Nvidia heeft de H200-gpu aangekondigd die een belangrijke rol kan spelen in de toekomst van deep learning en taalmodellen, zoals GPT-4 van OpenAI. Het is de eerste gpu van het bedrijf met HBM3e-geheugen.
De Nvidia H200 is gebaseerd op de Hopper-architectuur en vervangt de huidige H100-gpu. Het HBM3e-geheugen moet een hogere snelheid en meer capaciteit opleveren. Nvidia spreekt van 141GB gpu-geheugen met een bandbreedte van 4,8Tbit/s, wat twee keer de capaciteit van zijn voorganger is. De H200-gpu heeft volgens de chipmaker ook 2,4 keer zoveel bandbreedte als de Nvidia A100.
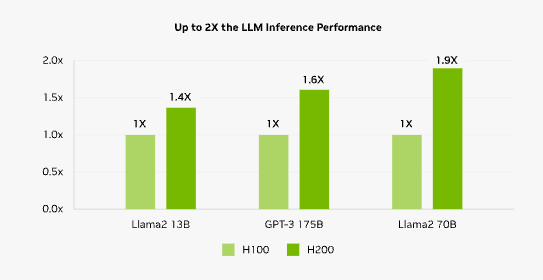
Volgens Nvidia verdubbelt de HGX H200-gpu de inferentiesnelheid van het large language model Llama 2 met 70 miljard parameters ten opzichte van de H100-gpu. Bij GPT-3 gaat het om een interferentiesnelheid van 175 miljard, wat ruim 1,5 keer zo snel is als de voorganger.
In het tweede kwartaal van 2024 komt de H200 uit. De gpu is ook beschikbaar in de GH200 Grace Hopper-'superchip' die in augustus werd aangekondigd. De H200 moet onderzoekers in staat stellen complexe AI-taken uit te voeren door de mogelijkheid om in een snel tempo terabytes aan gegevens te verwerken.

/i/2004919460.png?f=fpa)
:strip_exif()/i/2004714376.jpeg?f=fpa)
/i/2004850458.png?f=fpa)
:strip_exif()/i/2006489698.jpeg?f=fpa)
/i/2004611214.png?f=fpa)
/i/2004695548.png?f=fpa)
:strip_exif()/i/2005803048.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2001116017.png?f=fpa)
:strip_exif()/i/2004743102.jpeg?f=fpa)
/i/2000820476.png?f=fpa)
/u/945/motorola_mpx300_3.GIF?f=community)
:strip_icc():strip_exif()/u/850571/crop643b56c36ea81_cropped.jpg?f=community)
:strip_exif()/u/682799/crop5fc57c6c9c5fa_cropped.gif?f=community)
:strip_icc():strip_exif()/u/443373/crop5ed10069d8f77_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/92491/crop64a1593f33a7b_cropped.jpg?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
/u/238475/crop5db01b7054bdf_cropped.png?f=community)
/u/678946/crop6516cce7d5a19_cropped.png?f=community)