
Het is inmiddels geen geheim meer; het wordt steeds lastiger om transistors kleiner te maken. Het aantal transistors in een chip zou, afhankelijk van de interpretatie, elke een tot twee jaar verdubbelen, een principe dat sinds medio jaren zestig bekend staat als de Wet van Moore, of Moore's Law. Die wet is genoemd naar Gordon Moore, een medeoprichter van Intel. Door transistors steeds kleiner te maken, een proces dat bekendstaat als scaling, passen er steeds meer op dezelfde oppervlakte en worden de kosten lager. De wet is uitgegroeid van een observatie tot een richtlijn voor de hele halfgeleiderindustrie. Het blijkt echter steeds moeilijker te worden om die richtlijn te blijven volgen.
/i/2000601710.jpeg?f=imagegallery)
Een van de meest sprekende voorbeelden dat scaling steeds lastiger wordt, zien we in de tick-tock-cadans van Intel. Voorheen bracht het bedrijf elke anderhalf jaar een kleinere processorarchitectuur uit, ook wel bekend als een tick. De tock die daarop volgde, bracht een nieuwe microarchitectuur, zodat Intels bekende tick-tock-cyclus ontstond. Sinds de 22nm-generatie is het tempo er een beetje uitgegaan en bij Haswell werd zelfs een Refresh geïntroduceerd, omdat de stap naar 14nm met codenaam Broadwell lastiger bleek dan gedacht. Ook met de stap van Skylake naar CannonLake, van 14 naar 10nm, is een tussenstation aangekondigd, in de vorm van Kaby Lake.
Scaling wordt dus steeds lastiger, met steeds hogere kosten om kleinere transistors te maken. Een hogere dichtheid dankzij kleinere transistors levert in theorie goedkopere chips op, maar als het aantal stappen om ze te maken steeds groter wordt en de benodigde apparatuur duurder, wordt ergens een evenwicht bereikt. Volgens sommigen komen we steeds dichter bij dat punt en wordt het verhogen van de transistordichtheid simpelweg door scaling steeds minder effectief. Dat was het thema van het Imec Technology Forum, een tweedaags symposium waarop halfgeleideronderzoeksinstituut Imec, en partners als ASML en Intel de nieuwste ontwikkelingen op het gebied van de productie van halfgeleiders lieten zien. In dit achtergrondartikel laten we de hoofdpunten van dit symposium de revue passeren. Met andere woorden: is de Wet van Moore in zijn eenenvijftigste verjaardagsjaar eindelijk doodverklaard of gloort er nog hoop voor kleinere, snellere en goedkopere transistors?
Traditionele scaling
In de afgelopen jaren is scaling steeds volgens de Wet van Moore verlopen, met kleinere geometrieën, die meer transistors per wafer opleverden en daarmee de hogere productiekosten van de wafer meer dan compenseerden. De productie van elke kleinere node kost namelijk meer en meer geld; de apparatuur om kleinere transistors mogelijk te maken wordt duurder en het aantal stappen in de productie neemt toe. Dat laatste wordt onder meer veroorzaakt door de noodzaak om steeds lastigere technieken te implementeren om kleinere transistors te maken. Zo werd voor de stap naar 90nm strained silicon toegepast en voor de 45nm-node werd de hkmg-transistor geïntroduceerd. Voor 20/22nm-transistors wordt gebruikgemaakt van double patterning en voor kleinere transistors worden double-patterningtechnieken en finfets ingezet. Met die laatste techniek liep Intel een generatie voor en het paste finfets al in de 20nm-node toe, met de finfet-kostenpost een generatie eerder tot gevolg.
/i/2001188281.png?f=imagenormal)
Dat leidt allemaal tot hogere kosten. Tot de 28nm-node waren de kostentoenames steeds ongeveer 15 tot 20 procent per node; bij de stap naar 20nm stegen de extra kosten echter al tot bijna 30 procent en naar 14nm zelfs ruim 40 procent. De hogere transistordichtheid leverde bij de stap naar 28nm nog een kosteneffectieve methode op, maar de stap naar 20nm leidde voor het eerst niet tot goedkopere transistors en dat geldt ook voor de 14nm-node. Overigens zijn het niet alleen de productiekosten die steeds hoger worden, ook de r&d-kosten stijgen dermate dat steeds minder bedrijven zich dat kunnen veroorloven. Het gevolg is een consolidatie van chipfabrikanten, kleinere bedrijven die op grotere nodes blijven produceren en steeds langere termijnen voordat er weer nieuwe, kleinere nodes beschikbaar zijn.
Voor kleinere nodes nemen de kosten voor scaling alleen maar toe. Voor de 10nm-node moeten opnieuw finfets gebruikt worden, in combinatie met double of zelfs triple patterning en self-aligned patterning. De vertraging van euv-lithografie, die minder patterning-stappen mogelijk zou maken, levert ook hogere kosten voor de 10nm- en 7nm-nodes op. Voor nog kleinere transistors, op de 7nm/5nm-node, zouden zelfs vijf patterning-stappen en/of directed self assembly nodig zijn. Al die extra stappen kosten veel tijd en dus geld.
Ter illustratie: de overstap naar het vertraagde euv zou de zogeheten cycle-time, de tijd die een wafer in de fabriek doorbrengt, met twintig dagen kunnen verkorten. Het aantal masking steps, ieder goed voor anderhalve dag, zou van omstreeks 30 voor 193nm-immersielithografie gaan naar minder dan 10 voor euv-lithografie. De levensduur van euv is echter beperkt: we zitten inmiddels op 14nm en voor 10nm zal nog steeds 193nm gebruikt worden. Het 'insertion point' voor euv zou de 7nm-node zijn, maar veel verder dan tot 5nm zou euv niet meegaan.
/i/2001188371.png?f=imagenormal)
Wat is dan wel de oplossing? De baten van verdere scaling wegen nu al niet meer op tegen de kosten en voor kleinere nodes wordt dat alleen maar erger. Bovendien werken 'platte' transistors op de 14nm-node al niet goed meer en moet worden overgestapt naar complexere finfets. Maar ook die kunnen maar een tijdje mee; voor kleinere transistors zijn weer andere technieken nodig. Is het kleiner maken van transistors eigenlijk de enige oplossing om goedkopere, zuinigere en kleinere chips, sensors en geheugens te maken?
