In dit artikel bespreken we de opkomst van chiplets en multichipmodules. We gaan onder andere in op wat chiplets zijn en welke voordelen kleine chips met zich meebrengen. Ook bespreken we de manieren waarop fabrikanten chiplets met elkaar verbinden en gaan we in op huidige en toekomstige chipletontwikkelingen, waaronder mcm-gpu's, Intels chipletstrategie en UCIe, een universele standaard voor het verbinden van chiplets.
Al decennialang groeit het aantal transistors dat in een chip-die gestopt kan worden. De Wet van Moore stelt sinds 1965 dat dit aantal iedere twee jaar verdubbelt, met snellere en efficiëntere chips als gevolg. Naarmate transistors steeds verder krimpen en productieprocessen geavanceerder worden, neemt dat tempo echter af. De productie wordt complexer en de ontwikkeltijd en -kosten van nieuwe nodes nemen toe, terwijl ook de vraag naar rekenkracht toeneemt.
Vanwege de vertraging zijn bedrijven op zoek naar alternatieve manieren om de rekenkracht van hun chips op te schroeven. De industrie lijkt zich daarom in een nieuwe richting te bewegen: naar chiplets en multichipmodules. Waar processorontwerpers voorheen alle aspecten van een chip op een enkele die plaatsten, worden chips nu opgedeeld in kleinere blokjes en vervolgens met elkaar verbonden.
Intels uitspraken over AMD's EPYC-chiplets naast Sapphire Rapids-tiles
Het was AMD dat vijf jaar geleden als een van de eerste bedrijven deze nieuwe aanpak grootschalig inzette, met zijn eerste generatie EPYC-serverprocessors. Die processors bestonden uit vier kleine cpu-chips met ieder maximaal 8 cores, in plaats van een enkele grote cpu-die met 32 cores. In de afgelopen jaren heeft AMD die aanpak verder uitgebreid, door i/o- en cpu-dies te scheiden, extra cache boven op cpu-chiplets te stapelen en zelfs een datacenteraccelerator met twee gpu-dies te produceren.
De rest van de chipsector stapt langzaam maar zeker over op eenzelfde strategie, waarmee we ons aan het startpunt van een chiplettijdperk bevinden. In 2017 zei Intel nog spottend dat AMD's EPYC-processors 'vier aan elkaar gelijmde desktopprocessors' met inconsistente prestaties zijn. Vijf jaar later komt Intel met zijn Sapphire Rapids-cpu's voor servers, bestaande uit vierkleine cpu-chiplets. Apple combineerde onlangs twee M1 Max-chips voor een enkele M1 Ultra-soc en Nvidia maakte zijn NVLink-interconnect geschikt voor chiplets.
Bannerfoto: zf L / Getty Images
Wat zijn chiplets en wat zijn de voordelen?
Traditioneel hebben chips een zogeheten monolithisch ontwerp, waarbij alle verschillende aspecten zijn verwerkt op een enkel plakje silicium, oftewel een die. Denk daarbij aan de cores, de cache, geheugencontrollers, PCIe-lanes en noem maar op. In het verleden was die aanpak prima, maar nu de industrie afstevent op steeds kleinere productieprocessen, stijgen de kosten van grote dies. Daardoor wordt het steeds minder economisch om grote chips te fabriceren.
Chiplets moeten daarvoor een uitkomst bieden. De naam doet het al vermoeden; chiplets zijn kleine chips die specifiek zijn ontworpen om samen te werken met andere kleine chips en gezamenlijk een complex geheel te vormen. Chips worden daarmee dus in kleinere 'blokjes' opgedeeld en met elkaar verbonden, waarna ze functioneren als één chip.
Betere yields, lagere kosten
Die aanpak heeft verschillende voordelen. Chiplets moeten onder meer de yields bij halfgeleiderproductie verbeteren. Chips worden gemaakt op plakken silicium, ofwel wafers. Zo'n wafer wordt opgedeeld in verschillende dies, die vervolgens worden losgesneden en verwerkt in daadwerkelijk bruikbare chips. Tijdens halfgeleiderproductie kunnen kleine productiefoutjes ontstaan op een wafer. Bij het produceren van grote dies is de kans dat ergens op de die zo'n foutje ontstaat, relatief groot. Bij zo'n productiefoutje bestaat bovendien de kans dat de volledige die moet worden weggegooid. Hoe groter de die, hoe groter het gedeelte van de wafer dat dan moet worden afgeschreven.
Een deel van die defecten wordt al opgevangen, bijvoorbeeld door redundancy in te bouwen of door chips als minder krachtige modellen te verkopen, bijvoorbeeld met minder cores of lagere kloksnelheden. Bij chiplets wordt dat risico op productieproblemen verder verkleind. Als de dies fysiek kleiner zijn, geldt dat ook voor het gedeelte dat fabrikanten bij een fout moeten weggooien. Dat is dus economischer.
Betere yields met kleinere dies. De rode stippen zijn productiefoutjes. Afbeelding door Shigeru23, Cepheiden, via WikiMedia Commons. Licentie onder CC-BY-SA 3.0
Schaalbaarheid, flexibiliteit en nadelen
Chiplets moeten ook schaalbaarder zijn. Monolithische chips, zeker gpu's, zijn in de afgelopen jaren steeds groter geworden. Kijk bijvoorbeeld naar Nvidia, met datacenter-gpu's die boven de 800mm² liggen. Fabrikanten lopen daarbij tegen een reticle limit van 26x33mm aan, wat neerkomt op een maximale diegrootte van 858mm². Zo'n reticle limit is de maximale grootte van een masker waarmee een wafer belicht kan worden tijdens de lithografiestap van chipproductie. Daarmee vormt de reticle limit de praktische limiet van een die-grootte. Met de volgende generatie High NA-euv-machines van ASML wordt overgestapt op een anamorfische lens, waarmee de reticle limit wordt ingeperkt tot 26x16,5mm, of 429mm².
