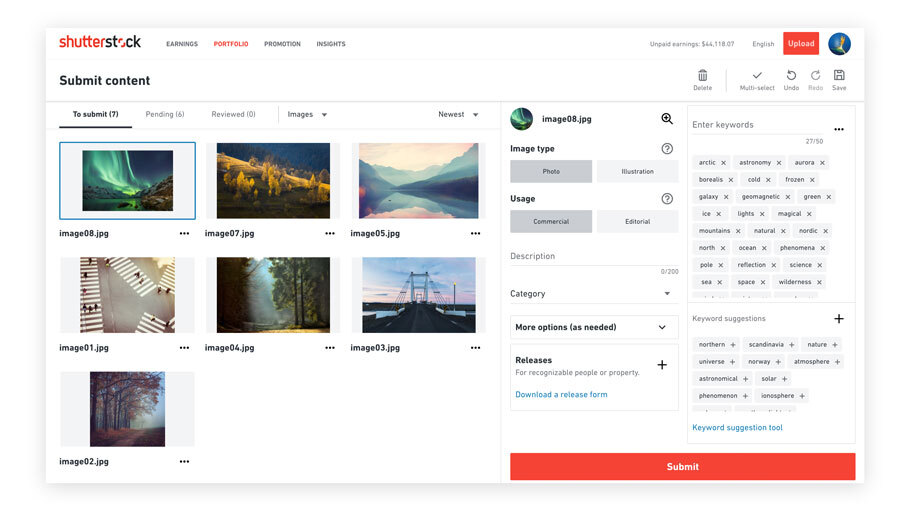
Verschillende Amerikaanse techbedrijven zouden een deal met Shutterstock hebben gesloten wat betreft het gebruik van media voor het trainen van AI-modellen. Amazon, Apple, Google en Meta zouden bij de groep horen en deals van minstens 25 miljoen dollar hebben gesloten.
Volgens persagentschap Reuters zijn de overeenkomsten tussen stockfotoplatform Shutterstock en de Amerikaanse techbedrijven eind 2022 afgesloten. De techbedrijven, waaronder Amazon, Apple, Google en Meta, zouden dankzij de overeenkomsten toegang hebben gekregen tot honderden miljoenen beelden van Shutterstock, maar ook tot video- en muziekbestanden van het platform. Aanvankelijk werden er bedragen tussen de 25 en 50 miljoen dollar op tafel gelegd voor de licentieovereenkomsten, maar deze deals zouden later zijn uitgebreid. De chief financial officer van Shutterstock zei tegen Reuters dat er ondertussen ook overeenkomsten met kleinere bedrijven zijn afgesloten. Dat gebeurde volgens het kaderlid tijdens de afgelopen paar maanden.
Reuters kon ook met de ceo van Freepik spreken: een concurrent van Shutterstock. Het kaderlid vertelde dat Freepik momenteel overeenkomsten heeft lopen met twee grote techbedrijven. Het is niet duidelijk om welke bedrijven het gaat. Het archief van Freepik bevat naar verluidt ongeveer 200 miljoen foto’s en de toegang tot elk beeld zou 2 tot 4 Amerikaanse cent kosten. Freepik stelt dat er nog een vijftal soortgelijke deals met techbedrijven in de maak zijn.
Shutterstock heeft eind 2022 aangekondigd dat het ging samenwerken met OpenAI. Het stockfotoplatform heeft OpenAI toen toegang gegeven tot zijn bibliotheek met miljoenen foto’s, afbeeldingen, video’s en muziekbestanden, inclusief metadata. Het bedrijf kreeg in ruil toegang tot de nieuwste AI-tools van OpenAI en kon diverse AI-tools integreren op zijn platform waardoor het voor klanten bijvoorbeeld eenvoudiger werd om stockafbeeldingen via kunstmatige intelligentie aan te passen. In de zomer van 2023 werd de samenwerking tussen Shutterstock en OpenAI verlengd met zes jaar.

:strip_exif()/i/2005345144.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/i/2004767618.png?f=fpa)
:strip_exif()/i/2006855932.jpeg?f=fpa)
/i/2004629064.png?f=fpa)
/i/1229700069.png?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
/i/2004618424.png?f=fpa)
/i/1197992055.png?f=fpa)
:strip_exif()/i/2006492806.jpeg?f=fpa)
/i/2005046258.png?f=fpa)
/i/2004919460.png?f=fpa)
/u/93853/lostworld_thumb_small.JPG?f=community)
/u/204872/crop65a1d5f52b87f.png?f=community)
/u/272509/60x60-Project.png?f=community)
:strip_icc():strip_exif()/u/88719/crop624ccd84437db_cropped.jpg?f=community)
:strip_exif()/u/1650466/crop6215360d3031f_cropped.gif?f=community)
:strip_icc():strip_exif()/u/144633/crop643e593ea432f_cropped.jpg?f=community)
/u/10248/phoenix.png?f=community)
/u/47542/crop5835c0be871d0_cropped.png?f=community)
:strip_icc():strip_exif()/u/563985/crop699314aceefef_cropped.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_icc():strip_exif()/u/279088/crop609fca601663b.jpg?f=community)