Tijdens de keynote van de Computex op 1 juni toonde AMD-ceo Lisa Su een nieuwe techniek voor Zen 3-chips. Die nieuwe techniek is door AMD '3D V-Cache' gedoopt en geeft het bedrijf een manier om extra cache toe te voegen aan zijn processors. Dat doet AMD in samenwerking met chipfabrikant TSMC en het moet de chips een prestatievoordeel opleveren ten opzichte van chips met alleen cache in de cpu-die. Waarom is die extra cache zo belangrijk en hoe heeft AMD dat technisch aangepakt?
De reden om cache in een processor te hebben, is primair dat een processorcore veel sneller is dan het geheugen kan bijhouden. Een van de grootste knelpunten in moderne processors is dan ook de manier om data snel genoeg bij de execution-units te krijgen. AMD noemde dit ooit treffend: 'Feed the beast'.
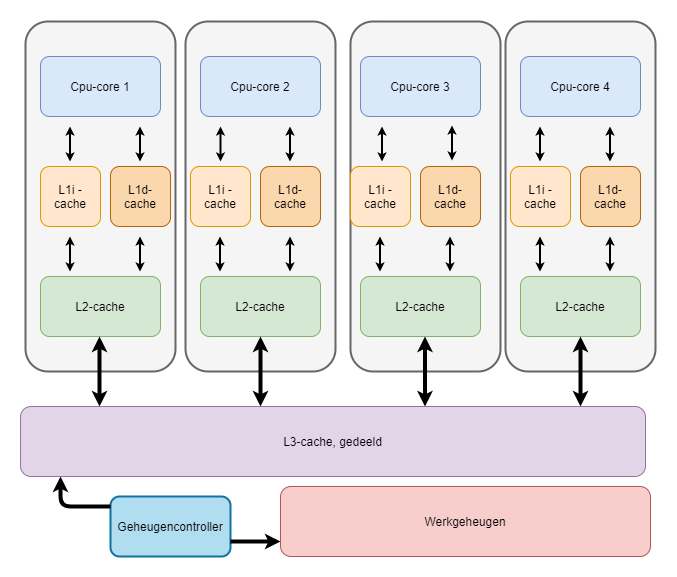
Om daadwerkelijk werk te verrichten, moet een processor data en opdrachten verwerken. Ervan uitgaande dat de data al in het werkgeheugen zit, worden opdrachten en bijbehorende data vanuit het werkgeheugen naar de L3-cache gestuurd en vandaaruit naar de L2-cache. Daarna gaat het naar de L1-instructiecache, naar de frontend van de cpu: de fetch-unit. Die stuurt het door naar de decode-unit. Van daaruit gaat de execution-unit ermee aan de gang en schrijft die de resultaten naar de L1-datacache. In werkelijkheid is het verhaal wat complexer, met registers, buffers en extra kleine caches als uop-cache.
Cache-levels in een processor
Een cpu-core 'kijkt' eerst in de L1-cache naar data. Wordt die daar niet gevonden, dan wordt de L2-cache geraadpleegd, en als de data daar ook niet is opgeslagen, wordt naar de gedeelde L3-cache uitgeweken. Daarna volgt als laatste redmiddel het dram, maar dat is veel trager. Meer cache vermindert dus de noodzaak om naar traag werkgeheugen uit te wijken, reden waarom bijvoorbeeld grote serverprocessors tientallen megabytes cache hebben.
AMD heeft met zijn 3D V-Cache een manier gevonden om een Zen-core extra cache te geven, zonder het ontwerp van de cores veel groter en duurder te maken. In dit stuk duiken we de verschillende cachelagen in en kijken we hoe AMD, samen met TSMC, zijn nieuwe ontwerp tot stand brengt.
Cachestructuur: geheugenlagen
Om te begrijpen wat er zo belangrijk is aan meer cache, moeten we eerst de processor induiken en naar de cachestructuur kijken. Een cpu werkt namelijk door instructies binnen te laten, ze te verwerken en de uitvoer weg te schrijven. In eerste instantie is er de L0-cache, waarin gedecodeerde instructies worden opgeslagen zodat de frontend ze niet opnieuw in uops hoeft te vertalen. Daarna volgen de L1-caches. Die bestaan uit een instructie- en een datacache, waarin respectievelijk de instructies en de invoer van een core worden opgeslagen. Omdat deze caches de cpu-core moeten bijhouden, moet de L1-cache zo snel mogelijk zijn en data met zo min mogelijk latency met de core uitwisselen. Een moderne core heeft dan ook altijd zijn eigen L1-cache; delen met andere cores zou te veel prestaties kosten. De meeste L1-caches per core zijn tussen de 32 en 64kB groot en bestaan net als de overige cache uit sram-cellen.
Daarna volgt de L2-cache. Die is groter dan de L1-cache, maar daarom ook inherent trager. Waar de L1-cache zeer dicht tegen de cores zit, is de L2-cache iets verder weg, wat extra latency kost. Er is een grotere prestatiehit doordat het opzoeken van data in de grotere cache langer duurt; er moet immers meer data afgezocht worden. Ook de L2-cache is nog exclusief voor een individuele core gereserveerd en is meestal in de ordegrootte van 512kB per core.
De grootste cache is de L3-cache. Die wordt gedeeld tussen verschillende cores en vormt meestal een aparte en duidelijk herkenbare structuur op de cpu-die. Omdat deze cache weer verder van de cpu-core vandaan zit, duurt het doorspitten ervan met vaak 2MB cache per core relatief lang. De L3-cache is echter belangrijk, omdat die ten eerste vrij eenvoudig kan worden toegevoegd aan een cpu en ten tweede nog altijd veel sneller is dan data in het reguliere werkgeheugen ophalen. Overigens kan een extra cachelaag worden toegevoegd: Intel introduceerde voor zijn Haswell Iris Pro GT3e-processor een package met 128MB edram, dat als L4-cache dienstdeed.
Cpu-generatie
Zen 3
Zen 2
Zen
Cypress Cove
L1-cachelatency
4 of 5 cycles L1i: 32kB / L1d: 32kB
4 of 5 cycles L1i: 32kB / L1d: 32kB
4 of 5 cycles L1i: 64kB / L1d: 32kB
4 of 5 cycles L1i: 32kB / L1d: 48kB
L2-latency
12 cycles 512kB/core
12 cycles 512kB/core
17 cycles (Zen+ 12 cycles) 512kB/core
12 cycles 512kB/core
L3-latency
46 cycles 32MB/ccx
38 cycles 16MB/4c-ccx
40 cycles 8MB/4c-ccx
42 cycles 16MB (8 cores)
Dram-toegang
46 cycles + ~66ns
38 cycles + 66ns
40 cycles + 90ns
42 cycles + 51ns
De toegangstijden zijn afhankelijk van de klokfrequentie van de cores; bij 5GHz is 1 klokcycle 0,2ns. L1-cachelatency is dan ongeveer 0,8ns, L2-latency ongeveer 2,4ns en L3-latency ongeveer 9 tot 10 nanoseconde.