Fabrikanten kunnen dat omzeilen via stitching, waarbij twee maskers gecombineerd worden, maar maskers zijn duur en de uitlijning is lastig. Chiplets zijn een praktischere optie om die limieten te omzeilen, aangezien daarbij verscheidene kleine chips gecombineerd worden, is het produceren van grotere chips niet meer nodig.
Daarnaast maken chiplets het mogelijk om verschillende procedés met elkaar te combineren op een enkele chip. Zo kunnen bepaalde chiplets geproduceerd worden op cutting-edge nodes, bijvoorbeeld onder de 7nm, terwijl andere onderdelen op een ouder procedé gemaakt kunnen worden, wat de kosten kan verlagen. In het verlengde daarvan kunnen chiplets ook beperkt worden tot een specifieke functie. Waar monolithische chips bijvoorbeeld cpu-cores, een geïntegreerde gpu, geheugencontrollers en PCIe-lanes bevatten, kunnen die elementen met chiplets worden opgedeeld in losse blokjes.
Er zijn overigens ook nadelen. Chiplets zijn uiteraard van elkaar gescheiden, terwijl alle onderdelen van een monolithische chip tegen elkaar aan zitten. Dat beperkt onder meer de bandbreedte ten opzichte van on-die-verbindingen. Die extra onderlinge afstand tussen chiplets brengt ook extra latency met zich mee. Off-die-verbindingen verbruiken daarbij meer stroom en produceren meer warmte.
Chiplets verpakken: substraten, interposers en 3d-stapels
Chiplets brengen nog een extra uitdaging met zich mee. Ze moeten natuurlijk met elkaar verbonden worden om te kunnen samenwerken. Dat gebeurt tijdens het packaging-proces, een van de laatste stappen in het chipproductieproces, waarbij de verschillende dies verpakt worden in een daadwerkelijk functionerende chip. Het is daarbij zaak om chips te verbinden met zoveel mogelijk bandbreedte en zo weinig mogelijk latency en stroomverbruik. Fabrikanten hebben daar verschillende opties voor.
2,5d-packaging met interposers en fan-outs
Allereerst is er de traditionele en relatief simpele vorm: 2d-packaging. Daarbij wordt een chip-die direct op een substraat geplaatst. Zo'n substraat verbindt de chips met de printplaten waarop ze uiteindelijk worden verpakt. Fabrikanten kunnen de benodigde links door zo'n substraat laten lopen om chiplets onderling te verbinden. Fabrikanten komen echter met steeds geavanceerdere opties om de eerdergenoemde nadelen van chiplets te beperken: latency, stroomverbruik en bandbreedte. Backendfabrikanten komen daarvoor met de opties 2,5d- en 3d-packaging, ieder met verschillende implementaties.
Bij de 2,5d-optie worden de chiplets bijvoorbeeld met microbumps naast elkaar op een zogeheten interposer gezet, die op zijn beurt boven op het substraat wordt geplaatst. Deze interposer is in de praktijk een grote plak silicium die functioneert als een soort brug tussen chips. Door die interposer lopen de benodigde schakelingen om de chiplets met elkaar verbinden. Een voordeel van deze vorm van packagen is de hogere bandbreedte ten opzichte van 2d-packaging, omdat de verbindingsdichtheid van microbumps op interposers hoger ligt dan die van verbindingen op een substraat. Ook kunnen chiplets met een interposer relatief dicht op elkaar geplaatst worden, wat de latency en warmteproductie van de verbindingen beperkt. Verschillende fabrikanten bieden packaging met interposers. Chipmaker TSMC biedt dit bijvoorbeeld aan onder de noemer Chip-on-Wafer-on-Substrate, oftewel CoWoS. De Taiwanese fabrikant biedt daarbij verschillende versies aan, met verschillende soorten interposers.
Daarnaast is er fan-out-packaging. Daarbij worden twee chip-dies volledig ingesloten in een materiaal zoals epoxy. Die epoxy functioneert als een soort package waar verbindingen doorheen kunnen lopen. Dat maakt het mogelijk om i/o-verbindingen buiten het chipoppervlak 'uit te waaieren' en de twee chips met elkaar te verbinden. TSMC biedt daar bijvoorbeeld InFO voor, oftewel Integrated Fan-Out. Die techniek kan gebruikt worden om chips horizontaal te verbinden, maar ook om chips te stapelen, waarop we straks verder ingaan.
TSMC's CoWoS-techniek met een silicium interposer. Bron: TSMC
TSMC InFO-on-substraat (links) en InFO-Package-on-Package. Bron: TSMC
Kleine 'bruggetjes': EMIB en LSI
Het is ook mogelijk om chiplets te verbinden met kleinere plakjes silicium, die als een soort brug tussen twee dies functioneren. Zo heeft Intel een 2,5d-packagingtechniek genaamd EMIB, oftewel Embedded Multi-Die Interconnect Bridge. De fabrikant maakt daarbij geen gebruik van een grote interposer. In plaats daarvan worden de dies direct op het eerdergenoemde substraat geplaatst. Intel verwerkt daarbij diverse van die kleinere 'bruggetjes' in het substraat zelf, die tussen twee chiplets geplaatst kunnen worden. Volgens Intel is dat in theorie goedkoper en leidt het tot betere yields, want ook bij interposers van silicium kunnen productiefoutjes ontstaan. Intel claimt ook dat EMIB op deze manier schaalbaarder is dan interposers. Er zijn grenzen aan de grootte van een interposer, terwijl EMIB-bruggetjes in theorie onbeperkt kunnen worden ingezet.
