De Britse chipontwerper Graphcore heeft een nieuwe processor onthuld. De Colossus MK2 is bedoeld voor het uitvoeren van ai-workloads. Hij beschikt over 1472 cores en 8832 parallelle threads. Het bedrijf start in het vierde kwartaal van 2020 met leveringen op grote schaal.
De Colossus MK2, door het bedrijf ook wel GC200 genoemd, is een zogeheten ipu die wordt gebruikt voor het uitvoeren van ai-berekeningen. De chip is voorzien van 59,4 miljard transistors en wordt gemaakt op een 7nm-procedé van TSMC. De GC200 beschikt hiermee over 1472 cores en 8832 parallelle threads. De ipu heeft daarnaast 900MB sram in de processor zelf. Het geheel wordt gehuisvest in een die van 823mm².
:strip_exif()/i/2003725186.jpeg?f=imagegallery)
:strip_exif()/i/2003725188.jpeg?f=imagegallery)
De Graphcore GC200-chip (links) en het M2000-systeem
Voor het geheugen ondersteunt Graphcore daarnaast extra 'exchange-memory'. Hiermee kan iedere ipu voorzien worden van maximaal 448GB geheugen met een maximale theoretische bandbreedte van 180TB/s. Graphcore claimt verder dat de GC200 ongeveer acht keer zo goed presteert als zijn voorganger: de Colossus MK1. Die laatste werd in 2018 aangekondigd en werd gemaakt op een 16nm-procedé.
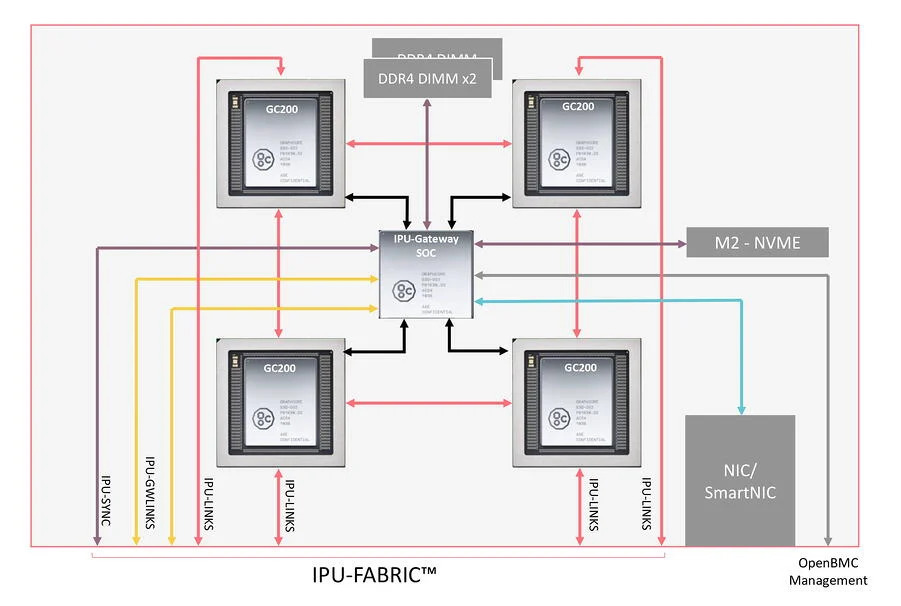
Graphcore meldt dat de nieuwe ipu wordt geleverd in een M2000-systeem. Deze M2000 bevat vier Colossus MK2-chips en heeft een 1U-behuizing. Dat systeem moet goed zijn voor een petaflops aan rekenkracht. Gebruikers kunnen tot 64.000 van deze ipu's aan elkaar koppelen voor een totale rekenkracht tot zestien exaflops. Het bedrijf levert ook een rack-scale 'IPU-POD64', die bestaat uit 16 M2000-machines voor een totaal van 64 Colossus MK2-chips. Deze Pod-systemen worden geplaatst in een standaard 19"-serverrack.
Voor communicatie tussen de verschillende ipu's bevat ieder M2000-systeem een GC4000-gatewaychip. Het bedrijf noemt dit 'ipu-fabric', wat functioneert als een interconnect tussen verschillende systemen, met een bandbreedte van 2,8Tbit/s per M2000-systeem. Volgens Graphcore kan dit lineair worden opgeschaald tot 'verscheidene petabits per seconde' bij gebruik van vele ipu's.
Het systeem gebruikt standaard koperen of optische osfp-connectors voor ipu-fabric. M2000-systemen kunnen hiermee individueel met elkaar worden verbonden. Bij grotere configuraties wordt gebruikgemaakt van tunneling-over-ethernet. Daarbij is ook het gebruik van standaard qsfp-interconnects en 100Gbit/s-ethernet-switches mogelijk.
Bedrijven kunnen de M2000-systemen en IPU-POD64 vooruitbestellen, meldt Graphcore. Leveringen op grote schaal starten in het vierde kwartaal van 2020. Het bedrijf maakt geen prijzen bekend.

:strip_icc():strip_exif()/i/2003840762.jpeg?f=fpa_thumb)
/i/2001777375.png?f=fpa)
/i/2003200348.png?f=fpa)
/i/2001843711.png?f=fpa)
/i/1208164214.png?f=fpa)
:strip_exif()/i/2003521894.jpeg?f=fpa)
/u/1983/whiteButton.png?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/33497/crop5e7214432b417_cropped.jpeg?f=community)
/u/453409/crop620241d45d87b_cropped.png?f=community)
:strip_icc():strip_exif()/u/147331/crop5a2d7f680544c.jpeg?f=community)
/u/710404/crop5e9f7de15e964_cropped.png?f=community)
:strip_icc():strip_exif()/u/178804/crop5c0f9b7d77913.jpeg?f=community)