Een nieuwe generatie
- AMD Ryzen 9 7950X
- AMD Ryzen 7 7700X
Samengevat
De AMD Ryzen 9 7950X is ruim sneller dan zijn voorganger en biedt dankzij het modernere AM5-platform veel meer mogelijkheden. De processor is in specifieke workloads dankzij optimalisaties en nieuwe instructiesets enorm veel sneller dan de 5950X. Die ultieme prestaties gaan wel gepaard met een erg hoog stroomverbruik, en het koelen van de chip is ook een uitdaging.
Samengevat
De AMD Ryzen 7 7700X is de goedkoopste processor met ondersteuning voor AVX-512 die we tot nu toe hebben getest. Voor dergelijke specifieke workloads is dat erg interessant, maar voor veel andere workloads, waaronder gaming, is de Intel Core i7-12700K een sterke concurrent. Het voordeel van de Intel-processor is dat je goedkoper DDR4-geheugen kunt gebruiken. Daar staat tegenover dat het AM5-platform veel langer mee zal gaan en je in de toekomst de 7700X dus makkelijker kunt upgraden.
De nieuwe AMD Ryzen 7000-processors op basis van de Zen 4-architectuur zijn, gecombineerd met de AM5-socket en de nieuwe chipsets, zonder twijfel de grootste technologische stap van AMD's processorportfolio van de afgelopen jaren. Een nieuwe generatie werkgeheugen, een geheel nieuwe socket en een beter productieproces zorgen ervoor dat AMD tot de tanden toe gewapend de strijd met Intel kan aangaan.
Die strijd is er een waar AMD eigenlijk niet omheen kan. Bijna een jaar geleden kwam Intel met zijn twaalfde generatie Core-processors, ook bekend als Alder Lake. De processors uit het blauwe kamp wisten met een geslaagde combinatie van een betere architectuur en een beter productieproces de Ryzen 5000-processors goed uit te dagen en in een aanzienlijk deel van de tests te verslaan. Met de Zen 4-architectuur in de Ryzen 7000-serie moet daar verandering in komen en AMD stelt dan ook dat het tegelijkertijd de snelste cpu-core voor gamers en de grootste hoeveelheid compute voor contentcreators heeft.
Voor deze review hebben we de twee processors getest die AMD ons tot dusver heeft opgestuurd: de Ryzen 9 7950X en de Ryzen 7 7700X. De Ryzen 9 7900X en Ryzen 5 7600X kunnen volgens de fabrikant elk moment binnenkomen, dus binnenkort kun je ook van deze modellen een review op Tweakers verwachten.
/i/2005372142.png?f=imagenormal)
De AMD Ryzen 7000-modellen
Het laagst gepositioneerde model van de nieuwe generatie is de Ryzen 5 7600X, een hexacoreprocessor met een turbokloksnelheid van 5,3GHz die 365 euro kost. Daarboven staat de Ryzen 7 7700X, die met acht cores op maximaal 5,4GHz draait en 489 euro moet gaan kosten. Vervolgens telt de Ryzen 9 7900X twaalf cores en een turboclock van 5,6GHz met een prijs van 669 euro. Het topmodel betreft de Ryzen 9 7950X, die net als zijn voorganger over zestien cores beschikt. De maximaal opgegeven turboclock van 5,7GHz ligt 800MHz hoger dan op de 5950X, terwijl de prijs van 699USD wel 100 dollar lager ligt dan bij zijn voorloper. In euro's merken we daar niet zoveel van, gezien de huidige koersen, en dat betekent dan ook dat de officiële adviesprijs van de Ryzen 9 7950X momenteel 849 euro bedraagt.
| Modelnaam |
Cores/Threads |
Baseclock |
Boostclock |
Cache (L2+L3) |
Tdp |
Adviesprijs in euro's (incl. BTW) |
| AMD Ryzen 9 7950X |
16C/32T |
4,5GHz |
5,7GHz |
80MB (16+64) |
170W |
€ 849 |
| AMD Ryzen 9 7900X |
12C/24T |
4,7GHz |
5,6GHz |
76MB (12+64) |
170W |
€ 669 |
| AMD Ryzen 7 7700X |
8C/16T |
4,5GHz |
5,4GHz |
40MB (8+32) |
105W |
€ 489 |
| AMD Ryzen 5 7600X |
6C/12T |
4,7GHz |
5,3GHz |
38MB (6+32) |
105W |
€ 365 |
/i/2005372140.png?f=imagenormal)
De Zen 4-architectuur
Het doel van AMD met Zen 4 was om double digit-ipc-verbeteringen en hogere kloksnelheden te halen, gecombineerd met een effectievere cache die ook een lagere latency heeft. AMD stelt dat het met Zen 4 gemiddeld 13 procent betere prestaties per kloktik bereikt dan met Zen 3. Dit cijfer is een gemiddelde van 22 verschillende workloads. Per test lopen de verbeteringen redelijk uiteen. Cinebench R23 vertoont bijvoorbeeld een verbetering van 9 procent, terwijl wPrime er maar liefst 39 procent op vooruitgaat.
Verbeteringen aan de frontend
Dit deel van een cpu-core haalt x86-instructies op, die meestal lang en ingewikkeld zijn, en verdeelt ze waar mogelijk in zogenaamde micro-ops waarmee de rekeneenheden daadwerkelijk aan de slag kunnen. In de frontend zijn er twee manieren om dit doel te bereiken. De traditionele, maar relatief langzame manier haalt instructies op uit de L1-cache, zet ze in de wachtrij en decodeert ze een voor een. De alternatieve en veel snellere manier kan worden gebruikt als een gedecodeerde instructie al in de micro-opcache staat. In de praktijk komen instructies vaak meer dan eens terug, waardoor telkens opnieuw decoderen niet nodig is.
/i/2005372036.png?f=imagenormal)
Onveranderd is het formaat van de instructiecache, die sinds Zen 2 al 32 kilobyte bedraagt. AMD heeft met Zen 3 de werking ervan geoptimaliseerd en om de bitrate van de micro-opcache nog verder te verhogen, heeft AMD de micro-opcache flink vergroot ten opzichte van Zen 3. Daarmee kan deze cache nu ruim 6700 in plaats van 4096ops bevatten. Bovendien is het aantal macro-ops per kloktik toegenomen van zes naar negen bij de nieuwe architectuur. Voor het sneller aanvoeren van lange instructies is de branch target buffer flink vergroot, op zowel L1- als L2-niveau. Daarin worden vertakkingen en de benodigde cache-informatie bijgehouden. Het eerste cacheniveau kan nu 1536 regels bevatten, tegenover 1024 regels bij Zen 3. De cache van het tweede niveau is van 6500 regels bij Zen 3 opgevoerd naar 7000 regels bij Zen 4.
Verbeteringen aan de execution-engine
Bij de integer-units zijn de gecombineerde alu- en agu-schedulers van Zen 3 gebleven, en ook bij Zen 4 kan elke scheduler 24 entry's verwerken, waardoor het totaal met 4 schedulers nog steeds op 96 uitkomt. De verbetering hier is echter dat de aansluitende registers zijn verbreed, van 192 entry's op Zen 3 naar 224 op Zen 4.