De redding van geheugen?
Er blijft voor de halfgeleiderindustrie hoop gloren om de Wet van Moore intact te laten: geheugen. Niet alleen dram bereikt steeds hogere dichtheden, dankzij nieuwe technieken, maar er worden ook nieuwe typen geheugen ontwikkeld. Zo is nand-geheugen de hoogte ingegaan met 3d-nand van diverse fabrikanten en Intel ontwikkelde met x-point een geheugentype tussen dram en nand in. Vooral nand blijft de curve van de Wet van Moore keurig volgen en aangezien dat het overgrote deel van de transistorproductie is, lijkt de wet veilig.
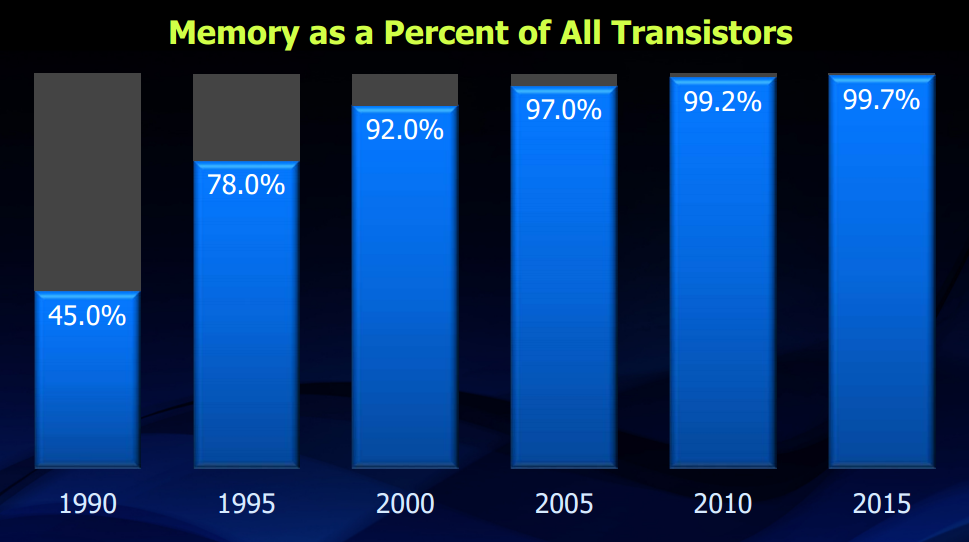 In theorie redt de productie van geheugen, met steeds grotere dichtheden dankzij 3d-nand, tlc-geheugen en nieuwe technieken de Wet van Moore. Voor het overgrote deel van transistors die voor geheugen geproduceerd worden, gaat de wet toch nog op. Voor geheugen kunnen we dus nog even vooruit, dankzij de ontwikkeling van steeds meer lagen geheugencellen in een 3d-structuur. Voor logic-chips als processors is die stapeling echter veel moeilijker te realiseren. Geheugen is namelijk erg simpel van structuur en organisatie, en kan daardoor vrij eenvoudig gestapeld worden. Voor processorcircuits gaat dat niet op; de complexiteit en de geproduceerde warmte door de hoge kloksnelheden maken 3d-structuren lastig.
In theorie redt de productie van geheugen, met steeds grotere dichtheden dankzij 3d-nand, tlc-geheugen en nieuwe technieken de Wet van Moore. Voor het overgrote deel van transistors die voor geheugen geproduceerd worden, gaat de wet toch nog op. Voor geheugen kunnen we dus nog even vooruit, dankzij de ontwikkeling van steeds meer lagen geheugencellen in een 3d-structuur. Voor logic-chips als processors is die stapeling echter veel moeilijker te realiseren. Geheugen is namelijk erg simpel van structuur en organisatie, en kan daardoor vrij eenvoudig gestapeld worden. Voor processorcircuits gaat dat niet op; de complexiteit en de geproduceerde warmte door de hoge kloksnelheden maken 3d-structuren lastig.
De package
Natuurlijk kan het stapelen van geheugenstructuren niet oneindig doorgaan. Om toch zuinigere, goedkopere en kleinere processors en apparaten te krijgen, moet er iets fundamentelers gebeuren. Gelukkig is er, voordat we in de sub-10nm-contreien komen, nog een andere quick win mogelijk om het energiegebruik en de footprint van elektronica te verkleinen. In de verpakking van de chip, de zogeheten package, zou gemiddeld zo'n dertig procent van de totale energie van de processor of soc verloren gaan. Dat komt onder meer door de toegenomen complexiteit en integratie van chips; een soc moet in- en outputs hebben voor geheugen, pcie-lanes en usb, en tal van andere i/o. Die schalen minder dan het silicium op de dies en leiden tot een onevenredige belasting op het power- en oppervlaktebudget. Zo zouden siliciumcomponenten drie ordes van grootte zijn geschaald in de tijd waarin de package slechts een factor drie werd geschaald.
 Een methode om de package efficiënter te maken, zou een betere integratie kunnen zijn. In plaats van een relatief groot moederbord met daarop chips gesoldeerd die weer in eigen packages verpakt zijn, zou meer met stapelen of interposers gewerkt kunnen worden. We hebben al een paar voorzichtige stappen in die richting gezien. Geheugen als nand wordt vaak opeengestapeld in een package, maar vaak met de bedrading buiten de dies om. Een geavanceerdere vorm is de verbinding van de dies via tsv's en fabrikanten van nand zijn inmiddels allemaal aangeland bij 3d-integratie op de die. Een andere verbetering die energieverlies tegengaat en compactere hardware mogelijk maakt, is het gebruik van interposers. Onder meer AMD maakt hiervan gebruik bij zijn videokaarten met hbm-geheugen op een interposer met de asic. Dat maakt kortere lijntjes naar het geheugen en daarmee minder energieverlies, kleinere producten en hogere snelheden mogelijk.
