De NOS vermoedt dat OpenAI en Midjourney beelden van Nederlandse makers hebben gebruikt om AI-modellen te trainen. De publieke omroep komt tot die conclusie na eigen onderzoek. Volgens de NOS hebben de techbedrijven mogelijk inbreuk gepleegd op het auteursrecht.
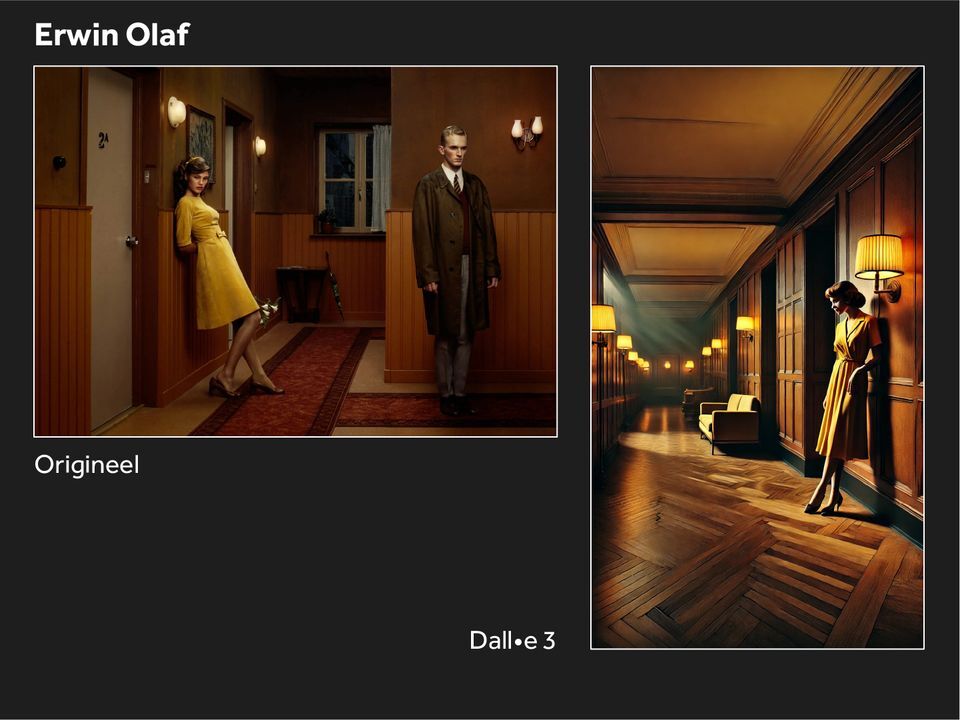
De redactie van de NOS heeft aan de beeldgeneratoren van de bovenvermelde techbedrijven gevraagd om plaatjes te genereren in de stijl van enkele bekende Nederlandse beeldenmakers zoals Erwin Olaf, Eddy van Wessel en Dick Bruna. Het is niet duidelijk welke prompts de redactie heeft gebruikt. Uit de verslaggeving blijkt dat er enkel is gevraagd om de stijl van deze makers na te bootsen, zonder specifieke verdere aanwijzingen.
De beeldgeneratoren zouden vervolgens beelden hebben voortgebracht met daarin ‘telkens karakteristieke eigenschappen’ van de bekende werken van de makers. In het geval van Erwin Olaf werden er bijvoorbeeld plaatjes gegenereerd met vrouwen in een gele jurk. Dat was een van de stijlkenmerken van de Nederlandse fotograaf. Bij Eddy van Wessel werden er zwart-witafbeeldingen gemaakt in een oorlogsgebied. Dat is opnieuw typerend voor de maker.
De redactie van de NOS ging met zijn bevindingen te rade bij vier AI-experts. Deze experts konden niet met 100 procent zekerheid zeggen dat de AI-modellen zijn getraind op de werken van de Nederlandse makers, maar stelden volgens de NOS wel dat het er ‘zeer sterk’ op lijkt.
De NOS klopte daarna aan bij een advocaat intellectueel eigendomsrecht. Die stelde dat als werken beschermd zijn, en iemand ermee aan de haal gaat, een schending van het auteursrecht vrij snel wordt aangenomen. Er zou wel een uitzondering bestaan voor het verzamelen van openbare gegevens uit wetenschappelijke instellingen. Commerciële partijen zouden hier ook gebruik van kunnen maken, zolang de rechthebbenden geen expliciet bezwaar hebben gemaakt tegen deze praktijk. Dat is volgens de NOS de opt-outclausule. Bij de werken van Dick Bruna en Eddy van Wessel is er gebruikgemaakt van zo’n opt-out. Bij de werken van Erwin Olaf is dat niet het geval.

/i/2005692496.png?f=fpa)
:fill(white):strip_exif()/i/2007543392.jpeg?f=fpa)
:strip_exif()/i/2007372856.jpeg?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
:strip_exif()/i/2005344592.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/i/2004767618.png?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/1229700069.png?f=fpa)
/i/2006611966.png?f=fpa)
/i/2004629064.png?f=fpa)
:strip_exif()/i/2006492806.jpeg?f=fpa)
:strip_icc():strip_exif()/u/14/wildhagen60x60.jpg?f=community)
/u/2089840/crop65d8bf7c41e1f_cropped.png?f=community)
:strip_icc():strip_exif()/u/1759306/crop66a5f1ae04a5c.jpg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/637028/crop6a3e22601b0f7_cropped.jpg?f=community)
/u/627287/crop5f8ef98351ddc_cropped.png?f=community)
/u/88794/dj_henk4b.png?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
/u/58518/crop55c9fb6f4244f_cropped.png?f=community)
/u/1355926/crop5f62118b50c6a_cropped.png?f=community)
/u/23785/crop5dcd5c59e07f9.png?f=community)
:strip_exif()/u/219668/crop6818d9983dc68_cropped.webp?f=community)
:strip_exif()/u/441804/crop565635b1553e3_cropped.gif?f=community)
:strip_exif()/u/38542/Scrat1ani.gif?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
/u/143137/crop5d1c4f96268ca_cropped.png?f=community)
/u/122874/crop5e26d7a209cd1_cropped.png?f=community)
:strip_icc():strip_exif()/u/233767/crop5db03cbc075aa.jpeg?f=community)
:strip_icc():strip_exif()/u/33880/crop5ec3d2d5f2541_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/227665/th_petey_rawrs.jpg?f=community)
/u/509758/crop5f996ff2e7378_cropped.png?f=community)
:strip_icc():strip_exif()/u/99162/crop5fbeb65712858_cropped.jpeg?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
:strip_icc():strip_exif()/u/94045/crop66c1b4250e8a2_cropped.jpg?f=community)
/u/314383/crop5dc6a4144d574_cropped.png?f=community)
:strip_icc():strip_exif()/u/503110/crop61892c383239e_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/93936/achtsubm.jpg?f=community)