Om die latencies naar de verschillende caches te illustreren, kun je twee criteria gebruiken. In absolute zin kun je de tijd meten die het kost om met de cache te communiceren. Voor L1-caches is dat pakweg een nanoseconde en voor de L2-cache loopt dat op tot twee of drie nanoseconden. Naar de L3-cache zit je met een moderne processor net boven de tien, twaalf nanoseconden, en naar het werkgeheugen kom je in de tientallen nanoseconden, zo niet tegen de honderd nanoseconden.
Nu is latency meten in nanoseconden vrij arbitrair, want cachetoegang is afhankelijk van de kloksnelheid van de processor. Om een architectuur eerlijker te vergelijken, is het zaak om de latencies in klokcycles uit te drukken, zodat je onafhankelijk bent van klokfrequenties. Voor Intels L1-, L2- en L3-cachelevels bij Cypress Cove-cores (Rocket Lake) is dat volgens metingen van Anandtech en volgens opgaaf van Intel 5, 12 en 45 cycles, met 250 cycles voor toegang tot het dram. Bij AMD's Zen 3-cores is dat 4, 4 en 46 klokcycles voor de caches en ongeveer 400 cycles voor dram-toegang. Bij een kloksnelheid van 5GHz is dat equivalent aan minder dan 1ns voor de L1- en L2-caches en ongeveer 10ns voor de L3-cache. De toegang tot het geheugen zit bij Zen 3 op bijna 400 klokcycles, of bijna 80ns.
Het snelheidsverschil tussen de verschillende caches is niet de enige performance penalty om van de ene naar de andere cache uit te wijken. Een cache miss, als data dus niet in de cache zit, kost dubbele tijd: eerst de latency om in bijvoorbeeld L1-cache te kijken, en vervolgens kost het extra tijd om in de L2-cache te zoeken. Zo wordt je 'dubbel gestraft' dus.
Dieshot van AMD's Zen 3-chiplet met opschrift. Afbeelding via Reddit-user Locuza
Het moge duidelijk zijn dat data uit caches halen enorm preferabel is tegenover data uit het werkgeheugen halen. In het slechtste geval, van L3 naar dram, is de toegangstijd acht keer zo hoog. Waarom hebben dan niet alle processors megabytes of gigabytes aan cache?
De kosten van cache
Zoals op de vorige pagina genoemd, is alle cache opgebouwd uit sram-cellen. Elke bit sram kost zes transistors. Daar komt natuurlijk nog extra hardware bij om de cache te bereiken en van prik te voorzien. Elke vierkante micrometer op een chip kost echter geld en hoe meer sram of cache je wilt, hoe groter de chip moet worden. Daarmee wordt een chip logischerwijs duurder, want het zijn niet alleen de afmetingen van de chip die grote chips duurder maken. Met minder dan 100-procents-yields is de kans op defecten in cruciale onderdelen bij grote chips groter dan bij kleine, wat het lastig maakt grote chips correct werkend te produceren. Het is niet voor niets dat AMD naar chiplets is overgestapt voor de Zen-cores.
Een sram-cel met zes transistors
Los van de oppervlakte die groot cachegeheugen vergt, zijn er twee andere belangrijke factoren die limieten stellen aan de cacheafmetingen. Ten eerste: cache bestaat uit sram, met voor iedere bit zes transistors. Omdat sram constant energie nodig heeft om data vast te houden, verstookt een grote cache meer energie dan een kleine. Dat heeft niet alleen gevolgen voor het opgenomen vermogen, maar elke watt die de processor ingaat, moet er ook weer uit, en dat gebeurt als warmte.
Bovendien heeft een steeds grotere cache geen navenante prestatievoordelen. In plaats van L2-cache te verdubbelen kan het bijvoorbeeld veel handiger zijn om een grotere execution-unit te ontwerpen of de branch prediction uit te breiden. Zoals altijd is ook bij cpu-ontwerp een goed evenwicht tussen opties noodzakelijk; de core moet netjes in balans zijn, zodat er geen resources verspild worden.
Samenwerking met TSMC
De grotere cache die AMD met zijn 3D V-Cache heeft laten zien, is vooral een technische oplossing om meer cache aan de cores beschikbaar te stellen zonder veel grotere chips te maken. Daarmee wordt vooral een oplossing geboden voor het kostenprobleem, want ook de 3D V-Cache heeft uiteraard energie en koeling nodig. De chiplets die AMD produceert, hoeven echter niet bijzonder veel duurder of complexer te worden.
De samenwerking met TSMC maakt dat mogelijk. In december 2020, tijdens het TSMC Technology Symposium, toonde de chipfabrikant namelijk nieuwe technieken om 'chips' met elkaar te verbinden. Feitelijk zijn het natuurlijk geen chips, maar dies, of plakjes silicium, die met elkaar verbonden worden. Deze 3d-integratie maakt het mogelijk de core-chiplet van Zen met een cachedie te verbinden.
Opties voor 3d-integratie TSMC
Er zijn diverse manieren om dies met elkaar te verbinden en dat kan op verschillende momenten tijdens de chipproductie. Zo is het mogelijk wafer-to-waferbonding toe te passen, waarbij complete wafers met elkaar verbonden worden, of wafer-to-dieverbindingen. AMD zou gebruikmaken van die tweede optie, een techniek die TSMC 'chip on wafer', of CoW, noemt. De Taiwanese fabrikant toonde in december aan maar liefst twaalf lagen met elkaar te kunnen verbinden, maar AMD kiest hier voor slechts twee verbonden lagen.
Twaalf lagen CoW-stacking. TSMC
Een onderscheidende eigenschap van TSMC's CoW-techniek, vergeleken met Intels packaging die het gebruikt om dies te stapelen in Foveros-chips, is het gebruik van koperen interconnects om dies met elkaar te verbinden. Intel gebruikt microbumps, of kleine soldeerbolletjes boven op de koperen verbindingen, om twee dies te verbinden. Met directe koperverbindingen is niet alleen de pitch, of de onderlinge afstand, kleiner en daarmee de beschikbare bandbreedte voor data-uitwisseling groter, maar zijn ook de thermische eigenschappen beter. Dat levert volgens AMD een bandbreedte van 2TB/s op tussen de 3D V-Cache en de cpu-die.
Vergelijking TSMC-verbindingen met micro-bumps
De 3D V-Cache ligt boven op de reguliere, on-die L3-cache, zodat de rest van de core zijn warmte goed kan blijven afgeven en de twee caches direct met elkaar via de tsv's verbonden zijn. Om het geïntroduceerde hoogteverschil te compenseren, krijgen de lagere delen van de core-chiplet een laagje passief silicium aangebracht, zodat de hoogte overal gelijk is. Dankzij het wegpolijsten van passief silicium zijn de Zen 3-chiplets met gestapelde cache even dik als de originele chiplets. Er hoeven dus geen aanpassingen aan het fysieke ontwerp van bijvoorbeeld heatspreaders gedaan te worden om de nieuwe chips te laten passen.