Een methode om de package efficiënter te maken, zou een betere integratie kunnen zijn. In plaats van een relatief groot moederbord met daarop chips gesoldeerd die weer in eigen packages verpakt zijn, zou meer met stapelen of interposers gewerkt kunnen worden. We hebben al een paar voorzichtige stappen in die richting gezien. Geheugen als nand wordt vaak opeengestapeld in een package, maar vaak met de bedrading buiten de dies om. Een geavanceerdere vorm is de verbinding van de dies via tsv's en fabrikanten van nand zijn inmiddels allemaal aangeland bij 3d-integratie op de die. Een andere verbetering die energieverlies tegengaat en compactere hardware mogelijk maakt, is het gebruik van interposers. Onder meer AMD maakt hiervan gebruik bij zijn videokaarten met hbm-geheugen op een interposer met de asic. Dat maakt kortere lijntjes naar het geheugen en daarmee minder energieverlies, kleinere producten en hogere snelheden mogelijk.
We hebben inmiddels twee pijlers van het fundament onder scaling gehad: het productieproces, met onder meer euv, en architecturele veranderingen, met interposers en 3d-structuren. Overigens geldt voor beide pilaren dat dit niet de enige verbeteringen zijn. Zo kan al dan niet plasma enhanced atomic layer deposition of peald gebruikt worden om met grote precisie atoomdikke lagen materiaal op een substraat aan te brengen. En op het gebied van architectuur zullen we nog andere technieken bekijken die de Wet van Moore in stand moeten houden, maar die bekijken we in combinatie met de derde pijler: materialen.
Voorbij finfets
In de bestaansgeschiedenis van geïntegreerde circuits zijn al vele innovaties ontwikkeld om kleinere transistors mogelijk te maken. Zo werden in recente jaren technieken als strained silicium, hafniumoxide en, recentst, finfets ontwikkeld. Het is bijna vanzelfsprekend dat nieuwe architecturele technieken voor bijvoorbeeld interconnects of de opbouw van een transistor gepaard gaan met nieuwe materialen. Zo kunnen materialen niet altijd meeschalen met productienodes; het isolerende vermogen van siliciumoxide bleek onvoldoende voor gates in de 45nm-node, reden om hafniumoxide in te zetten, samen met metallische gates in plaats van siliciumgates. Dit resulteerde in de voor velen bekende hkmg-transistorgeneratie. Een mooi voorbeeld van nieuwe materialen gecombineerd met een nieuwe architectuur.
/i/2001188377.png?f=imagenormal)
Zo is scaling steeds een samenspel van manieren om de transistors en andere componenten te bouwen geweest, samen met het ontwikkelen en inzetten van nieuwe materialen, en zo zal het ook voor toekomstige scaling moeten gebeuren. De trend van '3d-transistors' met finfets zal doorzetten, in eerste instantie met steeds hogere vinnen om een groter oppervlak tussen gate en channel te realiseren, maar dat zal tegen grenzen aanlopen. Een tussenoplossing voor waarschijnlijk al de 7nm-node en zeker bij 5nm zal het gebruik van nanodraden voor de channels zijn. Daarbij kan de gate helemaal rondom het channel zitten, wat meer oppervlak en daarmee hogere stuurspanningen en hogere snelheden mogelijk maakt. Die nanodraden kunnen in eerste instantie horizontaal liggen, maar om 3d-integratie makkelijker te maken, zouden ze in de toekomst verticaal, staand dus, gebouwd moeten worden. Dat zou nanodraden waarschijnlijk tot 3nm inzetbaar kunnen maken.
Natuurlijk wordt gewerkt aan meer technieken; silicium nanodraden kunnen ook maar beperkt schalen, en veel verder dan 5 en 3nm is er nog weinig zeker over materialen en architecturen. Wel wordt volop gezocht. Zo wordt bijvoorbeeld steeds duidelijker dat de traditionele interconnect van koper een te hoge weerstand heeft, reden om wellicht naar materialen als kobalt over te stappen. In elk geval moeten de interconnects, de metalen sporen die transistors in een die elektrisch aansluiten, herzien worden. Met steeds meer en kleinere transistors op een chip zijn steeds meer spoortjes nodig om ze aan te sluiten, maar de ruimte op het platte vlak is natuurlijk beperkt. Ook nu moet stapelen van de traces oplossingen bieden, samen met bijvoorbeeld kobalt en andere verbeteringen in de back-end. Ter illustratie: een 14nm-chip heeft dertien lagen voor de bedrading; dat worden er voor elke stap een of twee meer.
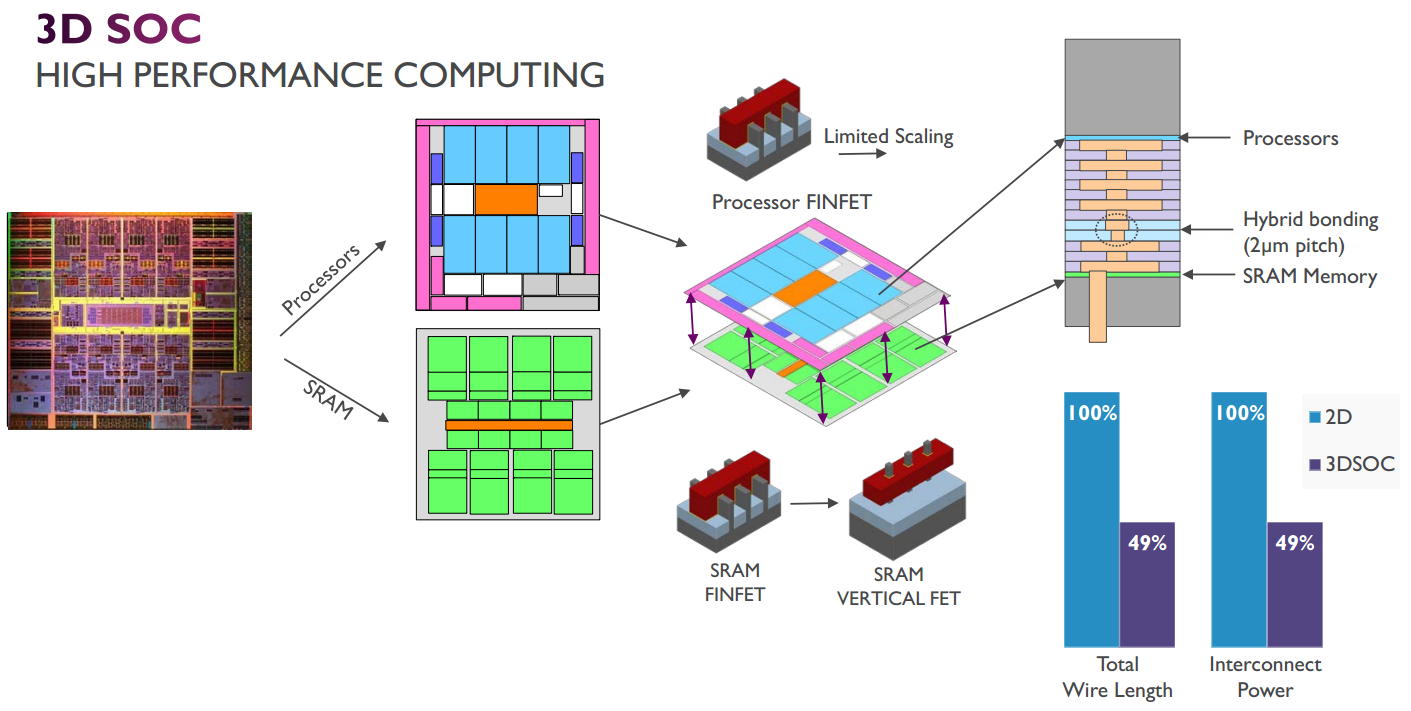
