Grote gevolgen voor nanoproblemen
We schrijven bij Tweakers vaak over de productieprocedés van chips. Voor de geïnteresseerde lezer zijn dit wellicht interessante artikelen, maar voor de leek zijn ze soms lastig te duiden. Consumenten zijn er aan gewend geraakt dat hun computers en smartphones elk jaar sneller en zuiniger worden en de achterliggende redenen boeit veel van hen niet zo. Toch zijn er ontwikkelingen gaande op chipproductieniveau die alle consumenten van pc's, tablets en smartphones raken en die te herleiden zijn tot de problemen om op steeds kleinere schaal chips te maken.
Over het ontstaan van die problemen hebben we al eerder achtergronden gepubliceerd, onder andere Is de wet van Moore dood?, De race naar 7nm en kleiner en Hoe worden chips gemaakt?. In die artikelen hebben we het regelmatig over nodes met een nanometer-indicatie, om de stand van de chipproductie aan te duiden. Maar wat betekent dat nu? Waar komt de 14nm van Intels chipproductie vandaan, en wat betekent het dat Samsung de overgang naar 10nm maakt?

Wat is een node?
In het algemeen zegt de hoeveelheid nanometer iets over de kleinste nog definieerbare structuren op het chipoppervlak, maar fabrikanten publiceren wel heel specifieke hoeveelheden nanometers. Dat lijkt er op te wijzen dat er een soort standaard is om de afmetingen van die structuren te meten. Dat ligt wat gecompliceerder, maar er zijn wel afspraken gemaakt. De aanduidingen zijn afkomstig van de ITRS, de International Technology Roadmap for Semiconductors.
Om de paar jaar stellen experts op het gebied van halfgeleidertechnologie die roadmap op en geven daarbij een overzicht van de stand van zaken rond de chipproductie en een voorspelling voor de daaropvolgende vijftien jaar. Het gaat dan om deskundigen uit de VS, Europa, Japan, Korea en Taiwan, van onder andere de grote chipbedrijven als Intel en TSMC, en van machinemakers als ASML en Nikon. Het meest in het oog springende onderdeel van de roadmap is de labeling van de nodes. Aan de ITRS hebben we dus de aanduidingen 45nm, 32nm, 22nm, 14nm, enzovoorts te danken.
Die labels komen niet uit de lucht vallen. Althans, in het verleden was die labeling direct gerelateerd aan het kleinste onderdeel van een chip: de transistor oftewel de mosfet. De eerste roadmap van de halfgeleiderindustrie verscheen begin jaren negentig. In die tijd zagen de chipbedrijven al dat de ontwikkeltijd voor processors enorm zou verkorten, wat de noodzaak voor coördinatie en het delen van kennis van de laatste technieken deed toenemen.
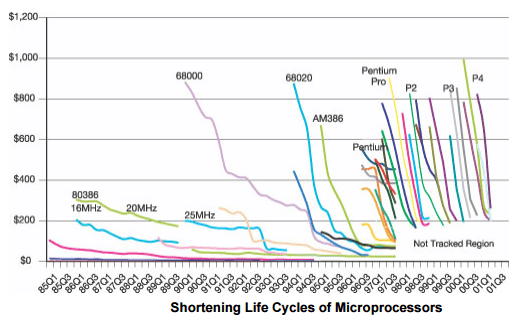
Op de eerste roadmap staat de feature size als belangrijkste eigenschap en voor dram, want om die chips ging het, was die in 1992 0,5 micrometer. Die lengte is gebaseerd op de gate van de transistor. Elke transistor heeft een source, een drain en een gate. Door spanning aan te brengen op de gate, vloeien de elektronen van de source naar de drain. De lengte van de gate heeft invloed op de snelheid van het schakelen van de transistor en chipfabrikanten proberen dan ook de gate zo kort mogelijk te maken.