3D V-Cache in de praktijk
We hebben inmiddels gezien wat de verschillende cachinglagen in processors inhouden en hoe AMD gebruikmaakt van de productiecapaciteiten van TSMC om zijn processors van meer cache te voorzien. Niet iedere toepassing zal uiteraard evenveel profijt hebben van extra cache, maar gezien de latency penalties die een cache miss oplevert, en die het ophalen van data uit dram kost, is er voldoende motivatie om extra transistors voor die cache te budgetteren.
AMD 3D V-Cache
Tijdens de Computex-keynote liet AMD een prototype Zen 3-processor met 3D V-Cache zien; een Ryzen 9 5900X kreeg op een van de twee chiplets de extra L3-cache. Daarmee kreeg de 5900X 64MB extra L3-cache, met de 32MB L3-cache per chiplet een totaal van 128MB dus. In een daadwerkelijk product dat verkocht zou worden, zouden beide core-chiplets van 3D V-Cache-dies worden voorzien, voor 192MB L3-cache per processor met twaalf of zestien cores. De V-cache zou een bandbreedte van 2TB/s krijgen met een onbekende latency, hoewel dat ten minste 46 cycles, net als het gewone L3-cache, zal zijn. Ter vergelijking: Intels L4-cache van enige jaren geleden had een bandbreedte van ongeveer 100GB/s.
Uit benchmarks tussen gewone een 5900X en een 5900X waarin beide core-chiplets met 3D V-Cache zijn uitgerust, ofwel een processor met 64MB tegen 192MB L3-cache, bleek de extra cache in gaming een gemiddelde fps-winst van 15 procent op te leveren. De ene game profiteerde meer dan de andere, met voorbeelden als League of Legends, dat slechts 4 procent sneller werd, en Monster Hunter World, dat een maar liefst 25 procent hogere framerate produceerde. Volgens de AMD-tests, waarbij beide processors overigens op 4GHz gefixeerd werden, bedroeg de gemiddelde fps-winst over verschillende games 15 procent.
Prestatieverschillen Ryzen 9 5900X met en zonder 3D V-cache
Met een diesize van zes bij zes milimeter, of 36mm², kost de extra cache flink wat extra silicium; de core-chiplet van Zen 3 is immers 80,7mm² groot. Dat betekent extra kosten, niet alleen voor de cacheproductie, maar ook voor de intregratie van CoW en vervolgstappen. Daarom heeft AMD aangekondigd alleen het hoogste segment processors van deze techniek te zullen voorzien. Processors in een lager segment zullen waarschijnlijk ook minder kunnen profiteren van de techniek, of het is budgettechnisch niet haalbaar. Het is een samenspel van productie-, dieoppervlak-, energie- en warmtebudget.
Wanneer kun je daadwerkelijk producten met extra 3D V-cache verwachten? AMD's Lisa Su heeft aangegeven tegen het eind van het jaar de cache aan high-end producten toe te voegen. Wellicht zou dat betekenen dat begin 2022 dergelijke producten daadwerkelijk op de markt komen. Dat zou dan zomaar de nieuwe generatie 5nm-Zen 4-processors kunnen zijn, die ook rond die tijd hun opwachting zouden maken.
Wanneer kun je daadwerkelijk producten met extra 3D V-cache verwachten? AMD's Lisa Su heeft aangegeven tegen het eind van het jaar de cache aan high-end producten toe te voegen. Wellicht zou dat betekenen dat begin 2022 dergelijke producten daadwerkelijk op de markt komen. Dat zou dan zomaar de nieuwe generatie 5nm-Zen 4-processors kunnen zijn, die ook rond die tijd hun opwachting zouden maken.
Update 6/1/2021 10am PT: AMD has confirmed to Tom's Hardware that Zen 3 Ryzen processors with 3D V-Cache will enter production later this year. The technology currently consists of a single layer of stacked L3 cache, but the underlying tech supports stacking multiple dies. The technology also doesn't require any specific software optimizations and should be transparent in terms of latency and thermals (no significant overhead in either). We also obtained further fine-grained details, stay tuned for additional coverage.
Waar precies in dat bericht op wccftech is (met bron) te lezen dat AMD dit heeft bevestigd? Ik kom het namelijk niet tegen, of mis ik iets? Ze linken wel naar een hele algemene tweet bij het woord 'confirmed' en gebruiken die als bron, terwijl daar helemaal niks in staat over 3D V-cache specifiek op Zen 3(+).
Het bericht eindigt met:
AMD will definitely have this tech on its Zen 4 Ryzen CPUs and they will go one step ahead to package upcoming Zen 3 powered Ryzen & EPYC Milan-X with stacked 3D V-Cache chiplets as reported in recent rumors.
In het praktijk stukje mist toch wel een hele belangrijke conclusie.. namelijk dat de resultaten enkel op 1080p zijn behaald. Op 1440p en 4k is het nog maar de vraag of je er oets aan gaat hebben (in games).
Update: in de presentatie werd het wel genoemd maar in dit artikel niet. Lijkt mij nogal cruciale info.
[Reactie gewijzigd door biggydeen2 op 22 juli 2024 15:43]
Game CPU tests doe je altijd op de zo laag mogelijke resolutie, omdat resolutie eigenlijk geen effect heeft op de CPU, maar dat je meer de GPU aan het testen bent. Hoewel dit ook niet meer zo zwart/wit is, want vooral nVidia heeft momenteel redelijk last van driver overhead op de CPU, omdat ze geen hardware scheduler aan boord hebben. Hoewel dit doorgaans meer een impact is op low-core count CPU's (een quad core begint ondertussen een bottleneck te worden). Ik had nog liever gehad dat ze 640*480 zouden testen
Maar dat doet er niets aan af dat @biggydeen2 wel een punt heeft, de theoretische grenzen opzoeken is leuk, maar uiteindelijk als koper wil je weten, tijdens het lezen van reviews, wat voor praktisch nut het heeft in jouw systeem en de workloads die jij draait op dit moment of in de nabije toekomst. Als ik bij wijze van morgen zo'n Ryzen met V-Cache koop voor mijn 1440P gaming rig dan wil ik daar wel nu al profijt van hebben in mijn workloads en niet pas over bijvoorbeeld 3 jaar, omdat ik dan pas tegen cpu bottlenecks aan loop in plaats van gpu bottlenecks, immers kan ik dan beter bij wijze van morgen een andere GPU kopen (dat levert immers wel direct resultaat op in die situatie) en over 3 jaar pas een betere cpu.
Bottlenecks wegnemen om maar de performance verschillen te kunnen laten zien zijn dan leuk, maar je wil ook weten wat een techniek toevoegt in vandaag de dag realistische gebruiksscenario's immers daar koop je het voor als gebruiker, niet om te benchen op 640 *480. 1080P gaming is nu nog enigszins relevant , want er is nog een grote installed base van 1080P users (maar extreem high FPS 1080 (denk aan 240 tot 260hz gamers), is echter wel een zeer kleine niche, het grootste deel 1080P schermen in omloop zal 60-144hz, waarmee je eigenlijk ook geen profijt gaan hebben van dit soort zaken, want de huidge cpu's behalen dat soort framerates al makkelijk), maar je wil zeker ook weten wat het doet op 1440P. aangezien die resolutie momenteel qua verkopen zeer populair is, en dus door veel gamers gekozen wordt voor hun dagelijke vermaak.
