De reacties zijn een van de waardevolste onderdelen van Tweakers. Regelmatig vind je daar interessante, diepgaande extra informatie van experts en gebruikers met praktijkervaring over een onderwerp. In dit artikel zetten we de beste reacties met een +3-moderatie van juni op een rij.
Tweakers maken Tweakers. Dit platform bestaat bij de gratie van gebruikers, die discussiëren op het forum, handelen op V&A en elkaar zelfs tijdens live-evenementen ontmoeten. Maar een van de belangrijkste onderdelen waar tweakers hun waarde toevoegen, zijn de reacties. Die houden ons niet alleen scherp en corrigeren ons op fouten, maar geven ook vaak waardevolle context of extra informatie die anderen meer kan leren. Daarvoor zijn we erg dankbaar. Het gaat bijvoorbeeld om informatie uit de praktijk, die we zelf nooit kunnen weten zonder die praktijkervaring.
De beste reacties worden door andere tweakers met een +3 beoordeeld. De lat om een +3-moderatie op een reactie te krijgen ligt hoog, maar dat levert wel erg mooie resultaten op.
Wat is dit artikel?
In dit artikel laten we zien wat de beste reacties op Tweakers waren in de afgelopen periode. Zo willen we andere gebruikers in aanraking brengen met reacties die ze misschien hebben gemist. We willen maandelijks een uitdraai maken van alle +3-reacties. We beginnen nu met de reacties uit juni. We zijn benieuwd wat je van dit artikel vindt. Laat dat weten in de comments − al zullen die niet snel een +3 krijgen!
Hoe maak je wafers?
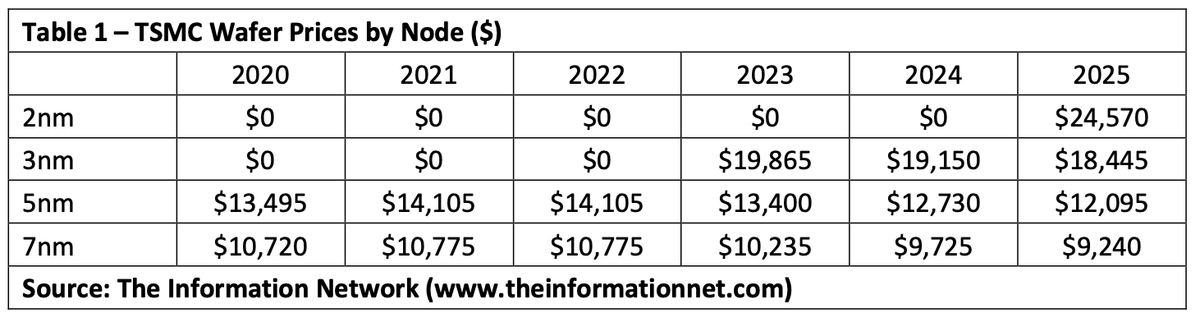
Computerchips maken is, op z'n zachtst gezegd, ingewikkelde materie. Niet gek dus dat twee van de tien +3-reacties onder een artikel over TSMC's waferprijzen staan. Tweaker jdh009 legt in deze reactie uit hoe de prijzen per wafer worden berekend.
Klopt, toen ik het overzicht las vroeg ik me ook het een en ander af, dus zelf het een en ander nagezocht. Wat je volgens mij kunt stellen is dat bij de door Dutchzilla genoemde wafers vrijwel iedere wafer een 300 mm (12 inch) is. De (gelekte) prijzen van TMSC vond ik hier (2004-2022) en hier (2020-2025, met pprijsontwikkeling over tijd) en bedragen (inflatiecorrectie niet toegepast):
- 90nm (2004): $2.000
- 40nm (2008): $2.600
- 28nm (2014): $3.000
- 10nm (2016): $6.000
- 7nm (2018): $10.000
- 5nm (2020): $16.000
- 3nm (2022): $20.000
- 2nm (2025) $25.000
De meerprijs per wafer komt vooral door duurdere materialen (zoals wafers die schoner, vlakker, zuiverder en mechanisch stabieler moeten zijn, en de hogere kosten voor EUV-resist en reticles), extra processtappen (EUV double patterning) en duurdere apparatuur om dit alles te doen (blame ASML). Dat maakt het mogelijk om een aantal algemene regels te stellen over chipdichtheid, kostprijs en opbrengst per wafer. Het waferformaat ligt immers vast, waardoor het aantal chips per wafer vooral wordt bepaald door de chipgrootte, complexiteit, gebruikte node en de yield.
