Twee jaar wachten
Ruim twee jaar geleden alweer, in mei 2016, introduceerde Nvidia zijn eerste Pascal-videokaarten voor consumenten, met de GTX 1080 en de GTX 1070 die het spits afbeten. De serie werd in de loop van enkele maanden aangevuld met onder meer de GTX 1050 en de 1060 en in maart 2017 de GTX 1080 Ti. De laatste uitbreiding in de Pascal-serie waren de instappers GT 1030 en een 3GB-variant van de GTX 1050. In grote lijnen ligt de Pascal-introductie echter dik twee jaar achter ons en dus is het hoog tijd voor een nieuwe architectuur en natuurlijk nieuwe kaarten.
Die nieuwe architectuur is er gekomen met de Turing-generatie kaarten. De eerste kaarten werden voor Nvidia's zakelijke Quadro-serie aangekondigd, maar ook voor de consumenten- dan wel gamingmarkt zijn drie kaarten aangekondigd: de RTX 2070, 2080 en 2080 Ti. Die aanduidingen zijn om twee redenen opmerkelijk. Ten eerste stapt Nvidia daarmee af van zijn gebruikelijke GTX-naamgeving en ten tweede introduceert het bedrijf al bij de eerste lichting een Ti-kaart.
De nieuwe RTX-naamgeving lijkt vooral te verwijzen naar een van de nieuwe mogelijkheden van de Turing-kaarten: real-time ray-tracing. Met ray-tracing wordt het pad van licht en de reflecties ervan berekend, en als dat in real-time gebeurt, levert dat realistische gamebeelden op. Voor we naar prestaties van kaarten kijken, duiken we eerst in de architectuur van Turing: wat mag je van de nieuwe features van de kaarten verwachten?

Turing: een nieuwe architectuur
Terminologie
sm: streaming multiprocessor
fp32: floating point-core, ook wel cuda-core genoemd
int32: integer-core
tpc: texture/processing cluster
rop: raster operation processor
Voor we in de Turing-architectuur duiken, bekijken we eerst de grootste verschillen met Pascal en de Quadro-kaarten. Pascal werd twee jaar geleden geïntroduceerd. De GTX 1080 Ti met de GP102 telde 28 sm's met ieder 128 fp32-cores, voor een totaal van 3584 cuda-cores. Samen met 4MB L2-cache telt de GP102-gpu ongeveer 12 miljard transistors die op 16nm geproduceerd werden. De Turing-gpu in de RTX 2080 Ti telt 4352 cuda-cores, ondergebracht in 64 sm's en gecombineerd met 6MB L2-cache. Dat is goed voor maar liefst 18,6 miljard transistors, die op 12nm worden gemaakt. De tdp's zijn ongeveer gelijk met 250W, hoewel de iets hoger geklokte Founders Edition van de 2080 Ti een tdp van 260W heeft, terwijl de FE van de 1080 Ti dezelfde tdp van 250W heeft als de gewone versie. De 1080 Ti FE heeft dan ook dezelfde kloksnelheden als de gewone versie, terwijl de 2080 Ti FE een hogere boost clock heeft dan de gewone 2080 Ti. We zetten de belangrijkste eigenschappen van de chips op een rij in onderstaande tabel.