En dat is wel iets waar ik enigszins bang voor ben, dat dit cherry picked resultaten zijn en dat het voor gaming workloads op 1440P bijvoorbeeld veel minder impact gaat hebben en dat is ook waarom ik eigenlijk geen grote fan ben van zulke marketing slides in artikels, maar soms moet je het er helaas mee doen omdat er niet meer informatie bekend is, maar neem het dan wel met een korrel zout totdat de cijfers onafhaneklijk gevalideerd zijn door de techpress.
[Reactie gewijzigd door Dennism op 22 juli 2024 15:43]
Nogmaals, leuk bedacht, maar een CPU heeft nou eenmaal minder in games invloed dan een GPU, omdat een CPU zich niet met pixels bezig houdt. Die doet per seconde een X aantal iteraties op: "als die richting op kijkend en vuurknop ingedrukt, doe vuur" en "projectiel is zo snel en is nu op die positie" en "op die positie loopt iemand, intersect met projectiel, doe -30 damage, doel health is nu 70", altijd gevolgd door een volgende instructie: "teken frame".
Dit zijn niet zulke cherry picked resultaten hoor, sterker nog, ik vindt ze heel transparant. Het gaat letterlijk om CPU in games, niet GPU, niet thermals. Ze hebben beide CPU's in deze tests zelfs locked op 4GHz, waardoor boost (of zelfs de baseclock) geen factor is. Beide zelfde infinity fabric, en memory settings, en dezelfde GPU, maar de "teken frame" calls zijn zo licht mogelijk gemaakt om dat geen invloed te hebben op de CPU test. 1080p, alles op low.
Dit is dan ook geen aankoop/game test, maar een CPU test. En niet eens cherry picked, want dan zou de boost erbij zijn gebleven
Daarnaast is niet elke game hetzelfde. Er zijn games waar 30fps goed genoeg is omdat het sightseeing games zijn, maar er zijn ook games waar 480fps niet goed genoeg is omdat ze competitive zijn. En daarnaast is niet elke game even goed in het omgaan met die draw calls, en moderne CPU's (zoals single-threaded drawcalls).
Als je de GPU meer zal belasten echter, dan is het vanzeflsprekend zo dat je een onbalans gaat genereren waar de GPU langer kan doen over een draw call, terwijl de CPU in principe al lang klaar is om aan het berekenen van de logic en input voor de volgende frame. En dat is de situatie waar je mee zit in de balans tussen CPU en GPU. En waarom zaken als een RTX3090 of Radeon RX6900XT aan een Zen basic APU (2200G) of een Intel Celeron zo belachelijk zijn. En waarom je eigenlijk alle componenten los moet testen, voordat je de balans gaat testen.
Het doel van deze CPU tests was om aan te tonen wat de impact zou kunnen zijn zonder een GPU bottleneck. Met een GPU bottleneck (door 1440p en high settings) is het afwachten. Maar dan is het niet de schuld van de CPU. Doet dit er iets aan af aan de vraag: "heb ik nu iets aan deze CPU?" Nee. Wacht de reviews af daarvoor. Doet dit iets er aan de vraag: "zit er potentie in deze CPU"? Hell yeah. Sterker nog, ik ben (met mijn 3960x) eigenlijk altijd CPU limited en dat zit vooral in cache misses. Ik werk met data waarbij de luxe van een pre-rendered LoD niet bestaat, dat is meer iets voor het eindresultaat.
Overigens blijft het bottleneck getouwtrek altijd een factor. Voor de voorbeelden hierboven (waar ik een RTX3090 aanhaal) zal de monitor sneller een bottleneck zijn dan de CPU of GPU als we het over 1080p hebben, overigens. Voor mij is de bottleneck nu geheugen/geheugensnelheid/cache, want PCIe is het zeker niet meer. Maar dat is mijn exotische GIS-werk. Als dat weg is, gok ik dat ik weer een GPU bottleneck ga hebben, en dan pas weer een echte CPU-rekenbottleneck. Tegen die tijd zit ik weer aan een storage bottleneck, en zo schuift dat altijd weer rond.
Puur voor je games? Tsja, wat deze tests aangeven is dat als de CPU niet hoeft te wachten op de GPU, dat er door cache misses op te lossen best veel te halen valt. Zodra je een dikke schijfrem er op legt in de vorm van een GPU (en driver overhead...), zal het best kunnen dat je er niets aan hebt. Maar nogmaals: dat was niet de essentie hiervan. Genoeg CPU workloads in-games en ook buiten games die er wel wat aan hebben (denk aan de Civ gamers, die lang op turns moeten wachten, waar FPS niet de benchmark score is!)
Dit zijn niet zulke cherry picked resultaten hoor, sterker nog, ik vindt ze heel transparant. Het gaat letterlijk om CPU in games, niet GPU, niet thermals. Ze hebben beide CPU's in deze tests zelfs locked op 4GHz, waardoor boost (of zelfs de baseclock) geen factor is. Beide zelfde infinity fabric, en memory settings, en dezelfde GPU, maar de "teken frame" calls zijn zo licht mogelijk gemaakt om dat geen invloed te hebben op de CPU test. 1080p, alles op low.
Dit is dan ook geen aankoop/game test, maar een CPU test. En niet eens cherry picked, want dan zou de boost erbij zijn gebleven
Maar dat is nu juist wat ik cherry picked vind, ze zoeken immers een scenario waarbij ze de grootste verschillen kunnen laten zien, vanuit marketing logisch, maar dat is nu ook wat de initiele vraagsteller lijkt te bedoelen, niemand gebruikt het product zo in de praktijk.
Dat het verder logisch is dat ze vanuit AMD op deze manier testen ben ik volledig met je eens, echter doet dat niets af aan de vraag van @biggydeen2, die voor de meeste consumenten veel belangrijker zal zijn dan de theoretische verschillen in scenario's waar zij nooit mee in aanraking zullen komen, en dat maakt voor mij dat je eigenlijk niet kan spreken van '3D V-Cache in de praktijk' zoals de laatste pagina in het artikel heet, want juist praktijk resultaten zien we niet (afgezien van door de fabrikant gegeven benchmarks die niet onafhankelijk gevalideerd kunnen worden).
[Reactie gewijzigd door Dennism op 22 juli 2024 15:43]
Nee. Dit is geen cherry picking. Sowieso is het niet relevant of jij het wel of niet cherry picking vindt. Umbrah legt je volgens mij bijzonder helder uit waarom deze testopzet zo transparant (en fair) is.
Ik denk dat je het meer met hem eens bent, dan je in eerste instantie denkt. Lees zijn stuk nog eens goed door.
Mijn korte argumentatie:
Door bewust ver weg te blijven van bottlenecks bij andere componenten, is het effect van de nieuwe toepassing van Cache goed te zien. Dat dit in allerlei andere situaties, waar mensen wel/niet met bottlenecks te maken hebben, een ander totaalplaatje van een pc laat zien, is niet relevant.
