt en uiteindelijk wordt dat in een index gebruikt.
Ik werk nog steeds aan (numerieke) AI modellen, maar dan vooral op het verkeer gericht. Momenteel ben ik bezig voor London (Canada) een compleet nieuw verkeerssysteem te ontwikkelen waarbij het gebruik van de fiets gestimuleerd moet worden en delen van de stad autoluw moeten worden. Grootste probleem is dat aanpassingen zoveel mogelijk tijdens regulier wegonderhoud moeten gebeuren.
AI blijft gebaseerd op indexeren en rubriceren. Antwoorden worden daarin weer meegenomen.
Dat AI niets voorstelt zal ik nooit zeggen. Het is een kunst om de juiste indexen te creëren en op de juiste manier te gebruiken. De verschillende lagen creëren en vervolgens in een volgend model te implementeren is zeker niet gemakkelijk.
AI blijft gebaseerd op indexeren en rubriceren. Antwoorden worden daarin weer meegenomen.
Aangezien er geen database of expliciet geheugen beschikbaar is in een transformer, hoe werkt dat dan precies?
Dat AI niets voorstelt zal ik nooit zeggen. Het is een kunst om de juiste indexen te creëren en op de juiste manier te gebruiken. De verschillende lagen creëren en vervolgens in een volgend model te implementeren is zeker niet gemakkelijk.
Het stelt echt geen bal meer voor. Voor kleine netwerken kun je zelfs de dimensies van de architectuur zelf opnemen als hyperparameters, dan is er helemaal geen bal meer aan. Ben blij dat ik ben gaan specialiseren in optimalisatie.
Je merkt inderdaad echt dat we nu weer in de een nieuwe hype zitten, en dat is AI, zelf de dit jaar uitgekomen Mission Impossible film was in het teken van AI, ben zeer benieuwd hoe ver dit zich door gaat ontwikkelen en in hoe verre we dit straks in ons dagelijks leven gaan merken.
Ik vind wel dat er even mag benadrukt worden dat AI de marketingterm is voor in essentie patroonherkenning.
Begrijp me niet verkeerd: AI/creatief toepassen van patroonherkenning past bij mij in het rijtje van uitvindingen zoals: elektriciteit, internet,... het zal op alles en iedereen invloed hebben.
Het interessante is dat een mens ook voortdurend aan patroonherkenning doet. En dat AI op sommige vlakken beter is in patroonherkenning én dat we geen idee hebben hoe AI dat voor elkaar krijgt.
een mens ook voortdurend aan patroonherkenning doet. En dat AI op sommige vlakken beter is in patroonherkenning én dat we geen idee hebben hoe AI dat voor elkaar krijgt
Volgens mij is het wel bekend waarom AI er beter in is. AI doet het namelijk bewust gestructureerd.
Het is al lang geleden onderzocht en er zijn zelfs technieken die je jezelf kunt aanleren om dingen beter te kunnen onthouden, anders te associëren.
Het is een bekend gegeven dat geuren sterkere herinneringen op kunnen roepen dan beelden of geluid omdat die in een ander deel van de hersenen verwerkt worden.
Een erg tot de verbeelding sprekend en extreem voorbeeld is savant syndroom.
Ik las onlangs een (basis)boek over AI. En daarin werd het voorbeeldje gegeven van AI dat aan de hand van een foto van de oogiris kan bepalen of het een man of een vrouw is van wie het oog is. (En ook als nuttige toepassing in staat is om bepaalde ziektes in een vroeg stadium te herkennen).
Dat de AI op een gestructureerde manier tot een conclusie komt lijkt mij logisch maar we weten niet waar de AI op let om de keuze te maken.
We weten wel dat geen enkele menselijke oogarts hiertoe in staat is.
maar we weten niet waar de AI op let om de keuze te maken
Het lijkt me dat dat gewoon te analyseren moet zijn. Zeker gezien AI altijd werkt met een vastgestelde set regels.
We weten wel dat geen enkele menselijke oogarts hiertoe in staat is.
Tot nu toe dan. Als we weten waar de AI naar kijkt, kan een mens het ook.
