Nvidia heeft de A100 aangekondigd, de eerste gpu die het bedrijf op zijn nieuwe Ampere-architectuur produceert. De chip komt als eerste naar een DGX-systeem met acht A100-gpu's. Ook GeForce-kaarten krijgen een gpu op basis van Ampere.
Ampere moet uiteindelijk niet alleen Volta maar ook Turing vervangen en als enkel platform dienen voor zowel de enterprise- als de consumentenkaarten, zei Nvidia-ceo Jensen Huang voorafgaan aan de aankondiging volgens Marketwatch. Volta is de architectuur van de gpu van de Tesla V100-accelerator; GeForce-kaarten op basis van Volta verschenen er nooit. De GeForce 20-kaarten zijn op de Turing-architectuur gebaseerd. Over Ampere voor GeForce zei Huang verder niets, alleen dat er veel overlap zal zijn met Ampere voor Tesla maar met andere configuraties.
De eerste gpu op basis van Ampere is de Tesla A100 en deze is bedoeld voor high performance computing, kunstmatige intelligentie en andere datacentertoepassingen. Deze chip laat Nvidia op 7nm produceren en bevat 54 miljard transistors. Het oppervlak van de die is 826mm². Daarmee is het aantal transistors flink toegenomen tegenover de GV100-gpu van de Tesla V100, die 21,1 miljard transistors heeft, terwijl het chipoppervlak niet veel groter is: de GV100 meet 815mm².
:strip_exif()/i/2003593026.jpeg?f=imagegallery)
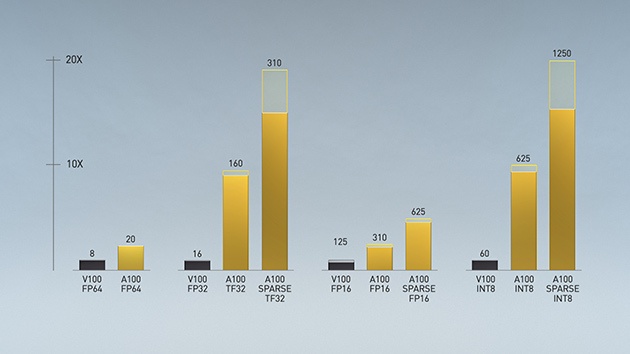
Het aantal cudacores van de A100 is ten opzichte van de V100 verhoogd van 5120 naar 6912. Het aantal tensorcores is afgenomen, van 640 naar 432, maar het gaat om tensorcores van de derde generatie die verbeterd zijn ten opzichte van de vorige generatie, volgens Nvidia. Bij fp64-rekenwerk bieden deze meer dan dubbel zo hoge prestaties. Bij fp32-rekenwerk zou dat zelfs een vertienvoudiging zijn, maar Nvidia vergelijkt hier berekeningen op basis van zijn eigen tensor float 32 met floating point 32-rekenwerk. Volgens Nvidia 'werkt tf32 net als fp32 zonder dat code veranderd hoeft te worden'.
De geheugenbus van de A100 is 5120 bits breed en de maximale geheugenbandbreedte bedraagt 1555GB/s. De accelerator heeft 40MB on-chip level cache, zeven keer meer dan de vorige generatie, en kan over 40GB vram beschikken, verdeeld over zes hbm2e-stacks.
Nieuw is verder de aanwezigheid van multi instance gpu voor virtualisatie. Elke A100 kan hiermee in tot aan zeven instances opgedeeld worden die elke geïsoleerd en met hun eigen geheugen aan het werk kunnen voor verschillende gebruikers. Daarnaast is er ondersteuning voor een nieuwe nv-link-interconnect om gpu's in een server met elkaar te verbinden. Deze biedt een gpu-naar-gpu-bandbreedte van 600GB/s.