Om het gebrek aan oppervlakte te compenseren moeten toekomstige chips waarschijnlijk de hoogte in. Door verschillende dies te stapelen en de afzonderlijke dies ook nog eens verschillende lagen te geven, kan veel logica in een klein oppervlak ondergebracht worden. Zo kunnen een of meer v-nand-dies onder op een substraat aangebracht worden, met een isolerende laag ertussen en daarbovenop een of meer lagen processordies. Dat heeft als extra voordeel dat het geheugen hogere snelheden en lagere latencies kan halen, en bovendien, dankzij de eenvoudige, herhalende structuur, veel makkelijker te scalen is dan processordies. De verschillende dies kunnen ten slotte met tsv's met elkaar verbonden worden. Dat alles zou een reductie van ruim vijftig procent in de bedrading van de soc opleveren en een halvering van de benodigde energie voor de interconnects.
Er zijn tal van andere ontwikkelingen gaande op het gebied van scaling. Zo wordt onderzocht of andere materialen, waarvan zogenaamde III-V-halfgeleiders de bekendste zijn, beter functioneren op kleine schaal. Ook andere manieren om stromen te schakelen, zoals tunnel-fets of spin-fets, worden ontwikkeld en getest. Er wordt zelfs aan dna als opslagmedium gewerkt, maar dat is zo langzaam dat de praktische toepasbaarheid nog ver in de toekomst ligt.
Interposers en scm
Het moge duidelijk zijn dat het tijdperk van 'makkelijke' scaling definitief voorbij is. Sinds twee nodes zijn de productiekosten voor kleinere transistors dermate toegenomen dat deze de lagere prijs per transistor door hogere dichtheid niet meer kunnen compenseren. Dat wordt met de ontwikkeling van kleinere nodes alleen maar erger. De benodigde technieken worden steeds duurder, terwijl het aantal stappen voor de productie groter wordt en dus kost het meer tijd en meer geld om kleinere chips te maken. Het is niet langer voldoende of zelfs haalbaar om de winst wat kosten, prestaties en energiegebruik betreft te zoeken in simpelweg kleinere procedés. Je kunt het een buzzword vinden, maar een holistische aanpak, van materialen, het productieproces en de architectuur of opbouw van chips is nodig. Het is zaak in de komende jaren andere materialen dan silicium te zoeken en de interconnect aan te pakken. Dat moet gepaard gaan met een nieuw type transistor, waarbij gate all around, kortweg gaa, in de vorm van nanodraden in plaats van finfets de eerste grote verandering in architectuur zal vormen.
Vooral in de verpakking van de chips moet nog flink winst te halen zijn, waarbij interposers de klassieke Von Neumann-componenten als processor en geheugen dichter bij elkaar moeten brengen. Interposers zijn letterlijk en figuurlijk maar een tussenoplossing voordat chips 3d-geïntegreerd worden, met niet alleen 3d-nand maar ook 3d-processors in een enkele package, verbonden met tsv's. Dat levert echter weer een ander probleem op: warmte en energiegebruik. Om dat laatste te beperken worden transistors ontwikkeld die met steeds lagere spanningen werken en wordt aan interconnects gewerkt met een lage intrinsieke weerstand. Een lagere weerstand betekent minder verlies in het circuit en lagere spanningen maken zuinigere schakelingen mogelijk. Transistors van InGaAs in gaa-nanowires kunnen bijvoorbeeld met 0,5V aangestuurd worden, in tegenstelling tot silicium finfets die op minimaal 0,8V werken.

Dat neemt niet weg dat processors kampen met een fenomeen dat 'dark silicon' heet. Om binnen de warmte- en energiebudgetten te blijven, moeten grote delen van processors uitgeschakeld worden om niet te veel warmte te genereren en stroom te verbruiken. Naarmate circuits complexer worden, neemt het aandeel van dit dark silicon toe. De impact van dark silicon wordt deels het hoofd geboden door finfets, dynamic voltage en frequency scaling, ofwel lagere snelheden met lagere spanningen om het vermogen in te perken, maar rond 7 of 5nm wordt het aandeel dark silicon zo groot, dat deze technieken niet genoeg meer compenseren.
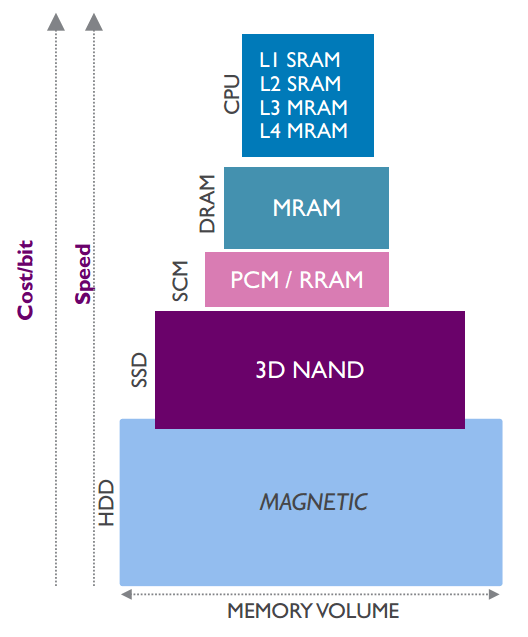 Opnieuw is er een aantal methodes om toch betere prestaties uit chips te persen. Zo kan voor meer geheugen gezorgd worden, vooral cache-geheugen dicht bij de cores levert prestatiewinst op, maar met traditionele architecturen is dat een prijzige aangelegenheid, vooral wat oppervlakte betreft. Sram is nog altijd het snelste geheugen dat we kunnen maken, maar voor de grotere caches is dat te duur; er zijn maar liefst zes transistors nodig voor een geheugencel. Voor de grotere caches, als de L3 en L4-caches, zou mram een oplossing kunnen vormen.