In theorie zou je bij kleinere nodes dus het volgende verwachten:
- Een kleinere node laat kleinere dies toe en dus méér chips per wafer
- Bij gelijke chipgrootte neemt de complexiteit toe: meer transistoren per mm²
- Meer chips per wafer verlaagt de kostprijs per chip, als de yield gelijk blijft
- Een kleinere node betekent echter ook een duurdere wafer
In de praktijk:
- Chips worden meestal niet kleiner, omdat ontwerpers de extra transistorruimte gebruiken voor meer functionaliteit (vooral bij high-end SoC’s, GPU’s en CPU’s)
- De chipgrootte blijft daardoor gelijk of groeit zelfs, waardoor het aantal chips per wafer beperkt blijft
- Niet elke chip vereist een kleinere die; soms zijn oudere nodes goedkoper en praktischer (zie veel uit de autobranche)
- Bij nieuwe nodes is de yield in het begin vaak lager door een hogere kans op defccten
- Daardoor zijn er minder werkende chips per wafer dan je op basis van de node zou verwachten
- Intussen stijgen de waferkosten, wat de prijs per werkende chip verder opdrijft
- De yield verbetert vaak na verloop van tijd, zodra bijv. TMSC het productieproces beter onder de knie heeft
- De transistordichtheid blijft in de praktijk vaak achter bij de theoretische limiet, waardoor de verwachte efficiëntiewinst per mm² niet volledig wordt gehaald (zie tabel hieronder).
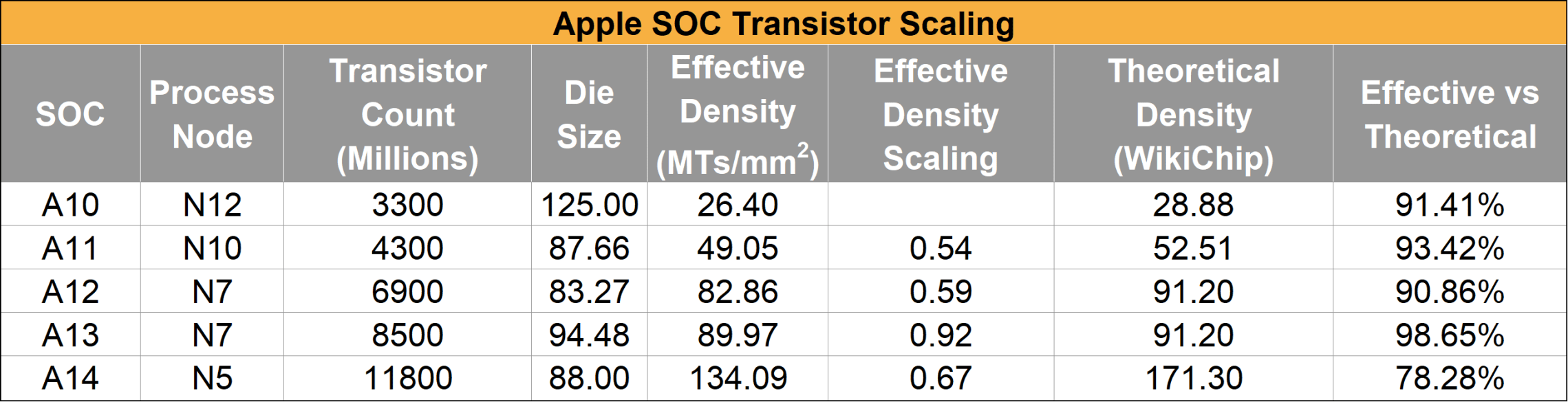
En ik zal vast nog wel wat missen. Tijdens het zoeken kwam ik een mooi voorbeeld tegen van de iPhone-SoC. Tabelletje hier: https://tweakers.net/fotoalbum/image/BJsxXjGq7MzWp3C2LYBuFX9L.webp.
Als je de Apple-SoC’s van A10 tot A14 vergelijkt, zie je dat de die size niet geleidelijk afneemt. Van 125 mm² bij de A10 (16nm, 3,3 miljard transistors) daalt het eerst flink tot 83 mm² bij de A12 (7nm, 6,9 miljard transistors), maar stijgt daarna weer naar 98 mm² bij de A13, omdat Apple op dat oppervlak (nog) meer functionaliteit wilde onderbrengen. Bij de A14 (5nm, 11,8 miljard transistors) daalt de die size licht naar 88 mm², maar blijft deze nog steeds groter dan bij de A12.
Een 300 mm-wafer heeft een totaal oppervlak van ongeveer 70.700 mm², maar door de cirkelvorm en de rechthoekige vorm van chips treden er randverliezen op. Het bruikbare oppervlak voor chips ligt daardoor meestal rond de 63.000 tot 65.000 mm². Bij een chipgrootte van circa 100 mm² passen er dus grofweg 630 tot 650 chips op één wafer, mnatuurlijk afhankelijk van de plaatsing en de vorm van het chipontwerp.
