
Op dinsdag 23 mei hield TSMC zijn jaarlijkse Technology Symposium in Amsterdam. Net als voorgaande jaren deelde de Taiwanese chipmaker daar nieuwe details over technieken die het bedrijf in de komende jaren gaat introduceren. Bedrijven als Apple, AMD, Nvidia en Qualcomm zullen die technieken op termijn gebruiken om snellere en zuinigere chips te maken.
Tweakers was aanwezig bij het evenement en hoorde alle details over TSMC's 3nm-nodes en over zijn komende N2-serie, waarvoor TSMC voor het eerst gebruik zal maken van nanosheettransistors. Ook biedt TSMC een kleine blik op de toekomst voorbij de 2nm en gaat het in op zijn overwegingen bij de mogelijke bouw van zijn eerste chipfabriek in Europa.
Bannerfoto: Bloomberg Creative / Getty Images
3nm-update: N3E, N3P en N3X
TSMC begon zijn presentatie met een update over zijn N3-serie, waarvan het bedrijf vorig jaar al de eerste details aankondigde. Deze serie omvat TSMC's laatste procedés op basis van finfets, voordat de chipmaker over een paar jaar de overstap naar gaa-transistors maakt met N2. Het bedrijf introduceerde met die serie tegelijk zijn Finflex-programma, waarmee chipontwerpers de hoeveelheid vinnen in een standaardcel kunnen aanpassen voor hogere prestaties of een lager stroomverbruik. Details daarover zijn te lezen in ons achtergrondverhaal over het TSMC Technology Symposium van vorig jaar.
TSMC begon eind 2022 met de productie van zijn eerste N3-procedé, hoewel die node vooral bedoeld is voor early adopters. Volgens SemiAnalysis gebruikt TSMC euv-lithografie voor 25 N3-lagen, waaronder zelfs enkele lagen met euv-multipatterning, hoewel TSMC dat niet wil bevestigen. Bij multipatterning wordt een enkele laag meermaals belicht met euv om kleinere features te produceren. Euv is op zichzelf al duur en bij multipatterning stijgen de complexiteit en kosten nog verder.
:strip_exif()/i/2005793714.jpeg?f=imagegallery)
Later dit jaar komt TSMC met N3E, waarbij de 'E' staat voor 'Enhanced'. Dat procedé is bedoeld voor een groter publiek. Volgens informatie van SemiAnalysis gebruikt het procedé negentien euv-lagen, waarvan geen met multipatterning. Daarmee moet N3E een versimpelde architectuur bieden met betere yields en goedkopere productie. Daartegenover staat dat de transistordichtheid iets lager is dan bij N3.
Volgens de chipmaker loopt de ontwikkeling van N3E nog altijd op schema. De fabrikant heeft samen met klanten de eerste tape-outs op dat procedé gedaan en volumeproductie begint in de tweede helft van dit jaar. Daarmee verschijnen de eerste N3E-chips waarschijnlijk in 2024 daadwerkelijk op de markt.
| TSMC N3, N3E en N5 | |||
|---|---|---|---|
| Node | N3 (vs. N5) | N3E (vs. N5) | N5 (vs. N7) |
| Snelheidsverbetering bij gelijk stroomverbruik |
+10 tot 15% | +18% | +15% |
| Afname verbruik bij gelijke snelheid |
-25 tot -30% | -32% | -30% |
| Transistordichtheid | Nnb | 1,30x | Nnb |
| Begin volumeproductie | December 2022 | H2 2023 | Q2 2020 |
Na N3E heeft TSMC nog twee nieuwe 3nm-procedés op de roadmap: N3P en N3X. Het bedrijf heeft die nodes vorig jaar al aangekondigd, maar deelt dit jaar meer details. Beide bieden verdere verbeteringen ten opzichte van N3E, maar brengen verschillende voordelen met zich mee.
N3P wordt een 'optische shrink' ten opzichte van N3E, met hogere prestaties en een grotere transistordichtheid. De ontwerpregels van N3P blijven daarmee ongewijzigd ten opzichte van N3E. Klanten kunnen hun bestaande N3E-chipontwerpen daardoor gemakkelijk overhevelen naar N3P voor betere prestaties of een lager stroomverbruik.