Dit is een prima eerste benchmark met resultaten in de praktijk: het is een praktijksituatie waarbij alle instellingen helder zijn toegelicht. Theoretische resulaten krijg je door berekeningen te maken op basis van doorvoersnelheden, etc, maar dit is gewoon een praktijksituatie. Ik kan er niks anders van maken.
Jij mag over een jaar een prachtige review schrijven waarin je aangeeft wat 'jouw praktijksituatie' is. Daar geef je dan netjes bij aan wat al je andere componenten en settings zijn. Dan kan iemand bepalen of hij/zij iets aan jouw meetresultaten heeft.
@Dennism heeft eigenlijk wel gelijk dat het een vorm van cherry picking is. Het is inderdaad een bedacht scenario om groteren verschillen te laten zien. Waar @Umbrah wel gelijk in heeft is dat dit scenario juist gekozen is om de kracht van de processor aan te kunnen tonen en dat je dan andere componenten (GPU) zo veel mogelijk moet uitsluiten. Als die de bottleneck gaan vormen presenteer je niet meer de potentiële kracht van de CPU.
Als je het totale "real world" effect wilt laten zien, dan zal je de processor wel moeten testen met een game in de gangbare (hoge) resolutie. Als @Dennism de real-world effecten wil zien zal hij nog even geduld moeten hebben totdat er complete systemen met de nieuwe CPU's worden getest.
Zoals altijd moet je een test afstemmen op wat je werkelijk wilt testen. Als je de smaak van een kers wilt testen, dan gebruik je toch ook alleen rijpe kersen? Dat kan je cherry picking noemen, maar het wordt wel met de juiste intentie gedaan en netjes beschreven.
Maar juist het zo inrichten van een test dat je de voor jou beste resultaten krijgt is een voorbeeld van cherry picking en dat is nu net wat AMD hier doet (wat uiteraard volledig logisch is vanuit AMD's oogpunt), ze kiezen hier logischerwijs voor test variabelen die deze nieuwe toepassing van cache is het beste daglicht laten zien. En daar is vanuit een marketing oogpunt niets mis mee maar zeg niet dat deze test variabelen niet cherry picked zijn, wat die zijn echt wel heel bewust zo gekozen, net zoals dat je heel bewust ervoor gekozen hebben om andere variabelen juist niet te laten zien. Dat ze duidelijk aangeven met welke variabelen ze getest hebben (wat inderdaad goed is), maakt niet dat de set variabelen niet zorgvuldig uitgekozen zal zijn en dat is gewoon een vorm van cherry picking.
Dat het een praktijk situatie laat zien ben ik niet geheel met je eens, hoewel de workload er een is die in de praktijk zeker voorkomt, zijn andere variabelen namelijk zaken die je juist normaliter niet terug ziet in de praktijk. Nu zal er vast een uitzondering zijn die de regel bevestigd, maar over het algemeen zal een gebruiker van dit soort cpu's deze bijvoorbeeld niet locken op een bepaalde, voor deze cpu's vrij lage, frequentie en alle games die deze gebruiker speelt instellen op low settings.
Of deze test met de uiteindelijke praktijk resultaten van de gekende reviewers overeen zal komen is toch echt maar zeer de vraag. Misschien wel, maar voordat deze resultaten van AMD door 3de partijen gevalideerd kunnen worden, moet je ze echt met een flinke korrel zout nemen.
Daarnaast weet je bijvoorbeeld ook niet wat deze cache chip (en dummy silicon spacers) gaan doen voor de performance in relatie met de koeling. Het is goed mogelijk dat een chip met deze cache misschien wel een iets lagere frequentie haalt bij een bepaalde workload omdat het koelen lastiger gaat zijn, waardoor het nu testen op gelijke frequentie uiteindelijk een vertekend beeld kan geven.
[Reactie gewijzigd door Dennism op 22 juli 2024 15:43]
Dit is simpelweg het cherry picken van een test zodat je de beste resultaten kunt laten zien. Dit is totaal geen praktijksituatie. Wie gaat er een 5900x kopen en vervolgens gamen op 1080p?
In een praktijktest zonder cherry picking hadden ze ook de resultaten op 1440p en 4k kunnen laten zien. Het feit dat ze dit niet hebben gedaan zegt al genoeg. Het is verder een mooie technologie en weer een stapje vooruit. Als ze dan toch aan het testen zijn laat dan alle resultaten zien. Nu krijgen we alleen het beste resultaat wat mogelijk is voorgeschoteld. Niet realistisch en niet relevant in de praktijk.
Een CPU heeft behoorlijke impact. Helemaal als je een oudere cpu hebt met een recente GPU. Als je nu nog een 4 core cpu hebt is het zelfs beter om je CPU te upgraden naar een recente 6 core dan een 3080 te halen.
Maar het punt blijft: CPU's blijven veel minder benut in games dan de GPU. Grafisch worden games steeds uitdagender en dus zijn er elke paar jaar nieuwe GPU's. De CPU wordt steeds minder belangrijk in games, waar de GPU steeds meer taken overneemt, kijk maar eens naar raytracing. De GPU architectuur is voor gamemakers veel interessanter dan de CPU.
Ja, je hebt wel games waar je veel rekenwerk hebt dat niet parallel verwerkt kan worden via bijvoorbeeld de CUDA cores, en de CPU dus belangrijk blijft, maar dat zijn er maar een handjevol en meestal blijft dat bij twee specifieke genres. Sims en strategy games.
En binnen die genres is dan ook nog maar de vraag of deze 3D Vcache nut heeft, meestal draaien zulke games op een paar cores waarbij het rekenwerk allemaal via 1 thread gaat, omdat alles nu eenmaal een voor een verwerkt moet worden, en frequency dus veel belangrijker blijft.
[Reactie gewijzigd door MrFax op 22 juli 2024 15:43]
maar uiteindelijk als koper wil je weten, tijdens het lezen van reviews, wat voor praktisch nut het heeft in jouw systeem en de workloads die jij draait
Maar dit is geen review. Dit is een achtergrondartikel. En elke persoon gebruikt zijn computer anders en heeft ook een andere computer. Jouw workloads zijn anders dan de mijne. Je moet dus zelfs in reviews alsnog een zo algemeen mogelijk beeld geven.
Dat het geen volledige review is ben ik met je eens, maar als je dan titels als '3D V-Cache in de praktijk' gebruikt, verwacht ik wel iets meer dan de niet verifieerbare resultaten van de fabrikant. Immers zijn die behaald in een setting die je in de praktijk nooit tegen zal komen.
Je moet toch voor iedere game zelf even bepalen of jouw huidige CPU de bottleneck is en het dus wel/niet waard is om die te upgraden. De te verwachten prestatie winst kun je prima afleiden van deze benchmarks, juist omdat alleen de pure rekenkracht van de CPU tentoon gesteld wordt.