Begin jaren negentig was er een hechte relatie tussen de gatelengte en de pitch. De pitch is de afstand tussen de metalen contactlijnen, of interconnects, waardoor de elektronen stromen en die aan weerszijden van de transistors zitten. In de praktijk gebruikt de industrie de helft daarvan als meeteenheid, de half-pitch. Voor geheugen is die afstand belangrijk want hoe kleiner de pitch, hoe meer bits er op een chip gepropt kunnen worden. Geheugenfabrikanten richten zich dus voornamelijk op het verkleinen van de half-pitch, terwijl voor logic-chips, oftewel processors, het terugbrengen van de gatelengte het belangrijkste is.

Daarmee zijn er al twee waardes die als basis kunnen dienen voor nodes, maar de relatie tussen de twee zorgde voor een probleem. Naarmate de transistors kleiner werden, was er steeds minder overeenstemming over hoe de lengte van de gate bepaald moest worden. Moest de lengte van de ontwerpen, de gemeten waarde of de effectieve afstand als basis dienen?
/i/2001412943.png?f=imagenormal)
Het gevolg was dat de waardes tussen half-pitch en gatelengte steeds verder uit elkaar kwam te liggen en chipfabrikanten elk hun eigen definities over de lengtes aanhielden. De relatie tussen de node zoals de experts van de ITRS die vaststelden, en de half-pitch- en gatelengte op de roadmap werd steeds diffuser. Kijk maar eens naar de waardes die de deskundigen gebruikten.
| Jaar |
Node (nm) |
Half-pitch (nm) |
Gatelengte (nm) |
| 2009a |
32 |
52 |
29 |
| 2007a |
45 |
68 |
38 |
| 2005b |
65 |
90 |
32 |
| 2004b |
90 |
90 |
37 |
| 2003b |
100 |
100 |
45 |
| 2001c |
130 |
150 |
65 |
| 1999c |
180 |
230 |
140 |
| 1997d |
250 |
250 |
200 |
| 1995d |
350 |
350 |
350 |
| 1992d |
500 |
500 |
500 |
a: ITRS 2008, b: ITRS 2006, c: ITRS 2001, d: ITRS 1997, bron: IEEE Spectrum
En vergelijk die met de cijfers van bijvoorbeeld Intel. De roadmaps van andere fabrikanten lieten eenzelfde discrepantie zien, waarmee de vraag ontstond wat een 'node' eigenlijk nog was.
| Intel's logic roadmap |
| Jaar |
Node (nm) |
Half-Pitch (nm) |
Gate-lengte (nm) |
| 2009 |
32 |
~52 |
~15 |
| 2007 |
45 |
~75 |
<25 |
| 2005 |
65 |
105 |
<35 |
| 2003 |
90 |
110 |
<50 |
De ITRS vroeg zich hetzelfde af en besloot daarom in de 2005-editie te stoppen met de term. "De flinke verwarring met betrekking tot de ITRS-definitie van een node zie je terug in veel persberichten en andere documenten die naar 'node-acceleratie' verwijzen, gebaseerd op andere, veelal, ongedefinieerde criteria", stond in de ITRS 2005. De node-aanduidingen waren dus in handen gekomen van de marketingafdelingen. En die lieten ze niet meer los, want na het besluit ermee te stoppen, keerden ze in de ITRS 2009 alweer terug. De industrie kon niet zonder een enkele aanduiding waaronder alle technologische vorderingen geschaard konden worden.

Dat betekent niet dat de onduidelijkheid over wat nu precies een 22nm- of 14nm-procedé is, verdwenen was, in tegendeel. Door de komst van finfets is er nog een extra eigenschap bijgekomen waarvan de grootte van groot belang is. De finfet-transistors worden ook wel 3d-transistors genoemd. Ze ontlenen hun naam aan de vorm; een vin tussen source en drain wordt door een gate aan drie kanten omsloten en vormt een dubbele gate. Bij de ITRS 2013 verscheen een Overall Roadmap Technology Characteristics-tabel waarin ook de halfpitch-waarde en breedte van de finfets meegenomen werd.