Opnieuw is er een aantal methodes om toch betere prestaties uit chips te persen. Zo kan voor meer geheugen gezorgd worden, vooral cache-geheugen dicht bij de cores levert prestatiewinst op, maar met traditionele architecturen is dat een prijzige aangelegenheid, vooral wat oppervlakte betreft. Sram is nog altijd het snelste geheugen dat we kunnen maken, maar voor de grotere caches is dat te duur; er zijn maar liefst zes transistors nodig voor een geheugencel. Voor de grotere caches, als de L3 en L4-caches, zou mram een oplossing kunnen vormen.
Dit magnetische geheugen is eenvoudig van structuur, maar wel snel. Net als dram is slechts één transistor nodig per geheugencel, maar mram is veel sneller doordat het niet afhankelijk is van het opladen van condensators, maar van het veel snellere tunnelmagnetoresistance-effect. Het feit dat mram op een magnetisch principe werkt, net als harde schijven, heeft als bijkomend voordeel dat het niet volatiel is. Bits blijven dus opgeslagen en hoeven niet zoals bij dram steeds ververst te worden.
Datzelfde mram zou dan ook een prima kandidaat zijn om het huidige dram, de tweede laag in de geheugenhiërarchie, te vervangen. Traditioneel bestond de derde laag uit magnetisch geheugen als harde schijven, maar daar is al enige tijd nand, in de vorm van ssd's, tussengekomen. We zijn bezig met nog een tussenlaag, tussen werkgeheugen en snel opslaggeheugen in. Dat zou een storage class memory tussen mram en 3d-nand worden en door phase change-geheugen gevormd moeten worden. Dat is snel, bit-uitleesbaar en niet volatiel. Intels 3d-crosspointgeheugen is daar een mooi voorbeeld van. In toekomstige computers zou daarmee de geheugenhiërarchie uitgebreid worden en sneller worden, zoals in de bovenstaande afbeelding.
Neuraal of Neumann?
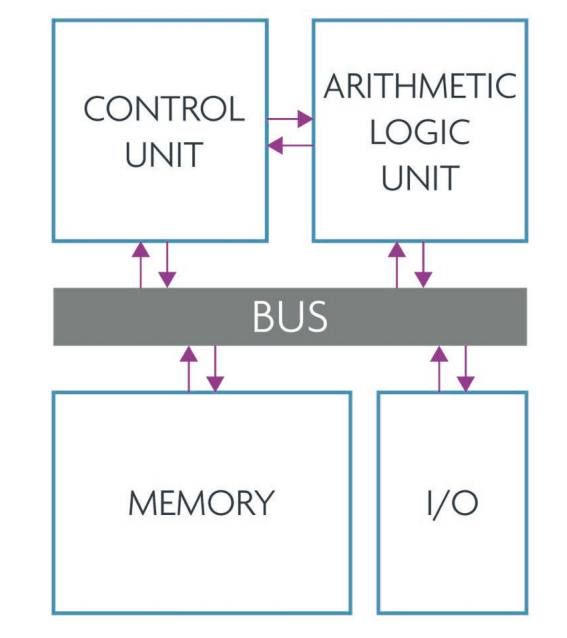
Daarmee zitten we nog steeds met bijzonder klassieke architecturen; een inputsysteem levert data aan een databus, een cpu rekent met de data en wisselt data uit met geheugen en uiteindelijk wordt een resultaat naar een output gestuurd. Dat principe staat bekend als een Von Neumann-architectuur en juist dat is waar onderzoekers en ontwikkelaars van toekomstige computersystemen wellicht vanaf willen stappen. Er zijn immers systemen die voor veel taken veel geschikter zijn dan klassieke architecturen, namelijk hersenen. Die zijn extreem goed in patroonherkenning en parallel werken. Juist dat is waar veel workloads steeds meer naartoe gaan en waar een neurale infrastructuur stukken beter zou presteren dan een Von Neumann-architectuur.
 Natuurlijk zullen klassieke computers gewoon doorontwikkeld worden en blijven bestaan, maar steeds meer computertaken worden visueel. Denk aan de enorme hoeveelheid foto's en video die dagelijks naar YouTube, Facebook en andere diensten verstuurd wordt. Bijna al die visuele informatie moet worden geïndexeerd, gecategoriseerd en geanalyseerd voor het doorzoekbaar maken, maar ook voor het taggen van bekenden op Facebook en om afbeeldingen of video te zoeken via Google. Ook de data van de toenemende hoeveelheid veiligheidscamera's moet geanalyseerd worden. Miljoenen videostreams leveren exabytes aan data op, een hoeveelheid die alleen maar toeneemt. Het geautomatiseerd analyseren en bewaren van alleen relevante beelden is werk voor computers met geavanceerde machine-visioncapaciteiten.
Natuurlijk zullen klassieke computers gewoon doorontwikkeld worden en blijven bestaan, maar steeds meer computertaken worden visueel. Denk aan de enorme hoeveelheid foto's en video die dagelijks naar YouTube, Facebook en andere diensten verstuurd wordt. Bijna al die visuele informatie moet worden geïndexeerd, gecategoriseerd en geanalyseerd voor het doorzoekbaar maken, maar ook voor het taggen van bekenden op Facebook en om afbeeldingen of video te zoeken via Google. Ook de data van de toenemende hoeveelheid veiligheidscamera's moet geanalyseerd worden. Miljoenen videostreams leveren exabytes aan data op, een hoeveelheid die alleen maar toeneemt. Het geautomatiseerd analyseren en bewaren van alleen relevante beelden is werk voor computers met geavanceerde machine-visioncapaciteiten.