Dat afleiden kan juist niet direct, omdat dit heel erg workload, en binnen gaming workloads, heel erg resolutie afhankelijk is, van deze 1080P low resultaten op een fixed frequency kun je dus bijvoorbeeld geen 1080P extreme of 1440P Ultra resultaten afleiden, die kunnen immers heel anders schalen met de gebruikte hardware.
Je verwacht toch niet werkelijk dat ze alle games op alle resoluties en alle grafische instellingen gaan testen? Je kunt met deze set benchmarks prima trends aflezen. Een game die nauwelijks afhankelijk is van de CPU gaat er 4% op vooruit, een game die flink afhankelijk is van de CPU kan tot 25% beter presteren. Vervolgens moet jij even kijken of de games die je speelt vooral CPU of GPU afhankelijk zijn in jouw scenario, waarmee je prima kunt bepalen of deze nieuwe CPU voor jou geschikt is.
Deze reactie krijg ik wel vaker. Een CPU test je in de praktijk. Niet op resoluties die je nooit gaat gebruiken. Niemand koopt een 5900x om vervolgens op 1080p te gamen.
Vanuit AMD snap ik prima dat ze het zo laten zien. Alleen wordt nu het beeld geschetst dat games in average 15% meer fps hebben. Wat dus niks zegt als er in het artikel geen resolutie wordt genoemd. Uberhaupt vreemd dat het niet wordt genoemd want in de presentatie werd het wel genoemd.
Je wilt als consument toch weten wat je koopt en of het voor jou zin heeft of een upgrade waard is? Oftewel je wilt een test zien op alle resoluties. Dit weer duidelijk een marketing praatje.
Nee, nogmaals, in de kleine tekst er onder staat ook: "getest op 1080, low, met de CPU's beiden locked op 4GHz". Het zijn bovendien beide Zen3 CPU's, ipv concurrentie, en de GPU is ook hetzelfde. Dit is geen consumenten demo voor systemen, dit is een demo voor enkel en alleen de CPU. Voor de echte performance moeten we sowieso veel games afwachten. CS:Go spelers eisen praktisch 1080p, en willen op hun 360Hz schermen minstens 480fps (immers +33% voor overlap compensatie) halen, en zullen eigenlijk nooit door hun GPU begrenst zijn, maar puur de CPU die snel genoeg drawcalls naar de GPU driver moet pushen.
CiV gamers geldt hetzelfde voor: niet voor de FPS, maar meer om de beurten te berekenen.
Ga je Doom Eternal spelen? Ja, laat dan maar. Ik zou die CPU verkopen en er een Arduino of RBPi CPU in proberen te rammen, want alles is wel genoeg zolang je de GPU maar hebt (mijn CPU valt in slaap tijdens Doom, terwijl m'n GPU naar 350W verbruik jumped).
Maar dat weet ik puur omdat ik de CPU counters bekijk. Zodra je de statistiek L2miss langs ziet komen, dan is dat een teken dat je baat hebt bij meer cache:
Ehhh, dit is een consumenten demo gericht op gamers. Aan wie hebben ze anders +15% performance on average in games" gericht?
Je bedoelt CS:Go proffesionals die jarenlang dag en nacht spelen. Deze mensen kunnen baat hebben bij 360hz. Er is geen enkele casual gamer die een 5900x gaat kopen om op 1080p Cs:Go te spelen.
Doom Eternal is net zo goed afhankelijk van een snelle CPU. Helemaal als je nu nog een oudere quadcore hebt. Dan kun je beter upgraden naar een recente hexacore in plaats van een 3080 te halen. Doom Eternal spelen op een Arduino of Rasberry omdat je enkel een snelle GPU hebt is natuurlijk complete onzin.
Misschien is voor e-sports die 1080p prefereren misschien die FPS winst belangrijker. Dan de voor de lol thuis singleplayer met high-end kaart die sandbox game in 4K speeld en ook vooral van de gedetaileerde game world geniet. In ook slow paced game waar 30fps nog te doen is.
Dat ligt aan de game en de hardware. Op dit moment is de CPU vaak de bottleneck op 1080P, maar dat kan op termijn opschuiven naar 1440P. Er gaan geruchten dat de volgende generatie videokaarten flink wat sneller zijn waardoor een CPU eerder de bottleneck wordt. Bij dit artikel, dat over de techniek gaat en niet een specifiek product, lijkt het me logisch om te laten zien wat de prestatiewinst van de CPU kan zijn. Dat is als het testen van de topsnelheid van een Ferrari op de Nederlandse snelweg. Op 4k zou het een vertekend beeld geven omdat de CPU dan de extra performance niet kan gebruiken. Ook moet Tweakers het natuurlijk doen met de benchmarks die AMD heeft vrijgegeven.
Als Tweakers een review zou schrijven over een CPU met deze extra cache zou ik wel graag 1440p en 4k benchmarks zien.
[Reactie gewijzigd door Moortn op 22 juli 2024 15:43]
Dat doen echt heel veel mensen dus wel, ik ken genoeg personen met een 3080 die 1080p spelen voor meer FPS in games.
Zeker bij mensen die elke FPS belangrijk vinden gaat het niet op de graphics maar alleen de FPS.
Dat zegt vrij weinig. Ten eerste kopen
relatief weinig mensen een 3080 daarnaast heb je ook minstens een 240hz g of freesync nodig plus een vrij recente cpu. Die markt is echt heel klein plus naast het feit dat een normale gamer echt geen verschil meer ziet boven de 144hz.
Dat zegt natuurlijk niet zoveel, jij kent er genoeg, ik ken er exact 1, een van mijn maten is een competitief FPS speler en die speelt inderdaad op 1080P met een high refresh schem. Maar verder hebben de kopers bij alle systemen die ik de laatste jaren gebouw hebt voor 'friends en family' gekozen voor minimaal 1440P.
Dat soort kleine sample sizes zullen nooit een volledig beeld geven, wil je dat hebben zou zou je moeten kijken welk marktaandeel 240+ Hz 1080P schermen momenteel hebben, en het zou mij eigenlijk enorm verbazen als dat geen enorm kleine niche is.
[Reactie gewijzigd door Dennism op 22 juli 2024 15:43]
Er zal altijd klein e-sport groep waar 1080 p defacto standaard blijft.
En groepje zeer competatieve gamers.
Maar er komt ook nog groepje bij. Die gewoon beste moeten hebben omdat het CPU het in 1080p zo goed doet.
En zelden in 1080P gamen omdat gewoon voor de heb en tussende oren het beste moeten hebben en in reviews gevoelig zijn voor cijferneuk kroon poolpositie hardware.
Dan vierde soort dat zich blind staart op wie de kroon heeft en dan van dat merk de midrange spul koopt.
5de het zal voor merk ook als doel hebben prestige om halo product naar hoger niveau te kunnen pushen.
In de presentatie werd ook specifiek 1080p genoemd maar in dit artikel niet. Vandaar mijn opmerking.
Ik snap prima waarom ze het zo laten zien. Het is marketing. Logisch vanuit AMD. Voor mij als gamer heb ik hier niks aan totdat er meer resultaten zijn op hogere resoluties. Je wilt als consument weten wat je er zelf aan hebt. Niet wat het theoretisch allemaal kan.