/i/2005372038.png?f=imagenormal)
Voor de floatingpoint-units is, net als voor de integer-units, de register file vergroot. Bij Zen 4 is deze 20 procent groter geworden en kan hij 192 entry's bevatten. Een noemenswaardige en opvallende toevoeging is dat Zen 4-processors ook AVX-512 ondersteunen. Dit heeft AMD bereikt door de verdubbelde schedulers elk 256bit te laten afhandelen en vervolgens samen te voegen, wat wel een extra cycle vereist. Dat dit niet exact dezelfde snelheid als een volledige 512bit-opstelling geeft, erkent AMD zelf ook, maar volgens de fabrikant is de behaalde versnelling wel aanzienlijk, met als voordeel dat het energiegebruik beperkt blijft en de kloksnelheden er geheel niet onder te lijden hebben. Daarbij mag gezegd worden dat de lijst van ondersteunde extensies van AVX-512 vrij uitgebreid is. Voor de meeste consumenten is AVX-512 vandaag de dag vrijwel niet relevant, maar voor het professionele segment en de enterprisemarkt is dat anders.
Verbeteringen in de loads en stores
Een moderne x86-processor werkt efficiënt door continu gebruik van L1-cachegeheugen, waarbij data aan de lopende band wordt geplaatst en weer opgehaald. Ook hier borduurt AMD verder op de eigenschappen van Zen 3, waarbij het aantal lees- en schrijfacties per kloktik eveneens uitkomt op drie loads en twee stores. De verbetering zit hier in de grotere loadqueue. Bij Zen 3 werd de storequeue weliswaar vergroot van 48 naar 64 entry's, maar de loadqueue werd met rust gelaten. Met Zen 4 is nu ook de loadqueue 22 procent groter gemaakt, waardoor de capaciteiten van de core zelf beter benut kunnen worden. Om dit mogelijk te maken, en eveneens ruimte te bieden aan de eerder genoemde AVX-512, is de data translation lookaside buffer twee keer zo groot gemaakt en is er 1MB aan L2-cache per core, tegenover 512kB op Zen 3.
/i/2005372040.png?f=imagenormal)
5nm-chips en i/o-die
Met trots presenteerde AMD zijn nieuwe generatie cpu's als de eerste op 5 nanometer geproduceerde desktopprocessors, wat de fabrikant laat uitvoeren bij TSMC. Dit productieprocedé maakt zuinigere transistors mogelijk, die met een lager energiegebruik uit de voeten kunnen en tegelijk geschikt zijn om hoge kloksnelheden te halen. Dat laatste is bij Zen 4 een van de uitgangspunten geweest om hogere prestaties te kunnen bieden. Met de nieuwe AM5-socket en de hogere tdp's komt er ten opzichte van voorgaande generaties meer ruimte vrij om die kloksnelheden zover mogelijk op te schroeven.
AMD geeft zelf aan dat Ryzen 7000-processors ontworpen zijn om bij zware workloads op hoge temperaturen te werken. De fabrikant wijst erop dat temperaturen van 95 graden Celsius in multithreaded workloads geheel volgens de specificatie zijn, en dat de processor ook bij langdurig gebruik op deze temperatuur niet beschadigd wordt. Zoals wij in onze tests ook hebben gezien, is het koelen van een Ryzen 7000-processor tot onder de 90 graden tijdens volle belasting buitengewoon lastig, zelfs met een 280mm-aio-waterkoeler. Wat daarbij niet helpt, is dat de 5nm-chiplets erg klein zijn en dat er dus veel vermogen van een klein oppervlak afgevoerd moet worden. Daarnaast heeft de nieuwe heatspreader dankzij de uitsparingen rondom ook een iets kleiner oppervlak gekregen ten opzichte van voorgaande Ryzen-processors.
/i/2005372066.png?f=imagenormal)
De nieuwe i/o-die
De grootste sprong in productietechniek zit echter niet bij de processorcores, maar bij de i/o-die. AMD stapt voor deze specifieke chiplet over van het grijsgedraaide 12nm-proces bij GlobalFoundries naar het veel modernere 6nm bij TSMC. Dat is uiteraard niet helemaal hetzelfde niveau als de 5nm-chiplets voor de processorcores, maar betekent desondanks een flinke stap vooruit. Volgens AMD vermindert dit niet alleen de afmetingen van de chip, maar biedt de geheel opnieuw ontworpen i/o-die op het kleinere procedé veel meer aansturingsmogelijkheden voor een slim energiebeheer. De desktopprocessors van afgelopen generaties moesten dat missen ten opzichte van hun mobiele tegenhangers. Dit slimmere energiegebruik moet vooral de prestaties bij lager ingestelde tdp's verbeteren. Zo zou de Ryzen 9 7950X bij 65W tot 74 procent beter moeten presteren dan de 5950X, terwijl dat bij 170W een kleinere voorsprong van 35 procent bedraagt.
/i/2005372054.png?f=imagenormal)
De nieuwe i/o-die brengt nog meer verbeteringen met zich mee, die het platform completer maken dan bij vorige generaties het geval was. Dankzij de ingebouwde gpu kan elke Ryzen-processor vanaf nu zonder losse videokaart gebruikt worden, wat voorheen voorbehouden was aan de G-processors. De RDNA 2-architectuur hiervan is bovendien nieuwer dan de Vega-igpu's die we in de afgelopen jaren standaard tegenkwamen. Vloeiend gamen zal er echter niet op gaan, doordat de geïntegreerde graphics uit slechts een dubbele compute-unit bestaan en dus erg beperkt zijn wat rekenkracht betreft. De overige features en mogelijkheden van de nieuwe igpu zijn overigens wel nuttig voor veel gebruikers. Zo kan de chip H.264 en H.265 coderen en decoderen, en daarnaast AV1 decoderen. Wat aansluitingen betreft zijn HDMI 2.1 en DisplayPort 2.0 mogelijk tot in totaal vier stuks voor evenveel beeldschermen in een multimonitor-opstelling.
/i/2005372056.png?f=imagenormal)
In de i/o-die zijn eveneens de geheugencontrollers en verbinding voor de PCI Express-lanes geplaatst. AMD heeft ervoor gekozen om met Ryzen 7000-processors enkel DDR5 te ondersteunen en bij deze eerste generatie komt de officieel ondersteunde snelheid uit op 5200MT/s. Daarbij is ondersteuning voor ecc aanwezig, maar net als bij voorgaande generaties hangt het af van de moederbordfabrikanten of deze hardwarematige foutcorrectie daadwerkelijk gebruikt kan worden. Ook heeft AMD met deze generatie voor het eerst de fclk, de kloksnelheid van het Infinity Fabric, losgekoppeld van de geheugencontroller. Een snellere geheugenkit laat vanaf Ryzen 7000 dus niet automatisch de fclk sneller draaien. In plaats daarvan kan dit vrij worden aangepast. De optimale snelheid ligt volgens AMD op 2000MHz.
Wat PCI Express-lanes betreft zien we met Ryzen 7000 zowel de overstap naar versie 5.0 als de uitbreiding met 4 lanes naar een totaal van 28 lanes. Die combinatie levert AMD een voordeel op tegenover Intel, als we de specificaties vergelijken. Wel moet daarbij worden opgemerkt dat de PCI Express-lanes voor grafische kaarten (het x16-slot) alleen op een moederbord met een Extreme-chipset op versie 5.0 zal werken, waarover op de volgende pagina meer.