| Turing vs Pascal |
RTX 2080 Ti |
GTX 1080 Ti |
Quadro RTX 600 |
Quadro 6000 |
| Architectuur |
Turing |
Pascal |
Turing |
Pascal |
| Chip |
TU102 |
GT102 |
TU100 |
GT100 |
| Transistors |
18,6 miljard |
12 miljard |
18,6 miljard |
12 miljard |
| Procede |
12nm |
16nm |
12nm |
16nm |
| Die-afmeting |
754mm |
471mm |
754mm |
471mm |
| Tpc |
34 |
28 |
36 |
30 |
| Sm's |
68 |
28 |
72 |
30 |
| Cuda/sm |
64 |
128 |
64 |
128 |
| Cuda-cores |
4352 |
3584 |
4608 |
3840 |
| Tensor-cores |
544 |
0 |
576 |
0 |
| Rt-cores |
64 |
0 |
72 |
0 |
| Rop's |
88 |
88 |
96 |
96 |
| Texture units |
272 |
224 |
288 |
240 |
| Geheugen |
11GB gddr6 |
11GB gddr5x |
24GB gddr6 |
24GB gddr5x |
| Geheugenbus |
352bit |
352bit |
384bit |
384bit |
| Geheugenbandbreedte |
616GB/s |
484GB/s |
672GB/s |
432GB/s |
| L2-cache |
5632kB |
2816kB |
6144kB |
3072kB |
| Register/gpu |
17408kB (256kB/sm) |
7168kB (256kB/sm) |
18432kB (256kB/sm) |
7680kB (256kB/sm) |
| Baseclock (FE) |
1350MHz (1350MHz) |
1480MHz (1480MHz) |
1455MHz |
1506MHz |
| Boostclock (FE) |
1545MHz (1635MHz) |
1582MHz (1582MHz) |
1770MHz |
1645MHz |
| Tdp (FE) |
250W (260W) |
250W (250W) |
260W |
250W |
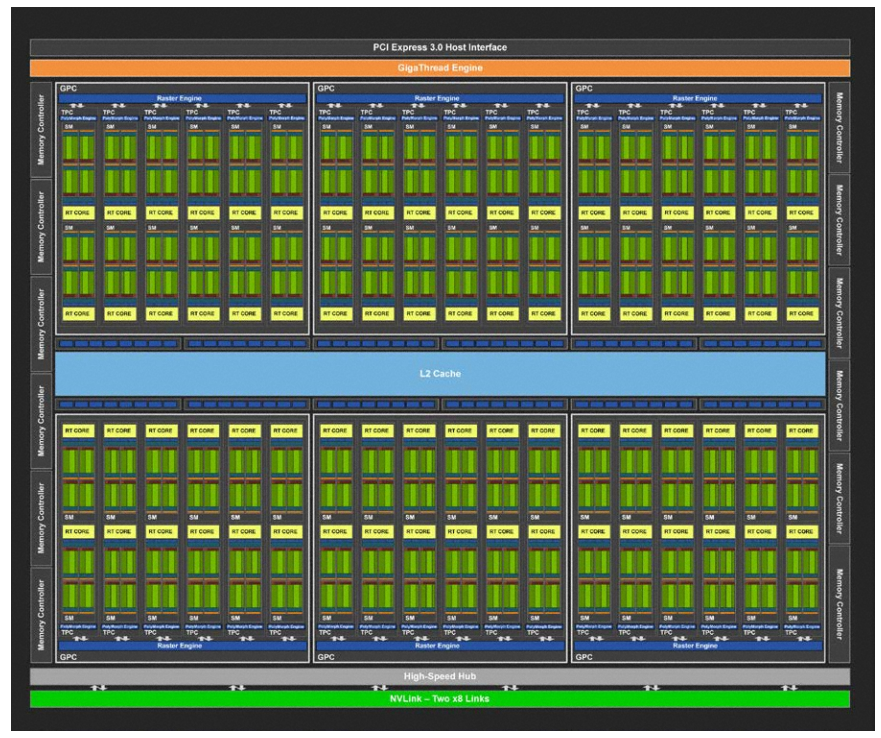
Nvidia heeft zijn streaming multiprocessors voor de Turing-architectuur behoorlijk aangepakt. Dat begint met de samenstelling van deze bouwstenen van de gpu: de streaming multiprocessors die in tpc's worden georganiseerd. Normaal zagen we in het verleden streamprocessors met wat cache en een x-aantal floating point-engines. De sm's van Turing, waarvan een volledige chip er 72 bevat, zijn veel complexer opgebouwd.
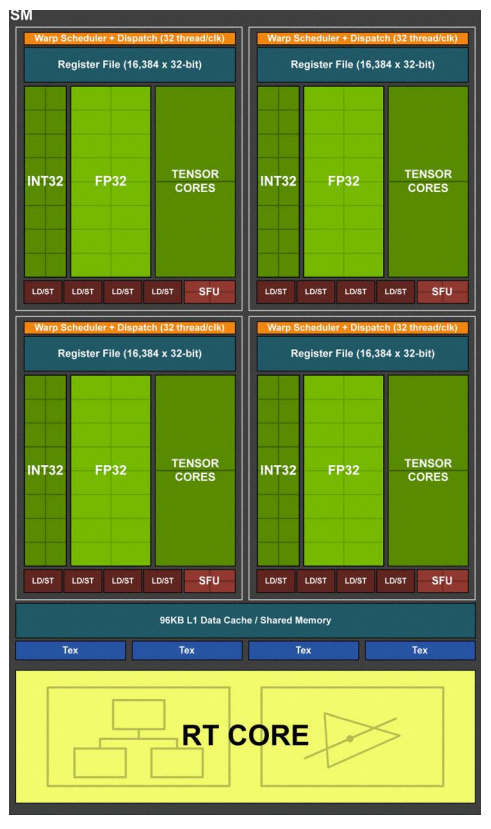
In Pascal bevatten tpc's één sm, maar Turing heeft twee sm's per tpc. De sm's zijn onderverdeeld in vier blokken met elk 16 int32- en 16 fp32-cores. Dat betekent dat een Turing-sm in totaal 64 fp32-cores heeft, waar Pascal 128 fp32-cores heeft. Bij Pascal houdt het dan echter op wat rekencores betreft, maar Turing heeft naast de 64 fp32-cores nog eens 64 int32-cores en 8 tensor-cores en een enkele raytracing-core. Daarmee heeft de Turing-sm dus drie nieuwe elementen in de streamprocessor, die we stuk voor stuk nalopen.