Al die visuele taken kunnen stukken efficiënter worden uitgevoerd door neurale netwerken dan door klassieke computerarchitecturen. Daarbij maakt het weinig uit hoe dat neurale netwerk tot stand komt, maar een architectuur die speciaal daarvoor gebouwd wordt, is altijd efficiënter dan een geëmuleerd systeem. Dat is een reden om computers te ontwikkelen die naar neuronen gemodelleerd zijn, om zo neurale netwerken te bouwen die beter in staat zijn patronen te herkennen en visuele informatie te verwerken. Een groot aantal onderzoeksinstituten is hiermee bezig, niet alleen voor kortetermijntoepassingen zoals hierboven beschreven, maar ook om uiteindelijk menselijke hersenen te simuleren en wellicht om kunstmatige intelligentie te realiseren.
Exaflops, en dan?
Wat moeten we eigenlijk met al die rekenkracht? De desktop, of laptop zo je wil, is al een flink aantal jaar nauwelijks sneller geworden. Afgaande op enkel ons dagelijks gebruik, ook met smartphones en tablets, zou je dus vrij makkelijk kunnen zeggen dat de rek er een beetje uit is en dat sneller ook niet echt nodig is. Scaling is echter niet alleen sneller, maar ook zuiniger en vooral daar is nog veel winst te behalen, met accu's die het momenteel ternauwernood een dag uithouden. Ook op het gebied van rekenkracht worden we veeleisender. Een computer zonder ssd vinden we veelal niet bruikbaar, dus moet er goedkoop nand in, mogelijk gemaakt dankzij scaling, nieuwe 3d-architecturen en nieuwe materialen. Ook nieuwe interfaces, zoals spraak in de vorm van Cortana, Google Voice, Alexa en Siri, worden steeds belangrijker en kosten flink wat rekenkracht. Andere nieuwe interfaces, zoals Microsofts Hololens en virtual reality, hebben niet alleen veel rekenkracht nodig, maar profiteren van hardware die dankzij scaling zuiniger is geworden. Denk maar aan de rugzak met een pc die sommige fabrikanten op de Computex lieten zien om een 'kabelvrije' vr-beleving mogelijk te maken.
Onze verwachtingen maken een ander groot deel van de benodigde rekenkracht onmisbaar; we willen alles snel, direct en zonder wachten. Of dat nu bestellingen zijn, het uploaden van content, het zoeken naar van alles en nog wat of streamen, alles is afhankelijk van de cloud. Volgens velen een buzzword pur sang, maar absoluut noodzakelijk voor zo ongeveer alles wat we met onze gadgets doen en de vraag naar rekenkracht wordt alleen maar groter; denk maar aan de visuele taken van onder meer Google, Facebook en YouTube die rekenkracht vreten.
Auto's of robots?
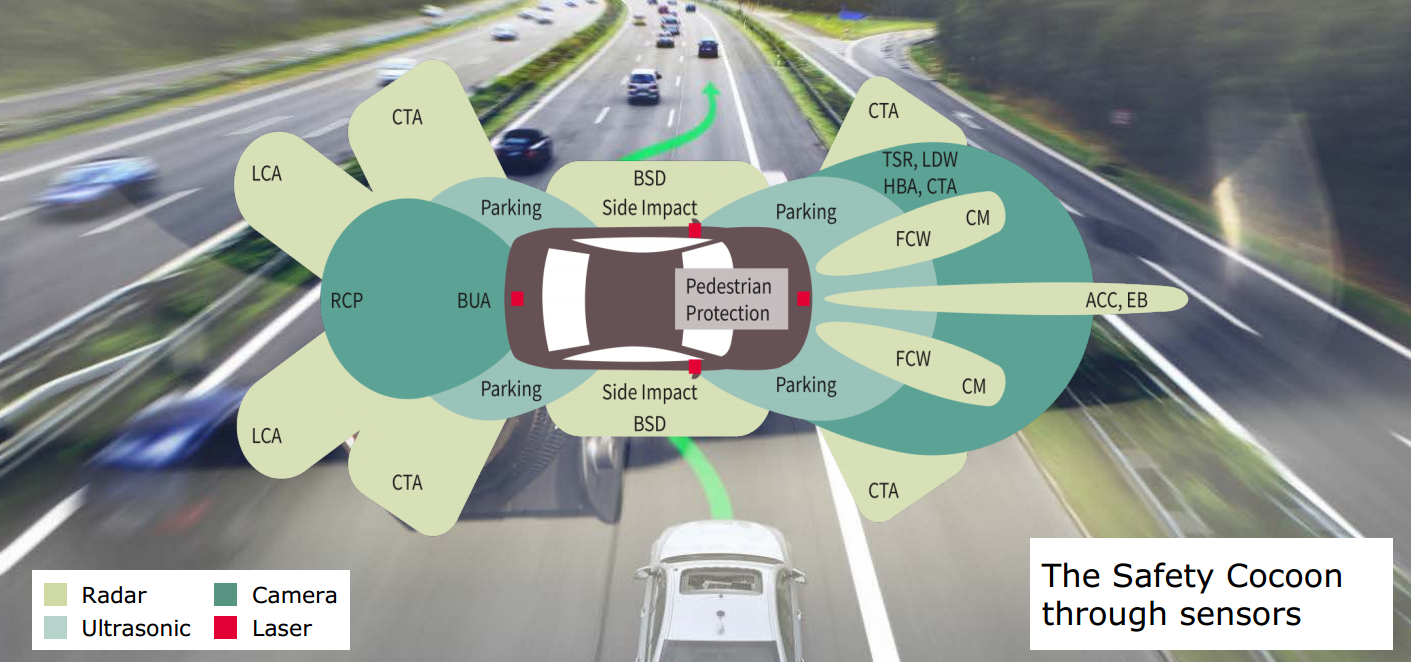 Een andere taak die in de komende jaren naar verwachting een grote vlucht zal nemen, is waarneming in het verkeer. Volgens diverse autofabrikanten - niet alleen Tesla, maar zo ongeveer elke fabrikant sleutelt hard aan autonome auto's - wordt de auto volledig vernieuwd. Het zou 'de slimste robot in ons leven' worden, aldus Audi, en slimme auto's hebben vanzelfsprekend rekenkracht nodig. Alle sensoren op een auto moeten zinvolle data opleveren, die geanalyseerd en gedeeld moet worden. De analyse moet bovendien razendsnel gebeuren; je auto kan moeilijk drie seconden nadenken als je met 120km/h over de snelweg rijdt. Ook hier zijn weer volop visual compute-taken weggelegd, van camera's die de omgeving in de gaten houden tot lidar- en radarbeelden die verwerkt moeten worden.
