Op Nvidia’s GPU Technology Conference heeft de fabrikant zijn Blackwell-gpu aangekondigd. Ceo Jensen Huang presenteerde tijdens zijn keynote de op AI-gerichte B200-chip en de gecombineerde GB200 ‘superchip’. Productie en levering van deze chip moet later dit jaar op gang gaan komen.
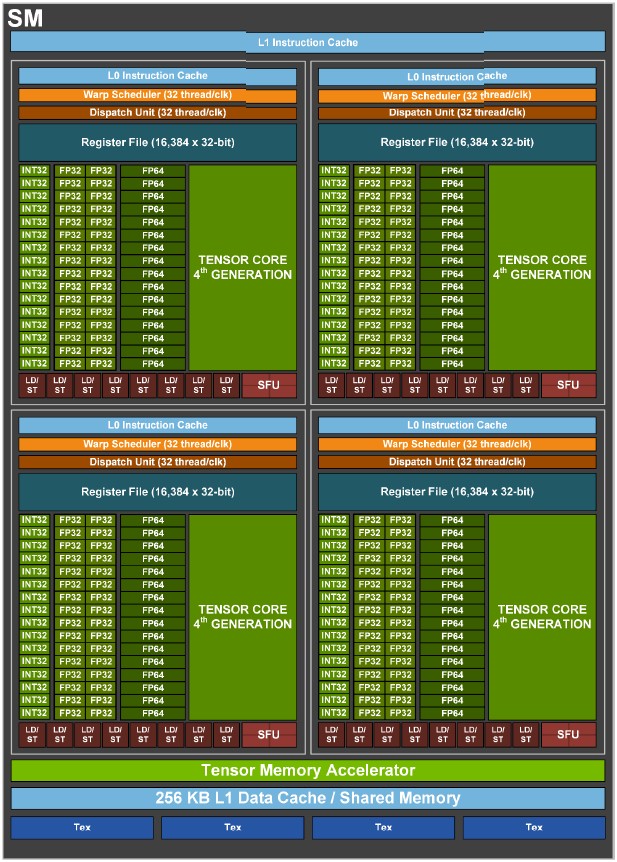
De B200-chip telt 208 miljard transistors en bestaat uit twee gpu-chiplets (B100) die verbonden zijn met wat Nvidia zijn High Bandwidth Interface (NV-HBI) noemt. De voorgangers GA100 en GH100 waren nog opgebouwd uit een enkele, grote processordie. Bij Blackwell kiest Nvidia nu dus voor een multichipmodule, maar de B100-gpu’s zijn met een oppervlakte van naar schatting meer dan 800mm² ongeveer even groot als wat het bedrijf voorheen in dit segment uitbracht. Er wordt dus flink meer chipoppervlakte gebruikt om de rekenkracht te vergroten. Nvidia zal voor Blackwell gebruik blijven maken van TSMC’s 5nm-proces, zij het op een sterk verfijnde versie van deze node, genaamd N4P.
De twee gpu-chiplets op B200 zijn elk voorzien van vier geheugencontrollers, met op elk 24GB HBM3e-geheugen dat met een 1024bit-geheugenbus is verbonden. Elke gpu-chiplet beschikt daarmee over een 4096bit-geheugenbus met daar in totaal 96GB werkgeheugen aan gekoppeld. Op B200 komt het totaal dan uit op 8192bit en 192GB, wat onder de streep een geheugenbandbreedte van 8TB/s betekent. Dankzij NV-HBI functioneren de twee chiplets als één gpu, en kan software ze ook als zodanig benaderen. Het is momenteel nog onduidelijk welke technologie Nvidia heeft gekozen voor het packagingproces, net als het aantal rekenkernen dat op de chip beschikbaar is.
/i/2006573408.png?f=imagegallery)
De Blackwell-architectuur voegt hardwarematige ondersteuning voor een lagere precisie van zwevendekommagetallen toe, namelijk FP4 en FP6. De FP4-ondersteuning kan voor kunstmatige intelligentie nuttig zijn wanneer een hogere snelheid sterk verkozen wordt boven precisie. Met FP6 wordt ook nog een middenweg mogelijk wanneer FP4 niet nauwkeurig genoeg is, maar wanneer FP8 dan weer niet nodig is. Omdat de Ampere- en Hopper-chips voor deze lagere precisie geen hardwarematige ondersteuning bieden, valt er geen directe vergelijking wat rekenkracht betreft te maken. Op FP8 levert B200 tweeënhalf keer de snelheid van de H100-chip. Om automatisch de juiste precisie voor rekenmodellen toe te passen en zo prestaties te optimaliseren, heeft Nvidia een nieuwe generatie Transformer Engine ontworpen voor de Blackwell-architectuur.
