De Nederlandse sites die het vaakst gebruikt worden voor het trainen van chatbots, staan bol van auteursrechtschendingen, privégegevens en nepnieuws. Dat concludeert De Groene Amsterdammer na eigen onderzoek. Docplayer.nl zou de belangrijkste bron voor chatbots zijn.
Voor het onderzoek keek De Groene Amsterdammer naar de tweeënhalf miljoen unieke Nederlandse en Belgische websites waar Google teksten uit verzameld heeft voor de mC4-dataset, een 'opgeschoonde versie' van de Common Crawl-webcrawldataset, schrijft de site. Daarin bevindt zich vrijwel elke tekst van het internet.
Omdat veel bedrijven niet prijsgeven welke bronnen ze gebruiken voor het trainen van hun chatbots, valt niet met zekerheid te zeggen of ze de mC4-database gebruiken. DGA schrijft dat voor GPT-3 in ieder geval de Common Crawl-dataset als basis gebruikt wordt, maar dat OpenAI daar nog een eigen 'strenger' filter overheen legt. Dat kwaliteitsfilter werd vergeleken met het filter dat Google gebruikt voor het opstellen van de mC4-dataset 'en we zagen geen belangrijke verschillen'. De Groene Amsterdammer schrijft in zijn verantwoording daarom dat de bestudeerde Nederlandse websites 'een zeer aannemelijke kans hebben' om in de ChatGPT-trainingsdata te zitten.
Naast de websites zelf is voor elke site ook berekend hoe groot het aandeel was in de collectie. "Dat deden we op basis van het aantal woorden in de collectie, dat we, vanwege de omvang van de dataset, relatief simpel berekenden door de teksten te splitsen op basis van spaties."
Hieruit kwam naar voren dat docplayer.nl met een aandeel van 3,6 procent de de belangrijkste Nederlandse bron voor chatbots is. Deze hostingsite verzamelt allerlei documenten, waaronder bestanden met persoonsgegevens zoals evaluaties van sollicitanten, en kwam in 2017 in opspraak omdat het die verkrijgt door andere sites te scrapen. Er werd door de Nederlandse overheid uiteindelijk besloten om geen stappen te ondernemen tegen die site.
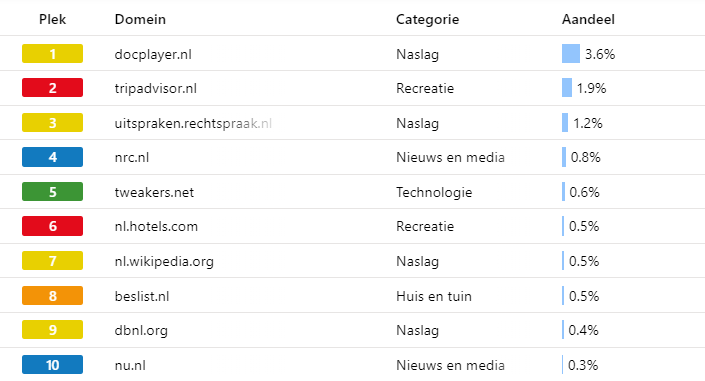
Daarnaast valt het De Groene Amsterdammer op dat veel websites over games en technologie hoog staan in de lijst. Zo staat Tweakers op nummer vijf. De site verklaart dat door het feit dat dergelijke sites veel Engelse termen gebruiken. Omdat het filter vooral is afgesteld op Engelstalige teksten, zouden dergelijke sites daarom de voorkeur krijgen van het filter.
Verder zou er ook een 'neonazistische complotwebsite' in de top 200 staan, namelijk Stormfront. Omdat deze site slechts een plek lager staat dan RTL Nieuws, concluderen de onderzoekers dat chatbots van beide sites ongeveer evenveel leren. Daarnaast noemt DGA het ook zorgelijk dat sites als Marktplaats in de lijst staan, omdat gebruikers daar bijvoorbeeld hun telefoonnummer op achterlaten. "Die informatie is of was weliswaar publiekelijk beschikbaar, maar nooit eerder werden zoveel gegevens op deze manier aan elkaar gekoppeld – door een systeem dat er ook nog eens van wil leren en er nieuwe teksten van maakt."
De Groene Amsterdammer zegt dat Nederlandse sites slechter gefilterd worden dan Engelse sites omdat ze vooral dienen als 'bijvangst' voor de Amerikaanse chatbots. Slechte kwaliteit in Nederlandse teksten zou door het kwaliteitsfilter amper herkend worden.
Eerder deed The Washington Post een soortgelijk onderzoek naar Engelstalige websites. Ook bij dit onderzoek werd gebruikgemaakt van de mC4-dataset. Hieruit bleek dat patents.google.com de grootste site was, gevolgd door de Engelse Wikipedia en scribd.com. Ook zaten er sites in de top 100 die een database met kiezersgegevens hosten, evenals propagandawebsites als het Russische RT.com en de extreemrechtse vdare.com.

/i/2004612784.png?f=fpa)
:strip_exif()/i/2004675778.jpeg?f=fpa)
:strip_exif()/i/2006076688.jpeg?f=fpa)
:strip_exif()/i/2006018352.jpeg?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
:strip_exif()/i/2005393580.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2005547492.jpeg?f=fpa)
/u/152942/crop687206d7bca78.png?f=community)
/u/85941/crop61dd9b39bb021_cropped.png?f=community)
:strip_icc():strip_exif()/u/63255/crop62861790abf81_cropped.jpg?f=community)
/u/111174/sachiel-small.png?f=community)
/u/1163076/crop63497384c28ad_cropped.png?f=community)
:strip_icc():strip_exif()/u/637028/crop6a3e22601b0f7_cropped.jpg?f=community)
:strip_exif()/u/2395/tweakers_forum.gif?f=community)
:strip_icc():strip_exif()/u/88719/crop624ccd84437db_cropped.jpg?f=community)
/u/214894/crop5baaa31f9c4ff_cropped.png?f=community)
:strip_icc():strip_exif()/u/432714/crop6287e94322cf6_cropped.jpg?f=community)
:strip_exif()/u/30814/newgot.gif?f=community)
/u/237439/cloudy-small-orange.png?f=community)
:strip_icc():strip_exif()/u/134130/crop656d9955ccc54.jpg?f=community)
/u/331792/crop624db22e81684_cropped.png?f=community)
/u/268967/crop5e8a0fac1d139.png?f=community)
:strip_exif()/u/119419/candc-60px.gif?f=community)
/u/12436/p1_normal.png?f=community)
/u/27299/hoofd.png?f=community)