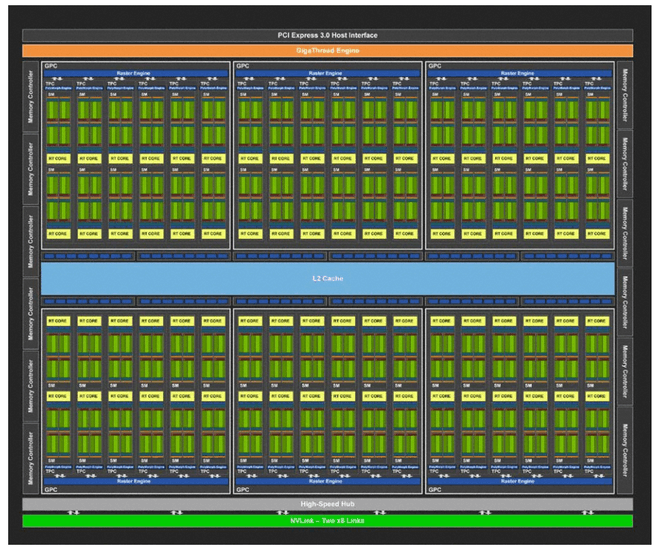
We beginnen echter bij de bekende onderdelen: de fp32-units en de caches, geheugen en omliggende hardware. De processor of cpu prepareert een scène met onder meer draw calls, waarna de gpu aan de gang moet om alle onderdelen invulling te geven. Daarvoor moet eerst de scheduler en dispatch de opdrachten verwerken en naar de verwerkingseenheden sturen. Daarvoor heeft elk blok in een Turing-sm een warp scheduler en dispatch-unit beschikbaar die 32 opdrachten per kloktik kan versturen. Elk blok heeft een eigen L0-instructiecache en register van 64kB.
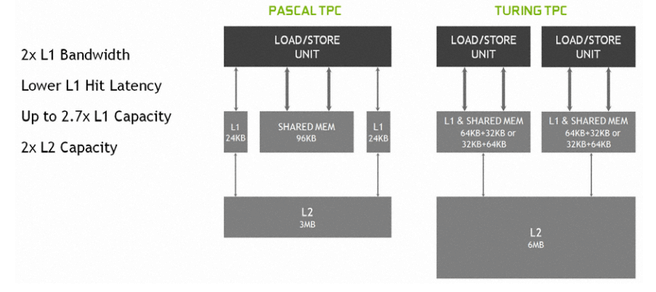
De vier logische blokken van een Turing-sm delen L1-cache. Die cache- en geheugenverdeling van Turing is echter behoorlijk aangepakt, het gereserveerde, gedeelde geheugen is namelijk verdwenen. In Pascal beschikten ontwikkelaars over een enkele load/store-unit per sm, met 24kB L1-instructiecache en 24kB L1-datacache en een flinke hap van 96kB geheugen dat naar wens ingezet kon worden. In Turing is dat gedeelde geheugen bij de L1-cache ondergebracht en zijn de load/store-units gesplitst, zodat gelijktijdig de integer- en floating point-cores aangestuurd kunnen worden.
Beide executiepijplijnen beschikken over een blok van 96kB gecombineerd L1-cache en gedeeld geheugen. Die blokken van 96kB kunnen onderverdeeld worden in 64kB L1-cache en 32kB geheugen, of andersom, al naar gelang traditionele dan wel compute-workloads gedraaid worden. Daarmee is de bandbreedte naar het L1-cache verdubbeld, omdat er geen aparte bandbreedte meer nodig is voor het gedeelde geheugen en bovendien is de capaciteit aan L1-cache maximaal 2,7 maal zo groot, van 24kB naar 64kB. Ook het L2-cache is verdubbeld van 3MB naar 6MB in Turing, voor de complete gpu.
Integer- tensor- en rt-cores
 De grootste verandering in de Turing-architectuur zien we in de extra cores die de streamprocessors hebben gekregen. Naast de traditionele fp32-cores heeft elke sm in Turing ook zestien integer-cores. De gedachte hierachter is dat steeds meer werklast voor videokaarten niet langer puur floating point-berekeningen vergen, maar ook integer-berekeningen. Volgens een analyse van Nvidia zouden gemiddeld voor elke 100 floating point-instructies 36 integer-instructies van een gpu gevraagd worden. Nu kunnen en worden die momenteel gewoon door de fp-units uitgevoerd, maar op een int-unit kost dat én minder transistors én het maakt de fp-unit vrij voor floating point-operaties.
De grootste verandering in de Turing-architectuur zien we in de extra cores die de streamprocessors hebben gekregen. Naast de traditionele fp32-cores heeft elke sm in Turing ook zestien integer-cores. De gedachte hierachter is dat steeds meer werklast voor videokaarten niet langer puur floating point-berekeningen vergen, maar ook integer-berekeningen. Volgens een analyse van Nvidia zouden gemiddeld voor elke 100 floating point-instructies 36 integer-instructies van een gpu gevraagd worden. Nu kunnen en worden die momenteel gewoon door de fp-units uitgevoerd, maar op een int-unit kost dat én minder transistors én het maakt de fp-unit vrij voor floating point-operaties.
De scheduler van Turing kan twee blokken tegelijk aansturen, zodat integer- en floating point-operaties tegelijk, zij aan zij, kunnen worden uitgevoerd. Dat levert volgens Nvidia een flinke winst op in shading-prestaties. Maar ook twee andere willekeurige blokken kunnen gelijktijdig werken, zoals de nieuwe tensor- of rt-cores.