/i/2001423893.png?f=imagenormal)
Daarmee houdt het nog niet op want er zijn nog andere afmetingen op de nanoschaal die volgens deskundigen als maatstaf gebruikt kunnen worden, zoals die van 6T sram-cellen of die van logic cellen. De omvang van de 6T sram-cellen is gebaseerd op het oppervlak van de bitcellen van static random-access memory, bestaande uit zes transistors. De caches van processors bestaan uit dit statische ram. De omvang van logic-cellen is gebaseerd op de lengte en breedte van finfet-transistors. Dit gebruikte Intel bijvoorbeeld onlangs bij een claim dat het bedrijf met deze oppervlakte nog steeds een voorsprong van drie jaar heeft op zijn concurrenten. De 10nm-node waar Samsung en TSMC dit jaar mee komen, zou wat logiccell-oppervlak betreft gelijk zijn aan Intels 14nm-procedé. TSMC beweerde in het verleden dat de nodes bij 10nm juist samen zouden komen.
De ene node is de andere niet
Het is duidelijk dat de basis van de nodes zoals experts die vaststellen nogal wankel is. Hoe zit het dan bij de fabrikanten? Op dit moment worden Intels processors op 14nm geproduceerd en TSMC zit op een 16nm-node voor bijvoorbeeld Apples A9/A10-soc van de iPhones. TSMC is de 10nm-productie inmiddels gestart. Samsung is eveneens begonnen met de 10nm-productie van zijn Exynos-socs en de Qualcomm Snapdragon 835, beide voor de Galaxy S8.
Over de 10nm-productie is nog niet veel bekend, maar fabrikanten gaven eerder wel details over hun 22/16/14nm-nodes, waardoor die procedés naast elkaar te zetten zijn. Bij Samsung ging het daarbij om de eerste 14nm-generatie, 14LPE of Low Power Early. Vorig jaar volgde het bedrijf met een tweede generatie, Low Power Plus, waarmee bijvoorbeeld de Snapdragon 820 geproduceerd werd. GlobalFoundries werkt met Samsung samen aan het 14nm-productieproces, waarmee die fabrikant bijvoorbeeld de Ryzen-processors maakt.
| Eigen cijfers van fabrikanten |
| Feature |
Intel 22nm |
Intel 14nm |
TSMC 16nm FF |
Samsung 14nm LPE |
| Fin-pitch |
60nm |
42nm |
48nm |
48nm |
| Gate-pitch |
90nm |
70nm |
90nm |
84nm |
| Interconnect-pitch |
80nm |
53nm |
64nm |
64nm |
| 6T sram cell-oppervlak |
0,1080µm2 |
0,0588µm2 |
0,0700µm2 |
0,0645µm2 |
Bron: analist Patrick Moorehead/Intel/TSMC/Samsung
Te zien is dat er grote verschillen zijn tussen de nodes, hoewel de naamgeving lijkt te suggereren dat ze hetzelfde zijn, danwel dicht bij elkaar liggen. Nu is het altijd gevaarlijk af te gaan op claims van fabrikanten zelf. Gelukkig heeft TechInsights metingen verricht bij de Intel 14nm 5Y70, Samsung 14nm Exynos 7 7420, en TSMC 16nm Apple A9.
| Metingen door TechInsights/Chipworks |
| Feature |
Intel 14 nm |
TSMC 16 nm FF |
Samsung 14 nm LPE |
| Fin-pitch |
42nm |
45nm |
48nm |
| Gate-lengte |
~24nm |
~33nm |
~30nm |
| Contacted gate pitch |
70nm |
88nm |
78nm |
| Interconnect-pitch |
52nm |
70nm |
67nm |
| 6T sram cell-oppervlak |
0,059µm2 |
0,074µm2 |
0,080µm2 |
Bron: TechInsights (volgens Intel is de gatelengte bij 14nm 20nm en was deze bij 22nm 26nm)
Hierbij komen opnieuw de verschillen naar voren. De conclusie is dat de nodes van de fabrikanten niet met elkaar te vergelijken zijn. Dat zal later dit jaar en volgend jaar zeker iets zijn om rekening mee te houden, als Intel, Samsung en TSMC allemaal op een geclaimde 10 nanometer produceren. Global Foundries, dat de AMD- en Radeon-chips maakt, slaat 10nm over en wil volgend jaar op 7nm overstappen.