/i/2005372092.png?f=imagenormal)
Socket AM5 en nieuwe chipsets
Wellicht de grootste overstap die AMD deze processorgeneratie maakt, is die naar de AM5-socket. Deze socket is ontworpen om compatibiliteit met AM4-koelers te bieden, maar daarbuiten komen we meer verschillen dan overeenkomsten tegen. Zo telt de AM5-socket 1718 pinnen, fors meer dan de 1331 stuks die op AM4-processors aanwezig zijn. Ook is de manier waarop de processor contact maakt met het moederbord veranderd. De pin grid array van AM4, waarbij de pinnetjes op de processor zelf zitten, is ingeruild voor een land grid array bij AM5. Vanaf nu hebben AMD-moederborden dus de pinnetjes op het moederbord zitten, net als bij Intel al jarenlang het geval is.
De AM5-socket is ontworpen om meer vermogen te kunnen leveren. De package power tracking, of ppt, bedraagt 230W, fors meer dan de 142W die op AM4 de limiet is. AMD zegt dit te hebben verhoogd om meer ruimte te bieden voor processors om tot hogere kloksnelheden te kunnen boosten. Volgens de fabrikant zijn de prestaties per watt nog altijd beter dan op voorgaande generaties en zijn deze hogere cijfers vooral als leidraad bedoeld om de juiste koeler uit te kiezen.
Chipsets: X670 en B650 in twee smaken
Dan zijn er nog de nieuwe chipsets waaruit valt te kiezen. AMD trapt AM5 gelijk af met vier stuks: X670E, X670, B650E en B650. Net zoals bij vorige generaties geeft een X-chipset meer mogelijkheden dan de goedkopere B-chipset. Nieuw is dat er nu ook Extreme-varianten van bestaan, die meer aansluitmogelijkheden op PCI-Express 5.0 bieden. Bij X670- en B650-moederborden zijn de lanes voor het x16-slot PCI-Express 4.0; bij de Extreme-chipset is dit versie 5.0. De lanes voor NVMe-drives zijn op beide varianten altijd PCIe 5.0, dus om binnenkort de nieuwste generatie ssd te gebruiken, hoef je niet het luxere Extreme-moederbord aan te schaffen.
De communicatie tussen de processor en de chipset verloopt op alle chipset-varianten via PCIe 4.0 met 4 lanes, net als bij X570 het geval was. Wel is er voor de moederbordfabrikanten veel meer om uit te kiezen wat aansluitmogelijkheden en i/o betreft. Nieuw is de ondersteuning voor 20Gbit/s-USB, maar daarvan kan een exemplaar ook gewisseld worden voor twee 10Gbit/s-USB-aansluitingen. Een aantal andere USB-aansluitingen is niet uit te wisselen voor iets anders. Wel zijn andere PCIe-lanes vanaf de chipset configureerbaar voor SATA, netwerkaansluitingen, bluetooth en nog meer.
| |
B550 |
X570 |
B650 |
X670 |
B650E |
X670E |
| PCI Express uit cpu |
20 PCIe 4.0 |
20 PCIe 4.0 |
24 PCIe (8x 5.0, 16x 4.0) |
24 PCIe (8x 5.0, 16x 4.0) |
24 PCIe 5.0 |
24 PCIe 5.0 |
| PCI Express uit chipset |
10 PCIe 3.0 |
16 PCIe 4.0 |
12 PCIe (8x 4.0, 4x 3.0) |
20 PCIe (12x 4.0, 8x 3.0) |
12 PCIe (8x 4.0, 4x 3.0) |
20 PCIe (12x 4.0, 8x 3.0) |
| USB 20Gbit/s |
0 |
0 |
1* |
2* |
1* |
2* |
| USB 10Gbit/s |
2 |
8 |
4+2* |
8+4* |
4+2* |
8+4* |
| USB 5Gbit/s |
2 |
0 |
0 |
0 |
0 |
0 |
| USB 2.0 |
6 |
4 |
6 |
12 |
6 |
12 |
| SATA |
4 |
4 |
4 |
8 |
4 |
8 |
| Overklokken |
Ja |
Ja |
Ja |
Ja |
Ja |
Ja |
*Aantal beschikbare aansluitingen afhankelijk van keuzes door moederbordfabrikant, zie diagram.
DDR5 en EXPO
AMD heeft ervoor gekozen om de geheugencontroller, die deel uitmaakt van de i/o-die, specifiek te ontwikkelen voor DDR5 en ondersteuning voor DDR4 achterwege te laten. Wil je de overstap maken naar een Ryzen 7000-serie processor vanaf een eerdere AMD-cpu, dan ben je dus genoodzaakt om naast een nieuw moederbord ook nieuw werkgeheugen aan te schaffen. In deze review gaan we niet dieper in op de eigenschappen van DDR5 zelf. Wil je daar meer over lezen, sla er dan ons achtergrondartikel over DDR5-geheugen nog eens op na.
/i/2005372094.png?f=imagenormal)
Met de overstap naar DDR5 maakt AMD van de gelegenheid gebruik om gelijk een nieuwe standaard te introduceren. EXPO, wat staat voor Extended Profiles for Overclocking, kan worden gezien als directe tegenhanger van Intels XMP. Hiermee kan werkgeheugen eenvoudig worden overgeklokt naar snelheden die door de fabrikant van het geheugen zelf worden ondersteund, maar de officieel ondersteunde maximumsnelheid vanuit de processor overstijgen. AMD blijft net als voorheen ook op Ryzen 7000 de XMP-standaard ondersteunen, maar geeft aan dat EXPO-ondersteunende geheugenmodules beter en stabieler zullen functioneren dan wanneer XMP wordt gebruikt. Dat komt doordat er met EXPO beter is aan te sturen op alle secundaire en tertiaire geheugentimings om Ryzen 7000-processors optimaal te laten presteren.
EXPO is verder vrij van licenties en royalty's, en kan daardoor door elke geheugenfabrikant gebruikt worden. Voor elke geheugenkit die EXPO ondersteunt, moet de maker een rapport publiceren waarin niet alleen de volledige timings staan, maar ook welke componenten, zoals geheugenchips, op de modules zijn gebruikt.
/i/2005372090.png?f=imagenormal)
Testverantwoording
Geheugen en videokaart
We geven de mainstreamplatforms 16GB per geheugenkanaal, wat in totaal op 32GB uitkomt voor de geteste systemen. De kloksnelheid van de processors stellen we in op de officiële maximumsnelheid, zoals opgegeven door AMD of Intel. Ook voor de geheugensnelheid houden we de officiële maximaal ondersteunde snelheid aan, wat in het geval van Ryzen 7000-processors DDR5-5200 betekent.
Bij processors met een geïntegreerde gpu draaien we het gros van onze benchmarks zonder extra videokaart, terwijl we cpu's zonder (geactiveerde) igpu combineren met een Nvidia GeForce GTX 1650.