Als we dit toepassen op Apple, zien we dat chips in de praktijk niet altijd evenredig krimpen bij een kleinere node. Apple gebruikt de extra transistorcapaciteit zoals de zien is vaak voor meer cores, grotere GPU’s of AI-units, waardoor de die-grootte regelmatig gelijk blijft of zelfs toeneemt, zoals in het voorbeeld van twee alinea's terug. Hierdoor nam het aantal chips per wafer niet sterk toe en daalde het zelfs percentage werkende chips, ondanks theoretisch kleinere die grootte.
Als je daarmee gaat rekenen, kun je voor Apple de volgende theoretisch te verwachten aantallen chips per wafer afleiden. Deze schattingen houden ook rekening met randverliezen, dus met het effectief bruikbare oppervlak van een 300 mm-wafer:
- 28 nm (A7, 102 mm²): +/- 620 chips
- 20 nm (A8, 89 mm²): +/- 715 chips
- 16 nm (A9, 96–104 mm²): +/- 610–660 chips
- 16 nm (A10, 125 mm²): +/- 510 chips
- 10 nm (A11, 89 mm²): +/- 715 chips
- 7 nm (A12, 83,3 mm²): +/- 760 chips
- 7 nm (A13, 98 mm²): +/- 650 chips
- 5 nm (A14, 88 mm²): +/- 720 chips
Bron: https://www.anandtech.com/show/9686/the-apple-iphone-6s-and-iphone-6s-plus-review/3One of the immediate ramifications of dual sourcing is that the die sizes of the A9s are different. The A9 produced by Samsung on their 14nm FinFET Process is the smaller of the two, at 96mm2. Meanwhile the A9 produced on TSMC’s 16nm FinFET process is 104.5mm2, making it about 9% larger. Though not an immense difference in size (and not that we’d expect otherwise) there are tradeoffs to be had. With all other things held equal, the larger TSMC die would produce fewer complete dies per 300mm wafer, and any given die is more likely to have an imperfection since there are fewer dies for the same number of imperfections.
Waardoor je kunt stellen dat: een groter oppervlak levert minder chips per wafer op en vergroot de kans dat een defect een chip raakt.
Ook de yield daalt over het algemeen bij nieuwe, fijnere nodes, vooral in de beginfase, al is volgens recentere cijfers de yield van TSMC’s 3 nm inmiddels (2025) boven de 90% terwijl het bij Samsung minder goed gaat (maar dit is wel sterk afhankelijk van ontwerp en klant):Bron: https://asiatimes.com/2024/02/smic-to-sell-huawei-costly-inefficient-5nm-chips en https://www.trendforce.com/news/2025/05/29/news-samsungs-3nm-yield-reportedly-stuck-at-50-far-behind-tsmcs-90/Media reports said TSMC has already boosted the yield of its 7nm and 5nm chips to 93.5% and 80%, respectively, in 2019. Now TSMC is making 3nm chips with a yield of 55%, competing against Samsung’s 60-70%.
Samung: According to South Korean media outlet Chosun Biz, even after three years of mass production, its 3nm yields remain at just 50%.
Daardoor kunnen er vrij veel chips wel geproduceerd worden, maar uiteindelijk onbruikbaar blijken door defecten, wat resulteert in een lage yield. Soms zijn ze nog deels bruikbaar, als defecte onderdelen uitgeschakeld kunnen worden terwijl de rest van de chip nog functioneert, zodat ze alsnog binnen de specificaties vallen en als een lager model verkocht kunnen worden, wat kosten kan besparen.Maar dat kun je niet aannemen. Op 2nm zal een verder (qua functionaliteit) identieke chip kleiner zijn dan een chip op een ouder procede en passen er dus meer van die chips op dezelfde wafer.
Dat klopt... theoretisch betekent een kleinere node kleinere transistoren, en dus een kleinere chip bij gelijke functionaliteit. Maar, zoals je hierboven in mijn veel te uitgebreide tekst leest, is niet elke chip gebaat bij een kleinere node. Of dat zinvol is, hangt af van de toepassing, de bijbehorende kosten, de beschikbaarheid van productiecapaciteit en eisen zoals betrouwbaarheid, bestendigheid of lange levertermijnen (vooral in de auto-industrie krijgen oudere nodes vaak de voorkeur, omdat kleinere nodes gevoeliger zijn voor spanningspieken, hitte en straling.)
En zelfs als een chip wel op een kleinere node wordt geproduceerd, betekent dat niet automatisch dat hij ook kleiner wordt, zoals in het voorbeeld van Apple’s SoC’s, waar de diegrootte vaak gelijk bleef of zelfs toenam. Daardoor blijft het aantal (potentiële) chips per wafer in de praktijk meestal vergelijkbaar met eerdere generaties, zolang een kleinere node vooral benut wordt voor extra functionaliteit binnen dezelfde oppervlakte en dat in het eindproduct ook daadwerkelijk een meerwaarde oplevert.