Een tweede nieuwe rekencore in Turing naast de integer- en fp32-cores is de tensor-core. Deze cores moeten, net als ze in deep learning-hardware doen, voor verbeterde prestaties in matrixberekeningen zorgen. In Pascal kunnen ook matrixberekeningen worden uitgevoerd, maar in de fp32-cores gaat dat minder efficiënt dan in tensor-cores. Die zijn namelijk speciaal ontworpen om matrixvermenigvuldigingen uit te voeren, wat bij neurale netwerken, een hoeksteen van deep learning, machine intelligence en artificial intelligence, van belang is. Waar die neurale netwerken voor gebruikt worden bekijken we straks.
De laatste nieuwe core in Turing is de raytracing-core, waar Nvidia zoveel aandacht aan besteedde tijdens Gamescon in Keulen. Hoewel raytracing al een jaar of veertig wordt gedaan, is het extreem rekenintensief en complex. Door speciale cores in de Turing-sm's in te bouwen die niets anders kunnen dan raytracing kunnen enerzijds meer stralen geraytraced worden en blijven de traditionele bouwblokken vrij voor andere zaken, zoals shading.
Raytracing: de heilige graal?
Een kleine opfriscursus over raytracing is voor Turing misschien wel op zijn plaats, want wat maakt die techniek zo bijzonder en gewild? Alle videokaarten tot dusver renderen een scéne door alle objecten daarin te vertalen naar een raster, dat als pixels op een scherm getoond kan worden. De juiste vormen worden zo omgezet van de polygonen naar pixels. Om alle pixels de juiste kleur, verlichting en structuur te geven, worden ze door de shading-engine aangekleed.

Raytracing werkt door nog steeds een 3d-scene op te bouwen uit objecten of polygonen, maar in plaats van een rasterisatie en shading op de zichtbare objecten los te laten, wordt het uiterlijk van elk zichtbaar oppervlak berekend met licht. Elke weerkaatsing van een lichtbron op een object levert kleur- en textuurinformatie op voor de kijker. Stel een lichtstraal van een lamp voor, die op een houten tafel met daarop een porseleinen kopje schijnt. Het hout reflecteert een deel van het licht en absorbeert een deel, wat de kleur en helderheid van het hout definieert. Bij het kopje gebeurt hetzelfde, maar omdat het ander materiaal is, reflecteert het meer licht en is het dus lichter en witter. Maar ook het hout reflecteert licht op het kopje en vice versa. En misschien is er een muur, die ook licht direct naar de camera of kijker reflecteert. Bovendien reflecteert een deel van het licht van de lamp via de muur naar het kopje en de tafel, en vice versa. Zo kun je wel even doorgaan en al snel besef je dat ray tracing een nogal rekenintensieve aangelegenheid is.
Nu is dat deels te ondervangen door niet alle lichtstralen van een lamp of andere lichtbron door te rekenen, maar alleen de stralen te berekenen die het oog dan wel de camera bereiken. De makkelijkste manier om dat te doen is de lichtstralen niet van een lichtbron 'af te vuren', maar vanaf het oog dan wel de camera. Alle lichtstralen die niet zichtbaar zijn, hoeven zo niet berekend te worden, wat een flinke besparing in de rekenlast oplevert.
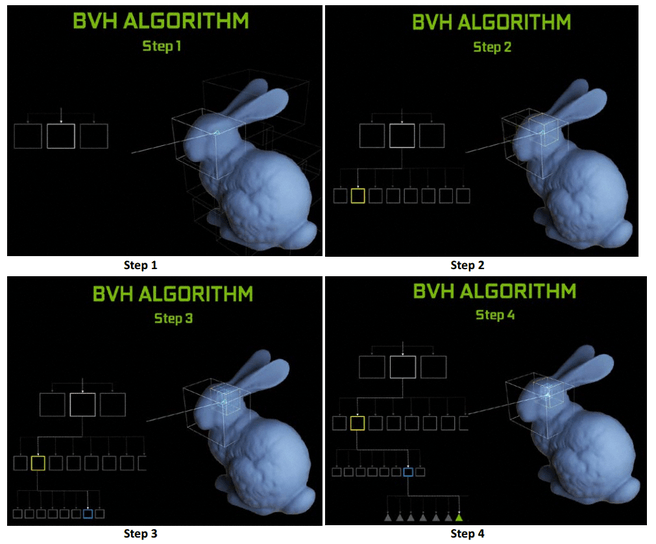
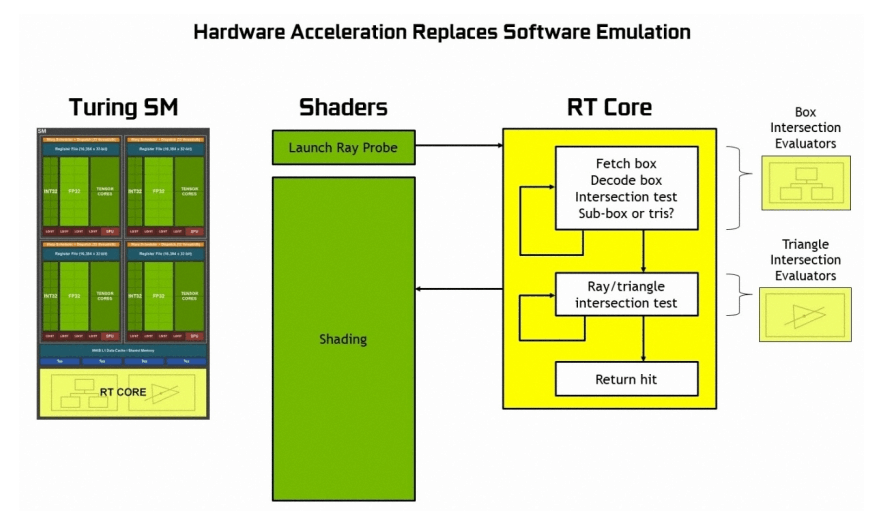