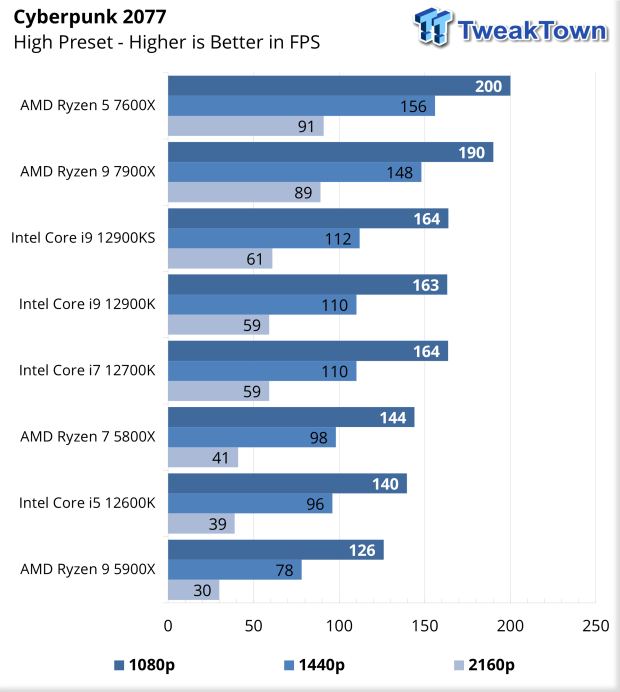
Gametests
Alle gamebenchmarks draaien we in combinatie met een van de snelste videokaarten van dit moment, een AMD Radeon RX 6950 XT. Dat doen we primair in full-hd-resolutie, 1920x1080 pixels, met medium- en ultra-settings. We kiezen juist voor de relatief lage full-hd-resolutie om de cpu waar mogelijk de bottleneck te laten zijn. Dit blijft representatief als er in de toekomst snellere videokaarten verschijnen die het knelpunt naar de processor laten verschuiven. Bij hogere resoluties, zoals 4k, ligt de bottleneck doorgaans volledig bij de videokaart. Wel testen we op verzoek twee games ook op een resolutie van 2560x1440 pixels, om te kijken of er op die resolutie nog verschil is tussen processors.
Stroomverbruik
Uiteraard meten we ook het stroomverbruik van de processors. Onze meetmethode daarvoor is gebaseerd op de stroom die door de EPS- en ATX-kabels naar het moederbord loopt en die we onderscheppen met behulp van Tinkerforge-hardware. Door uitsluitend het vermogen van de processor te meten, geïsoleerd van de rest van het systeem, kunnen we een appels-met-appelsvergelijking maken. Daarbij rapporteren we de mediaan van zowel het verbruik via de EPS-kabels, cpu-only, als het totale verbruik inclusief het moederbord. We noteren het stroomverbruik idle, gemiddeld over vijf minuten, en tijdens drie soorten belasting: tijdens een Cinebench R23-run, multithreaded uiteraard, tijdens het renderen van een video in Adobe Premiere Pro en tijdens een game: Metro Exodus op 1080p-resolutie met ultra-settings.
Welke testgegevens het relevantst zijn voor jou, verschilt naar gelang je gebruiksdoel. Installeer je als gamer bijvoorbeeld toch al een losse videokaart, dan is het vergelijken van alleen het cpu-verbruik de meest logische route. Zou je daarentegen genoeg hebben aan geïntegreerde graphics of moet je cpu's die dat niet hebben, voorzien van een videokaart om beeld te krijgen, dan kan het totale platformverbruik relevanter zijn.
Ipc-test
We trappen af met de ipc-test, waarbij we de ruwe snelheid van de processorarchitectuur in instructions per clock proberen te vangen. Hiertoe stellen we alle processors in op dezelfde kloksnelheid. Vervolgens draaien we de singlethreaded test van Cinebench 15, een van de meestgebruikte processorbenchmarks. Aangezien de test singlethreaded en op een vaste kloksnelheid is, maakt het in principe niet uit op welke cpu binnen een serie je hem draait, zolang de interne opbouw gelijk is.
In Cinebench R20 is AMD met Zen 4 per kloktik 8 procent sneller dan op Zen 3. Die vooruitgang geeft niet automatisch een voorsprong, want Intel is met Alder Lake nog eens 7 procent sneller dan AMD's nieuwste generatie. In Cinebench R15 loopt Zen 4 net iets minder ver voor op Zen 3, maar daar is het vooral Intel dat met de twaalfde generatie opvalt en ver uitloopt.
- Cinebench R20 @ 3.5GHz
- Cinebench R15 @ 2.4GHz
Latency en bandbreedte
Om te meten en vergelijken hoe de latency's en doorvoersnelheden van het werkgeheugen en de verschillende cacheniveaus eruitzien, hebben we AIDA64's Cache & Memory-benchmark gedraaid. Dit hebben we zowel op de Ryzen 9 7950X als op de Core i9 12900K gedaan, op twee configuraties. Allereerst draaiden we de test op officieel ondersteunde geheugensnelheden, dus DDR5-5200 voor AMD en DDR5-4800 voor Intel. Daarnaast hebben we beide platforms met 6000MT/s getest, daarbij gebruikmakend van respectievelijk EXPO en XMP.
Als we kijken naar de leessnelheden van het werkgeheugen, valt op dat AMD achterblijft bij Intel. Zelfs met DDR5-6000 lukt het de 7950X niet om de Alder Lake-chip op DDR5-4800 bij te benen. Hetzelfde geldt voor kopiëren; dat gaat Intel ook beter af. In de schrijffsnelheden komen ze op officiële snelheden gelijk uit, maar bij een gelijke geheugensnelheid wint Intel opnieuw, zij het met een kleinere voorsprong.
In de geheugenlatency's is AMD op officiële snelheid juist in het voordeel, met EXPO en XMP geactiveerd staan de twee met 6000MT/s op gelijke voet. De snelheden en latency's van de verschillende cacheniveaus zijn vrijwel beter op de Ryzen-processor. In de L2-cache en met name in L3 zijn die verschillen best groot; AMD's cachegeheugen werkt veel sneller dan dat van Intel.
| Configuratie |
Test |
Read |
Write |
Copy |
Latency |
AMD Ryzen 9 7950X
(DDR5-5200CL38) |
Memory |
65.367MB/s |
68.017MB/s |
59.650MB/s |
72,5ns |
| L1 cache |
5.262GB/s |
2.708GB/s |
5.321GB/s |
0,7ns |
| L2 cache |
2.665GB/s |
2.555GB/s |
2.567GB/s |
2,5ns |
| L3 cache |
1.599GB/s |
1.360GB/s |
1.391GB/s |
9,4ns |
Intel Core i9 12900K
(DDR5-4800CL36) |
Memory |
77.160MB/s |
68.506MB/s |
69.374MB/s |
79,3ns |
| L1 cache |
4.298GB/s |
3.113GB/s |
5.109GB/s |
1,0ns |
| L2 cache |
1.326GB/s |
542GB/s |
954GB/s |
3,5ns |
| L3 cache |
992GB/s |
462GB/s |
763GB/s |
17,2ns |
AMD Ryzen 9 7950X
(DDR5-6000CL30 EXPO) |
Memory |
75.128MB/s |
77.560MB/s |
69.663MB/s |
63,5ns |
| L1 cache |
5.262GB/s |
2.708GB/s |
5.260GB/s |
0,7ns |
| L2 cache |
2.669GB/s |
2.532GB/s |
2.526GB/s |
2,5ns |
| L3 cache |
1.569GB/s |
1.377GB/s |
1.431GB/s |
9,2ns |
Intel Core i9 12900K
(DDR5-6000CL30 XMP) |
Memory |
92.848MB/s |
82.610MB/s |
84.585MB/s |
64,0ns |
| L1 cache |
4.298GB/s |
3.113GB/s |
4.972GB/s |
1,0ns |
| L2 cache |
1.366GB/s |
541GB/s |
989GB/s |
3,5ns |
| L3 cache |
917GB/s |
494GB/s |
729GB/s |
15,8ns |
Foto- en videobewerking
In Photoshop is de Ryzen 9 7950X het snelst klaar met het uitvoeren van een reeks complexe bewerkingen. De cpu is niet alleen ruim sneller dan zijn voorganger, maar weet ook Intels vlaggenschip te verslaan. De Ryzen 7 7700X zit in dezelfde test ondertussen de 5950X op de hielen en plaatst zich vlak boven de 5900X.