:strip_exif()/i/2007447210.jpeg?f=imagenormal)
Geen lieve ontwikkelaar
Een beetje drama is de opensourcewereld niet vreemd, maar als je als ontwikkelaar heel radicale ideeën hebt, val je zelfs daar op. Het viel deadinspace dan ook op dat de ontwikkelaar achter een Xorg-fork erg opvallend gedrag vertoonde. Dat wordt mooi uiteengezet in deze reactie:
Oef, ik ben even een beetje verder gaan kijken, maar dit is wel de moeite van het opmerken waard. In de project description van de XLibre fork staat inderdaad:
EnIt's explicitly free of any "DEI" or similar discriminatory policies.
Maar dat is maar het topje van de ijsberg. Ik vind deze passage bovenaan in de project description misschien wel zorgwekkender voor het project:Together we'll make X great again!
"Moles from BigTech" proberen Xorg te vernietigen? Dit klinkt gewoon als een complottheorie.That fork was necessary since toxic elements within Xorg projects, moles from BigTech, are boycotting any substantial work on Xorg, in order to destroy the project, to elimitate competition of their own products. Classic "embrace, extend, extinguish" tactics.
Hij postte ook dit over corona vaccins op de Linux kernel mailing list (waarop Linus Torvalds hem in typische Linus-stijl vertelt dat hij op moet flikkeren):En het wordt niet beter naarmate ik verder zoek. Hij is een Duitser, en hij lijkt van mening te zijn dat Duitsland in WW1 en WW2 meer slachtoffer was van "de imperialisten" dan iets anders. Selectieve quote:And I know *a lot* of people who will never take part in this generic human experiment that basically creates a new humanoid race (people who generate and exhaust the toxic spike proteine, whose gene sequence doesn't look quote natural). I'm one of them, as my whole family.
> So yes, sure, nobody can stop people that think the pandemic is over
> ("we are vaccinated") from meeting in person.
Pandemic ? Did anybody look at the actual scientific data instead of just watching corporate tv ? #faucigateAndere juweeltjes in dat bericht zijn dat hij ontevreden is dat de extreem-rechtse AfD met Nazi's vergeleken wordt, en hij wil dat Holocaust-ontkenning legaal is.WW1 was clearly *NOT* started by Germany - the only mistake of the Emperor was officially declaring a war, that was already going undeclared. And WW2 was forced upon Germany, and the allied rejected all the numerous peace offerings from the German side.
Oef. Maar, terug naar XLibre, en het verhaal achter de fork. Hij klaagt dus dat "Redhat employees banned [...] so censored all my work" omdat "My most evil heresies probably were: a) forking Xorg and making *actual progress*".
Hij lijkt inderdaad te hebben bijgedragen aan Xorg; Zo'n 800 commits sinds februari 2024.
800 commits klinkt veel, maar bij het scrollen door die lijst viel me onder andere deze commit op met maar 6 gewijzigde regels:Dat is niet heel groot, en lijkt ook niet al te belangrijk. Maar ok, cleanupje, mogelijk prima. Maar hij heeft 24 van dat soort "os: unexport Foo" commits. Zo kom je wel aan 800.os: unexport ClientIsLocal()
Not used by any modules, so no need to keep it exported.
In zijn andere cleanups is het een aantal keer voorgekomen dat hij onbedoeld Xorg stuk maakte voor gebruikers, wat kritiek van andere Xorg ontwikkelaars opleverde. Het lijkt er nu op dat die verstandhouding inmiddels zo slecht is dat hij er uit gegooid is (of boos is opgestapt? Ik kon zo snel geen bewijs vinden dat hij echt geband is).
Het is moeilijk en veel werk om de precieze dynamiek uit te zoeken zonder honderden commits, bugreports en mails te lezen, maar ik vond de discussies in de volgende twee Xorg git issues de sfeer wel een beetje samenvatten.
In 1760: Xorg git broken again (oktober 2024, issue is nog steeds open?):In 1797: xrandr doesn't work anymore on xorg-git (februari 2025). Sommige comments zijn gericht aan Enrico Weigelt, sommige comments gaan over hem:davidbepo: @metux i appreciate you maintaining and trying to improve Xorg but this is the second time you break it recently, you really should implement more testing...
Jasper St. Pierre: Honestly, I would strongly recommend just not merging anything @metux does from now on. I do not feel that their presence here has been a net positive -- I have seen zero actual bugs solved by any of their code changes. What I have seen is build breakage, ABI breakage, and ecosystem churn from moving code around and deleting code.