TSMC verwacht dat N3P vijf tot tien procent zuiniger is dan N3E bij dezelfde prestaties. Bij hetzelfde stroomverbruik zouden N3P-chips vijf procent beter presteren. De Taiwanese chipmaker rept verder over een transistordichtheid van 1,04x. N3P moet gereed zijn voor volumeproductie in de tweede helft van 2024.
Daarnaast werkt TSMC aan een N3X-procedé. Dat krijgt dezelfde transistordichtheid als N3P, maar krijgt extra optimalisaties voor high-performance computing. Daarmee is die node vooral bedoeld voor hpc-chips voor bijvoorbeeld datacenters en supercomputers. Producten op basis van N3X moeten betere prestaties en hogere kloksnelheden leveren. Volgens TSMC is N3X vijf procent sneller dan N3P bij een drive voltage van 1,2V.
| TSMC N3E, N3P en N3X | |||
|---|---|---|---|
| Node | N3E (vs. N5) | N3P (vs. N3E) | N3X (vs. N3P) |
| Snelheidsverbetering bij gelijk stroomverbruik |
+18% | +5% | +5% (bij Fmax op 1,2V) |
| Afname verbruik bij gelijke snelheid |
-32% | -5 tot -10% | Hoger stroomverbruik, geen exact percentage |
| Transistordichtheid | 1,30x | 1,04x | Zelfde |
| Begin volumeproductie | H2 2023 | H2 2024 | 2025 |
N2 met nanosheets krijgt hogere dichtheid
TSMC deelde daarnaast meer details over zijn komende N2-procedés, die op de planning staan voor 2025 en verder. N2 wordt TSMC's eerste serie procedés op basis van gate-all-aroundtransistors, ook wel nanosheets genoemd. We gingen vorig jaar al in op TSMC's nanosheettransistors en spraken over datzelfde onderwerp met het Leuvense onderzoeksinstituut imec.
In het kort bestaan gaa-transistors uit kanalen die volledig zijn omsloten door de gate, zoals de naam ook doet vermoeden. Dat moet onder meer leiden tot minder lekstroom ten opzichte van finfetkanalen, die aan drie kanten worden ingekapseld door de gate.
Nanosheettransistors bestaan uit verschillende brede en platte kanaaltjes die bovenop worden geplaatst. Dat is relatief compact, waardoor chipmakers bredere kanalen kunnen maken zonder dat dit ten koste gaat van de transistordichtheid. Dit zorgt er op zijn beurt voor dat er hogere stuurstromen gebruikt kunnen worden, wat de prestaties dan weer ten goede komt. Bovendien zijn de breedtes van nanosheets flexibel; chipmakers kunnen de kanalen ook smaller maken voor een lager stroomverbruik.

TSMC kondigde vorig jaar al aan dat zijn eerste N2-procedé op de planning staat voor 2025. Het bedrijf benadrukte dinsdag dat die planning ongewijzigd is. Het zegt dat het al meer dan tachtig procent van zijn prestatiedoelen heeft gehaald bij de ontwikkeling van zijn N2-node en noteert momenteel N2-yields van 'meer dan vijftig procent' bij een interne sram-testchip. N2 zou tot vijftien procent sneller zijn dan N3E bij hetzelfde stroomverbruik of tot dertig procent zuiniger bij dezelfde prestaties. De transistordichtheid wordt met N2 opgehoogd met 'meer dan' 1,15x; het bedrijf sprak vorig jaar over een toename van 1,10x.
TSMC wordt niet de eerste chipmaker die nanosheettransistors introduceert. Samsung is vorig jaar al begonnen met de relatief kleinschalige productie van 3nm-chips met dergelijke transistors. Intel introduceert op zijn beurt nanosheettransistors met zijn 20A-procedé, dat volgend jaar in productie gaat. TSMC volgt relatief laat, in 2025, hoewel de fabrikant zegt dat TSMC N2 bij introductie 'de geavanceerdste transistortechniek op de planeet' zal zijn.