In Premiere Pro meten we rendertijden die lastig te verklaren zijn. De software van Adobe lijkt niet goed te schalen over grote aantallen processorscores, met name op AMD-cpu's. Ook in DaVinci Resolve liggen de resultaten niet voor de hand, maar dit keer zijn het enkel de Ryzen 7000-processors die echt afwijkend scoren. We hebben ervoor gekozen de resultaten hieronder wel te publiceren, maar nemen de twee tests gezien de uitkomsten niet op in de Prestatiescore verderop.
- Adobe Photoshop
- Adobe Premiere Pro
- DaVinci Resolve
Video- en audiocodering
In onze x264-test met StaxRip wordt de vooruitgang van de nieuwe Ryzen-processors ten opzichte van hun voorgangers een beetje ondergesneeuwd door de enorme snelheid waarmee Intels twaalfdegeneratie-Core-processors zich door deze workloads heen bijten. Een ruim 22 punten hogere score voor de 7950X ten opzichte van de 5950X is desondanks geen gek resultaat. Daarna zien we in de x265-test wel AMD's nieuwste topmodel bovenaan eindigen en ook de 7700X plaatst zich tussen oudere Ryzens met veel meer cores.
Waar StaxRip verschillende cores goed weet te benutten, is de FLAC-test primair singlethreaded. Hier komt de nieuwe Zen-core goed tot zijn recht en zien we het nieuwe ontwerp op beide processors overtuigend de leiding nemen.
- StaxRip - x264
- StaxRip - x265
- FLAC - 1 uur WAVE naar FLAC
3d-rendering
Cinebench is de benchmarksoftware die hoort bij de Cinema4D-rendersoftware. Je kunt deze benchmark gratis downloaden en eenvoudig zelf draaien, in zowel single- als multithreaded modus. Mede daardoor is hij uitgegroeid tot een van de populairste cpu-tests.
De singlethreaded benchmark van Cinebench meet de prestaties van een enkele processorcore. Daar zien we dat de nieuwe Zen 4-core gecombineerd met hoge kloksnelheden genoeg is om Intel te snel af te zijn, zij het met een kleine voorsprong. In de multithreaded test domineert de 7950X juist wel; de processor is ruim 51 procent sneller dan de 5950X en weet zelfs de 12900K, voorzien van e-cores, ver achter zich te laten. De 7700X is ondertussen 29 procent sneller dan de 5800X, al blijft de 12700K op zijn beurt nog eens 14 procent sneller.
- Cinebench 23 - Single
- Cinebench 23 - Multi
Ook Blender kan uitstekend gebruikmaken van alle cores die een processor te bieden heeft. De snelle Zen 4-core presteert goed in deze test en op de 7950X zorgt het grote aantal van deze cores voor een gelopen race. Ook de 7700X is fors sneller dan zijn voorganger, maar opnieuw is Intels 12700K nog weer een stapje sneller.
Keyshot Viewer is een stand-alone benchmark waarmee processorprestaties eenvoudig gemeten kunnen worden. Wij draaien de benchmark zonder gpu-acceleratie. In de test komt de 7700X uit op het niveau van een 3900X, een processor met veel meer cores. De 7950X laat alle overige deelnemers ver achter zich en presteert flink beter dan zijn voorganger.
Compute en compile
We compileren de volledige Firefox-browser met behulp van MozillaBuild, aan de hand van de opensourcebroncode. Deze benchmark was in de afgelopen generaties afwisselend in het voordeel van AMD en Intel, en nadat Intel met de komst van Alder Lake AMD wist te evenaren, gaat de 7950X er nu ruimschoots aan voorbij. De 7700X is ondertussen ruim sneller dan de 5800X en kan zich meten met de 12700K.
De reeks AIDA64-tests die we draaien, laat uiteenlopende winsten voor Ryzen 7000 zien. Voorgaande Ryzen-processors hadden al hardwareversnelling voor sommige algoritmen aan boord. Met Zen 4 zijn die verbeterd, maar de tests die er uitspringen, zijn Secure Hash Algorithm (SHA3), Julia en Mandel. Bij die subtests kan AVX-512 worden gebruikt, wat Zen 4 een gigantisch voordeel geeft ten opzichte van de andere processors, die dit niet kunnen gebruiken. Alsof die winst nog niet groot genoeg is, walsen de nieuwe Ryzens er in de raytracingtests nog harder overheen, wat de verbeteringen in de floatingpoint-units nog eens onderstreept.
- Zlib
- AES
- Hash
- SHA3
- Julia
- Mandel
- FP32 RT
- FP64 RT
Webbrowsing en compressie
De browserbenchmark Jetstream 2, die we draaien in Google Chrome, leunt vooral op de singlecoreprestaties. Dat gaat de Zen 4-processors goed af en we zien beide modellen comfortabel de eerste en tweede plek bemachtigen.
In 7-Zip zijn de winsten voor de Ryzen 7000-processors ten opzichte van hun voorgangers minder dramatisch. De 7950X en 7700X presteren enkele procenten beter dan respectievelijk de 5950X en 5800X.
Games: geïntegreerde gpu
Voordat we kijken naar de prestaties met een losse videokaart, draaien we een test met de geïntegreerde gpu. Dat doen we in 3DMark's Night Raid, een synthetische benchmark gericht op igpu's die gebruikmaakt van DirectX 12. Omdat AMD aangeeft dat de ingebouwde grafische chip enkel ontworpen is voor simpele taken, zoals verschillende monitors aansturen en video decoderen, hebben we het testen van losse games op de igpu overgeslagen.
De Graphics Score in Night Raid komt op hetzelfde niveau uit als Intels elfde generatie. De luxere Alder Lake-processors zijn nog wat sneller, maar de echte Ryzen apu's scoren duidelijk het best. Toch stemt deze uitslag hoopvol dat toekomstige apu's op basis van RDNA2 erg krachtig kunnen worden als we in het achterhoofd houden dat onderstaande score van de Ryzen 7000-processors met slechts twee compute-units wordt behaald, tegenover 8 Vega compute-units op de 5700G.
- Night Raid - Graphics
- Night Raid - Totaalscore
- Night Raid - CPU latency
In F1 2022 doen de igpu's op de Ryzen 7000-processors het nog wat beter dan in Night Raid.
- 1920x1080 - Low
- 1920x1080 - Low (99p)
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
Games: Far Cry 6
In Far Cry 6 lukt het de nieuwe Ryzens niet om zich te onderscheiden van de Alder Lake-processors en de 5800X3D. Wel zijn de cpu's duidelijk sneller dan hun voorgangers. Vooral de 7700X presteert significant beter dan de normale 5800X en verslaat nipt de 3D-versie van die cpu.