Xorg could use some actual maintenance, but that means fixing actual bugs and solving real problems.Peter Hutterer: bugs happen, that's normal, but the commit at fault here (c6f1b8a7) did nothing but shuffle code around. No bug fixed, no new feature added, just changing things around. And there are hundreds of other commits like this.
Michel Dänzer: Apologies for being blunt, but I'm afraid it's more like "everyone except you" by now. He's managed to fall out with pretty much every other active project member.
[...]
In general, a very small percentage of Enrico's commits have any user-visible effect. I honestly don't believe they truly benefit Xorg users, certainly not enough to make up for the churn and pain.
Peter Hutterer: I'm not sure why you think trash-talking code that's several decades old is useful. Rules, requirements and tools were different 20 years ago, and even more different 40+ years ago and you're ignoring the various user visible changes that have been fixed over decades. Or, IOW, you're apparently unaware or ignoring that dozens of people have also improved things before you came to your realization that the code is bad.
Some of the code you've been rewriting hasn't changed for decades and requiring others to review, build and test changes just to have e.g. different struct initialization style (like the commit set that triggered this regression) is not worth it. Easy to fix does not imply easy to review and certainly does not imply the result is bug-free.
I burnt myself out trying to review your flood of patches that shuffle things around and eventually gave up. For me this also meant I stopped looking at other MRs because everything else got drowned out.
Daniel Stone: And yet, as @whot says above, your changes are not helping. Changing calls pScreen->DestroyPixmap to dixDestroyPixmap doesn't meaningfully improve the code or make it easier to reason about. Moving byte-swapping of requests and events from one function to another doesn't make the code more robust. Cosmetic changes to the way length fields are written doesn't help with byte vs. word unit confusion, or keep you from writing the wrong amount of data. You're just moving the complexity from point A to point G, not reducing it.
[...]
The immense value X11 has - that it always had and will have for decades to come - is its backwards compatibility, still being able to run 40-year old apps. You correctly called the codebase 'fragile' - you've been finding this out as your changes repeatedly break things. If you're breaking apps, then what exactly is the value in a codebase which is 'cleaner' to your subjective standard but doesn't actually work? If you're trying to get to a multi-threaded xserver, have you read the classic MTX post-mortem where the people who actually did it discussed the problems they faced and why they discontinued it?
Jasper St. Pierre: @metux that you've had to fix this bug twice (!1844 (merged), !1845 (merged)) shows a lack of attention and care. This was a known regression, with clear reproduction steps, and at first glance, it does not look like you tested your PR at all.De aard van zijn technische bijdragen en de kritiek van langer actieve Xorg developers geven me dan ook weinig hoop.
Alles bij elkaar zie ik twee goede redenen om XLibre niet al te serieus te nemen.
De impact van schermtijd op kinderen
Hoe erg is schermtijd nou eigenlijk écht voor kinderen? Die discussie speelt al jaren, maar Mirved zette eens op een rij wat het wetenschappelijk onderzoek daar eigenlijk over zegt, bij dit artikel over hoe het Nederlandse kabinet Europese normen voor socialemediagebruik bij kinderen wil invoeren.
Wist niet dat Smartphones en Social media in deze vorm al 100 jaar bestond. Wat betreft onderzoek:
Een Canadese en Zuid-Koreaanse studie toonde aan dat zelfs kleine hoeveelheden mobiele schermtijd bij baby's (rond 18–30 mnd) samenhangen met taalachterstanden: elke extra 30 min/dag verhoogt de kans op taalvertraging met ~49 %
https://pmc.ncbi.nlm.nih.gov/articles/PMC8572488/
peuters (3–5 j) die meer dan 1 uur/dag schermtijd hadden, minder witte stof-ontwikkeling hadden in hersengebieden belangrijk voor taal en zelfregulatie.
https://pmc.ncbi.nlm.nih.gov/articles/PMC6830442/
Een studie met 7.097 kinderen in Japan toonde dat 1 tot 4 uur schermtijd op leeftijd 1 gekoppeld was aan significant hogere kans op ontwikkelingsachterstanden (communicatie, fijne motoriek, sociale vaardigheden) op de leeftijd van 2
https://edition.cnn.com/2...risks-wellness/index.html
Britse Canadeze peuters (3–5 j) met meer dan 1 uur/dag schermtijd bleken een 48 % lagere kans te hebben op goede werkgeheugencapaciteit.
https://pubmed.ncbi.nlm.nih.gov/35599677/
Studies tonen aan dat vroege blootstelling aan smartphones en YouTube samenhangt met verhoogde emotionele/gedragsproblemen, door blootstelling aan ongepaste content en algoritmische aanbevelingen
https://bmcpublichealth.b...0.1186/s12889-024-19011-w
:strip_exif()/i/2007558052.jpeg?f=imagenormal)
Intels massaontslagen
Intels sores houden veel tweakers al lang bezig. Ook de interne strubbelingen rond de massaontslagen van duizenden werknemers zijn interessant, zoals kidde uitlegde bij dit artikel over die massaontslagen.