In 2020 presenteerde TSMC zijn eigen EMIB-tegenhanger, in de vorm van Local Silicon Interposers. TSMC's LSI is gebaseerd op soortgelijke stukjes silicium. Die worden overigens boven op het substraat geplaatst, terwijl EMIB juist in het substraat wordt verwerkt. Het bedrijf biedt de optie voor zulke 'lokale siliciuminterposers' voor zijn eerdergenoemde InFO en CoWoS-packagingtechnieken.
AMD lijkt LSI al in te zetten voor zijn Instinct MI200-serie. Die datacenter-gpu's maken gebruik van een zogeheten Elevated Fanout Bridge, die ook boven op het substraat geplaatst wordt. Het diagram daarvan toont grote gelijkenissen met InFO-LSI. AMD bevestigt echter niet dat TSMC de gpu's op deze manier verpakt; het is ook mogelijk dat een andere partij de packaging van deze gpu's op zich neemt.
Een andere optie is 3d-packaging. Zoals de term doet vermoeden, worden chips daarbij driedimensionaal geplaatst, of boven op elkaar gestapeld. Dat bespaart ruimte en de onderlinge afstand tussen de dies wordt verder beperkt. Stapelen gebeurt al langer met zaken als geheugen. Aanvankelijk werden geheugenstapels daarvoor verbonden met gouden draadjes die langs de zijkanten van de dies liepen, en later met through-silicon via's, een soort verbindingen die dwars door de dies heen lopen. Tegenwoordig kijken fabrikanten echter ook naar het stapelen van chiplets en complexere chips.
Intel introduceert daarvoor Foveros. Daarbij plaatst het bedrijf twee dies op elkaar. In de praktijk gebruikt Intel daarvoor nog steeds een interposer, net als bij 2,5d-packaging. Het verschil is echter dat de interposer bij Foveros 'actief' is, wat betekent dat hij functioneert als een daadwerkelijke chip. Die interposer kan bijvoorbeeld i/o-elementen als USB- of PCIe-controllers bevatten. Het bedrijf gebruikt een groot aantal kleine microbumps met een onderlinge afstand van 50 tot 36 micron om deze chips verticaal met elkaar te verbinden.
Overigens is Intel al bezig met nieuwere generaties Foveros: Foveros Omni en Direct, die onder meer een kleinere bump pitch mogelijk moeten maken. Dergelijke kleinere bump pitches maken een hogere dichtheid voor de interconnect mogelijk. Foveros is verder niet per se een vervanger voor het eerdergenoemde EMIB; die twee technieken kunnen ook met elkaar gecombineerd worden, bijvoorbeeld om verscheidene met Foveros gestapelde chips met elkaar te verbinden.
Ook TSMC biedt een optie voor verticale 3d-packaging, in de vorm van SoIC, oftewel System of Integrated Chips. Het voordeel van die techniek is dat TSMC daarvoor geen microbumps hoeft te gebruiken. In plaats daarvan is SoIC gebaseerd op hybrid bonding, waarbij de verschillende plakjes silicium bijna direct op elkaar worden gezet en met elkaar worden verbonden door middel van koperen interconnects met een pitch van 9 micron. SoIC van TSMC levert onder meer een kleinere afstand tussen de verschillende chips op, wat volgens TSMC een aanzienlijk hogere bandbreedte oplevert. Het bedrijf stelt dat SoIC '10 keer zo snel' is en '190 keer zoveel bandbreedte' heeft als 3d-packaging met microbumps. Het moet ook de koelprestaties verbeteren; TSMC stelt dat de thermische weerstand van SoIC tot 35 procent lager is dan die van een 3d-verpakking met microbumps. Net als Foveros en EMIB, kunnen ook TSMC's SoIC en CoWoS gecombineerd worden om verscheidene 3d-chiplets met elkaar te verbinden.
Huidige chiplet- en multichipproducten
De afgelopen vijf jaar hebben aangetoond dat chiplets in opkomst zijn. Uiteraard heeft AMD daar een behoorlijke rol in gespeeld met de introductie van zijn eerste EPYC-processors in 2017, die beschikten over vier losse cpu-chiplets met ieder 8 cores. Sinds 2019 gaat AMD daarin een stapje verder, zowel in zijn enterpriseprocessors als in zijn consumenten-cpu's.
AMD Zen: chiplets voor cpu en i/o
Vanaf de Zen 2-architectuur en de bijbehorende EPYC Rome- en Ryzen 3000-cpu's deelt AMD namelijk zijn processors op in chiplets met cpu-cores en L3-cache, en een losse i/o-die. Daarin worden onder meer PCIe-lanes en geheugenkanalen verwerkt. Dat heeft als voordeel dat de cpu-chiplets gemaakt kunnen worden met een geavanceerder productieproces, wat leidt tot hogere kloksnelheden en lagere spanningen. Bij de i/o-die letten de prestaties minder nauw. Die dies worden daarom gemaakt op een oudere 12- of 14nm-node, wat de complexiteit en productiekosten beperkt.
