Intel gaat processors opdelen in onderdelen die op verschillende productieprocedés gefabriceerd worden. Processors kunnen zo uit 10nm-, 14nm- en 22nm-delen bestaan. Daarnaast heeft Intel een nieuwe zuinige 22nm-node aangekondigd.
Intel gaf tijdens de Technology and Manufacturing Day in San Francisco details over bestaande en komende technieken die het gebruikt bij de chipproductie. Het bedrijf kondigde onder andere aan dat het heterogene 'mix and match'-ontwerpen gaat toepassen bij processorproductie in plaats van monolithische ontwerpen. Hierbij worden bijvoorbeeld de cpu en gpu op 10nm geproduceerd, terwijl de input/output als pcie- en geheugencontrollers en overige onderdelen op 14nm geproduceerd worden. De mogelijkheid onderdelen op deze manier te combineren is mogelijk door Intels emib-technologie, of embedded multi-die interconnect bridge, die delen efficiënt met elkaar verbindt.
Anders dan een grote silicon interposer maakt de emib-technologie gebruik van kleine interposers die alleen voor communicatie tussen de verschillende dies zorgt: voeding wordt via meer traditionele metaallagen verzorgd. Dat brengt de kosten van de interposer omlaag en vereenvoudigt het ontwerp en maakt bovendien grotere chips mogelijk. Het voordeel van de heterogene ontwerpen is dat niet de gehele complexe processor op een nieuwe node-generatie overgezet hoeft te worden, wat een positieve invloed kan helpen op de opbrengst van goed functionerende chips en minder r&d-kosten met zich meebrengt. De eerste chip waarbij Intel dit toepast is de Stratix 10-fpga.
Aanvullend maakte Intel bekend dat de platform controller hub, het equivalent van de chipset, vanaf de eerste helft van 2018 op 14nm in plaats van 22nm geproduceerd gaat worden, wat Intels platform zuiniger moet maken. Ergens in dat jaar start ook de fabricage van networking-chips op 14nm, terwijl de productie van modems nog eind dit jaar op die 14nm-node overgaat.




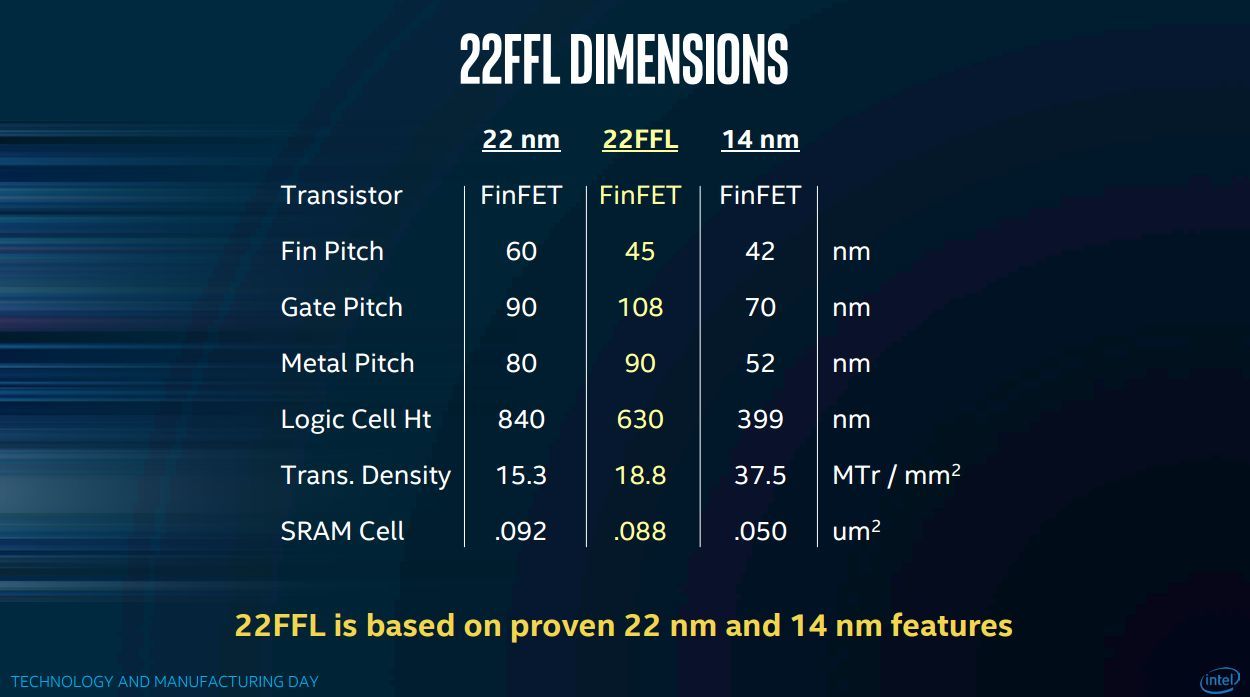
Intel kondigde verder een nieuwe 22nm-generatie aan: 22FFL, een energiezuinige node voor iot- en mobiele toepassingen. Intel heeft zijn 22nm verfijnd en onder andere de lekstromen met een factor honderd verkleind. Daarbij heeft het bedrijf kennis van zijn 14nm-node gebruikt en wat omvang van de features betreft zit 22FL dan ook tussen Intels 22nm- en 14nm-node in. Intel schuift zich als custom foundry voor productie voor derde partijen naar voren en ziet met name toepassingen voor internet-of-things-producten en mobiele chips voor de 22FFL-node. Wat kosten betreft zou de node zich kunnen meten met 28nm- en 22nm-nodes.
