Nvidia gaat mogelijk een deel van zijn datacenter-gpu's laten 'packagen' door Intel. Dat melden bronnen aan het Taiwanese UDN. Momenteel neemt TSMC die taak volledig op zich met zijn CoWoS-packagingtechniek, maar de Taiwanese chipmaker kan niet aan alle vraag voldoen.
Nvidia stapt niet volledig over op Intel, maar zal slechts een klein deel van zijn productie aan de Amerikaanse chipmaker uitbesteden. Dat melden bronnen aan het Taiwanese dagblad United Daily News. Dat moet gebeuren vanaf het tweede kwartaal van dit jaar. TSMC blijft de primaire leverancier van Nvidia. Volgens UDN gaat Intel ongeveer 5000 wafers per maand verwerken voor Nvidia, wat volgens het dagblad goed zou zijn voor ongeveer tien procent van Nvidia's totale vraag. Dat kan bijvoorbeeld neerkomen op maandelijks 300.000 Nvidia H100-datacenter-gpu's, schrijft Tom's Hardware.
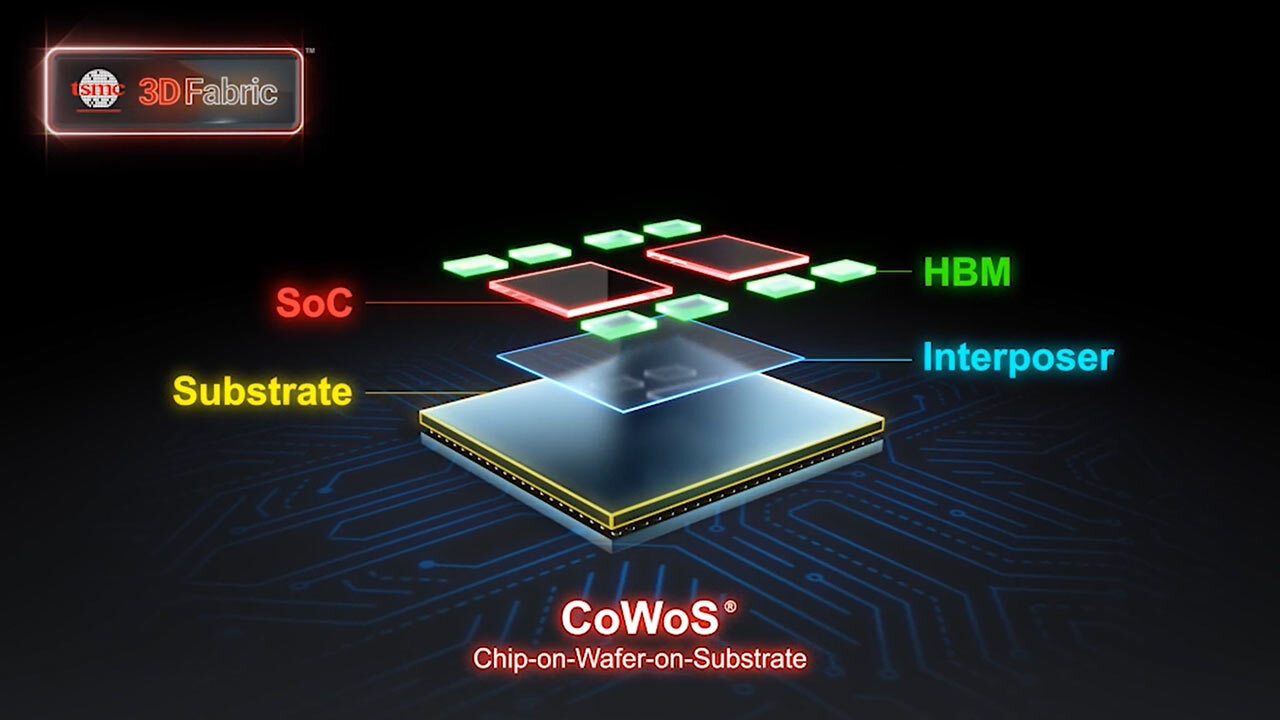
Intel Foundry Services zou de gpu's niet zelf gaan produceren, maar enkel packagen met geavanceerde technieken. Bronnen van UDN melden niet om welke technieken het precies gaat. Veel van Nvidia's datacenter-gpu's voor AI, waaronder de high-end A100, H100 en H200, worden momenteel gepackaged met TSMC's CoWoS-techniek. Dat is een techniek voor 2,5d-packaging, waarmee verschillende chips met elkaar worden verbonden op een interposer van silicium. Daardoor kunnen de chips dichter bij elkaar geplaatst worden.
Hpc-chipmakers, waaronder Nvidia, gebruiken de CoWoS-techniek bijvoorbeeld om hun gpu-dies te verbinden met snel HBM-geheugen. Intel biedt zijn Foveros-packagingtechniek, ook op basis van interposers, hoewel die techniek niet een-op-een gelijk is aan die van TSMC. Nvidia moet vermoedelijk zijn ontwerpen aanpassen en valideren voordat het gebruik kan maken van Intels packagingcapaciteit voor grootschalige productie.
TSMC erkende eerder al dat het momenteel niet kan voldoen aan de vraag naar geavanceerde packaging, waarbij losse chip-dies worden gecombineerd tot een werkend geheel. Dat komt door de hoge vraag naar datacenter-gpu's die worden gebruikt voor het trainen van AI-modellen. Het bedrijf zou vorig jaar al hebben gezegd dat het de inspanningen om zijn packagingcapaciteit te verhogen wil 'versnellen', meldde DigiTimes destijds.
Intel biedt met zijn Foundry Services-divisie tegenwoordig ook chipproductie- en -packagingdiensten voor andere bedrijven, waar het vroeger zijn volledige productiecapaciteit inzette voor eigen producten. De Amerikaanse chipmaker opende onlangs een nieuwe packagingfabriek in New Mexico. Dat betrof de eerste fabriek waar Intel op grote schaal Foveros kan inzetten om chips te packagen. De fabrikant heeft ook packagingcapaciteit in Oregon en bouwt momenteel een geavanceerde packagingfab in Maleisië.
:strip_exif()/i/2006406936.jpeg?f=imagegallery)
TSMC's CoWoS-techniek (links) en Intel Foveros

:strip_icc():strip_exif()/i/2005002394.jpeg?f=fpa_thumb)
:strip_exif()/i/2004886338.jpeg?f=fpa)
:strip_exif()/i/2006847440.jpeg?f=fpa)
/i/2004628280.png?f=fpa)
/i/2004695548.png?f=fpa)
:strip_exif()/i/2004681518.jpeg?f=fpa)
:strip_exif()/i/2006355622.jpeg?f=fpa)
/i/2006468270.png?f=fpa)
/i/2004919460.png?f=fpa)
/i/2004611214.png?f=fpa)
:strip_exif()/i/2003847926.jpeg?f=fpa)
:strip_exif()/i/2004743102.jpeg?f=fpa)
/i/2004628264.png?f=fpa)
:strip_exif()/i/2005803048.jpeg?f=fpa)
/i/2004781850.png?f=fpa)
/i/2001665377.png?f=fpa)
/u/77158/crop61d86f7651cf3_cropped.png?f=community)