Intel deelt volgende maand details over zijn technische roadmap voorbij 2025. Het bedrijf doet dat tijdens zijn IFS Direct Connect-evenement op 21 februari. Het bedrijf deelt dan zijn roadmap voor na de '5N4Y'-planning, die dit jaar eindigt met Intels '1,8nm'-achtige 18A-procedé.
De nieuwe roadmap van Intel wordt gepresenteerd door Ann Kelleher, general manager of technology development bij Intel, zo merkte Tom's Hardware op. Tijdens het Intel Foundry Services Direct Connect-evenement gaat de chipmaker dan in op de periode nadat het 5N4Y-plan is afgerond, wat staat voor 'Five Nodes, Four Years'. Het bedrijf hanteerde die planning sinds 2021, toen ceo Pat Gelsinger aan het hoofd van de chipmaker kwam.
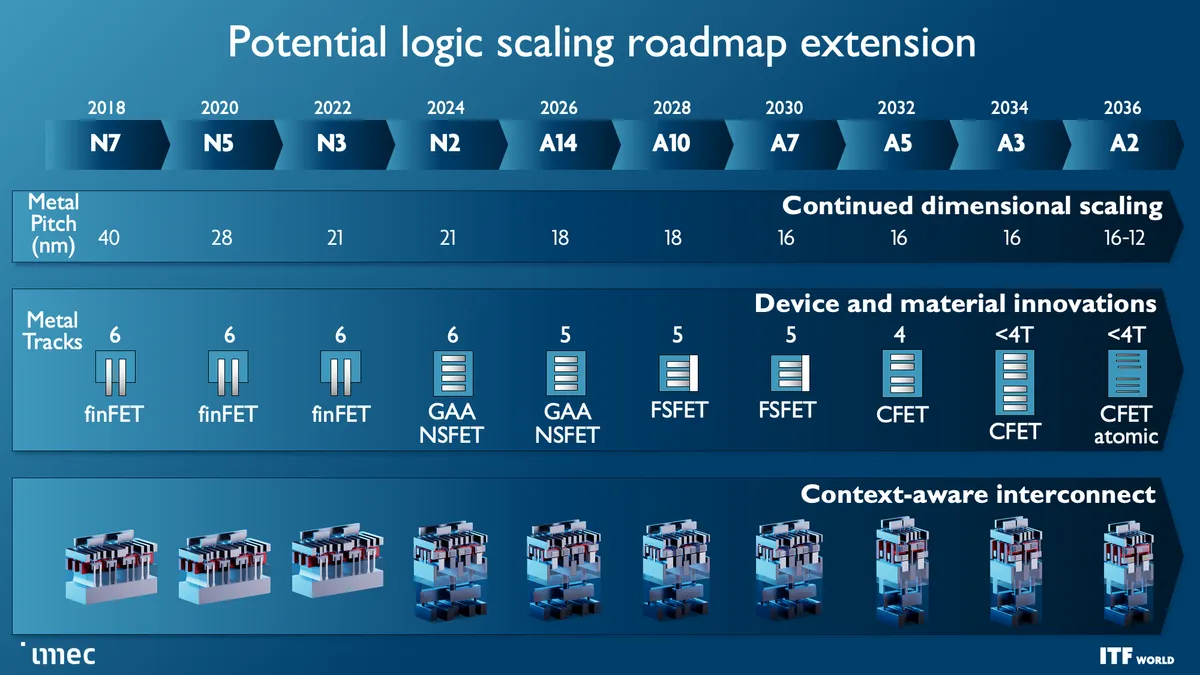
Met 5N4Y wil Intel vijf procedés afleveren in vier jaar tijd, nadat het bedrijf een jarenlange achterstand opbouwde op concurrenten wegens 10nm-problemen. Sinds die tijd kwam het bedrijf met de Intel 7-, Intel 4- en Intel 3-nodes. In 2024 resteren nog Intel 20A en 18A, waarmee de chipmaker overstapt op zogeheten gate-all-aroundtransistors.
Details over de nieuwe roadmap van Intel zijn nog niet bekend. De chipmaker bevestigde eerder aan zogeheten cfet-transistors te werken. Daarmee worden p- en n-type transistors, respectievelijk met een positieve en negatieve lading, boven op elkaar gestapeld voor een hogere dichtheid. Momenteel worden die transistortypen nog naast elkaar geplaatst. Naar verwachting zijn cfet-transistors pas rond 2032 klaar voor massaproductie, zo stelde Leuvens onderzoeksinstituut imec eerder. Waar Intel in de tussentijd aan werkt, is nog niet bekend. Vermoedelijk gaat het bedrijf werken aan zijn gaa-transistors.
:strip_exif()/i/2006343438.jpeg?f=imagegallery)

:strip_icc():strip_exif()/i/2006846190.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005816748.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005286184.jpeg?f=fpa_thumb)
:strip_exif()/i/2007373050.jpeg?f=fpa)
:strip_exif()/i/2007319776.jpeg?f=fpa)
/i/2006468270.png?f=fpa)
/i/2007299570.webp?f=fpa)
:strip_exif()/i/2004681518.jpeg?f=fpa)
/i/2004611214.png?f=fpa)
/i/2006162262.png?f=fpa)
:strip_exif()/i/2006343552.jpeg?f=fpa)
/i/2004781850.png?f=fpa)
:strip_exif()/i/2005833488.jpeg?f=fpa)
:strip_exif()/i/2005833550.jpeg?f=fpa)
:strip_exif()/i/2005835004.jpeg?f=fpa)
:strip_exif()/i/2004753098.jpeg?f=fpa)
:strip_icc():strip_exif()/u/233767/crop5db03cbc075aa.jpeg?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
/u/214894/crop5baaa31f9c4ff_cropped.png?f=community)
/u/246414/crop64732e7f0bf92_cropped.png?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
{kind=link}