Rome is niet in één dag gebouwd, EPYC Rome ook niet: EPYC 7001 (Naples) en EPYC 7002 (Rome) naast elkaar
Deze chiplets communiceren met elkaar via AMD's eigen Infinity Fabric-protocol. Opvallend is dat AMD de verbindingen daarvoor direct op een substraat plaatst en dus geen geavanceerdere packagingtechnieken zoals interposers inzet. Dat terwijl AMD als een van de eerste bedrijven interposers commercieel inzette om zijn Radeon R9 Fury-gpu's te verbinden met HBM-geheugenstapels.
AMD verduidelijkt die keuze in een researchpaper die door de chipontwerper tijdens ISCA 2021 werd gepresenteerd. Het bedrijf schrijft daarin dat het heeft gekozen voor routing op het substraat, omdat de communicatie-eisen van zijn EPYC- en Ryzen-chiplets relatief bescheiden zijn. Point-to-pointlinks op het substraat zijn meer dan voldoende voor de benodigde bandbreedte, schrijft AMD. Het bedrijf zegt ook dat de maximale lengte van de interposerverbindingen beperkt is en dat de chiplets daarom dicht op elkaar geplaatst moeten worden. Voor bandbreedte en stroomverbruik is dat gunstig, maar wat ruimte betreft in dit geval niet. Als AMD een interposer zou inzetten, zouden daar maximaal vier Ryzen-ccd's en een i/o-die op passen. De recentste EPYC-cpu-generaties hebben acht ccd's en een i/o-die op het substraat.
AMD scheidt sinds Zen 2 zijn cpu-chiplets en i/o-die.
Intel: Kaby Lake-G, Lakefield en fpga's
Intel Kaby Lake-G met Radeon-gpu (links) en cpu-chip
Ook Intel is geen vreemde met chiplets, hoewel dat bedrijf vooralsnog vooral monolithische chips bakt. In het verleden introduceerde die fabrikant bijvoorbeeld een serie van zes Kaby Lake-G-laptopprocessors. Die chips combineerden een cpu-chip met een losse gpu, opvallend genoeg een Radeon RX Vega-gpu van AMD. Ze behoorden bovendien tot de eerste producten waarvoor Intel zijn EMIB-verbinding inzette. Kaby Lake-G bleek echter geen succes; in de praktijk werden de chips in slechts een beperkt aantal laptops gebruikt. In 2019 liet Intel dan ook weten dat het alle zes de Kaby Lake-G-cpu's met pensioen zou sturen.
Het bedrijf maakte ooit ook een geïntegreerde Iris Pro 5200-gpu, die werd gebruikt in bepaalde Haswell-laptopprocessors. Daarbij combineerde Intel een geïntegreerde gpu met een stapel van 128MB aan 'eDRAM', wat neerkwam op L4-cache. Daarop werden bijvoorbeeld cpu- en gpu-requests gecachet. Die cachestapel werd op dezelfde package als de chip geplaatst, maar was niet on-die. Het bedrijf noemde dat Crystalwell. Het gaf daarbij weinig details over de verbinding tussen de cache en de chip, maar zei wel dat de verbinding goed was voor 50GB/s aan bidirectionele bandbreedte.
Intel Lakefield
Intel bracht in 2019 ook Lakefield uit, een van de eerste commercieel beschikbare, 'gestapelde' processors die gebruikmaakten van de eerdergenoemde Foveros-packagingtechniek. De package van die chip bestond uit een base-die, die werd geproduceerd op 22nm. Die basislaag functioneert als interposer, maar beschikt bijvoorbeeld ook over i/o-elementen zoals PCIe- en USB-controllers. Via eentussenlaag van microbumps werd daarbovenop een 10nm-compute-chip geplaatst, met daarop onder meer verschillende cpu-cores, Lpddr4-geheugen en een geïntegreerde gpu. Ook Lakefield werd echter geen succes en is inmiddels uit de handel gehaald.
Daarbij produceert Intel ook nog bepaalde fpga's die kunnen bestaan uit verscheidene chiplets. De Stratix 10-fpga's hebben bijvoorbeeld een chipletontwerp. Die fpga's bestaan uit een monolithisch fpga-blok dat via EMIB kan worden uitgebreid met transceivers of controllerchiplets voor zaken als PCIe en ethernet.
Apple: M1 Ultra met UltraFusion-interconnect
Onlangs kwam ook Apple met een soort soc met verscheidene chips. De M1 Ultra-soc die het bedrijf introduceerde in de Mac Studio, bestaat als het ware uit twee losse M1 Max-processors, die op zichzelf grote, monolithische chips zijn. Die twee chips zijn via een eigen die-to-die-interconnect met elkaar verbonden en functioneren als een enkele chip. Apple schrijft dat de M1 Max-dies aan elkaar verbonden worden met een interposer waar 10.000 die-to-dieverbindingen doorheen lopen. In een video lijkt het echter dat Apple gebruikmaakt van een kleinere brug van silicium, zoals EMIB, LSI of EFB.
Apples UltraFusion-interconnect
Deze interconnect is volgens Apple goed voor een bandbreedte van 2,5TB/s tussen de twee chips. Het is niet duidelijk of dit geaggregeerde cijfers zijn, wat zou betekenen dat bandbreedte in beide richtingen bij elkaar is opgeteld. Zelfs dan zou het erop neerkomen dat Apple een bandbreedte van 1,25TB/s in beide richtingen heeft, wat in de buurt komt van de bandbreedte van verbindingen in monolithische chips. Apple noemt deze interconnect 'UltraFusion' en zegt dan ook dat deze aanpak zo snel is dat er geen merkbaar verschil is met monolithische chips.