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
- 1920x1080 - Medium (99.9p)
- 1920x1080 - Ultra
- 1920x1080 - Ultra (99p)
- 1920x1080 - Ultra (99.9p)
Games: F1 2022
Ook in F1 2022 valt te zien dat de Ryzen 7000-processors een behoorlijke verbetering vormen ten opzichte van de voorgaande generatie, met als uitzondering de 5800X3D, die het nog wat beter doet. Op ultra-instellingen nemen de verschillen af en komt Intels Alder Lake bovendien de podiumplaatsen in beslag nemen.
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
- 1920x1080 - Medium (99.9p)
- 1920x1080 - Ultra
- 1920x1080 - Ultra (99p)
- 1920x1080 - Ultra (99.9p)
Games: Metro Exodus
Metro Exodus testen we op zowel 1080p- als 1440p-resolutie. De nieuwe Ryzens kunnen zich meten met de beste modellen van Intel en de snelste voorgangers uit de 5000-serie, maar ook hier bewijst de 5800X3D zich als uitstekende gamingprocessor.
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
- 1920x1080 - Medium (99.9p)
- 1920x1080 - Ultra
- 1920x1080 - Ultra (99p)
- 1920x1080 - Ultra (99.9p)
- 2560x1440 - Medium
- 2560x1440 - Medium (99p)
- 2560x1440 - Medium (99.9p)
- 2560x1440 - Ultra
- 2560x1440 - Ultra (99p)
- 2560x1440 - Ultra (99.9p)
Games: Red Dead Redemption 2
Ook Red Dead Redemption 2 draaien we in beide resoluties. De Ryzen 7000-cpu's zijn in deze game tot 10 procent sneller dan hun directe voorgangers. Voorgaande topmodellen van AMD doen hier niet onder voor het nieuwe Ryzen-duo en tussen de twee meten we in deze game ook amper prestatieverschillen.
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
- 1920x1080 - Medium (99.9p)
- 1920x1080 - Ultra
- 1920x1080 - Ultra (99p)
- 1920x1080 - Ultra (99.9p)
- 2560x1440 - Medium
- 2560x1440 - Medium (99p)
- 2560x1440 - Medium (99.9p)
- 2560x1440 - Ultra
- 2560x1440 - Ultra (99p)
- 2560x1440 - Ultra (99.9p)
Games: Total War: Warhammer III
Tot slot bekijken we de prestaties in Total War: Warhammer III. De 7700X eindigt op medium bovenaan, terwijl de 7950X gelijk met de 5950X uitkomt. Op ultra worden de verschillen nog kleiner en vinden we de nieuwe processors terug tussen de best presterende modellen.
- 1920x1080 - Medium
- 1920x1080 - Medium (99p)
- 1920x1080 - Medium (99.9p)
- 1920x1080 - Ultra
- 1920x1080 - Ultra (99p)
- 1920x1080 - Ultra (99.9p)
Games: streaming
In de streamingtest coderen we een videobestand met de x264-codec, terwijl het spel F1 2021 draait op een vaste snelheid van 60fps, om zo het streamen van gameplay te simuleren. Hiervoor gebruiken we de 'very fast'-kwaliteitsinstelling van de codec, met een bitrate van 6Mbit en een framerate van 60fps. We rapporteren een gemiddelde van drie runs. In feite geeft deze test een indicatie van hoeveel rekenkracht een processor overheeft naast het draaien van een game.
De Ryzen 7000-processors zijn flink sneller in het coderen, zoals we eerder in de review al zagen. Dat zorgt ervoor dat de 7700X en 7950X het flink beter doen dan respectievelijk de 5800X en 5950X. Helemaal meten met Intels topmodellen uit de twaalfde generatie lukt niet, maar de nieuwe Ryzen-processors komen al wel in de buurt.
Prestatiescores
Om de prestaties van processors in één getal te vatten, hebben we op basis van alle benchmarkresultaten een index samengesteld: de Tweakers CPU Prestatiescore. Elke deeltest telt hierin even zwaar mee. Alleen de igpu-benchmarks hebben we weggelaten, omdat lang niet elke processor over geïntegreerde graphics beschikt. Ook hebben we voor deze prestatiescore de resultaten van Premiere Pro en DaVinci Resolve niet meegenomen. De index is door deze opzet een mix van tests die wel en niet schalen met bijvoorbeeld kloksnelheid, cache, aantal cores, smt/hyperthreading en andere factoren. Het is daarmee een realistische afspiegeling van het moderne softwarelandschap.
Ga je je processor primair gebruiken om te gamen? Dan kun je kijken naar de Tweakers CPU Gaming Prestatiescore, in feite hetzelfde concept, maar dan alleen op basis van de gamebenchmarks in combinatie met een losse videokaart.
Tweakers CPU Prestatiescore
In de Tweakers CPU Prestatiescore komt de AMD Ryzen 9 7950X uit op 315 punten, flink meer dan waar de 12900K en 5950X op uitkomen. Deze voorsprong komt voor een aardig deel door de aanzienlijk hogere scores die de Zen 4-processors in de verschillende AIDA64-tests halen. Voor de 7700X betekent dit dan ook dat de cpu gemiddeld genomen vrijwel even snel is als de 5950X, terwijl dat in veel andere tests juist niet het geval is.
Tweakers CPU Gaming Prestatiescore
In games zetten de nieuwe Ryzen 7000-processors hoge scores neer en ze behoren daarmee tot de top. Toch is dit geen nieuw prestatieniveau; de nieuwe chips kunnen zich slechts meten met de beste modellen die al op de markt waren.
Stroomverbruik en efficiëntie
Om je zoveel mogelijk context te bieden, rapporteren we het verbruik via de EPS-kabels (cpu) en via de ATX-kabel (moederbord). Over het algemeen omvat dat laatste verbruik de chipset, het geheugen en waar van toepassing de stroom die de videokaart uit het PCIe-slot trekt, telkens voor zover dat op de 12V-rail gebeurt. Bij sommige platforms wordt een secundaire rail van de processor via de ATX-stekker gevoed, waardoor het interessant wordt om het totale verbruik te bekijken.
Stroomverbruik idle
Het idle verbruik is gecombineerd met het X670E-moederbord relatief gezien niet zo gunstig, maar de meting van enkel de processor laat zien dat AMD wel degelijk een optimaler powermanagement heeft dan op voorgaande generaties processors. De X670E-chipset lijkt een fors onderdeel van de gecombineerde score uit te maken.
- Cpu + moederbord
- Cpu
- ATX 12V
- EPS 12V1
Stroomverbruik allcoreload (Cinebench R23 MT)
Zodra de Ryzen 7000-processors vol aan het werk worden gezet, lusten ze ook aardig wat energie. Met name de Ryzen 9 7950X verbruikt veel, zelfs precies evenveel als onze 12900K als we enkel naar de cpu kijken.
- Cpu + moederbord
- Cpu
- ATX 12V
- EPS 12V1
Stroomverbruik mixed load (Adobe Premiere Pro)
In Premiere Pro eindigt de 7950X niet eens zo gek ver onder de 5950X en scoort hij nagenoeg identiek bij de meting aan de cpu zelf. De 7700X verbruikt ook los nog 10 procent meer dan de 5800X.