De rt-cores van Nvidia's Turing doen precies dat, en om het rekenen nog wat sneller en eenvoudiger te maken, moet het aantal mogelijke triangles waarop een willekeurige lichtstraal daadwerkelijk botst zo snel mogelijk gereduceerd worden. Het is immers nogal een karwei om van elk straaltje licht dat wordt uitgezonden te berekenen of hij een willekeurig oppervlak raakt. Daarom wordt de scene in steeds kleinere blokken opgedeeld waarbinnen de lichtstraal zijn doel heeft, om uiteindelijk bij de triangle uit te komen. De rt-core regelt de berekening van dit bounding volume hierarchy-algoritme en de identificatie van daadwerkelijke objecten waarop een lichtstraal valt, waarna een shader het mag overnemen en bedenken hoe dat oppervlak er uit moet zien. Ter vergelijking: in Pascal en de gpu's daarvoor moest al dit werk in de floating point-unit uitgevoerd worden, die daar niet voor gemaakt is en dus ook niet bijster snel erin is.
In Turing kunnen de rt-cores per seconde zo'n tien miljard stralen doorrekenen, waar dat bij Pascal op een fractie van zo'n tien procent bleef hangen. Dan nog is het raytracen van Turing-kaarten niet de heilige graal die het lijkt, want ondanks tien miljard rays per seconde kan een scène nog steeds niet volledig geraytraced worden in realtime. In plaats daarvan wordt raytracing ingezet om bepaalde effecten, zoals schaduwen, reflecties en lichtschijnsel realistisch weer te geven. Het is dus meer een soort ShadowWorks of volumetric lighting-techniek.
Deep learning en ai
Normaal zouden we tensor-cores en de daarmee geassocieerde termen als deep learning, neural nets en ai, in accellerator-kaarten voor de zakelijke markt verwachten. Nu is de Turing-architectuur natuurlijk ook terug te vinden in Nvidia's Quadro RTX-kaarten die iets voor de Geforce RTX-kaarten werden aangekondigd.
Voor neurale netwerken worden hoofdzakelijk matrixvermenigvuldigingen doorberekend en een tensor-core is daar stukken beter in dan een floating point-unit in de Pascal-en eerdere sm's. Waar vroeger een matrix rij voor rij vermenigvuldigd werd, kan nu in een keer een hele matrix worden vermenigvuldigd. Die extra snelheid kan in consumentenkaarten worden ingezet om real-time de beeldkwaliteit op te schroeven.

Nvidia heeft daartoe een neural graphics framework ontwikkeld, waarmee neurale netwerken getraind worden om beeld te verbeteren. Dat trainen gebeurt 'in de cloud' op supercomputers van Nvidia, waarna de getrainde modellen door de videokaartdriver kunnen worden gebruikt om de tensor-cores te laten rekenen. Game-ontwikkelaars kunnen dus Nvidia's supercomputers gebruiken om de neurale netwerken te trainen, waarna de 'oplossingen' voor beeldverbetering met behulp van neurale netwerken op het lokale systeem, via drivers of game-engines, realtime op frames kunnen worden toegepast. Uiteraard is daar een api voor in het leven geroepen die game-ontwikkelaars optioneel kunnen benutten.
Maar wat levert zo'n door een neuraal netwerk verbeterd plaatje op? Een van de mogelijkheden die Nvidia noemt is superresolutie, waarbij een frame meer detail weer kan geven dan wanneer het beeld wordt opgeschaald met ouderwetse technieken als nearest neighbor of bicubic resampling. Ook de-noising van beelden of het voorspellen van afbeeldingen die gerenderd moeten worden behoort tot te mogelijkheden. Volgens Nvidia zouden de tensor-cores voor 'eindeloze' mogelijkheden zorgen, van verbeterde ai van tegenstanders via de verwerking van stemcommando's tot de realistische animatie van gezichtsuitdrukkingen.