Op de Grace Blackwell 200 (GB200) combineert Nvidia twee B200’s met een Grace-cpu tot wat de fabrikant zelf een ‘superchip’ noemt. De op Arm gebaseerde Grace-cpu op de GB200 telt 72 cores en het geheel krijgt een maximum tdp van 2700W. De GB200 Superchips kunnen in grotere aantallen gecombineerd worden om de rekenkracht voor AI-gerelateerde toepassingen te vergroten en te versnellen.
Bedrijven zoals Amazon, Dell, Google, Meta, Microsoft, OpenAI, Oracle, Tesla en xAI hebben interesse getoond in de Blackwell-gpu. Nvidia's jaaromzet verdubbelde in 2023 door de sterk toegenomen vraag naar AI-toepassingen. Voor de consumentenmarkt betekent de aankondiging vooralsnog weinig, maar volgens geruchten brengt Nvidia zijn GeForce RTX 50-serie videokaarten voor gamers later in 2024 ook uit.
| Blackwell B200 | Hopper H100 | |
| Architectuur | Blackwell | Hopper |
| Gpu Diesize |
"Blackwell GPU" 2x +800mm² |
GH100 814mm² |
| Transistors | 208 (2x 104) miljard | 80 miljard |
| Productieprocedé | TSMC N4P (5nm) | TSMC 4N (5nm) |
| Rekenkernen | onbekend | 16896 |
| FP4 FP8 FP16 FP64 |
9 pflops 4500 tflops 2250 tflops 40 tflops |
n.v.t. 1980 tflops 990 tflops 67 tflops |
| Geheugenopstelling | 192GB HBM3e 2x 4096bit |
80GB HBM3 5120bit |
| Geheugenbandbreedte | 8TB/s | 3,35TB/s |
| Tdp | 1000W | 700W |

:strip_exif()/i/2006573412.jpeg?f=imagegallery)

:strip_icc():strip_exif()/i/2007948260.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006702746.jpeg?f=fpa_thumb)
:strip_exif()/i/2007544438.jpeg?f=fpa)
/i/2004919460.png?f=fpa)
:strip_exif()/i/2007317574.jpeg?f=fpa)
:strip_exif()/i/2006573404.jpeg?f=fpa)
:strip_exif()/i/2004714376.jpeg?f=fpa)
/i/2004695548.png?f=fpa)
/i/2004628280.png?f=fpa)
:strip_exif()/i/2006211424.jpeg?f=fpa)
/i/2004911352.png?f=fpa)
/i/2004850458.png?f=fpa)
/i/2004609076.png?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/u/27299/hoofd.png?f=community)
/u/2801/crop5ccb23f820755.png?f=community)
:strip_icc():strip_exif()/u/116210/crop5ab6397009836_cropped.jpeg?f=community)
/u/305155/crop5f64a5ce6862d_cropped.png?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/112916/51.jpg?f=community)
/u/581763/crop671d464e1d270_cropped.png?f=community)
/u/12436/p1_normal.png?f=community)
/u/1092689/crop61dd63c9a3c15_cropped.png?f=community)
/u/204872/crop65a1d5f52b87f.png?f=community)
:strip_icc():strip_exif()/u/476420/crop5623d9ad036cf_cropped.jpeg?f=community)
:strip_exif()/u/28986/javaone6666.gif?f=community)
:strip_icc():strip_exif()/u/321031/crop572f5527b6acf_cropped.jpeg?f=community)
/u/85038/mp3-file.JPG?f=community)
/u/233413/crop574768220d598_cropped.png?f=community)
:strip_icc():strip_exif()/u/287731/crop6270fa65746ea_cropped.jpg?f=community)
/u/464964/crop5706bee0228c3_cropped.png?f=community)
:strip_icc():strip_exif()/u/78279/crop5a9fe3f83191c.jpeg?f=community)
:strip_icc():strip_exif()/u/35767/images.jpg?f=community)
{kind=link}
{kind=link}