Maakt niet uit. Naar mate je hoger gaat in resolutie is "CPU" niet langer meer van invloed. Zeker niet op 4K. Als je een FPS nerd bent en de hoogst mogelijke FPS op je 1080p scherm hebben wilt dan is een zo snel mogelijke CPU wenselijk.
Een CPU is wel degelijk belangrijk, ook op hogere resoluties. Die FPS nerd markt is zo ontzettend klein en vooral gericht op pro gamers. Boven de 144fps/Hz ga je weinig verschil merken en daarnaast heb je ook minimaal een 240/360hz g of freesync scherm nodig.
je moet testen in situaties waarin je hardware de bottleneck is. Als een ferrari door een woonwijk rijdt aan de toegelaten snelheid, dan kan je zijn top nog van 250 naar 320 verhogen, hij gaat daardoor niet sneller die wijk door zijn.
Dat hangt natuurlijk al van je doel. Wil je theoretische verschillen laten zien, dan test je die Ferrari inderdaad op het circuit.
Wil je laten zien dat de aspirant koper er daadwerkelijk aan heeft, dan je natuurlijk de normale gebruikersscenario's, waar rijden in woonwijken en op snelwegen uiteraard ook onder vallen, net als het testen of de Ferrari fatsoenlijk over een drempel komt en zal juist de performance op het circuit minder relevant zijn
Als ik eerlijk ben, heb ik, als ik mezelf verplaats in een gebruiker, meer interesse in het 2de dan in het eerste. Ik wil immers weten wat nieuwe hardware doet voor mijn workloads, niet wat het theoretisch kan doen in een workload die ik nooit zal draaien.
Dat is ook bijvoorbeeld ook de reden dat ik (bij mijn werkgever) wanneer een klant vergelijkingstesten wil van hardware we die testen doen met zo realistisch mogelijk traces, en zo min mogelijk met synthetische benchmarks.
[Reactie gewijzigd door Dennism op 22 juli 2024 15:43]
Ik ben het wel een beetje met je eens. Ja ik weet dat je met een lage resolutie de CPU verschillen duidelijker kunt zien. Maar zoals jij terecht zegt: in de praktijk levert het veel minder op.
Deze technologie zal vooral z’n weg vinden in de highend, gezien de extra kosten. En daar is 1440p en 4K toch echt wel de standaard.
Voor gaming lijkt me dit dus allemaal niet zo boeiend. Maar hoe zit het op andere vlakken (compileren, video, rendering, ML etc)?
Complimenten. Goed geschreven, en goede diepgang. Goede aanvulling: traditioneel in een geheugen-tiering lijst, waar een "cache miss" (een statistiek die je met milde turning perfect kan monitoren in Windows) een factor is, is er ná het dram nog een tier. Een tier die absurd veel trager is. Een tier die in tegenstelling tot al die andere caches wél persistent is (bij power loss ben je L1 t/m DRAM kwijt qua opgeslagen data/instructies). Ik heb het natuurlijk over de storage.
Het starten/booten/laden van een applicatie of een stuk daarvan, zoals een level, is dan ook eigenlijk niets meer dan data/instructies verplaatsen van de trage, persistent storage naar de snellere RAM en Cache levels.
Dit is overigens ook wat voor mij 3d XPoint zo spannend maakte: je had eindelijk een soort tier persistent storage die in de buurt van RAM lag. Hoewel in sommige aspecten de PCIe bus in z'n geheel (en daar kun je dan ook SSD's aan koppelen) qua volle bandbreedte in de buurt komt van RAM(vooral threadripper, met slechts 4 memory lanes maar toch 88 PCIe 4.0 lanes moet zich zorgen maken), is en blijft de heilige koe van optimalisatie nog steeds het niet hebben van cache miss. En dat zit in de hele boom. Doet u mij maar een paar TB persistent L1 cache, mevrouw Su. Hoewel ik t/m L3 an-sich de cache miss wel kan slikken hoor, dus een paar terrabyte persistent L3 is ook wel goed
L0 en L1 zijn zeer snel en low latency. Maar al snel te klein voor de task en task heeft vaker meer data en instructies die daar sowieso niet in passen. L2 is al tradeof kwa size en latency sommige task magertjes zijn en voldoende hebben aan L2 de L3 speelt bij data zware task de hoofd rol
Bij extreem data grote task is L4 performance bepalend.
Naast dat voor goed cache gebruik paradigma zoals functioneel , reactive en data-oriented programmeren beter en of optimaliseren voor prefetcher en cache goed gebruik van wordt gemaakt en dat ook multithreaded ook de paradigma beter licht.
Als je L1 van TB maakt heb je in principe een L4 cache zonder een L2 en L3 en kan je juist performance kosten want opzoek latency is dan ook gerelateerd aan de TB grote. Daarom zijn er die lagen dat is dus ook niet voor niks.
Vraag me af of dit impact heeft op APUs, en of dit daar ook gebruikt gaat worden. Die zijn over het algemeen nog afhankelijker van snel geheugentoegang.
Klopt, hoewel die de L1/L2/L3 caches vaak overslaan. Wat je wel vaak ziet is dat ze iets van 64MB SRAM aan boord hebben, wat min of meer juist die rol vervult.
Het is grappig te zien wat voor prioriteit cache algemeen krijgt tussen 'rekenchips'. Datacenter ARM/Sparc chips zie je vaak zelfs een soort L4 verschijnen, en de laatste generaties snapdragon kennen een soort "system cache" wat officieel dan geen L4 is maar wel dichter bij de SOC staat dan z'n 4x 16bit memory controller...
Apple heeft juist absurde hoeveelheden L1 cache aan z'n CPU's geplakt, en echt mega verschillen zie je niet.
GPU's blijft wat gek. nVidia Ampere kent in de max configuratie 216 SM's, met elke SM voorzien van een set registers, en eigenlijk alle eigenschappen voor een GPU. Inclusief max 164KB cache. In de compute versie van de kaarten (A100) zie je vervolgens ~20MB L1 voor de hele GPU in 108 blokken (1 per twee SM's), en ~40MB L2 cache. In een RTX3090 is dat ineens slechts 6MB, en vinden we geen info over L1. Tot GT200 was er zelfs helemaal geen cache, behalve het vram zelf... zelfs binnen dezelfde GPU familie, blijft het dus: gek.
Een geheugencache repliceert de data die in het geheugen staat. Je hebt pas wat aan een cache als je die data continue aanpast en opnieuw benaderd. Als je heel veel data moet halen uit het geheugen dan heb je niet zo heel veel aan een (grotere) cache.
Als bepaalde textures heel vaak worden hergebruikt dan kan een cache helpen. Als de data continue uit een andere locatie moet worden gehaald dan is de cache alleen maar een sta-in-de-weg.
Ik heb geen idee hoeveel voordeel je hebt van de cache in een GPU. Ik vermoed dat, zoals met alles GPU, dat het erg veel van het scenario zal afhangen (zowel het gerenderde scenario en het test scenario : ).
