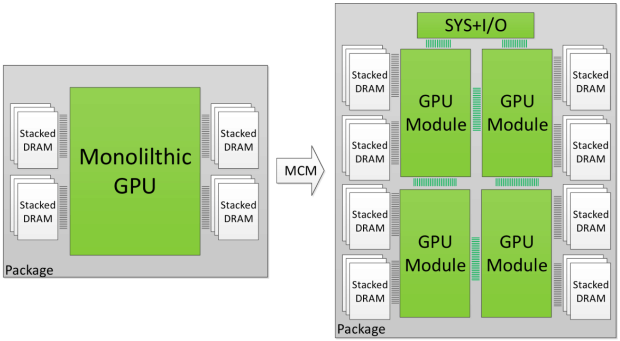
Onderzoekers van Nvidia hebben een paper gepubliceerd waarin zij een gpu beschrijven die is opgebouwd als een multichip-module. De gpu bestaat daarmee uit meerdere delen, die met een interconnect met elkaar verbonden worden.
Het opdelen van de gpu in meerdere modules moet het volgens het onderzoek mogelijk maken om grotere gpu's te produceren die meer rekenkracht hebben. Historisch gezien worden gpu's steeds krachtiger omdat het aantal transistors in een chip van gelijke grootte steeds toeneemt dankzij kleinere productieprocessen, maar in de afgelopen jaren is gebleken dat die Wet van Moore steeds moeilijker te volgen is.
Het maken van een enkele grote chip is bovendien erg kostbaar. Door deze op te delen in verschillende stukjes en een multichip-module te maken van bijvoorbeeld vier dies nemen de kosten af. Ook zou op deze manier een gpu gemaakt kunnen worden met een grootte die onmogelijk is als een enkele monolithische chip.
De onderzoekers beschrijven een gpu die bestaat uit bijvoorbeeld vier gpu-modules. In hun onderzoek stellen ze drie verschillende architectuuroptimalisaties voor die moeten zorgen voor een minimaal verlies bij de communicatie tussen de verschillende modules. Volgens de onderzoekers benadert hun ontwerp de prestaties van een theoretische monolithische chip van het vergelijkbare formaat. Het mcm-ontwerp zou maar 10 procent langzamer zijn.
Het is al mogelijk om meerdere gpu's met elkaar te combineren, door bijvoorbeeld twee of meer videokaarten in een sli-opstelling te gebruiken. Volgens de onderzoekers presteert het mcm-gpu-ontwerp echter 26,8 procent beter, dan een vergelijkbare multi-gpu-oplossing.
Of en wanneer Nvidia daadwerkelijk gpu's gaat maken op basis van een mcm-ontwerp is nog niet bekend. De voorstellen in het onderzoek zijn allemaal gebaseerd op theoretische berekeningen. AMD gebruikt al een multichip-module-ontwerp in zijn Epyc-serverprocessors en in de komende Threadripper-cpu's voor high-end desktops. AMD verbindt de dies met elkaar via zijn Infinity Fabric. Eerder heeft AMD al aangegeven dat die interconnect ook gebruikt kan worden voor gpu's.

/i/2001190117.png?f=fpa_thumb)
:strip_exif()/i/2001508675.jpeg?f=fpa)
/i/2000820476.png?f=fpa)
/i/2001435495.png?f=fpa)
/u/324913/crop56a24cce05cd3_cropped.png?f=community)
:strip_icc():strip_exif()/u/405148/numatic-henry-plus-eco-stofzuiger.jpg?f=community)
:strip_icc():strip_exif()/u/637028/crop6a3e22601b0f7_cropped.jpg?f=community)
/u/75323/5procentoog.JPG?f=community)
/u/657708/crop5808fb779c7a3_cropped.png?f=community)
/u/243953/crop56f55a7bcf291.png?f=community)
/u/343341/crop6095457d39560_cropped.png?f=community)
:strip_exif()/u/677/crop5e62ccc026e5a_cropped.gif?f=community)
/u/4501/crop5bdb35c450e89.png?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
/u/295372/piq_51496_60x60.png?f=community)
/u/195334/crop612515c58c13c_cropped.png?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
/u/355158/crop575b478b97ccb.png?f=community)
{kind=link}