Een beeldverbeteringstechniek die al ontwikkeld is voor de tensor-cores is dlss, wat een afkorting voor deep learning super sampling is. Daarmee zouden de bekende kartelrandjes van objecten in een game netjes afgewerkt kunnen worden, met een beeldkwaliteit die minstens zo goed of beter dan technieken als taa is.Die technieken kunnen gecombineerd worden, waardoor Turing-kaarten tot twee keer betere anti-aliasing in staat zou zijn dan Pascal-kaarten. Dlss is vrij eenvoudig te implementeren, blijkens de grote hoeveelheid games die de techniek nu of in de toekomst gaat ondersteunen, waaronder PUBG, Shadow of the Tomb Raider en Hitman 2.
Alles bij elkaar
We hebben gezien hoe de Turing-architectuur in elkaar zit, met maar liefst drie nieuwe bouwstenen in een streaming multiprocessor. Naast de floating point-cores hebben we nu integer-cores, tensor-cores en raytracing-cores. Om al die cores aan het werk te houden, zijn de warp scheduler en de dispatcher in staat steeds twee van die blokken in te zetten en de cache-structuur is flink uitgebreid om voldoende data aan te leveren zodat de blokken zich niet vervelen.
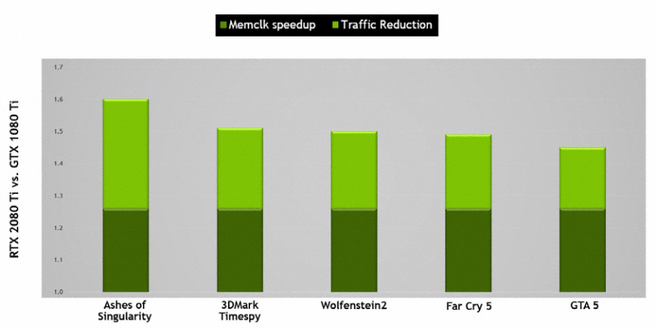
Nu moet ook de cache nog gevuld worden en daar speelt het videogeheugen een belangrijke rol. Nvidia maakt voor zijn Turing-kaarten gebruik van gddr6-geheugen, dat een stuk sneller is dan het gddr5-geheugen van Pascal. Laatstgenoemde geheugen werkt op 11Gbit/s, terwijl het gddr6 van Turing op 14Gbit/s zijn werk doet. Dat, samen met verbeterde compressie van alle data die over de databus gaat, levert volgens Nvida ongeveer 50 procent meer effectieve geheugenbandbreedte voor Turing op vergeleken met Pascal. Bovendien zou het geheugen ongeveer 20 procent zuiniger zijn dan het gddr5x van Pascal, onder meer dankzij verbeterde clock gating, waardoor ongebruikt geheugen minder energie gebruikt. Dat leidt mede tot de tdp van 250W voor de RTX 2080 Ti, ondanks dat Turing vergeleken met Pascal 50 procent meer transistors heeft.
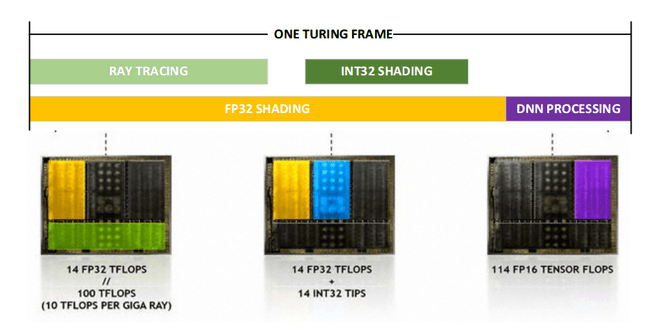
Als een frame gerenderd moet worden, kunnen de fp-units aan shading werken, terwijl tegelijkertijd rt-cores lichteffecten berekenen. Iets verderop in de renderpijplijn blijven de fp32-shadercores bezig, maar nemen ook de integer-cores werk van de fp-cores over. En ten slotte kunnen de tensor-cores het plaatje nog extra mooi maken met hun versie van anti-aliasing of dlss. Zo ziet volgens Nvidia zo'n beetje een framerender eruit, mits de game natuurlijk al die nieuwe technieken ondersteunt. En om aan te geven hoe veel sneller Turing dat zou doen dan Pascal, heeft Nvidia een berekening gemaakt waarin het probeert de appels met peren-vergelijking met een formule recht te trekken. Dat zou een verbetering van bijna tachtig procent opleveren, maar die berekening nemen we met een korreltje zout, al was het maar omdat er geen game is die al die technieken ondersteunt zodat we het kunnen toetsen.
Er is nog een handigheidje om de prestaties in Turing op te schroeven. Nvidia heeft zich gerealiseerd dat het weinig zin heeft om pixels in hoge kwaliteit te renderen die je toch amper ziet, dus concentreert Turing zich op de pixels die je wel ziet, een techniek die het rate adaptive shading noemt. Zo worden met motion adaptive shading snel bewegende pixels in lagere resolutie gerenderd, bijvoorbeeld de weg die onder je auto doorsnelt in racegames. Er zijn ook varianten met content adaptive shading, foveated rendering die we al van vr-toepassingen kennen en lens optimized-rendering.