| TSMC N2 naast N3E | ||
|---|---|---|
| Node | N2 (vs. N3E) | N3E (vs. N5) |
| Snelheidsverbetering bij gelijk stroomverbruik |
+10 tot 15% | +18% |
| Afname verbruik bij gelijke snelheid |
-25 tot 30% | -32% |
| Transistordichtheid | >1,15x | 1,30x |
| Begin volumeproductie | 2025 | H2 2023 |
Verdere N2-plannen: N2P met backside power delivery, N2X voor hpc
Toen TSMC vorig jaar zijn N2-roadmap introduceerde, ontbrak het aan details. Het bedrijf sprak alleen over de komst van N2 rond 2025. Nu voegt TSMC twee nieuwe N2-procedés toe aan zijn roadmap: N2P en N2X. Die laatste is weer een specifieke node voor hpc-producten met hogere kloksnelheden en spanningen. TSMC deelt daarbuiten echter weinig details over N2X.
N2P is wellicht de interessantste van de twee. Naast vermoedelijk hogere prestaties en een lager stroomverbruik implementeert het bedrijf voor het eerst backside power delivery in dat procedé. Het zei in 2022 al dat die techniek in zijn N2-serie zou worden geïntroduceerd, maar gaf toen verder geen details.
Zoals de naam doet vermoeden, wordt de stroomtoevoer voor de transistors met bpd vanaf de achterkant van de wafer geregeld. Dit vermindert onder meer de routing congestion aan de bovenkant van de wafer. Dat moet hogere frequenties mogelijk maken en lekstroom verminderen. Bovendien blijkt stroomtoevoer aan de onderkant efficiënter dan stroomtoevoer aan de bovenkant. Het verbetert bijvoorbeeld de supply-voltage drop die wordt veroorzaakt door de steeds hogere weerstand in de back-end-of-line van traditionele transistorontwerpen.


Een traditioneel transistorontwerp met stroomvoorziening aan de voorkant (links) naast een wafer met backside power delivery. Bron: imec
TSMC stelt dat bpd vooral geschikt zal zijn voor hpc-producten met fijnmazige stroomnetwerken. Senior vice president Kevin Zhang verwacht dat de techniek een tien tot vijftien procent hogere dichtheid krijgt op het gebied van logic-transistors, puur door de frontsidemetalen volledig op signalrouting te richten. Voor andere transistortypen, zoals sram en analog, deelde Zhang geen verwachte dichtheidsverbeteringen.
Bpd komt in de tweede helft van 2025 beschikbaar voor productontwerp. De techniek gaat dan in volumeproductie met de N2P-node, die voor 2026 op de roadmap staat. TSMC is niet de enige fabrikant die aan bpd werkt; Intel wil die techniek in 2024 introduceren in zijn 20A-node. Ook Samsung wil bpd toepassen in zijn 2nm-procedé. Volumeproductie van Samsungs eerste 2nm-node begint in 2025.