- Cpu + moederbord
- Cpu
- ATX 12V
- EPS 12V1
Stroomverbruik gaming (Metro Exodus)
In-game is het stroomverbruik van de nieuwe Ryzens ook hoger dan bij veel 5000-serieprocessors. De 7700X valt daarin nog redelijk in de middenmoot; de 7950X is hier echt de hekkensluiter.
- Cpu + moederbord
- Cpu
- ATX 12V
- EPS 12V1
Efficiëntie
Om te bepalen hoe efficiënt een processor werkt, meten we de totale hoeveelheid energie die hij nodig heeft om de benchmark Cinebench 23 MT af te ronden. Hierbij spelen dus zowel de tijd die de processor nodig heeft, en daarmee de prestaties, als het stroomverbruik een rol.
Ook op de nieuwe generatie zien we dat het topmodel het in deze test beter doet dan de lager gepositioneerde Ryzen 7 7700X. De 7950X komt net onder de 3950X terecht; de 5950X loopt daar nog een stapje op voor.
De efficiëntie in games geeft vaak een ander beeld, want dergelijke software belast doorgaans lang niet alle cores zo zwaar als bijvoorbeeld Cinebench. Om hier wat over te zeggen, delen we het vermogen dat de processor in de game Metro Exodus vraagt, door de behaalde framerate, steeds op 1080p met ultra-settings.
De Ryzen 7000-processors zetten zoals verwacht geen duidelijk betere scores neer dan voorgaande cpu's. De framerates liggen niet hoger, terwijl het verbruik wel wat is toegenomen. Bij de 5800X3D is dat een ander verhaal. Die presteert dankzij zijn 3D-cache uitstekend in spellen en verbruikt door relatief lage kloksnelheden weinig energie.
Volledig systeemverbruik
Voor de volledigheid rapporteren we ook het complete systeemverbruik, gemeten aan het stopcontact.
Temperatuurtest en allcore-turbo
De temperaturen van de processors testen we met een be quiet Dark Rock Pro 4, een van de best presterende luchtkoelers die je kunt kopen. In het luxere segment is hij dan ook een van de populairste koelers in de Pricewatch.
Om te waarborgen dat de geboden koeling altijd identiek is en de temperaturen van verschillende processors dus vergelijkbaar zijn, laten we de ventilators van de koeler altijd op volle snelheid (12V) draaien. De gebruikte belasting is een vijftien minuten durende loop van Cinebench R23 multithreaded. We loggen elke seconde de temperatuur van de cpu-package, de kloksnelheid (effectief de allcoreturbo) en het stroomverbruik, allemaal gebaseerd op de sensors die in de processor zijn verwerkt.
Dat de Ryzen 7000-processors flink heet worden, hadden we al verwacht en AMD's opmerking hierover was dan ook terecht. Toch is het nog even schrikken als we zien dat zelfs de 7700X met zijn acht cores tegen een keiharde thermal limit aanloopt op de Dark Rock Pro 4-koeler. Als je nagaat dat het energiegebruik van de 7700X in deze workload vrijwel gelijk is aan dat van de 3950X, 3900X en 5900X, zoals we ook op de vorige pagina zagen, dan zet dit met onderstaande maximale temperaturen goed in perspectief hoe lastig deze Ryzen 7000-processors te koelen zijn.
- Dark Rock Pro 4 - Max. temperatuur
- Gem. kloksnelheid
- Max. package power
Test met waterkoeling
Naast onze temperatuurtest met de luxe luchtkoeler van be quiet hebben we de Ryzen 9 7950X gedraaid met twee verschillende waterkoelers in de AIDA64-cpu-stresstest. Allereerst is de test gedaan in combinatie met de Kraken X62, een 280mm-aio-waterkoeler. Vervolgens hebben we de processor ook gecombineerd met onze custom-waterkoeling; de Alphacool XT45 480mm-radiator en Alphacool D5-waterpomp, zoals gebruikt wordt op ons gpu-testsysteem.
Ook met onderstaande resultaten zien we opnieuw hoe lastig de Zen 4-desktopprocessors zijn te koelen. Onze 7950X is met de aardig capabele Kraken X62 tegen de 90 graden Celsius, en zelfs met de normaal gesproken overbemeten custom-480mm-waterkoeler krijgen we de processor niet onder de 80 graden tijdens volle belasting. Het verschil in temperatuur lijkt maar marginaal impact te hebben op de behaalde kloksnelheden en ook het opgenomen vermogen verschilt niet wezenlijk in de twee scenario's.
- Temperatuur
- Kloksnelheden
- Package power
Conclusie
Het valt niet te ontkennen dat de processors van de Ryzen 7000-serie technisch veel verbeteringen hebben ten opzichte van hun voorgangers. De i/o-die heeft eindelijk de broodnodige upgrades gekregen, zowel wat productieprocedé als wat features betreft, die het platform echt een stap verder helpen. En als we de communicatie vanuit AMD over socket AM5 tot dusver mogen geloven, zit je met een dergelijk moederbord opnieuw naar lange ondersteuning voor nieuwe generaties processors te kijken, net als bij AM4. Toch is het niet enkel rozengeur en maneschijn.
:strip_exif()/i/2005372068.jpeg?f=imagenormal)
Het AM5-platform
Na jarenlang AM4 moet dit keer zowel een nieuw moederbord als nieuw geheugen worden aangeschaft om een nieuwe generatie Ryzen-processor te kunnen gebruiken. Uiteraard maakt de AM5-socket met een geheel ander ontwerp dan AM4 dat je een nieuw moederbord moet kopen, maar voor het werkgeheugen is dat iets minder makkelijk te verdedigen. AMD heeft er zelf voor gekozen om geen DDR4-ondersteuning te leveren met de Ryzen 7000-serie en beargumenteerde dat het met deze keuze de adoptie van DDR5 juist bespoedigt, doordat een grotere vraag de (verdere) ontwikkeling en betaalbaarheid van de nieuwe geheugenstandaard helpt.
Daar valt wat voor te zeggen, al is duidelijk dat we eind 2022 met een totaal ander AMD te maken hebben dan aan het begin van AM4. De underdogpositie waarin de fabrikant toen verkeerde, is verleden tijd. AMD heeft sindsdien met Ryzen een sterke merknaam opgebouwd, die veel gebruikers inmiddels associëren met hoge prestaties. Lange tijd ging dit gepaard met een relatief scherpe prijs, maar met de nieuwste Ryzens zien de kosten voor een geheel samengesteld systeem er onder de streep heel anders uit.
De Ryzen 9 7950X en Ryzen 7 7700X
Voor de losse processors ligt dat iets anders. De AMD Ryzen 7 7700X en AMD Ryzen 9 7950X zijn in euro's amper duurder dan hun voorgangers en dus wel een stuk geavanceerder. Van de twee geteste modellen is de Ryzen 7 7700X eigenlijk minder imposant, hoewel de processor geen verkeerde prestaties neerzet. Toch is het vlaggenschip, de Ryzen 9 7950X, de processor die hoge ogen gooit. Het grote aantal snelle Zen 4-cores met hoge kloksnelheid zorgt ervoor dat de cpu in redelijk veel workloads uitstekend presteert en in de zeldzame gevallen dat de AVX-512-ondersteuning gebruikt kan worden, gaat de processor er keihard vandoor. Wat dat betreft hoef je niet te rouwen om het einde van Threadripper voor consumenten; de Ryzen 9 7950X is in zekere zin namelijk een hedt-processor.
