Volgens Intel maakt zijn komende Intel 4-chipprocedé 21,5 procent hogere kloksnelheden bij processors mogelijk, bij gelijkblijvende tdp's. Intel 4 is de eerste chipnode van het bedrijf waarbij Intel euv-chipmachines inzet. Intel toonde een dieshot van een Meteor Lake-chip.
Intel 4 maakt 21,5 procent hogere kloksnelheden bij gelijkblijvende tdp, een 40 procent lager verbruik bij gelijke kloksnelheden of een combinatie daarvan mogelijk, meldde Intel tijdens het IEEE VLSI Symposium 2022. Tom's Hardware schrijft over de presentatie. Intel vergelijkt Intel 4 daarbij bij de huidige chipnode van het bedrijf, Intel 7, die onder andere voor Alder Lake gebruikt wordt.
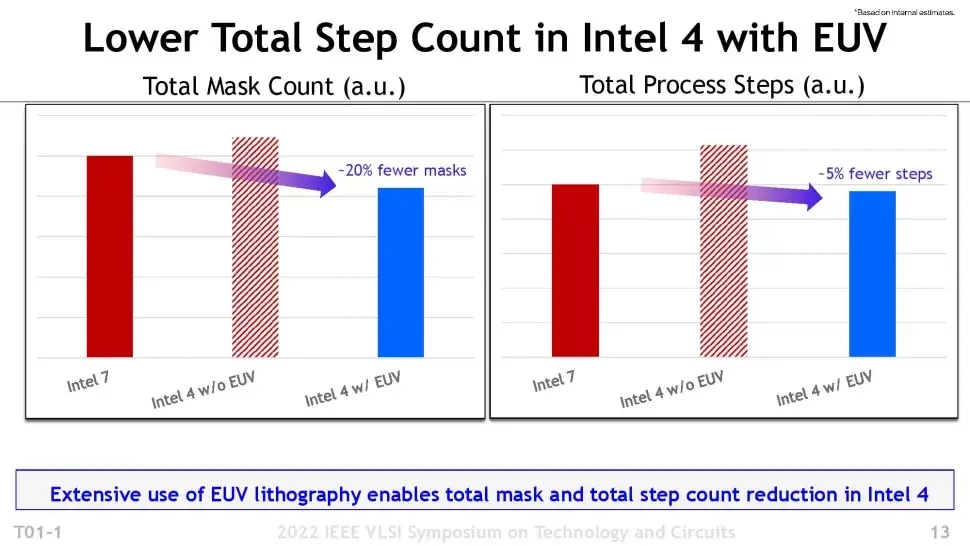
Intel 4 is het chipprocedé waar het bedrijf voorheen onder de noemer 7nm naar verwees, waarbij Intel 7 de 10nm-node was. Het bedrijf maakt uitgebreid gebruik van euv-chipmachines voor de productie en daardoor zijn minder tijdrovende processtappen en dure maskers voor de belichting vereist. Intel spreekt van 2x scaling wat betreft de high performance library, wat betekent dat het bedrijf bij Intel 4 twee keer zoveel transistors op een oppervlak als bij Intel 7 weet te plaatsen bij de chipstructuren voor hoge prestaties.



De eerste processorgeneratie op basis van Intel 4 wordt Meteor Lake. Deze moet in 2023 verschijnen. Intel onthulde dat het in het tweede kwartaal werkende processors heeft geproduceerd. Intel maakt bij Meteor Lake gebruik van de Foveros 3D-technologie voor packaging. Deze stelt het bedrijf in staat verschillende 'tegels' of chiplets op een interposer te plaatsen, verbonden via through silicon via-kanaaltjes. Het gaat daarbij om tegels voor compute, graphics, I/O en soc.
Intel toonde een dieshot van de compute-tegel, waarop te zien is dat Meteor Lake uit zes krachtige p-cores, met codenaam Redwood Cove, en twee clusters van elk vier zuinige e-cores, de Crestmont-cores, bestaat. Foveros 3D stelt Intel in staat de verschillende onderdelen op verschillende procedés te maken, of te laten maken. Het compute-deel maakt het bedrijf in ieder geval op de Intel 4-node.





/i/2004611214.png?f=fpa)
:strip_exif()/i/2005833488.jpeg?f=fpa)
:strip_exif()/i/2005833550.jpeg?f=fpa)
:strip_exif()/i/2005798502.jpeg?f=fpa)
:strip_exif()/i/2005546144.jpeg?f=fpa)
/i/2005295852.png?f=fpa)
/i/2004781850.png?f=fpa)
/u/102775/crop5fdca9bae9d3a_cropped.png?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
/u/27299/hoofd.png?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
/u/298857/crop6471d9676d431.png?f=community)
:strip_icc():strip_exif()/u/15647/crop60adf598f02ba_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/41507/crop5e808de4a35b0_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/299039/dv3.jpg?f=community)
:strip_icc():strip_exif()/u/173388/crop5dbbf7660b2c7_cropped.jpeg?f=community)
/u/90622/crop5dc942b9bd727_cropped.png?f=community)