Dat is niet het hele verhaal:
De chip-foundry van AMD fuseerde met Chartered om GlobalFoundries te vormen, en GlobalFoundries bleek op het laatste moment geen werkend 14nm proces te hebben. AMD was contractueel vastgelegd om bij GlobalFoundries te kopen. TSMC was geen optie; Ryzen 1 was eigenlijk ten dode opgeschreven.
Tegelijk had Samsung het 14nm proces ontworpen voor Exynos smartphone-processors. En wonder boven wonder, kwam iemand van op het lumineuze idee, om Samsungs 14nm smartphone-proces in licentie te geven aan GlobalFoundries.
En ziedaar, het succes van Ryzen: dat zorgde ervoor dat AMD in een keer competitieve server-chips had. En dat zorgde voor de marge-compressie (hard teruglopende winst vanwege verlies van de monopolie-positie) bij Intel.
Vervolgens, Intel 10nm: Het is hetzelfde verhaal over net een beetje teveel hoogmoed van Market Garden / "een bridge too far". Bij Market Garden moesten de geallieerden tegelijk bruggen veroveren in Son en Breughel, Veghel, Nijmegen en Arnhem, en als er 1 zou mislukken, zou het hele project (hogere doel was eerder in Berlijn zijn dan de Sovjets) mislukken. En dat gebeurde helaas.
Natuurlijk werd Montgomery gewaarschuwd dat het plan megalomaan was (onder andere door Sosibowski); en Montgomery zou later aangeven dat alles fout had kunnen gaan; maar het enige probleem was de infrastructuur; er was niet genoeg hulp - en met name door Montgomery zelf niet genoeg tijd (!) gegeven aan het 1e Canadese leger om de Westerschelde (en daarmee diepzeehaven) Antwerpen in te nemen. En daardoor waren de aanvoerlijnen niet goed.
Intel 10nm zat ook zo in elkaar:
-Veghel: Er was een ontwerp waar het hele ontwerp-team aan had gewerkt, genaamd Cannon Lake, dat afhankelijk was van de M1 poly-pitch (kleinste afstand tussen metalen geleidende kanalen van dit proces) van 36nm. Als die afstand groter zou worden, zou Cannon Lake niet meer maakbaar zijn.
-Son en Breughel: Intel zou voortaan Single Dummy gates gebruiken; een beetje het idee van ruimte-besparing van een trein in de 2e klas, vergeleken met de 1e klas . Waarbij je in plaats van twee "prive-armleuningen" per stoel, je de armleuning "deelt' met de buurman, waardoor er eentje weggelaten kan worden.
-Nijmegen: Contact over active gate: De contacten zitten niet meer naast een bepaalde schakeling, maar er boven.
-Arnhem: Vanwege quantum fysica tussen verschillende lagen, kunnen er vroeg of laag electronen gaan "lekken" tussen 2 lagen die moeten isoleren. Als er veel "druk" op de lagen staat (potentiaal-verschil a.k.a. voltage) over langere tijd, kan daardoor de chip gaan falen.
Om dat te voorkomen, ging Intel een nieuw materiaal gebruiken bij de grenslaag: Kobalt.
Bij het maakproces echter, komen er vaak spanningen in het materiaal; net als bij metaal harden. Om dat "ontgedaan" te maken gloei je metaal na; vaak aangeduid als "ontlaten".
Intel echter had geen ervaring met kobalt ontlaten, en de leverancier van de ontlaat-ovens (Applied Materials) had Intel aangegeven, dat volgens de leverancier dus (AMAT), het proces nog niet rijp was voor massa-productie. Dus net als Montgomery had Intel eigenlijk de "infrastructuur" voor het plan niet op orde; en teveel haast gemaakt; en niet naar waarschuwingen geluisterd omdat ze dachten dat ze het beter wisten dan anderen.
Intel echter dacht dat ze beter wisten dan de leverancier hoe ze dat voor elkaar moesten krijgen, en dat mislukte.
Daarom mislukte de brug 'Arnhem', (kobalt), en daarom mislukte het hele project 10nm; en was Cannon Lake dus ook ten dode opgeschreven.
Welnu, het electro-migratie-probleem: Om tegen te gaan dat er voor het einde van de levensduur electronen gaan lekken bij de grenslaag, moet je de "slijtage" op het grensvlak verminderen. Dat kan door te kiezen voor een kortere levensduur, maar voor servers is dat geen optie.
Of je kiest ervoor de "druk" (spanning, voltage dus) te verlagen. Daar koos Intel voor, en de frequentie is een derdemachts-functie van het voltage.