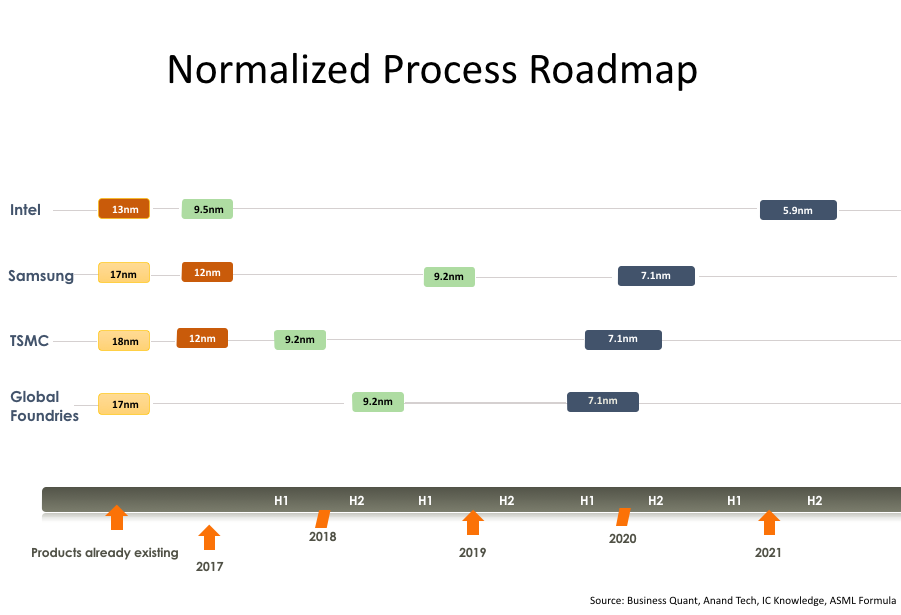
Om een einde aan de onduidelijkheid te maken lijkt ASML een formule te hanteren op basis van de verhouding tussen contact poly half pitch, of cphp, en minimum metal half pitch, of mmhp. Die formule luidt "standaardnode is = 0.14 x ((cphp x mmhp)^0.67)". Hoewel deze formule een aantal waardes buiten beschouwing laat, zoals de omvang van de sram-cell, is het een tool om een realistische inschatting van de verschillende nodes van fabrikanten te krijgen en de marketing buiten beschouwing te laten.
Als de formule toegepast wordt op de voorspelde waardes van de nodes van fabrikanten, wat dus speculatie is, komt naar voren dat Intel nog een voorsprong heeft, maar deze in 2018 lijkt te verliezen.
/i/2001439371.png?f=imagenormal)
Bron van speculatiecijfers: ICKnowledge, bron van grafiek: Business Quant
Als er zoveel onduidelijk is hoe een node gedefinieerd moet worden, waarop baseren chipfabrikanten dan hun besluit dat er overgestapt is op een nieuwe node? Over het algemeen wordt een lineaire schaalverkleining van 0,7x voor de belangrijkste features als maatstaf gehouden om van een nieuwe node te kunnen spreken. Dit zorgt grofweg voor een verdubbeling van de transistordichtheid bij de overstap naar een nieuwe node. De geschiedenis leert dat Intel zich het nauwkeurigst aan die lijn gehouden heeft. Bovenstaande tabellen tonen dat concurrenten ergens gedurende het pad de afgelopen jaren afgeweken zijn van die strakke lijn.