Nvidia kondigde direct een eerste systeem met de A100 aan: de DGX A100. Dit bevat acht A100-accelerators met een totaal van 320GB geheugen en ook is dit systeem van 200Gbit/s-interconnects van het door Nvidia overgenomen Mellanox voorzien. Opvallend hierbij is dat Nvidia de overstap van Intel naar AMD heeft gemaakt: de vorige DGX-2 had twee Intel Xeon Platinum 8168-processors. De fabrikant is van plan om de DGX A100 gebundeld in een cluster van 140 systemen aan te bieden in de vorm van de zogenoemde DGX SuperPOD.
:strip_exif()/i/2003593028.jpeg?f=imagenormal)
| Nvidia Tesla-serie | ||||
|---|---|---|---|---|
| Tesla A100 | Tesla V100s | Tesla V100 | Tesla P100 | |
| Gpu | 7nm GA100 | 12nm GV100 | 12nm GV100 | 16nm GP100 |
| Die-oppervlak |
826 mm² |
815 mm² |
815 mm² |
610 mm² |
| Transistors |
54 miljard |
21,1 miljard |
21,1 miljard |
15,3 miljard |
| Sm's |
108 |
80 |
80 |
56 |
| Cudacores |
6912 |
5120 |
5120 |
3840 |
| Tensorcores |
432 |
640 |
640 |
NA |
| FP16 Compute |
78 tflops |
32.8 tflops |
31,4 tflops |
21,2 tflops |
| FP32 Compute |
19,5 tflops |
16,4 tflops |
15,7 tflops |
10,6 tflops |
| FP64 Compute |
9,7 tflops |
8,2 tflops |
7,8 tflops |
5,3 tflops |
| Boost-kloksn. |
~1410MHz |
~1601 MHz |
~1533 MHz |
~1480MHz |
| Max. geh. bandbr. |
1555 GB/s |
1134 GB/s |
900 GB/s |
721 GB/s |
| Eff. geh. kloksn. |
2430 MHz |
2214 MHz |
1760 MHz |
1408 MHz |
| Geheugen |
40GB HBM2e |
32GB HBM2 |
16GB / 32GB HBM2 |
16GB HBM2 |
| Geheugeninterface |
5120-bit |
4096-bit |
4096-bit |
4096-bit |
| Tdp |
400 |
250W |
300W |
300W |
| Formfactor | SXM4 / pci-e 4.0 | pci-e 3.0 | SXM2 /pci-e 3.0 | SXM |

/i/2004919460.png?f=fpa)
/i/2000820476.png?f=fpa)
:strip_exif()/i/2004301474.jpeg?f=fpa)
:strip_exif()/i/2001508675.jpeg?f=fpa)
:strip_exif()/i/2002463806.jpeg?f=fpa)
:strip_exif()/i/2003823980.jpeg?f=fpa)
:strip_exif()/i/2003803908.jpeg?f=fpa)
:strip_exif()/i/2003521894.jpeg?f=fpa)
:strip_exif()/i/2003725192.jpeg?f=fpa)
:strip_exif()/i/2002201553.jpeg?f=fpa)
:strip_icc():strip_exif()/u/788821/crop646f152e79148_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/1107487/crop5cae00c236612_cropped.jpeg?f=community)
/u/331666/crop581e2c93efc13.png?f=community)
:strip_icc():strip_exif()/u/299339/anonpict.jpg?f=community)
/u/158588/crop5c36197741423.png?f=community)
:strip_icc():strip_exif()/u/297932/Untitled.jpg?f=community)
:strip_icc():strip_exif()/u/800239/crop57a0ef1d2331e.jpeg?f=community)
/u/655063/crop5f54de6b4ae5e_cropped.png?f=community)
:strip_exif()/u/325996/bomb3.gif?f=community)
:strip_icc():strip_exif()/u/192659/crop5f634a975d689_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
/u/331213/crop56ef13408ff38_cropped.png?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
/u/1081811/crop6273bac91c6ae_cropped.png?f=community)
/u/407459/tw.PNG?f=community)
:strip_icc():strip_exif()/u/498479/crop5ab26974e0f1d_cropped.jpeg?f=community)
/u/654175/crop5628bfffe5fdf_cropped.png?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)