Intel heeft vermoedelijk het voltage met 10% moeten verlagen, dan is de frequentie 1.103 = 33% lager, en daarom was Cannon lake in plaats van 4gHz op 3gHz gezet.
Waarom hadden TSMC en GloFo geen last van het cobalt-verhaal: Van TSMC weet ik het niet, maar GloFo zat in de common platform alliance met IBM; en die hebben hele goede natuurkundigen. Iemand, mogelijk iemand van IBM; heeft een ander trucje bedacht, ik dacht iets met mechanische spanning op het materiaal zetten, waardoor ze geen last hadden van het levensduur-verkortende electromigratie probleem. En daarom had de concurrentie helemaal geen Kobalt nodig.
Vervolgens mocht AMD na het 14nm proces contractueel weg bij GlobalFoundries, maar ze wilden daar wel klant blijven. Dus had iemand wederom een lumineus idee: Het mixen van GlobalFoundries (I/O die) met TSMC binnen 1 chip. Zo kon een stuk van Ryzen 1 (Samsung proces dus) hergebruikt worden met kleinere dies van TSMC, en daardoor kon AMD sneller vooruit; zonder alles overnieuw te hoeven ontwerpen.
Overigens, double patterning en met name SADP (single aligned double patterning) is juist iets waar Intel extreem goed in is; ze waren er zelfs zo goed in dat ze het twee keer achter elkaar konden doen om tot SAQP (single alligned quadruple patterning) te komen. De Intel baas heeft ooit gezegd dat er echter quintuple of sextuple patterning nodig was; terwijl bijvoorbeeld Samsung gewoon het veel eenvoedigere LELELE deed (litho-etch-lito-etch-lito-etch). Dus eigenlijk totaal verchillende keuzes.
Lichte en donkere foto's
Onze downloadssectie is vooral populair omdat tweakers er zelf hun praktijkervaringen kunnen delen met software. In deze releasenotes over het fotobewerkingsprogramma Darktable zette dipje2 op een rij hoe dat programma werkt met lichte en donkere foto's.
Het hele "scene referred" betekent dat je zo lang mogelijk blijft werken in "ruw licht" als values... Eigenlijk een soort van hdr mode om het simpel uit te leggen, en dan een tone mapping stap op het eind om het in normaal, gamma correct sdr te krijgen.
Daarna kan je ook wel changes maken, maar echte kennis van "hoeveel licht" is dan weg, het is meer "lichter en donkerder", maar niet meer absoluut. Beetje vaag om in een reactie te omschrijven.
Filmic-rgb en sigmoid zijn inderdaad twee manieren om die tone mapping stap te doen. Filmic-rgb is gemaakt door een ontwikkelaar die ondertussen niet meer aan Darktable werkt, maar zijn eigen fork.
Filmic-rgb kan veel leuke dingen, maar is moeilijk te begrijpen soms, en doet dingen die niet altijd gewenst zijn. Sigmoid is _meestal_ simpeler en heeft minder settings / parameters. En daarom makkelijker in het gebruik.
Alle twee werken ze door een soort van curve te maken, een S-curve die voor wat contrast zorgt. Highlights zitten wat meer bij elkaar, shadows zitten wat meer bij elkaar, wat ruimte in het midden voor je mids. Bij filmic-rgb kan je veel parameters aanpassen om die curve te beïnvloeden, en hoe diep gaan de shadows en waar stoppen de highlights (alle twee moet je eerst met exposure het middenpunt instellen). Sigmoid zal altijd alle data gebruiken die er is, en zelf een mooie contrast curve maken. Maar die kan je dus moeilijker tweaken. En aanpassingen moet je dus eigenlijk doen voor sigmoid, vooral met de tone equalizer (waar je bepaalde zaken lichter en donker kan maken). Omdat je bij filmic-rgb het tonemapping process meer kan beinvloeden, merk ik dat het niet altijd nodig is om dingen 'goed' te hebben voor die stap. Dingen zoals shadow-crush regel ik in filmic-rgb, niet in een aparte module bijvoorbeeld.
Ze verschillen ook in wat ze - standaard - doen met de highlights in combinatie met kleur.
Denk aan een mooie knalrode bloem. Geef die meer licht... Meer licht, meer licht... nog meer licht. Wat gebeurt er met het knalrood? Wordt het ooit zo licht dat het puur wit wordt, en je geen rood meer ziet? Of blijft het knalrood? Of er tussen in?
Sigmoid gaat uiteindelijk naar wit toe, en een hoop mensen verwachten dat. Vooral met sunsets en landschappen, en dergelijke. Maar bij portret of human subjects kan het juist gewenst zijn dat je de kleur (beter) blijft zien, en juist niet naar wit gaat.