Het zal duidelijk zijn dat de M1 Ultra van Apple een enorme chip is. Tijdens een teardown bleek dat de package van de M1 Ultra ongeveer drie keer zo groot is als die van een Ryzen-cpu en daarmee eerder overeenkomt met het formaat van een EPYC-processor. Dat is overigens inclusief geïntegreerd systeemgeheugen; bij Zen-cpu's worden uiteraard losse DDR4-dimms gebruikt.
Apples M1 Ultra naast andere Apple Silicon-chips
De (nabije) toekomst: multichip-gpu's, Intel-tiles en chipletstandaarden
AMD komt eind dit jaar met Ryzen 7000 op basis van Zen 4, waarmee eveneens een einde komt aan het AM4-platform dat sinds 2017 bestaat. Die chips stappen daarmee over op LGA-socket AM5, worden geproduceerd op TSMC's 5nm-procedé en zullen AMD's chipletstrategie doorzetten. Meer is nog amper bekend; vermoedelijk deelt AMD in de komende maanden meer details, aangezien Zen 4 al in de planning staat voor de tweede helft van 2022.
Gestapelde L3-cache
Tijdens de CES-beurs heeft AMD al wel een tipje van de sluier opgelicht over Zen 4 en onlangs demonstreerde het ook nieuwe packaginginnovaties met zijn Ryzen 7 5800X3D- en EPYC Milan-X-cpu's met 3D V-Cache, waarover Tweakers eerder een achtergrondverhaal heeft gepubliceerd. Bij die chips stapelt AMD extra L3-cache boven op zijn cpu-chiplets. Daarvoor gebruikt het bedrijf hybrid bonding en TSMC's SoIC-techniek, wat volgens het bedrijf een bandbreedte van 2TB/s tussen de 3D V-Cache en de cpu-die oplevert.
Langs die weg kan iedere Zen-ccd beschikken over 96MB L3-cache. EPYC-cpu's met acht ccd's hebben daarmee 768MB aan L3-cache op een enkele cpu. Het is overigens nog niet bekend of AMD die techniek doorzet in zijn komende Zen 4-cpu's. AMD noemde X3D-packaging in 2020 al wel als de volgende grote stap na chiplets, wat doet vermoeden dat het bedrijf dat in de toekomst breder gaat inzetten.
RDNA3 en multichip-gpu's
AMD breidt zijn chipletstrategie overigens ook uit naar nieuwe productgroepen. Het bedrijf komt bijvoorbeeld met zogeheten multichipmodules voor zijn videokaarten. Het eerste voorbeeld bestaat al sinds eind vorig jaar, in de vorm van AMD's Instinct MI200-serie voor datacenters en hpc. Die videokaarten bestaan in feite uit twee identieke, losse 6nm-gpu's met ieder 110 compute-units en HBM-geheugen die met elkaar zijn verbonden. Daarmee functioneren de twee gpu's samen als een geheel met 110 cu's. De gpu's gebruiken daarvoor een derdegeneratie-Infinity Fabric. De links daarvoor zijn verwerkt in de eerdergenoemde EMIB-achtige Elevated Fanout Bridges.
Het lijkt erop dat AMD die aanpak dit jaar doorzet naar videokaarten voor consumenten. Er gaan al maanden geruchten dat enkele AMD Radeon RDNA 3-videokaarten ook een mcm-ontwerp krijgen. De hoogst gepositioneerde Navi 31- en Navi 32-gpu's zouden daarbij een multichiplay-out krijgen, terwijl lager gepositioneerde modellen een monolithisch ontwerp houden. Ook dit is echter nog niet officieel bevestigd. De RDNA 3-architectuur staat voor dit jaar in de planning, maar een exacte releasedatum is er nog niet.
AMD's Instinct MI200-serie bestaat uit twee CDNA 2-gpu's, ieder met vier stapels HBM2e-geheugen.