"For high performance computing" ... M.a.w het is een ding dat ontwikkeld is specifiek voor de Epyc lijn maar ook toegepast wordt in consumenten chips. Per toeval heeft het dan weer 15% meer performance voor games.
Dat is correct, alles wat AMD momenteel ontwerpt is eigenlijk om de perf/watt in servers naar boven te krijgen, meestal werkt dit dan ook goed op de consumenten tak. Ow Thread Rippers in workstations zullen daar ook baat bij hebben.
Ik had liever een test gezien wat het doet als je met databases of andere grote datasets speelt.
Exact: Google, Tencent, Baidu en Microsoft zijn deze technologie nu waarschijnlijk aan het testen in datacenters.
Maar óf de resultaten zijn nog niet bekend, óf ze willen ze niet met AMD delen gezien de concurrenten.
AMD wil de indruk wekken van een jarenlange pijplijn aan op stapel staande nieuwe product-verbeteringen, want veel kleinere server-klanten zitten nog vastgeroest op Xeon. Computex is een mooi podium want daar focust alle pers zich. Tevens gelijk mooie reclame voor TSMC haar 'advanced packaging' tak, vroeger huurde AMD daarvoor de TSMC-concurrenten ASE en STATS Chippac in vziw.
Dus tsja, dan in 's hemelsnaam maar gaming, dan snappen Epyc-klanten ook wel dat het nut heeft.
Xilinx heeft deze technologie overigens al jaren lang voor hun peperdure FPGAs (sinds 2016 dacht ik) en was trendsetter, Apple gebruikt veel TSMC InFO.
Intel heeft EMIB/Foveros, maar door de microbumps verbruikt dat makkelijk 35% meer stroom dan TSMC CoW (volgens TSMC). Dus op het gebied van efficiëntie is dit een gevoelige nederlaag voor Intel Xeon. Het zal interessant zijn wat zij als antwoord zullen introduceren.
[Reactie gewijzigd door kidde op 22 juli 2024 15:43]
Vraag me af wat de increased power usage is bij de genoemde 15% prestatie gain. Als dat minder dan 15% is, dan is dat zeker netjes. Als dat 100% schiet je er niet echt iets mee op.
Hou er rekening mee dat je processorklok niet omhoog hoeft. De vraag is dus eerder of het minder verbruikt dan dezelfde CPU die circa 10% hoger geklokt is. Maar ook dan is het niet geheel onzinvol, het is gewoon een extra troef om de performance te verhogen. Stel dat je CPU niet zo heel lekker maar omhoog schaalt in klokfrequentie, dan kan je toch nog de performantie verhogen via deze weg. Het verhogen van de cache kan misschien ook leiden tot het iets anders gaan balanceren van het CPU ontwerp, zou ik vermoeden.
Data van verder weg halen kost (veel) meer energie. Dus elk stukje data dat je uit de cache haalt ipv dat je helemaal naar het geheugen moet levert winst op voor verbruik. En extra L3 cache helpt daarbij.
Maar meer L3 kost ook energie om te hebben. Echter zolang je workload redelijk gebruik kan maken de cache (een dus niet bijna alleen maar bestaat uit random access) zal je hier onder de streep zuiniger uit komen
Dat de extra L3 er voor zorgt dat de cores beter van data worden voorzien betekend gewoon een hoger verbruik, maar die is in loon met de verbetering in prestaties.
De prestaties per watt zullen gemiddeld gezien denk ik hoger uit komen met de extra cache.
[Reactie gewijzigd door Countess op 22 juli 2024 15:43]
vraag me beetje af wat nu het effect zal zijn op bijvoorbeeld werken met een 5900x in een Adobe creative omgeving, premiere, after effects en photoshop dus. hoeveel voegt dit toe aan de al bestaande 5900x en hoeveel meer gaat die nieuwe proc zo kosten ?
Het kostenplaatje lijkt mij inderdaad nog het meest interessant. En er is nog zo goed als niet over gesproken.
Zoals het in de presentatie werd gebracht en in de video's van HWU en GN is het bijna een gratis extra.
We gaan het zien.
De op prestatie gerichte CPU's hebben 2 CPU chiplets. Als deze cache letterlijk en figuurlijk boven deze 2 komt te liggen, dan heb je eindelijk een unified L3 cache. Als een thread dan nogal ongelukkig van chiplet verspringt, is er minder penalty om de data op te gaan halen. Ipv naar het gewone ram geheugen te moeten, wat nu het geval is bij die CPU's, kan je dan terug vallen op snellere L3. Al wat simulaties etc aan gaat, zal er wel bij varen.
[Reactie gewijzigd door Jack77 op 22 juli 2024 15:43]

:strip_exif()/i/2004386274.jpeg?f=imagenormal)
:strip_exif()/i/2004394552.jpeg?f=imagegallery)
/i/2004394530.png?f=imagenormal)
:strip_exif()/i/2004394546.jpeg?f=imagegallery)
:strip_exif()/i/2004394548.jpeg?f=imagegallery)
:strip_exif()/i/2004394542.jpeg?f=imagegallery)
:strip_exif()/i/2004386284.jpeg?f=imagegallery)
/i/2004394980.png?f=imagegallery)
:strip_icc():strip_exif()/i/2005002394.jpeg?f=fpa_thumb)
/i/2004611214.png?f=fpa)
/i/2004983532.png?f=fpa)
:strip_exif()/i/2005651656.jpeg?f=fpa)
:strip_exif()/i/2005738708.jpeg?f=fpa)
:strip_exif()/i/2005168382.jpeg?f=fpa)
:strip_exif()/i/2005279580.jpeg?f=fpa)
/i/2005551282.png?f=fpa)
:strip_exif()/i/2005121904.jpeg?f=fpa)
/i/2004646380.png?f=fpa)
/i/2004919460.png?f=fpa)
/i/2004716534.png?f=fpa)
/i/2004828994.png?f=fpa)
:strip_exif()/i/2004729486.jpeg?f=fpa)
:strip_exif()/i/2004609702.jpeg?f=fpa)
:strip_exif()/i/2001610695.jpeg?f=fpa)
:strip_icc():strip_exif()/u/1013875/crop5cb9ab952214e_cropped.jpeg?f=community)
/u/1436766/crop618e3e0324655_cropped.png?f=community)
/u/175440/crop5b5f0d899a5e8_cropped.png?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
:strip_icc():strip_exif()/u/341611/crop59bdeb03f3805_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
/u/183354/day.png?f=community)
:strip_icc():strip_exif()/u/1157718/crop5e6d5ebf96a5f_cropped.jpeg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
/u/72143/crop5e4c3cfd5f71d_cropped.png?f=community)
:strip_icc():strip_exif()/u/269054/crop6064049cee9ab_cropped.jpg?f=community)
/u/115333/crop5f45784fcadad_cropped.png?f=community)
:strip_icc():strip_exif()/u/92491/crop64a1593f33a7b_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/83337/countess6-nice.jpg?f=community)
:strip_icc():strip_exif()/u/25009/crop65f1e3109d1b7_cropped.jpg?f=community)
:strip_exif()/u/31303/HMC2.gif?f=community)