Verder stelt Intel een nieuwe manier voor om de naamgeving van nodes op te baseren. Intel-senior fellow, Mark Bohr constateert dat niet alle chipfabrikanten zich nog houden aan de lineaire schaalverkleining van 0,7x voor de belangrijkste features bij de overstap naar een nieuwe node, wat tot een 'zooitje' met betrekking tot de naamgeving heeft geleid. Intel stelt daarom voor een nieuwe formule te hanteren om tot de hoeveelheid transistors per vierkante mm te komen:
| 0,6 | x | 2-input-nand transistoraantal | + | 0,4 | x | Scan Flip Flop transistoraantal | = | # transistors/mm2 |
| 2-input-nand celloppervlak | Scan Flip Flop celloppervlak |
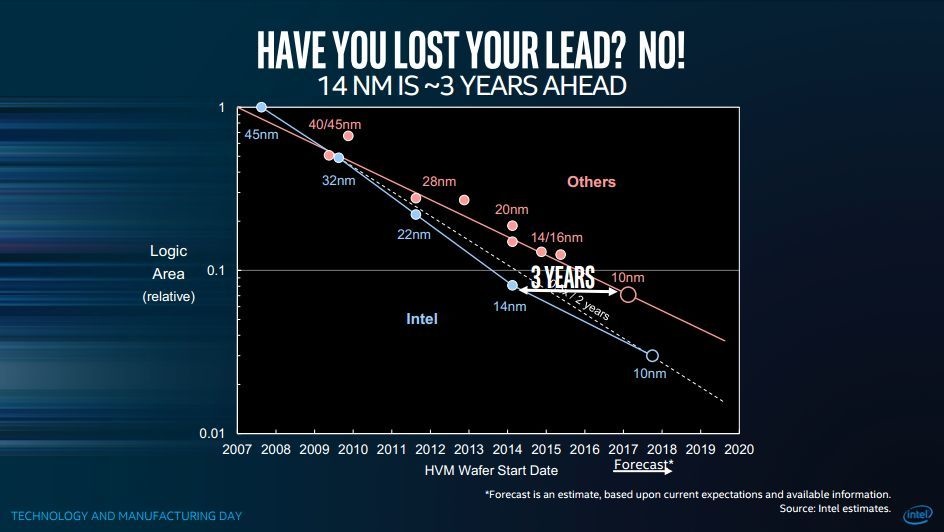
De fabrikant tekent aan dat het oppervlak van sramcellen hierbij buiten beschouwing gelaten is. Intel stelt voor deze afzonderlijk te vermelden. De chipgigant claimt bij gebruikmaking van de formule met zijn 10nm-node nog altijd een voorsprong te hebben op de gelijknamige nodes van concurrenten als TSMC en Samsung. Volgens Intel zit er nog voldoende rek in de Wet van Moore voor de afzienbare toekomst en het bedrijf claimt zelfs steeds beter te kunnen schalen. Voor de 10nm-productie zet Intel self-aligned quad patterning in. Quad-patterning zorgt voor hogere kosten, maar de hogere yields en verkleining van de interconnect-pitch door het gebruik van de self-aligned-techniek zouden dit compenseren.
Intel gaat de 10nm-productie inzetten voor zijn Cannonlake-processors, waarvan de eerste chips voor laptops later dit jaar moeten verschijnen. Het bedrijf noemde een chipoppervlak van 7,6mm2, waar een vergelijkbare 14nm-chip 17,7mm2 in zou nemen. Niet eerder zou het bedrijf een verkleiningsfactor van 0,43x hebben behaald. Een refresh van de 10nm-node, die Intel alvast 10++ noemt, zou voor verdere prestatie- en verbruiksverbeteringen zorgen.



/i/2001435493.png?f=fpa_thumb)
/i/2001665377.png?f=fpa)
/i/1309767168.png?f=fpa)
/i/1235349650.png?f=fpa)
/i/2001752657.png?f=fpa)
:strip_exif()/i/1398151713.jpeg?f=fpa)
/i/2001331269.png?f=fpa)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/212961/Alfred%2520Max%2520Headroom.png?f=community)
:strip_icc():strip_exif()/u/63387/crop619c2ec45e26f_cropped.jpg?f=community)
/u/203098/Stalker60.png?f=community)
:strip_icc():strip_exif()/u/30256/right_of_way_065.jpg?f=community)
:strip_icc():strip_exif()/u/280016/crop58a99242b659f_cropped.jpeg?f=community)
/u/27299/hoofd.png?f=community)