:strip_exif()/i/2005793696.jpeg?f=imagegallery)
Nieuwe transistors voorbij de 2nm
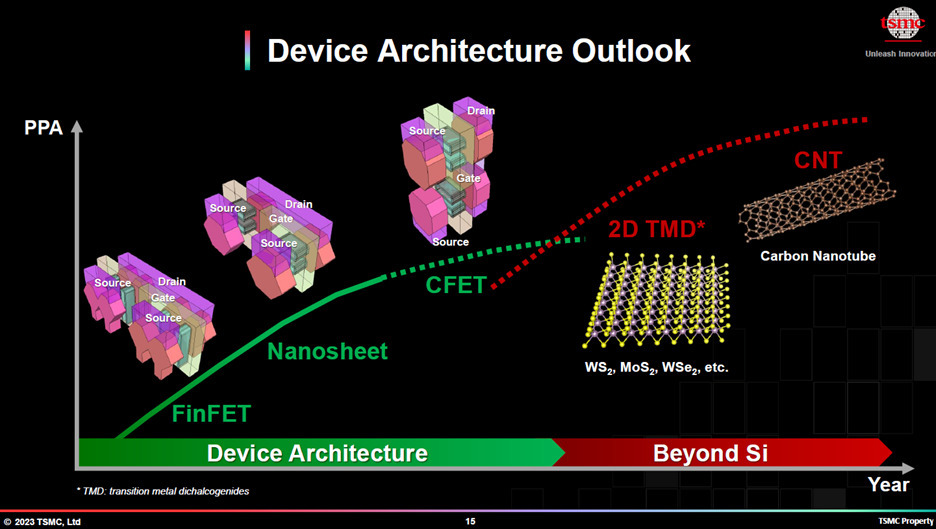
Ook voorbij de 2nm ziet TSMC mogelijkheden om transistors verder te verkleinen, hoewel het zijn roadmap daarvoor nog niet concreet heeft uitgestippeld. Voorlopig blijft het bedrijf inzetten op nanosheets, die dus met N2 geïntroduceerd worden. Het zegt wel tegen journalisten dat het verschillende opties voor nieuwe transistorarchitecturen overweegt die verdere nodeverkleiningen mogelijk moeten maken. TSMC ziet complementary field-effect transistors als een van de meestbelovende opties. Het bedrijf noemde die optie vorig jaar al en gaf dit jaar aan dat het werkende cfets in zijn lab heeft.
Cfets zijn een soort doorontwikkeling van de nanosheets die twee transistorsoorten combineren. Moderne chips bestaan uit een combinatie van p-transistors met positieve lading en n-transistors met een negatieve lading. De combinatie daarvan zorgt ervoor dat transistors alleen stroom verbruiken tijdens het schakelen, waarmee ze relatief energiezuinig zijn en relatief weinig warmte produceren.
Momenteel worden p- en n-transistors naast elkaar gezet als losse devices. Met cfets komt daar verandering in; bij dat transistortype worden ze verticaal boven op elkaar geplaatst. Dat maakt een hoop ruimte vrij voor verdere scaling; TSMC schat dat de dichtheid van cfets met een factor 1,5x tot 2,0x zal stijgen ten opzichte van nanosheets.
Tegelijk geeft het bedrijf aan dat het geen concrete plannen heeft om cfets te gebruiken. De fabrikant evalueert verschillende transistorarchitecturen voor in de toekomst en cfet is daar een van. "Alles voorbij de nanosheet staat op onze roadmap, om te laten zien dat er nog een toekomst is", verduidelijkt Zhang na vragen van Tweakers. "We blijven werken aan verschillende opties. We kijken bijvoorbeeld ook naar siliciumalternatieven. We zullen niet precies vertellen wat de transistorarchitectuur na de nanosheet wordt."
Voorlopig blijft TSMC dan ook nanosheets gebruiken, vertelt Zhang. "We beginnen met nanosheets op 2nm. Het is redelijk om te verwachten dat nanosheets op zijn minst een aantal generaties worden gebruikt. We hebben finfets vijf generaties ingezet; dat is meer dan tien jaar." Hoeveel generaties nanosheets precies gebruikt zullen worden, wilde Zhang niet zeggen.
Mogelijke chipfabriek in Duitsland
Naast zijn technologieroadmap deelde TSMC nog enkele updates over zijn uitbreidingsplannen voor nieuwe fabrieken. Behalve met nieuwe fabrieken in Azië, is het bedrijf vorig jaar begonnen met de bouw van zijn eerste 4nm-chipfabriek in de Amerikaanse staat Arizona. Het bedrijf gaat daar later ook een 3nm-fabriek bouwen. Dat doet het om zijn productiecapaciteit over meer regio's te spreiden; de fabrikant was tot op heden vooral actief in Azië.