Daarmee samenhangend is de beslissing welke objecten met welk detail gerenderd moeten worden van de cpu afgepakt. Tot dusver bepaalde de cpu de level of detail of lod in een scene, werden objecten wel of niet geschrapt en werden de draw calls naar de gpu gestuurd. Bij Turing hoeft de cpu alleen draw calls van alle objecten te sturen en de gpu bepaalt, middels een task shader en mesh shader, het level of detail van elk object en welke objecten weggelaten kunnen worden.
De eerste generatie Turing
Zoals inmiddels bekend zullen de eerste Turing-kaarten voor consumenten uit drie modellen bestaan, waarvoor Nvidia zelf Founders Editions maakt, en aib's goedkopere modellen produceren. De grootste chip, die geen volledige Turing-gpu is, zit in de Geforce RTX 2080 Ti. Die heeft 68 van de 72 mogelijke stream multiprocessors actief in zijn TU102, goed voor 4352 streamprocessors, 544 tensor-cores en 68 rt-cores. De FE-uitvoering gaat 1199 dollar kosten, terwijl kaarten van derden 999 dollar moeten gaan kosten.
| Variant |
RTX 2080 Ti |
RTX 2080 |
RTX 2070 |
| Chip |
TU102 |
TU104 |
TU106 |
| SP's |
4352 |
2944 |
2304 |
| SM's |
68 |
46 |
36 |
| Tensor-cores |
544 |
368 |
288 |
| RT-cores |
68 |
46 |
36 |
| NVLink (bandbreedte) |
2x (100Gbps) |
1x (50Gbps) |
nvt |
| Baseclock |
1350MHz |
1515MHz |
1410MHz |
| Boostclock (FE) |
1545MHz (1635MHz) |
1710MHz (1800MHz) |
1620MHz |
| Geheugen |
11GB gddr6 14GT/s |
8GB gddr6 14GT/s |
8GB gddr6 14GT/s |
| Tdp (FE) |
250W (260W) |
215W (225W) |
175W |
| Prijs (FE) |
1259 euro |
849 euro |
639 euro |
Specificaties van Founders Editions (FE) staan, waar van toepassing en indien afwijkend, tussen haakjes.
De Geforce RTX 2080 heeft de TU104 aan boord met 46 sm's ingeschakeld, goed voor 2944 streamprocessors, 368 tensor-cores en 46 rt-cores. De kleinste gpu zit in de RTX 2070 en dat is de TU106, met slechts 36 sm's actief, en dus 2304 shaderprocessors, 288 tensor-cores en 36 rt-cores. De FE's van die kaarten gaan respectievelijk 799 en 599 dollar kosten, terwijl aib-versies voor 699 en 499 dollar te koop moeten zijn.
In de grootste Turing-chip heeft Nvidia maar liefst 18,6 miljard 12nm-transistors op een oppervlakte van 754 vierkante millimeter gepropt. Die gpu wordt gecombineerd met 11GB gddr6-geheugen op 14GT/s en de gpu zelf tikt op 1350MHz met boost naar 1545MHz. De Founders Edition doet daar nog 90MHz bovenop en tikt op maximaal 1635MHz. Het geheel zou een tdp van 250W moeten hebben. De 2080 en 2070 hebben een iets hogere kloksnelheid van respectievelijk 1515MHz en 1410MHz, met boosts naar 1710MHz en 1620MHz. De kaarten worden beide gecombineerd met 8GB gddr6-geheugen op 14GT/s en hebben een tdp van 215W en 175W.
Wat uitgangen betreft ondersteunen de Turing-kaarten hdmi-poorten van versie 2.0b, goed voor 4k60Hz. De displayport-uitgangen zijn 1.4a-'ready' en ondersteunen 8k op 60Hz. Verder heeft Nvidia aan vr-headsets gedacht en VirtualLink-uitgangen toegevoegd. Dit zijn usb c-poorten die in staat zijn een displayport-signaal uit te sturen en 27W aan energie over de usb-poort te leveren. Zo zou een headset dus met een enkel kabeltje aangesloten kunnen worden.

Wil je dat soort hoge resoluties met twee kaarten realiseren, dan heb je en NVLink-bridge, de opvolger van sli, nodig. Voor de RTX 2070 is die niet beschikbaar, terwijl de 2080-varianten over een enkele link beschikken, goed voor 50Gbit/s bidirectionele bandbreedte. De 2080 Ti heeft zelfs twee NVlink-lanes, voor 100Gbit/s bidirectionele bandbreedte. Om de link te gebruiken is een hardware-bruggetje nodig, die je 79 dollar kost.
Overklokken
We moeten nog even stilstaan bij overklokken, want uiteraard wil Nvidia ook dat makkelijker maken. Waar je dat voorheen met tooltjes als Afterburner zelf mocht doen door kloks te verhogen, de stabiliteit te testen en te tweaken tot je een stabiele overklok had, heeft Nvidia daar nu Nvidia Scanner voor bedacht. Daarmee kun je automatisch overklokken en wordt de stabiliteit van de overklok over een brede belasting getest, wat tot stabielere overkloks moet leiden. Het overklokken wordt daarbij geholpen door de vrm's dynamisch, op basis van de belasting, te activeren, wat tot een stabielere en schonere stroomvoorziening moet leiden.