Een andere taak die in de komende jaren naar verwachting een grote vlucht zal nemen, is waarneming in het verkeer. Volgens diverse autofabrikanten - niet alleen Tesla, maar zo ongeveer elke fabrikant sleutelt hard aan autonome auto's - wordt de auto volledig vernieuwd. Het zou 'de slimste robot in ons leven' worden, aldus Audi, en slimme auto's hebben vanzelfsprekend rekenkracht nodig. Alle sensoren op een auto moeten zinvolle data opleveren, die geanalyseerd en gedeeld moet worden. De analyse moet bovendien razendsnel gebeuren; je auto kan moeilijk drie seconden nadenken als je met 120km/h over de snelweg rijdt. Ook hier zijn weer volop visual compute-taken weggelegd, van camera's die de omgeving in de gaten houden tot lidar- en radarbeelden die verwerkt moeten worden.
Ter illustratie: hetzelfde Audi dat ons autorobots belooft, huivert bijna van de kosten die daarmee gepaard gaan. Momenteel wordt namelijk al een dikke 30 procent van de productiekosten uitgegeven aan elektronica. Dat wordt rond 2020 35 procent en maar liefst 50 procent in 2025. Dat zijn kosten die het bedrijf niet in de hand heeft. Audi is een autofabrikant, geen radar- of socmaker, dus moet dat ingekocht worden. Dat is gek voor een fabrikant die van oudsher alle productie van een auto in eigen beheer had, maar illustratief voor de veranderingen in de automarkt.
Overigens moeten er een paar dingen veranderen, willen die slimme, rijdende robots het succes worden dat fabrikanten en futurologen voor ogen hebben. Aan de hardwarekant wordt gewerkt en vooruitgang geboekt; radar wordt krachtiger en kleiner, machine vision beter en onder meer Tesla en Google bewijzen dat autonome voertuigen veilig kunnen rijden. Om intelligent verkeer mogelijk te maken, moeten al die auto's echter ook verbonden worden via een snel netwerk met lage latency, zodat snel data kan worden uitgewisseld. Ook dat is met de ontwikkeling van 5g-dataverbindingen ondervangen. Al over twee jaar, bij de Olympische Winterspelen in 2018, zal een 5g-netwerk van 1Gbit/s getest worden.
Dan rest aan de hard- en softwarekant alleen nog veiligheid, zowel verkeers- als dataveiligheid. De grootste uitdaging zal echter in de beleving van mensen zitten; de regelgevers moeten overtuigd worden van de veiligheid en de bestuurder moet de controle uit handen geven. Een ander obstakel is het eigendom; we hebben graag een eigen auto. De investering in slimme auto's komt echter pas echt tot zijn recht als het gros van de auto's bijna continu rondrijdt en als autonome Uber-taxi's mensen vervoeren. Daarvoor moeten auto's worden ontworpen met een levensduur van dik 120.000 uur, voor 22,5 uur per dag gedurende vijftien jaar, in plaats van een levensduur van 8000 uur, goed voor 1,5 uur per dag gedurende vijftien jaar. Zo kan het vervuilende wagenpark enorm verkleind worden en maken auto's optimaal gebruik van wegen: weg files.
Op je gezondheid
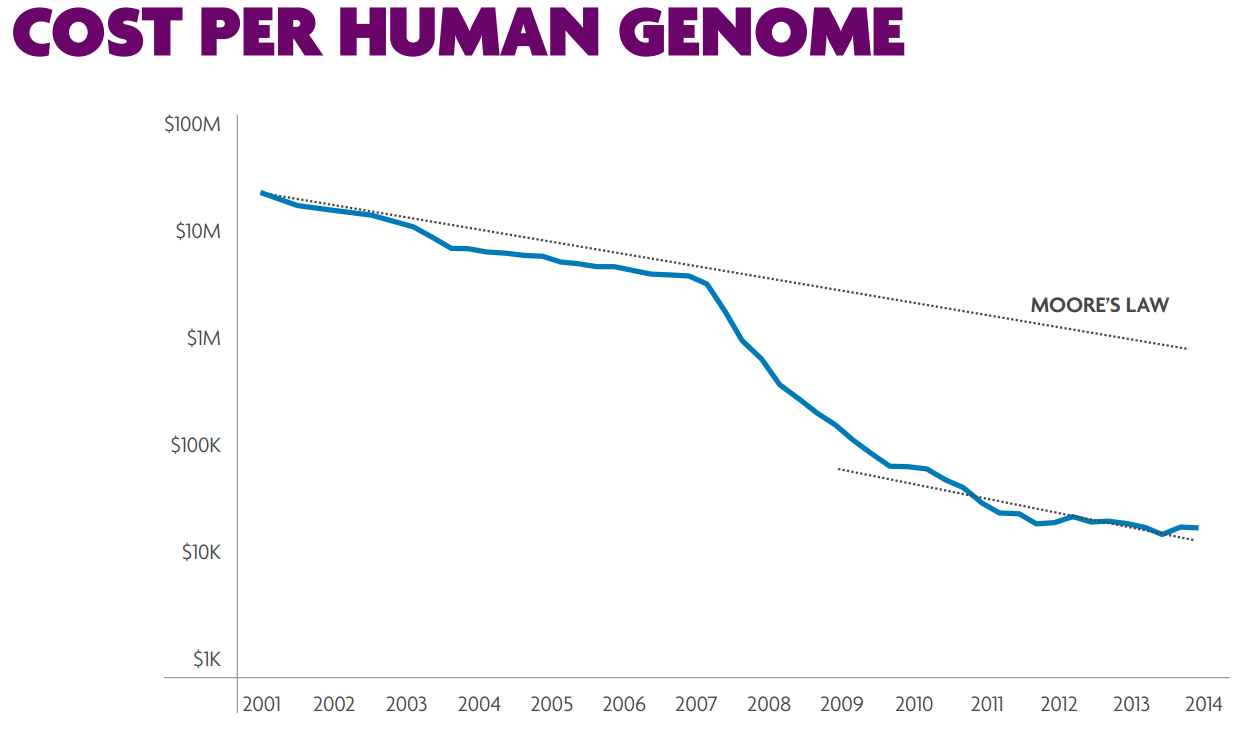 Een laatste belangrijke grootverbruiker van rekenkracht wordt de gezondheidszorg, als het aan onder meer GSK, Johnson & Johnson, Intel Life Sciences en natuurlijk het Imec zelf ligt. Voor allerlei velden, van het verwerken van data van clinical trials tot het zoeken naar nieuwe antibiotica tegen resistente bacteriën, en de simulatie van cellen om medicijnen te testen en onderzoek te doen: allemaal hebben ze honger naar veel rekenkracht, nieuwe manieren van dataverwerking en methodes om de enorme datastromen te verwerken. En dan hebben we het nog niet over genetische screening, bijvoorbeeld voor gepersonaliseerde behandelmethodes tegen specifieke kankervormen, in plaats van een botte bijl die veel schade aan gezond weefsel toebrengt. Het menselijke genoom is ongeveer 1TB groot en de snelle sequencing en analyse ervan kan levens redden.