Intel: chiplettiles en Ponte Vecchio
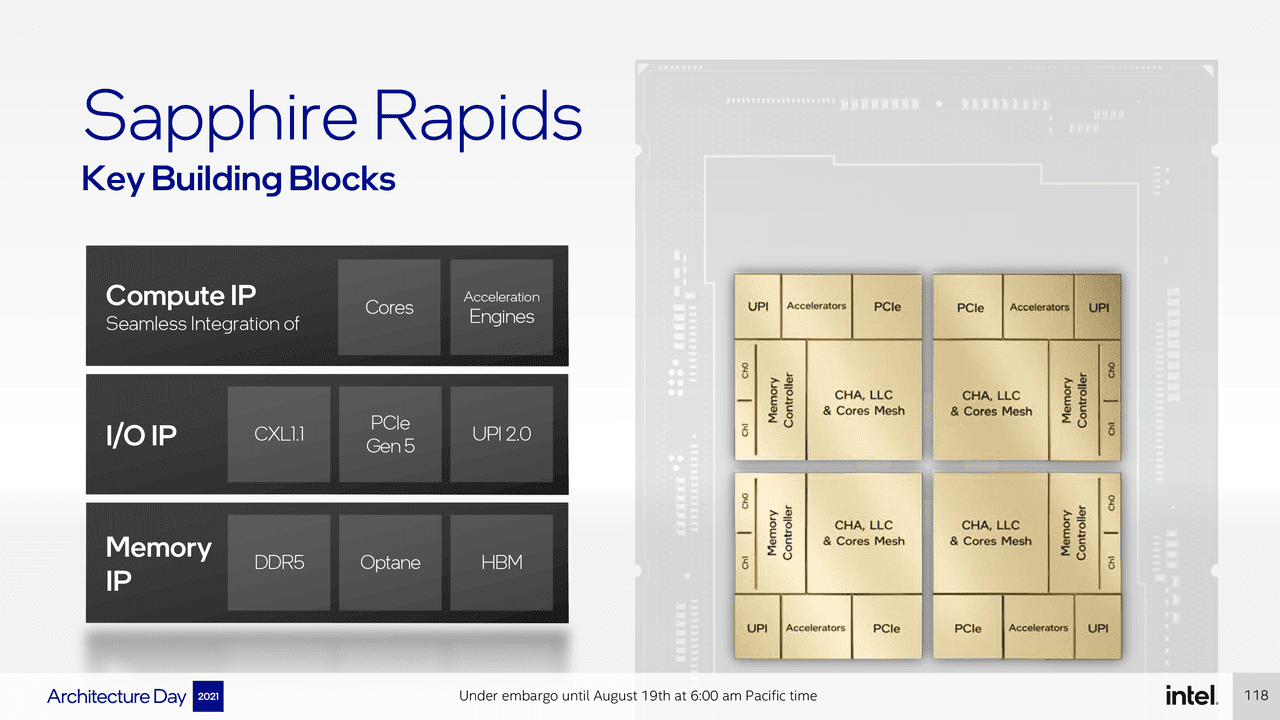
Intel Sapphire Rapids
In de nabije toekomst gaat ook Intel op grotere schaal inzetten op chiplets en multichipmodules, hoewel die nog vooral bedoeld zijn voor enterprise en hpc. Zo komt het bedrijf met Sapphire Rapids-processors, die worden uitgebracht in Intels Xeon-line-up. Deze serverchips krijgen eveneens een chipletachtig ontwerp. Waar Intel eerder spottend zei dat AMD's eerstegeneratie-EPYC-processors vier 'aan elkaar gelijmde' desktopprocessors zijn, bestaat ook Sapphire Rapids uit vier tiles die allemaal dezelfde opbouw hebben. In dat opzicht bestaat dat platform eigenlijk uit vier monolithische chips met ieder 14 cores, die door middel van EMIB met elkaar zijn verbonden.
Intel Meteor Lake
Intels huidige consumenten-cpu's blijven nog even monolithisch. Dit jaar komt Raptor Lake uit, een verbeterde versie van Alder Lake met meer E-cores. Voor volgend jaar staat echter Meteor Lake op de roadmap. Dat worden Intels eerste consumentenchips die bestaan uit chiplets. Zo krijgt Meteor Lake een compute-tile waarin de cpu-cores zitten die op het Intel 4-procedé worden gemaakt. Die chip wordt aangevuld met een gpu-tile met 96 tot 192 execution-units en een soc-lp-chiplet met PCIe-lanes, geheugencontrollers en overige i/o-elementen. Intel zegt dat die tiles geproduceerd worden op andere nodes. Daarmee is de opbouw van Meteor Lake vergelijkbaar met de ontwerpen die AMD inzet sinds Zen 2, met cpu-chiplets en een losse i/o-die. Voor het verpakken van de Meteor Lake-processors gaat Intel de tweede generatie van zijn Foveros-technologie voor het stapelen van chips gebruiken.
Dit jaar komt Intel ook met zijn Ponte Vecchio-gpu. Dat wordt een videokaart voor datacenters en supercomputers die bestaat uit actieve tiles. De gpu is daarbij bijvoorbeeld opgebouwd uit compute-tiles die gemaakt worden op TSMC's N5-node, Xe-Link-tiles die gemaakt worden op TSMC N7, terwijl cache- en Foveros-basechiplets gemaakt worden op Intel 7. Het geheel wordt met elkaar verbonden door middel van een combinatie van Foveros en EMIB, zegt Intel. Het is niet bekend of Intel in de toekomst losse consumenten-gpu's met chiplets gaat maken. Bij de eerste generatie Arc-gpu's is dat in ieder geval niet zo.
Nvidia gaat verder met monolithische chips, maar introduceert ook NVLink-C2C
Nvidia lijkt zich vooralsnog te richten op grote chips. Er gingen maandenlang geruchten rond dat Hopper, de opvolger van Nvidia's Ampere-architectuur voor datacenters, een mcm-ontwerp met verschillende gpu-dies zou krijgen. Afgelopen dinsdag kondigde het bedrijf zijn eerste Hopper-gpu aan, in de vorm van de Nvidia H100. Dat betrof echter een grote monolithische 4nm-chip met 80 miljard transistors en een oppervlakte van 814mm².
Volgens geruchten komt Nvidia nog met een GH202-gpu. Dat zouden in wezen twee losse H100-gpu's zijn, die met elkaar zijn verbonden via iets als NVLink, Nvidia's gpu-naar-gpu-interconnect. Die aanpak zou overeenkomen met bijvoorbeeld AMD's Instinct MI200-serie, maar ook met de eerdergenoemde Apple M1 Ultra. Nvidia presenteerde die vermeende GH202 echter niet tijdens zijn GTC 2022-keynote. Misschien introduceert het bedrijf die variant later, maar dat blijft voorlopig speculatie.