Om diezelfde reden overweegt het bedrijf een fabriek in de Duitse stad Dresden. Het zei in 2021 al een fabriek in Duitsland te overwegen, hoewel er sindsdien vooral radiostilte heerste rondom de fabriek. Als TSMC al sprak over zijn beoogde Duitse fab, dan was het om te zeggen dat het 'alle opties overweegt', maar nog geen concrete plannen had. In de afgelopen maanden begon de geruchtenmolen echter te draaien. Verschillende media, waaronder Reuters en Bloomberg, berichtten dat de onderhandelingen rondom de Duitse TSMC-fabriek steeds verder vorderden en dat een beslissing mogelijk later dit jaar zou volgen.

Hoewel het zegt nog steeds geen concrete beslissing genomen te hebben, deelt TSMC tijdens een Q&A-sessie met journalisten meer details over de Duitse uitbreidingsplannen. Kevin Zhang zei tegen onder andere Tweakers dat het bedrijf 'zeer goede vorderingen' heeft geboekt rondom de fabriek in Dresden. Het bedrijf zegt veel steun te krijgen van de lokale overheid en de EU en doorloopt nu zijn beoordelingsproces. Het zou op zijn vroegst in augustus een knoop kunnen doorhakken voor de bouw van een Duitse chipfabriek, hoewel dat tijdpad niet vaststaat.
Als de Duitse fabriek er komt, zal deze zich richten op de productie van microcontrollers voor auto's. "In Europa draait de helft van onze business om microcontrollers", zegt Zhang. Daarbij doelt de topman onder meer op producten als embedded non-volatile memory. Dergelijke chips kunnen geproduceerd worden op relatief oude procedés. "Als we een fabriek bouwen in Dresden, beginnen we waarschijnlijk met 28nm", zegt Zhang dan ook. Daarbij wordt echter niet uitgesloten dat de fabriek later wordt geüpgraded naar modernere nodes nu automakers langszaam maar zeker de overstap naar geavanceerdere chips gaan maken.
Met uitbreidingen buiten Azië wil TSMC dichter bij zijn klanten chips produceren om beter samen te werken. Daar staat tegenover dat chips die in Azië worden gemaakt, relatief goedkoop zijn. Er gingen onlangs al berichten rond dat de chips die TSMC in Arizona produceert, tot dertig procent duurder zijn dan chips uit Azië. Hoewel TSMC dat percentage niet bevestigt, geeft het wel aan dat dergelijke chips inderdaad een meerprijs meekrijgen.
Datzelfde geldt voor een eventuele chipfabriek in Europa. "Chips uit Europa zijn ook best duur", zegt Kevin Zhang. Volgens een woordvoerder van TSMC zouden de kosten van chips uit Europa vergelijkbaar zijn met die van chips uit de VS. "Het is een economische uitdaging om een fabriek te bouwen in duurdere regio's." Die meerprijs is een tweesnijdend zwaard, vervolgt Zhang. "Niemand wil meer betalen; je wil altijd de laagst mogelijke prijs. Maar klanten snappen ook dat we een sterkere toeleveringsketen nodig hebben. Klanten begrijpen de redenering achter deze mogelijke uitbreiding."
:strip_exif()/i/2005793948.jpeg?f=imagegallery)
:strip_icc():strip_exif()/i/2006702746.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006695094.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006208958.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005816748.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005286184.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005184414.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003840762.jpeg?f=fpa_thumb)
:strip_exif()/i/2004681518.jpeg?f=fpa)
:strip_exif()/i/2005279580.jpeg?f=fpa)
:strip_exif()/i/2006689170.jpeg?f=fpa)
/i/2004767550.png?f=fpa)
/i/2004611214.png?f=fpa)
:strip_exif()/i/2004886338.jpeg?f=fpa)
/i/2004628264.png?f=fpa)
/u/246414/crop64732e7f0bf92_cropped.png?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_icc():strip_exif()/u/637028/crop6a3e22601b0f7_cropped.jpg?f=community)
/u/113545/no_wai.png?f=community)
:strip_icc():strip_exif()/u/715918/crop6270f596785bb_cropped.jpg?f=community)
/u/244207/crop5c38ae2351fe1.png?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_icc():strip_exif()/u/63694/spion200_250-150x150.jpg?f=community)
/u/96692/chili_pepper.png?f=community)
{kind=link}