Als je de node-naam buiten beschouwing laat, maar naar de afzonderlijke waardes voor schaalverkleining kijkt, laat Intel nog altijd een voorsprong zien met zijn chipproductie. Maar duidelijk is wel dat Samsung, GlobalFoundries en TSMC met een flinke inhaalslag bezig zijn. Verwonderlijk is dat niet. De Wet van Moore is immers een economische wet; het aantal componenten dat tegen de laagste prijs geproduceerd kan worden, zou elk jaar verdubbelen.
Maar om de transistordichtheid verder toe te laten nemen zijn steeds hogere investeringen nodig. TSMC met Apple als klant en Samsung die de chips voor zijn Galaxy-lijn en voor Qualcomm maakt, kunnen die investeringen makkelijk verantwoorden: de vraag naar mobiele socs is enorm. Voor Intel, die het deels van de kwakkelende pc-markt moet hebben, is dat een ander verhaal.
Bovendien staat de optimale verhouding tussen dichtheid en yields, het aantal correct functionerende chips, onder druk. Om op steeds kleinere schaal te kunnen produceren, moeten fabrikanten overgaan tot multiple patterning, zoals triple of quadruple patterning. Ze moeten wafers meerdere keren belichten wat extra tijd, en dus geld, kost. Daarnaast moeten ze meerdere dure maskers maken en moeten die maskers tot op de nanometer op elkaar afgesteld zijn om overlayproblemen te voorkomen.
/i/2001435497.png?f=imagenormal)
Nieuwe smartphone, oude processor
Het is gezien alle haken en ogen geen wonder dat fabrikanten langer bij dezelfde nodes blijven. Intel hield altijd een jaarlijkse cadans aan waarbij de ene generatie chips op een nieuwe architectuur gebaseerd werd, gevolgd door een generatie op een kleinere node. In 2015 maakte Intel bekend dat deze strategie niet standhield. Het bedrijf ruilde de tick-tock-strategie in voor een 'process-architecture-optimization'-variant van drie stappen.
Bij die optimalisatie-stap worden dus wel verbeteringen bij de chipproductie doorgevoerd, maar die zijn niet van dien aard, dat Intel van een nieuwe node durft te spreken. Met andere woorden, er is geen sprake van de lineaire schaalverkleining van 0,7x voor de belangrijkste features waar de chipgigant naar streeft.
Maar ook met de overgang van een driestappenplan was het niet gedaan. Vorige maand moest Intel toegeven dat de komende generatie Intel-chips voor de desktop, met codenaam Coffee Lake, nog steeds op 14nm geproduceerd gaan worden. Opnieuw tweakt Intel dus zijn 14nm-procedé, waarmee er nu sprake is van een 'process-architecture-optimization-optimization'-stappenplan. Het houdt in dat straks Broadwell, Skylake, Kaby Lake en Coffee Lake op deze node zijn gemaakt. In de praktijk kunnen kopers van desktopchips alsnog een prestatiewinst van 15 procent tegemoet zien, claimt Intel, maar de fabrikant moet zich in vele bochten manoeuvreren om dit te bereiken, in tegenstelling tot bij een klassieke die shrink. De vraag is bijvoorbeeld of ook het verbruik omlaag gaat.
Eind dit jaar komen wel de eerste 10nm-chips van Intel, de Cannon Lake-chips voor laptops, maar de yields op 10nm zijn blijkbaar onvoldoende voor een overstap met alle Core-chips. Bij de 10nm-node keert Intel niet terug naar zijn tick-tock-cadans; het bedrijf heeft al bevestigd dat er drie 10nm-generaties komen. Bij de derde 10nm-generatie en de uiteindelijke overstap naar 7nm, zullen consumentenprocessors bovendien niet als eerste overgaan.
Intel gaat een 'datacenter first'-strategie hanteren en chips voor die markt zullen als eerste op een nieuw procedé gemaakt worden. Het bedrijf levert inmiddels genoeg datacenterprocessors om dit te rechtvaardigen en kan tegen die tijd grote complexe Xeon-dies in delen vervaardigen omdat dankzij emib, of embedded multi-die interconnect bridge, die delen efficiënt met elkaar verbonden kunnen worden. De reden dat pc-chips niet meer als eerste op een nieuwe node gemaakt worden is duidelijk: daar zit de groei niet meer.