Nvidia's monolithische Hopper H100-gpu
Ook Nvidia's komende Lovelace-architectuur voor nieuwe GeForce RTX-videokaarten blijft naar verwachting monolithisch. Over een paar jaar komt Nvidia met Blackwell, de opvolger van Hopper. Dat blijkt uit een lek van hackergroep Lapsus$. Ook over deze gpu's wordt gespeculeerd dat ze bestaan uit verschillende gpu-dies, maar ook dat is nog onbevestigd.
Nvidia gaat overigens wel chips op andere manieren combineren. Het bedrijf kondigde onlangs zijn Grace CPU Superchip aan, die in de eerste helft van 2023 moet verschijnen. De Grace CPU Superchip is een datacenterchip waarop twee losse cpu-packages zitten, met in totaal 144 Arm-v9-cores. Dat wordt gecombineerd met Lpddr5x-geheugen met ecc en een geheugenbandbreedte van 1TB/s. Het bedrijf komt daarnaast met een variant met Grace-cpu en Hopper-gpu. Het gaat daarbij dus niet om chiplets of multichipmodules, aangezien het volledig losstaande packages betreft. Om die losse processors te verbinden, gebruikt het bedrijf een nieuwe variant van zijn NVLink-interconnect, genaamd NVLink-C2C. Nvidia geeft daarbij overigens specifiek aan dat deze NVLink-variant geschikt is voor die-to-dieverbindingen via interposers of andere geavanceerde packagingtechnieken. In het verlengde daarvan stelt Nvidia zijn NVLink-C2C beschikbaar aan andere bedrijven, zodat ze hun chiplets kunnen integreren met Nvidia's gpu's, dpu's en cpu's.
Nvidia's Grace CPU Superchip (links) en zijn NVLink-C2C-interconnect
De weg naar een universele chipletstandaard: UCIe
Dat is een van de voordelen van chiplets: de mogelijkheid om verschillende chiplets met elkaar te combineren binnen een enkele package. In dat opzicht is er echter veel fragmentatie op de chipletmarkt; in plaats van te standaardiseren maken veel fabrikanten hun eigen interconnects. Kijk naar AMD met Infinity Fabric, Nvidia met NVLink-C2C en Apple met UltraFusion. Nu de chipletmarkt echter volwassen is en chiplets grootschalig worden ingezet, groeit de behoefte aan een open chipletstandaard.
Begin dit jaar kwamen veel chipbedrijven daarom met een specificatie om chiplets met elkaar te verbinden. De bedrijven noemen dit Universal Chiplet Interconnect Express, oftewel UCIe. Het doel daarvan is om een reeks standaarden te hebben die het productieproces versimpelen en volledige interoperability tussen chiplets van verschillende fabrikanten mogelijk maken. Daarmee zou UCIe de weg vrijmaken voor een soort chipletecosysteem voor chipmakers, net als andere open standaarden zoals PCIe en USB.
Een mooi streven en gezien de partijen die UCIe steunen, niet onrealistisch. Met Intel, Samsung en TSMC krijgt de standaard steun van alle drie de grote foundries, en met AMD, Arm en Qualcomm scharen ook vrijwel alle grote processorontwerpers zich achter UCIe. Nvidia werd niet genoemd bij de aankondiging, maar gaf deze week aan dat het eveneens meewerkt aan UCIe, terwijl het ook zijn eigen NVLink-C2C pusht. ASE Group, de grootste OSAT-foundry die zich puur richt op packaging en het testen van chips, voegt zich ook bij het UCIe-consortium. Daarnaast steunen hyperscalers zoals Google Cloud, Meta en Microsoft het initiatief.
Vanuit de industrie is er grote steun voor UCIe, dus de toekomst ziet er rooskleurig uit voor dit protocol. Het is overigens nog niet bekend hoe en wanneer de bedrijven UCIe gaan implementeren in hun producten, maar versie 1.0 van de specificatie is al af, dus het wordt vermoedelijk binnen enkele jaren ingezet.
De eerste specificatie van UCIe is grotendeels gedoneerd door Intel en bouwt verder op de PCIe- en CXL-protocollen. De standaard ondersteunt daarbij 2d-packaging en 2,5d-packaging met interposers, siliciumbridges als EMIB of fan-outs. Ondersteuning voor 3d-packaging is er nog niet, maar een latere versie van UCIe moet dat toevoegen. UCIe kan overigens gebruikt worden naast andere, gespecialiseerdere interconnects, zoals Infinity Fabric en NVLink. Chipmakers kunnen hun eigen protocollen gebruiken terwijl ze UCIe-compliant blijven. Uiteraard moeten de verbonden chiplets beide zo'n aangepast protocol ondersteunen. Op maat gemaakte interconnects zullen dus niet volledig verdwijnen, maar met UCIe wordt in ieder geval de basis gelegd voor een mooie toekomst met een open chipletecosysteem.
Leuk artikel! Afgelopen week had ik toevallig al een vergelijkbaar stuk gelezen over UCIe op Anandtech. De vraagtekens die ik daarbij had tijdens het lezen (wegens mijn gebrekkige kennis over chipdesign) worden hier mooi beantwoord, wat dit artikel op Tweakers voor mij betreft een stuk leesbaarder maakt.
Ik ben ook heel nieuwsgierig hoe deze ontwikkeling zich in de toekomst zal vertalen. Ik zie wel een markt voor bedrijven die zelf geen chiplets maken maar deze kopen van Intel, AMD etc. en de eindgebruiker in staat stellen om tientallen, misschien wel honderden verschillende configuraties te bestellen. Een scheiding van de chipmaker en degene die de assemblage en packaging doet zeg maar.