Om dat geweld een beetje koel te houden heeft Nvidia op zijn eigen kaarten niet een, maar twee fans gemonteerd, waardoor ze beter moeten koelen en ook nog eens stiller moeten zijn dan de voorgaande kaarten met een enkele koeler.
Tot slot
Nvidia heeft een flink aantal nieuwe onderdelen in de Turing-architectuur ondergebracht, en dat levert volgens het bedrijf flinke winsten op, die sterk afhankelijk zijn van de workloads die de gpu te verwerken krijgt. Games die van raytracing gebruik kunnen maken om een deel van de verlichting en schaduwen in een scène te verzorgen, of games die de tensor-cores inzetten om beelden te anti-aliasen houden meer rekenkracht in de floating point-units vrij dan games die dat niet kunnen. Daarmee hengelt Nvidia handig developers binnen, want om optimaal van dit soort technieken gebruik te maken moet je nauw samen werken met Nvidia en moet je van het RTX-ecosysteem gebruik maken.
Er zijn momenteel nog weinig games die van alle functies gebruik kunnen maken: een handjevol games zullen binnen nu en een half jaar raytracing ondersteunen, waaronder Battlefield V, Shadow of the Tomb Raider en Metro First Light. Het aantal games dat dlss gaat ondersteunen is wat groter, omdat Nvidia hapklare brokken voor de berekeningen in de tensor-cores levert.
Om alle features van de Turing-architectuur optimaal te benutten is het RTX-ecosysteem in het leven geroepen, een beetje vergelijkbaar met Gameworks. Het is nog onduidelijk of raytracing alleen binnen dat RTX-ecosysteem werkt: ray tracing is als DXR immers onderdeel van DirectX 12. Wel zou RTX-ray tracing via de DXR-api aangesproken kunnen worden, maar RTX behelst dus meer dan enkel ray tracing: onder meer dlss valt ook onder de RTX-paraplu.
Van de prestatiewinst die aparte integer-cores in de sm's moeten opleveren, en natuurlijk het snellere gddr6-geheugen, kunnen in principe wel alle games profiteren. Volgens Nvidia moet dat aanzienlijk hogere framerates opleveren vergeleken met de Pascal-kaarten. Wat de daadwerkelijke winsten gaan zijn in courante games zullen benchmarks moeten uitwijzen. Voorlopig ziet het er op papier goed uit.



:strip_exif()/i/2002203715.jpeg?f=imagegallery)
:strip_exif()/i/2002203717.jpeg?f=imagegallery)



:strip_exif()/i/2002170191.png?f=thumbmedium)
:strip_exif()/i/2002170193.png?f=thumbmedium)
:strip_icc():strip_exif()/i/2002949734.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002701878.jpeg?f=fpa_thumb)
/i/2002678218.png?f=fpa_thumb)
/u/468821/crop594848c6b86e5.png?f=community)
:strip_exif()/i/2002170195.png?f=thumbmedium)
:strip_icc():strip_exif()/i/2002615352.jpeg?f=fpa_thumb)
/i/2002611140.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002517596.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002440044.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002284531.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002252679.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2002203719.jpeg?f=fpa_thumb)
/i/2001237765.png?f=fpa)
:strip_exif()/i/2002463806.jpeg?f=fpa)
:strip_exif()/i/1360583044.jpeg?f=fpa)
/i/1217408551.png?f=fpa)
:strip_exif()/i/2002170155.jpeg?f=fpa)
/i/2001507509.png?f=fpa)
/i/2000820476.png?f=fpa)
:strip_exif()/i/2002219937.jpeg?f=fpa)
:strip_exif()/i/2002169777.jpeg?f=fpa)
/i/2001298295.png?f=fpa)
:strip_exif()/i/2002208863.jpeg?f=fpa)
:strip_exif()/i/2002201553.jpeg?f=fpa)
:strip_exif()/i/2002162309.jpeg?f=fpa)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
/u/347911/28jjvhf.png?f=community)
:strip_exif()/u/677/crop5e62ccc026e5a_cropped.gif?f=community)
:strip_icc():strip_exif()/u/990411/crop5bc04095902b6_cropped.jpeg?f=community)
/u/416523/fotos_in_de_cloud_android.png?f=community)
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
:strip_exif()/u/623199/crop5818669bdbe95_cropped.gif?f=community)
:strip_icc():strip_exif()/u/481280/Foto%2520van%2520mij%25204.jpg?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
:strip_exif()/u/331588/Louise-Brooks-style1.gif?f=community)
:strip_icc():strip_exif()/u/341611/crop59bdeb03f3805_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/595811/crop63fc7d02d590c_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/226826/aardblij-60.jpg?f=community)
:strip_icc():strip_exif()/u/192015/crop609667eb665d7_cropped.jpg?f=community)