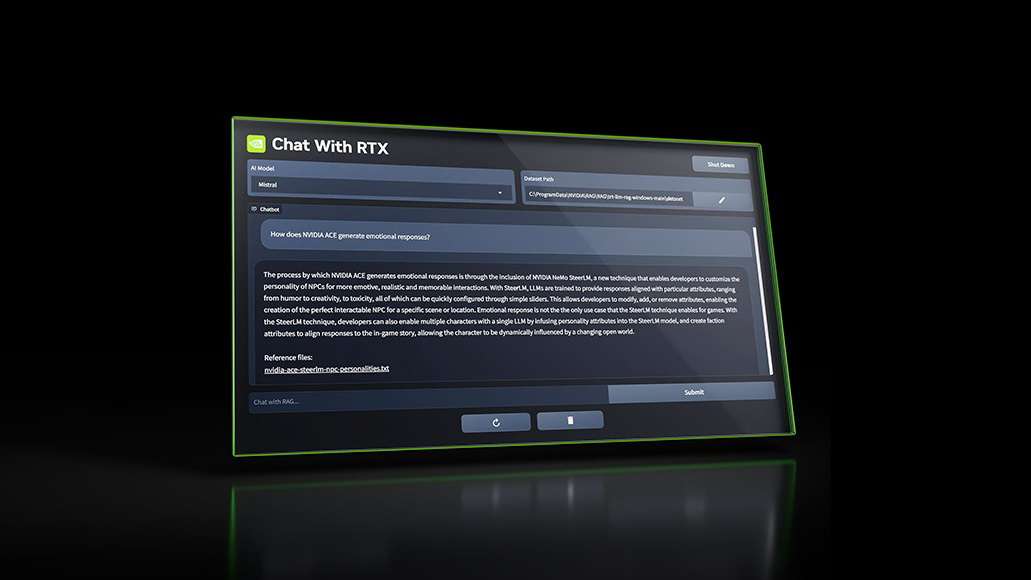
Nvidia toont een 'Chat with RTX'-techdemo. Gebruikers met een RTX-gpu kunnen daarmee later deze maand lokaal een AI-chatbot maken. Ze kunnen bijvoorbeeld hun eigen documenten invoeren in de software, waarna de chatbot vragen over die data kan beantwoorden.
Chat with RTX wordt gebaseerd op een groot taalmodel van Nvidia, dat gebruikers lokaal kunnen draaien. Ze kunnen het taalmodel 'verbinden' met hun eigen data, zoals lokaal opgeslagen tekstdocumenten, pdf's en XML-bestanden. Gebruikers kunnen ook de URL's van YouTube-video's en -afspeellijsten invoeren, waarna de software transcripten van die video's downloadt om die te gebruiken in de chatbot. De bot kan die data analyseren en daar vervolgens vragen over beantwoorden.
De demo maakt gebruik van de Retrieval-Augmented Generation-techniek voor generatieve AI en de opensource-Tensor-LLM-software. Chat with RTX gebruikt de Tensor-cores van RTX-gpu's. De software kan dan ook lokaal draaien op 'Windows-pc's met RTX'. Of de demo beschikbaar komt voor alle RTX-gpu's of alleen voor de RTX 40-serie, is niet bekend. Tweakers heeft daarover vragen uitstaan bij Nvidia.
Nvidia zegt dat de Chat with RTX-demo later deze maand beschikbaar zal zijn. Wanneer precies is niet duidelijk. Gebruikers kunnen zich inschrijven op de website van Nvidia, zodat ze een notificatie krijgen als de demo beschikbaar is.

/i/2004919460.png?f=fpa)
/i/2004695548.png?f=fpa)
:strip_exif()/i/2004714220.jpeg?f=fpa)
:strip_exif()/i/2005362044.jpeg?f=fpa)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
:strip_exif()/u/44466/0115455001290429971.gif?f=community)
:strip_icc():strip_exif()/u/291391/crop6148d881d04cd_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/66961/crop5c20da5d3451c_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/162143/crop5b6d888e9cc79_cropped.jpeg?f=community)
/u/111174/sachiel-small.png?f=community)
/u/619951/60.jpg.png?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_exif()/u/7689/Copicon.gif?f=community)
:strip_exif()/u/267506/crop6737556602b99.gif?f=community)
/u/1006081/crop5a2704340349c_cropped.png?f=community)
/u/48718/crop619e5ed546e66_cropped.png?f=community)
/u/325014/Inter3-play.png?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
:strip_icc():strip_exif()/u/299039/dv3.jpg?f=community)
:strip_icc():strip_exif()/u/621125/crop65cd0fde312bc_cropped.jpg?f=community)
/u/2008130/crop6536ebba0daf2_cropped.png?f=community)