Als het op gaming aankomt, zijn de Ryzen 7950X en 7700X niet onmiddellijk de overtuigende opties waar je direct voor moet gaan. Dat is opvallend; AMD zelf prijst de processors juist aan als uiterst geschikt voor games. Ook hier kunnen we stellen dat er helemaal niets mis is met de gamingprestaties van de nieuwe generatie, maar dat Intels Alder Lake en AMD's eigen 5800X3D nog interessantere opties zijn als het puur op gaming aankomt. De 5800X3D is met lager geprijsd DDR4-geheugen en een betaalbaarder moederbord minstens zo snel als de nieuwe Ryzens en onder de streep blijft er meer geld over voor de videokaart, nog altijd de meest bepalende factor in een gamingsysteem.
Too hot to handle
AMD's Ryzen 7000-processors worden erg heet onder volle belasting. Dat blijkt uit onze eigen tests en dit is ook wat AMD duidelijk naar de pers heeft gecommuniceerd. De fabrikant lijkt tussen de regels door te zeggen dat voor eindgebruikers de knop om moet: cpu-temperaturen boven de 90 graden zijn niet hoog, maar hartstikke normaal en prima geschikt voor langdurig gebruik. De thermal limit is waar de Ryzen 7950X en 7700X als eerste tegenaan lopen. Met de be quiet Dark Rock Pro 4-koeler is dit al het geval en zelfs met onze grootste waterkoelers komen we niet onder de 80 graden. Dat is een enorm verschil ten opzichte van de Ryzen 5000-generatie. Het wordt zo duidelijk dat de 5nm-chiplets op de nieuwe Ryzen-processors simpelweg te veel vermogen op een te klein oppervlak afgeven om met bestaande koelers goed de warmte te kunnen afvoeren.
AMD heeft er ook voor gekozen om op AM5 meer vermogen beschikbaar te stellen dan het op AM4 deed, allemaal om de kloksnelheden zover mogelijk op te voeren. Dat levert in veel benchmarks de ultieme prestaties die we van de 7950X hebben gezien en dat resultaat is onder de streep wel een flinke winst ten opzichte van de voorgaande generatie.
- AMD Ryzen 9 7950X
- AMD Ryzen 7 7700X


:fill(white):strip_exif()/i/2005322056.jpeg?f=thumblarge)
:fill(white):strip_exif()/i/2005322060.jpeg?f=thumblarge)
/i/2005372142.png?f=imagegallery)
/i/2005372140.png?f=imagegallery)
/i/2005372036.png?f=imagegallery)
/i/2005372038.png?f=imagegallery)
/i/2005372040.png?f=imagegallery)
/i/2005372066.png?f=imagegallery)
/i/2005372054.png?f=imagegallery)
/i/2005372056.png?f=imagegallery)
/i/2005372092.png?f=imagegallery)
:strip_exif()/i/2005372080.jpeg?f=imagegallery)
:strip_exif()/i/2005372082.jpeg?f=imagegallery)
:strip_exif()/i/2005372084.jpeg?f=imagegallery)
:strip_exif()/i/2005372086.jpeg?f=imagegallery)
:strip_exif()/i/2005372088.jpeg?f=imagegallery)
/i/2005372062.png?f=imagegallery)
/i/2005372064.png?f=imagegallery)
/i/2005372094.png?f=imagegallery)
/i/2005372090.png?f=imagegallery)
:fill(white):strip_exif()/i/2005322060.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/2005545994.jpeg?f=thumbmedium)
:strip_icc():strip_exif()/i/2006869184.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004582428.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005916094.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004582430.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005671678.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005586778.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005559510.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005441302.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005416386.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005408332.jpeg?f=fpa_thumb)
/i/2005121912.png?f=fpa)
:strip_exif()/i/2005121904.jpeg?f=fpa)
:strip_exif()/i/2005279580.jpeg?f=fpa)
:strip_icc():strip_exif()/u/164703/images2.jpg?f=community)
/u/314383/crop5dc6a4144d574_cropped.png?f=community)
:strip_icc():strip_exif()/u/466863/crop560dc5c3e12e8_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/64029/crop5b4e6ed3481f4_cropped.jpeg?f=community)
/u/1199540/crop677c3c8f2c048_cropped.png?f=community)
:strip_icc():strip_exif()/u/271437/9fc8308efd68a5895cad297e4bf80e167d660a00_full.jpg?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_icc():strip_exif()/u/338057/10%2520Pin%2520Bowling%2520juiste%2520maat.jpg?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
:strip_icc():strip_exif()/u/1157718/crop5e6d5ebf96a5f_cropped.jpeg?f=community)
:strip_exif()/u/19665/ElfEverQuestTweakersSmall.gif?f=community)
/u/331213/crop56ef13408ff38_cropped.png?f=community)
:strip_icc():strip_exif()/u/12169/crop5f6b926faa837_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/73069/zT-Cad.jpg?f=community)
:strip_exif()/u/609320/crop5b6ae539e2dcd_cropped.gif?f=community)
/u/407459/tw.PNG?f=community)
/u/52587/crop637254f3d1860_cropped.png?f=community)
:strip_icc():strip_exif()/u/263315/crop592fef8caf3e6_cropped.jpeg?f=community)
:strip_exif()/u/427573/butterflyInTheMachine.gif?f=community)
/u/286895/icon1.png?f=community)
:strip_icc():strip_exif()/u/789283/crop65b0dfe4af024_cropped.jpg?f=community)
/u/403512/crop69327050426ec.png?f=community)
:strip_icc():strip_exif()/u/22588/472892.jpg?f=community)
/u/617268/crop58700492a0145_cropped.png?f=community)
:strip_icc():strip_exif()/u/129411/therapieklein1.jpg?f=community)
/u/27299/hoofd.png?f=community)
/u/1233126/crop63614f65924fa_cropped.png?f=community)
:strip_icc():strip_exif()/u/180657/texacoiq2.jpg?f=community)
:strip_icc():strip_exif()/u/21712/crop668d500bcc980_cropped.jpg?f=community)
:strip_exif()/u/130235/balance.gif?f=community)
:strip_icc():strip_exif()/u/846253/crop606c33fb7f7bd_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/109773/ziltoid_fetid_70px.jpg?f=community)
:strip_icc():strip_exif()/u/433754/crop5ce27ff853c70_cropped.jpeg?f=community)
:strip_exif()/u/467778/crop5d7a5dd1f296a.gif?f=community)
:strip_icc():strip_exif()/u/324515/crop627103b05ba2e_cropped.jpg?f=community)
/u/577935/crop5cba3792108de.png?f=community)
:strip_icc():strip_exif()/u/397908/crop5a8183633ae3b_cropped.jpeg?f=community)
/u/1820372/crop6315cf985f21d_cropped.png?f=community)
/u/946619/crop61e32cdbe8065_cropped.png?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/912957/crop5f16acacac354_cropped.png?f=community)
/u/180271/av.png?f=community)
:strip_icc():strip_exif()/u/350783/crop62ff797f3eccf_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/1044469/crop609531313c7c0_cropped.jpg?f=community)
/u/375324/crop5d95a2d427d1d_cropped.png?f=community)
:strip_exif()/u/57212/a.gif?f=community)
{kind=link}
{kind=link}