Niet alleen Intel hanteert meerdere generaties van een node. Samsung doet dat bijvoorbeeld ook. De Exynos-socs van de Samsung Galaxy S6 en S7 werden achtereenvolgens op het 14LPE- en 14LPP-procedé gemaakt. Daarbij staat de laatste 'E' voor early en de 'P' respectievelijk voor performance. De derde generatie, 14LPC, wordt voor goedkopere socs en internet-of-things-apparaten ingezet en de vierde 14nm-productie, 14LPU, moet de prestaties van die chips bij gelijk verbruik verbeteren.
Samsung is nu bezig de Exynos 9 Series 8895-soc voor de Galaxy S8 en de Snapdragon 835 op een 10LPE-procedé te maken, waarbij het bedrijf gebruikmaakt van een triple-patterninglithografietechniek. Opnieuw zal die generatie opgevolgd worden door geoptimaliseerde 10nm-nodes, de 10LPP- en 10LPU-varianten die eind volgend jaar moeten verschijnen.
/i/2001437413.jpeg?f=imagenormal)
TSMC is eveneens begonnen op 10nm te produceren. In eerste instantie gaat het om de Helio X30-soc van MediaTek, die in de tweede helft van volgend jaar in smartphones te vinden moet zijn. Later in het jaar gaat TSMC de productie voor de, vermoedelijk A11 geheten, socs voor de volgende iPhone starten.
Er zijn al maanden berichten dat het met die productie bij zowel Samsung als TSMC niet zo soepel verloopt en er zijn nu aanwijzingen dat de yields inderdaad niet goed zijn. Zo kondigde Qualcomm zijn 10nm-soc Snapdragon 835 weliswaar in januari al aan, maar op het Mobile World Congress in februari, werden er maar weinig smartphones met de processor aangekondigd.
Zo zijn enkele topmodellen van fabrikanten, zoals de LG G6 en de HTC U Ultra, met een Snapdragon 821 uitgerust, Qualcomms soc van vorig jaar. Een topman van HTC zei eind januari dat het 'nog maanden' ging duren voordat er smartphones met de Snapdragon 835 gingen verschijnen, daarmee geruchten voedend dat Samsung zichzelf voorrang geeft en er blijkbaar niet genoeg voor andere fabrikanten kan maken.
/i/2001437415.jpeg?f=imagenormal)
De Taiwanese site Digitimes bracht eind december het gerucht dat de yields bij Samsung tegenvielen en begin maart herhaalde de site dit. Samsung zou zelfs de introductie van de Galaxy S8 uitgesteld hebben om deze reden. Samsung presenteert de Galaxy S8 op 29 maart tijdens een evenement in New York maar niet bekend is wanneer de smartphone beschikbaar komt.
Digitimes noemde in zijn bericht over slechte yields eveneens TSMC, dat ontkende problemen te ondervinden. MediaTek stelde onlangs echter onomwonden dat zijn Helio X30 maanden vertraging opliep door de tegenvallende productie bij TSMC. De soc had MediaTeks debuut op de markt voor high-end-chips moeten vormen, maar alleen Meizu lijkt nog interesse te hebben. Naar verluidt zou ook Huawei's HiSilicon de Kirin 970 op 10nm bij TSMC laten maken en in het eerste kwartaal van 2017 aankondigen, maar na geruchten hierover eind december is hier niets meer van vernomen. De P10 bevat in ieder geval nog de Kirin 960.
Smachten naar euv
Het beeld ontstaat zo dat steeds onduidelijker is wat een node is, dat het overstappen op nieuwe nodes steeds lastiger wordt en dat fabrikanten elk hun eigen definities hanteren, al dan niet uit marketingoverwegingen. Die onduidelijkheid is er op een moment dat de halfgeleidermarkt zich in een cruciale fase bevindt.