Het hele punt van AI is natuurlijk dat we het juist dingen als dit laten doen en ontdekken. Veel onderzoek wordt nu door mensen niet gedaan omdat het tijdrovend is, geld kost en het ook iets op moet leveren. En waarschijnlijk missen we een hoop omdat we simpelweg niet overal aan kunnen denken of mee bezig kunnen zijn.
Generatieve AI en patroonherkenning zijn toch wel fundamenteel andere technieken. Met patroon herkenning leer je discrimineren, met generatieve AI leer je om nieuwe voorbeelden te genereren. Dat doe je door de onderliggende, data genererende distributie te leren. Met patroonherkenning leer je enkel de distributie van de data die je gezien hebt.
Ik vermoed dat Wozmro bedoelt te zeggen dat sommige applicaties die nu 'AI' genoemd worden misschien wel op een slimme manier van de patronen gebruik maken om schijnbaar intelligente 'nieuwe' data te genereren, maar verder niet 'leren' van die onderliggende data en daarin geen verbanden kunnen leggen.
Zoals bijv. een plaatjesgenerator die feitelijk ook niet veel meer hoeft te doen dan aan de hand van prompts vanuit de enorme hoeveelheid data een random plaatje te genereren.
De versies van AI-chatbots zoals ChatGPT die online voor iedereen beschikbaar zijn zullen de lerende functies niet aan hebben staan, maar een kort geheugen hebben en geen persoonlijke dingen kunnen beantwoorden omdat ze de boel niet willen vergiftigen met alle rotzooi die mensen er in stoppen.
En hoewel het al indrukwekkend is wat het kan lijkt het er af en toe nog heel erg op dat het niet veel meer doet dan domweg tekst spugen vanuit een database.
De versies van AI-chatbots zoals ChatGPT die online voor iedereen beschikbaar zijn zullen de lerende functies niet aan hebben staan, maar een kort geheugen hebben en geen persoonlijke dingen kunnen beantwoorden omdat ze de boel niet willen vergiftigen met alle rotzooi die mensen er in stoppen.
Zelf lerende LLM systemen bestaan niet, ook niet voor betalende gebruikers en ook niet ergens in het geheim. Je hebt een context van x tokens, wat gewoon het huidige gesprek is en daar moet je het mee doen. Dat wil ik geen geheugen noemen zoals we dat kennen bij de mens.
En hoewel het al indrukwekkend is wat het kan lijkt het er af en toe nog heel erg op dat het niet veel meer doet dan domweg tekst spugen vanuit een database.
Maar dat doet het dus expliciet niet, vandaar ook de naam 'generatieve AI'.
Arnoud; respect voor je kaasanalogie en dat die overeind blijft tot en met het laatst. Ik ga hem ook gebruiken tijdens de oliebollen party vandaag en morgen.

:strip_exif()/i/2004968122.jpeg?f=imagenormal)
:strip_exif()/i/2005630924.jpeg?f=imagegallery)
:strip_exif()/i/2005629750.jpeg?f=imagegallery)
:strip_exif()/i/2005721412.jpeg?f=imagegallery)
:strip_exif()/i/2005721410.jpeg?f=imagegallery)
:strip_exif()/i/2005721408.jpeg?f=imagegallery)
/i/2006334902.png?f=imagegallery)
:strip_exif()/i/2005818644.jpeg?f=imagenormal)
:strip_exif()/i/2006334904.jpeg?f=imagegallery)
/i/2006112278.png?f=imagegallery)
:strip_exif()/i/2006226550.jpeg?f=imagegallery)
:strip_exif()/i/2006285084.jpeg?f=imagenormal)

:strip_icc():strip_exif()/i/2006728156.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006504206.jpeg?f=fpa_thumb)
:strip_exif()/i/2005682890.jpeg?f=fpa)
/u/581347/crop64beea7e7f624_cropped.png?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
/u/581763/crop671d464e1d270_cropped.png?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
:strip_icc():strip_exif()/u/149883/crop57a462252fb63_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
/u/314383/crop5dc6a4144d574_cropped.png?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
/u/266273/crop6989a0a0d22e9_cropped.png?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
:strip_exif()/u/1820/GoTicon.gif?f=community)
:strip_exif()/u/305537/112.gif?f=community)
:strip_icc():strip_exif()/u/678890/crop59368024e5669_cropped.jpeg?f=community)
{kind=link}