Amazon bijvoorbeeld gebruikt voor hun Graviton 3 chips een ontwerp van Amazon zelf op een instructie-set van ARM, vervolgens produceert TSMC de chiplets maar Intel doet het verpakken (EMIB) en testen.
AMD geeft sinds kort hun video kaart als ontwerp in licentie aan Samsung. Samsung maakt die Radeon chiplets op Samsung N4 (qua dichtheid ongeveer gelijk aan TSMC N6) in eigen fab, terwijl het ontwerp oorspronkelijk voor TSMC N7 was.
Voorlopig is degene die de opdracht voor chiplets en packaging geeft nog wel dezelfde, dus het is nog niet zo dat je losse chiplets van een ander fysiek kan bestellen en zelf combineren. Maar de OSATS zijn al heel lang gescheiden van de chiplets: Op veel Ryzens staat al 'diffused in Taiwan and USA, assembled in Malaysia ". De chiplets zijn van GloFo Malta (New York, 12nm Samsung SoC proces) en TSMC (Hsinchu denk ik, N7 DUV), de assemblage gebeurt in Maleisië, ik geloof dat TSMC daar niet zit dus bij een OSAT*.
Outsourced Assembly & Test bedrijf.
Nvidia bijvoorbeeld maakt gebruik van de OSATs Siliconware Precision (SPIL) en ASE (Taiwan). ASE is dan weer een concurrent in eigen land van TSMC, want TSMC biedt nu heel veel populaire verpakkings-opties aan. Mogelijk gaat Nvidia om politieke redenen meer naar Amkor (VS).
Er is dus heel veel in beweging, en Intel lift mee door met subsidie een verpakkingsbedrijf in Italië te zetten. Mogelijk ook voor andere klanten, dus Intel is nu behalve fab ook een OSAT geworden.
[Reactie gewijzigd door kidde op 23 juli 2024 21:17]
Inderdaad leuk artikel. We doen in NL ook actief mee aan deze ontwikkelingen, zo heeft de Hogeschool van Arnhem en Nijmegen i.s.m. NXP een minor voor bachelor studenten wat hier direct aan raakt: https://www.kiesopmaat.nl/modules/han/-/141472/
Mooi overzichts artikel, had nog wat meer diepgang mogen hebben. Ik ben hier toch op tweakers?
(de feedback-link is nog steeds kapot, ik kom in een overzicht terecht, en niet in het feedback-topic van dit artikel. De link zou bovendien niet alleen bovenaan maar zeker ook onderaan het artikel moeten staan)


:strip_exif()/i/2005002776.jpeg?f=imagegallery)
/i/2004999188.png?f=imagegallery)
:strip_exif()/i/2005002376.jpeg?f=imagegallery)







:strip_exif()/i/2004989622.jpeg?f=imagegallery)
:strip_exif()/i/2005002370.jpeg?f=imagegallery)



:strip_exif()/i/2004999074.jpeg?f=imagegallery)
:strip_exif()/i/2004968514.jpeg?f=imagegallery)
:strip_exif()/i/2004999186.jpeg?f=imagegallery)
:strip_exif()/i/2004776750.jpeg?f=imagegallery)

/i/2004506458.png?f=imagegallery)
/i/2004545136.png?f=imagegallery)
:strip_exif()/i/2004997822.jpeg?f=imagegallery)

:strip_exif()/i/2004999272.jpeg?f=imagegallery)
:strip_exif()/i/2005002780.jpeg?f=imagegallery)


:strip_icc():strip_exif()/i/2007287756.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006702746.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006107804.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005286184.jpeg?f=fpa_thumb)
/i/2004845680.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004394938.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003978744.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003840762.jpeg?f=fpa_thumb)
/i/2003785544.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002421862.jpeg?f=fpa_thumb)
:strip_exif()/i/2005279580.jpeg?f=fpa)
:strip_exif()/i/2006846208.jpeg?f=fpa)
/i/2004919460.png?f=fpa)
/i/2004611214.png?f=fpa)
:strip_exif()/i/2005833550.jpeg?f=fpa)
:strip_exif()/i/2004681518.jpeg?f=fpa)
:strip_exif()/i/2005798502.jpeg?f=fpa)
:strip_exif()/i/2005651656.jpeg?f=fpa)
:strip_exif()/i/2005561046.jpeg?f=fpa)
:strip_exif()/i/2004935626.jpeg?f=fpa)
:strip_exif()/i/2005229388.jpeg?f=fpa)
:strip_exif()/i/2004996836.jpeg?f=fpa)
/i/2004983532.png?f=fpa)
:strip_exif()/i/2004917882.jpeg?f=fpa)
/i/2004781850.png?f=fpa)
/i/2004506454.png?f=fpa)
/i/2001237765.png?f=fpa)
:strip_exif()/i/2004386270.jpeg?f=fpa)
:strip_exif()/i/2003847926.jpeg?f=fpa)
:strip_exif()/i/2001508675.jpeg?f=fpa)
/i/2001665377.png?f=fpa)
/i/2001393753.png?f=fpa)
:strip_icc():strip_exif()/u/238912/crop64a6afe025bc1.jpg?f=community)
/u/186071/crop58bc21e8285fa.png?f=community)
.PNG){kind=link}
_-_Version_2_-_EN.png){kind=link}