Ook met kleuren 'out of gamut' zit er verschil. Diezelfde knalrode bloem. Die is veeeeel te rood dan wat er eigenlijk mogelijk is in sRGB plaatjes. Je camera heeft wel de mogelijkheid om de hoeveel rood goed op te vangen, maar als je het uiteindelijk op het web of op de standaard wil weergeven, moet je iets met die TE intense kleur rood. Wil je de details in het rood bewaren? Dan maak je het minder intensief. Je raakt dan saturation kwijt, maar je hebt wel al het kleurverloop. Of clip je het zodat zo veel mogelijk van de saturatie behouden blijft, maar met de kans dat je geen verschil meer ziet in 'hoe rood', alleen maar 'puur rood'.
Hier hebben ze verschillende algoritmes, en hier wordt ook constant aan gesleuteld.
Dat zijn ook problemen in de wereld van Blender of DaVinci Studio trouwens, alleen bestaan er standaarden in de video wereld (ACES?) die blind gebruikt kunnen worden. Niet omdat ze correct zijn, maar omdat iedereen ze gebruikt.
Ze zijn nog aan het experimenteren en worstelen wat je moet doen met dingen 'out of bounds'. Of het nu brightness is of kleurinfo, er zijn vele wegen naar Rome. En geen lijkt geschikt voor alle situaties.
Sigmoid is dus wel de simpelere van de twee en krijgt wat meer liefde en aandacht van de ontwikkelaar(s) die er nog zijn, en is waarschijnlijk gekozen als default omdat het gewoon beter werkt met zero slider tweaken, en minder 'fout' doet. Filmic-rgb heeft meer mogelijkheden en kan een live saver zijn (en snappen wat alles doet, maakt je heel veel beter in Darktable) maar kan soms ook gewoon troep produceren. En als dat de default rendering is, denken veel gebruikers "darktable zuigt".
Andere reacties
In totaal werden er in juni 19 reacties uitgedeeld die uiteindelijk op een +3-moderatie zijn beland. Dat gebeurde zowel onder nieuwsartikelen als onder .geeks, reviews en downloads. Hieronder vind je alle reacties.

:strip_icc():strip_exif()/i/2007146242.jpeg?f=fpa_thumb)
/i/2007634940.png?f=fpa)
:strip_exif()/i/2007644500.jpeg?f=fpa)
:strip_exif()/i/2005823556.jpeg?f=fpa)
/i/2006843282.png?f=fpa)
/i/2007153598.png?f=fpa)
/i/2007418864.png?f=fpa)
/i/2006495260.png?f=fpa)
:strip_exif()/i/2005332048.jpeg?f=fpa)
:strip_exif()/i/2007557970.jpeg?f=fpa)
/i/2004675202.png?f=fpa)
:strip_exif()/i/2007543314.jpeg?f=fpa)
/i/1289231065.png?f=fpa)
/i/2007132434.png?f=fpa)
/i/2007355830.png?f=fpa)
:strip_exif()/i/2005121800.jpeg?f=fpa)
:strip_exif()/i/2007527762.jpeg?f=fpa)
/i/2007186220.png?f=fpa)
:strip_exif()/i/2004681518.jpeg?f=fpa)
:strip_exif()/u/8063/phizzie_05.gif?f=community)
/u/314383/crop5dc6a4144d574_cropped.png?f=community)
:strip_icc():strip_exif()/u/448966/crop62a741840cd69_cropped.jpg?f=community)
/u/590416/crop5d8a8f12228ba_cropped.png?f=community)
:strip_icc():strip_exif()/u/727882/crop66e07cc209d99_cropped.jpg?f=community)
:strip_exif()/u/26152/INV_Misc_Gem_Emerald_01.gif?f=community)
:strip_icc():strip_exif()/u/107933/crop624ed9e4ef1a5_cropped.jpg?f=community)
/u/263454/crop69528a83920d8.png?f=community)
:strip_exif()/u/165291/Beholder60.gif?f=community)
/u/508326/02fe8676b9194155ae0a61dd1cfc9f8c.png?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
/u/298866/crop5ef045407bab9_cropped.png?f=community)
/u/464964/crop5706bee0228c3_cropped.png?f=community)
:strip_icc():strip_exif()/u/535868/crop602666c56a991_cropped.jpg?f=community)
/u/189401/crop5a5e7beb70a42_cropped.png?f=community)
:strip_icc():strip_exif()/u/821329/crop6817c75ef2272_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/453808/image.jpg?f=community)
:strip_icc():strip_exif()/u/116600/crop5be04a1ae3ded_cropped.jpeg?f=community)
/u/112676/crop63f49f7963127_cropped.png?f=community)
:strip_icc():strip_exif()/u/79969/crop5dd9232d4f793_cropped.jpeg?f=community)
{kind=link}
{kind=link}