Een laatste belangrijke grootverbruiker van rekenkracht wordt de gezondheidszorg, als het aan onder meer GSK, Johnson & Johnson, Intel Life Sciences en natuurlijk het Imec zelf ligt. Voor allerlei velden, van het verwerken van data van clinical trials tot het zoeken naar nieuwe antibiotica tegen resistente bacteriën, en de simulatie van cellen om medicijnen te testen en onderzoek te doen: allemaal hebben ze honger naar veel rekenkracht, nieuwe manieren van dataverwerking en methodes om de enorme datastromen te verwerken. En dan hebben we het nog niet over genetische screening, bijvoorbeeld voor gepersonaliseerde behandelmethodes tegen specifieke kankervormen, in plaats van een botte bijl die veel schade aan gezond weefsel toebrengt. Het menselijke genoom is ongeveer 1TB groot en de snelle sequencing en analyse ervan kan levens redden.
Kortom, de Wet van Moore mag dan inmiddels al ruim vijftig jaar oud zijn en al enige keren geherformuleerd zijn, hij is nog steeds de leidraad, of misschien wel self-fulfilling prophecy, die de halfgeleiderindustrie voortstuwt. De jaren van makkelijke scaling, waarbij de geometrie van transistors en chips vrij eenvoudig verkleind kon worden, zijn echter definitief voorbij. Het wordt moeilijker en moeilijker om kleinere transistors te maken en al helemaal om dat tegen dalende kosten te doen. De materialen, het onderzoek, de apparatuur en de tijd die de productie kost: alles wordt duurder en complexer. Toch is de industrie van mening dat scaling niet alleen moet, maar ook kan doorgaan, al is het dan op manieren die veel complexer zijn dan voorheen.
Scaling moet een samenspel worden van alle betrokken elementen en partijen, van de architectuur, tot materialen en productiemethode. Ook chemische bedrijven, zoals BASF, werken samen met fabrikanten om nieuwe materialen te ontwikkelen en nieuwe methodes om die per atoom te beheersen. Want ook al lijkt het dat laptops al vijf jaar nauwelijks sneller zijn geworden, de vraag naar meer rekenkracht, beheersing van energie aan zowel de opwek- als verbruikskant en nieuwe technologie zoals visual computing, machine vision, big data, cloudtechnologie en smart cities zullen in de komende jaren alleen maar toenemen. De Wet van Moore heeft dat allemaal mogelijk gemaakt en zal dat blijven doen.
:strip_icc():strip_exif()/i/2004698074.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003043920.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001508423.jpeg?f=fpa_thumb)
/i/2001435493.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001004567.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2000601725.jpeg?f=fpa_thumb)
/i/1383492840.png?f=fpa_thumb)
:strip_exif()/i/2005283572.jpeg?f=fpa)
:strip_exif()/i/2005686012.jpeg?f=fpa)
:strip_exif()/i/2004114990.jpeg?f=fpa)
/i/2001665377.png?f=fpa)
/i/1309767168.png?f=fpa)
/i/2000820476.png?f=fpa)
/i/1297430422.png?f=fpa)
/i/2001435495.png?f=fpa)
:strip_exif()/u/56159/archer.gif?f=community)
/u/96692/chili_pepper.png?f=community)
/u/95480/crop6360e43b695cb_cropped.png?f=community)
/u/137180/TS4YTL60R.png?f=community)
/u/38782/crop6146c7a29805d_cropped.png?f=community)
:strip_icc():strip_exif()/u/348363/crop5673ea2423487_cropped.jpeg?f=community)
:strip_exif()/u/489455/7750.gif?f=community)
:strip_icc():strip_exif()/u/101289/vimes60.jpg?f=community)
:strip_icc():strip_exif()/u/5634/crop616bfdd3d480f_cropped.jpg?f=community)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
:strip_icc():strip_exif()/u/481280/Foto%2520van%2520mij%25204.jpg?f=community)
:strip_icc():strip_exif()/u/20862/dusty2.jpg?f=community)
:strip_icc():strip_exif()/u/413995/crop5daf4ad59bbb8.jpeg?f=community)
/u/715027/crop6047c50ae8d4c.png?f=community)
:strip_icc():strip_exif()/u/116283/crop5814e3224425d_cropped.jpeg?f=community)
/u/477729/crop585be4a453f0d_cropped.png?f=community)
:strip_icc():strip_exif()/u/481839/e-resized.jpg?f=community)
/u/254093/crop678fb402f18f5_cropped.png?f=community)
:strip_exif()/u/111031/clark2.gif?f=community)
:strip_icc():strip_exif()/u/79988/XD_small.jpg?f=community)
:strip_icc():strip_exif()/u/614228/crop6023bf71e398d_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/63694/spion200_250-150x150.jpg?f=community)
/u/262016/crop64ed94e1a7757_cropped.png?f=community)
:strip_icc():strip_exif()/u/65843/chef60x60.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_icc():strip_exif()/u/285051/teaglass_tweakers.jpg?f=community)
:strip_icc():strip_exif()/u/24792/74f128e7b84aec3866ab9eff6d09b097.jpg?f=community)
:strip_icc():strip_exif()/u/511682/crop5bb0eaf29070f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/273605/NS.jpg?f=community)
{kind=link}