De weg naar 7nm en 5nm bevat veel hobbels en risico's. Als het langdurig vasthouden aan 14nm en 10nm door Intel en de vermeende yieldproblemen bij Samsung en TSMC voor 10nm een indicatie zijn, gaan we nog een interessante tijd tegemoet. De eerste gevolgen zijn nu al zichtbaar. Intels komende desktopprocessors worden voor de vierde keer op 14nm gebakken en LG en HTC beschikken voor hun laatste high-end smartphones niet over de nieuwste generatie Snapdragon-soc.
Het is speculeren of deze trend zich voortzet. Krijgen Apple en Samsung voorrang bij nieuwe processors en moet de rest geduldig afwachten voor de opbrengst van goed werkende chips op peil is? Nieuwkomers als Huawei en Xiaomi produceren ook eigen processors, maar kunnen zij het zich straks permitteren naar nieuwe nodes over te stappen bij de stijgende kosten? Gaan in de toekomst de nodes veel meer door elkaar lopen, zoals bij Intel gaat gebeuren met 14nm en 10nm?
Helemaal interessant wordt het als de verkoop van high-end smartphones gaat afzwakken of dalen. Uit de Wet van Moore volgt dan wel dat de kosten per transistor nog even dalen, maar wat als de opbrengsten sneller dalen? De roadmaps van chipfabrikanten houden hier geen rekening mee. TSMC, Samsung, GlobaFoundries en Intel investeren enorm in 7nm- en 5nm-fabrieken.
Om het spook van dure en complexe quadruple of quintuple patterning te verjagen is euv nodig, liet ASML-directeur Peter Wennink eerder weten. Als alles meezit kan die lithografietechnologie eind 2018, begin 2019 ingezet worden voor massaproductie. Intel, Samsung en TSMC hopen de techniek voor hun 7nm-nodes in te kunnen zetten, GlobalFoundries houdt het bij implementatie op 5nm. Ongeacht of je tegen die tijd überhaupt nog over nodes kunt of zou moeten spreken: voor de fabrikanten kan euv waarschijnlijk niet snel genoeg komen.







:strip_icc():strip_exif()/i/2005704922.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005286184.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005184414.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005169150.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004698074.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004086480.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003043920.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001385603.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001377377.jpeg?f=fpa_thumb)
/i/2001190117.png?f=fpa_thumb)
:strip_exif()/i/2006689170.jpeg?f=fpa)
:strip_exif()/i/2005229388.jpeg?f=fpa)
/i/2001665377.png?f=fpa)
/i/1247738571.png?f=fpa)
/i/1297427597.png?f=fpa)
/i/1242207182.png?f=fpa)
/i/2001435495.png?f=fpa)
/i/2001331269.png?f=fpa)
:strip_icc():strip_exif()/u/65843/chef60x60.jpg?f=community)
:strip_icc():strip_exif()/u/112202/lighthouse.jpg?f=community)
:strip_icc():strip_exif()/u/324515/crop627103b05ba2e_cropped.jpg?f=community)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
:strip_icc():strip_exif()/u/405084/ESI.jpg?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_icc():strip_exif()/u/64029/crop5b4e6ed3481f4_cropped.jpeg?f=community)
:strip_exif()/u/94091/lynxa.gif?f=community)
/u/27299/hoofd.png?f=community)
/u/69397/crop5b20ed488c1d9_cropped.png?f=community)
:strip_icc():strip_exif()/u/83337/countess6-nice.jpg?f=community)
:strip_icc():strip_exif()/u/59684/crop60756d629e04f_cropped.jpg?f=community)
/u/715027/crop6047c50ae8d4c.png?f=community)
/u/875309/crop6931a92622a14.png?f=community)
/u/450652/crop5e2c2b1bb978e.png?f=community)
/u/200366/naamloos9999.JPG?f=community)
{kind=link}
{kind=link}