Aan Intels E-core zijn we al een paar generaties gewend, maar terwijl je dit leest lepelt ook AMD de eerste extra zuinige en compacte cores in enkele van zijn consumentenprocessors. Hoe verhouden de E-cores van Intel en de nieuwe Zen 4c-cores van AMD zich tot elkaar?
Na Intel komt nu ook AMD met extra zuinige cores
Intel ontwierp al sinds mensenheugenis twee verschillende soorten cores. Aan de ene kant had je de grote, prestatiegerichte cores die je in de Core i3/i5/i7/i9-processors tegenkwam en die we ter onderscheid P-cores zijn gaan noemen. Aan de andere kant stonden de kleine, zuinige cores die ooit in Atoms werden gebruikt en tegenwoordig vooral in mobiele Celerons en Pentiums zaten, en die Intel een paar jaar geleden tot E-cores heeft gedoopt.
Bij Alder Lake, de twaalfde generatie Core, combineerde Intel die twee soorten cores voor het eerst in een massaproduct. Vanaf de Core i5 12600K beschikten processors over een combinatie van P- en E-cores. In de daaropvolgende generaties breidde Intel het aantal modellen met E-cores steeds verder uit, en ook in laptops kom je ze nu vaak tegen. Een op zuinigheid gefocuste chip als de Core i7-1365U heeft bijvoorbeeld zelfs maar twee normale P-cores en maar liefst acht zuinige E-cores.
Intel-processors bestaan nu al enkele generaties uit een combinatie van P- en E-cores.
Al gauw liet AMD doorschemeren ook wel iets te zien in zo'n hybrideprocessorarchitectuur. Als zuinige core zet het Zen 4c in, een kleinere versie van zijn reguliere Zen 4-core die oorspronkelijk werd ontwikkeld voor Epyc-serverprocessors met extreem veel cores. Vorige maand kondigde AMD de eerste laptopchips met Zen 4c-cores aan, die we vermoedelijk ook terug gaan zien in de Ryzen 8000G-apu's voor desktops.
Ander doel dan bij smartphones
Smartphones bevatten al veel langer verschillende soorten cores.
De techniek om kleine en grote cores te combineren vindt zijn oorsprong in smartphones. Arm-socs bestaan al veel langer uit combinaties van twee of soms zelfs drie soorten cores. Het belangrijkste doel van de diverse cores is vooral de 'race to idle'. Voor een lange accuduur moet de processor van een smartphone zoveel mogelijk grotendeels uitgeschakeld zijn. Eén of enkele grote, snelle cores kunnen piekprestaties leveren om een taak zo gauw mogelijk af te ronden, om daarna direct weer in stand-by te gaan en minder zware taken over te laten aan zuinigere cores.
Bij x86-processors en zeker bij desktopmodellen speelt dat niet zo. Het gaat AMD en Intel er vooral om zo hoog mogelijke prestaties te kunnen behalen in de toegestane hoeveelheid vermogen en hitte. Veel cores die per stuk wat langzamer zijn, kunnen dat 'budget' efficiënter benutten dan een kleiner aantal hoger geklokte cores. Hoewel vooral Intel daar nog wel wat aandacht aan schenkt, is een laag idleverbruik veel minder een focus dan bij smartphonesocs.
Grote verschillen tussen kleine cores
We kunnen in ieder geval stellen dat AMD en Intel ieder een ander pad hebben gekozen om in essentie hetzelfde probleem op te lossen. Wat die verschillen precies inhouden en of een van de twee concepten de betere is, onderzoeken we in dit artikel.
Intels E-core
We beginnen met het nader bekijken van Intels Efficient-core, die al sinds het einde van 2021 in allerlei desktop- en laptopprocessors van het blauwe kamp wordt gebruikt. Tot nu toe is dat in feite steeds dezelfde, namelijk de E-core die schuilgaat onder de codenaam Gracemont. Gracemont is een verre afstammeling van de simpele cores die Intel rond 2010 gebruikte voor energiezuinige netbook-cpu's, bekend van de Atom-serie, en die uiteindelijk voortkwamen uit de Pentium M-serie (2003).
Een ASUS Eee PC, een van de bekendste netbooks
Na het verdwijnen van de netbook, een kleine en goedkope laptop, voor wie dat niet heeft meegemaakt, bleef Intel dit type cores doorontwikkelen. Deze cores speelden bijvoorbeeld een rol in de goedkoopste Celeron- en Pentium-chips voor laptops. Die werden op hun beurt ook wel eens in mediacenterachtige mini-pc's gebruikt, waardoor je ze als tweaker misschien nog tegen bent gekomen, ondanks dat je voor een nieuwe laptop niet in het budgetschap shopt. En dan slaan we voor het gemak maar even over dat Intel de relatief zuinige en simpele cores ook wilde gaan gebruiken in zijn gefaalde project om smartphonesocs te gaan maken.
De eenvoudige E-core werd steeds geavanceerder
Toen Intel dit type core in het begin van dit millennium bedacht, waren de belangrijkste doelen dat de core simpel, zuinig en goedkoop zou worden. Met de Pentium 4 had de fabrikant toen immers een core ontwikkeld die op elk van die vlakken een tegenpool was. Ondersteuning voor 64bit-instructies werd bijvoorbeeld weggelaten, net als allerlei trucs die moderne processors gebruiken om sneller te werken, zoals instruction reordering en speculative execution.
In de loop van de ontwikkeling van de Atom-core werd hij steeds wat geavanceerder. Er werd ondersteuning voor de x86-64-instructiesetarchitectuur toegevoegd, maar bijvoorbeeld ook hardwareversnelling voor cryptografiealgoritmes ingebouwd. Bij Silvermont (2013) werd out-of-order execution toegevoegd, waardoor de core instructies in een efficiëntere volgorde kan uitvoeren dan hoe de software ze aanreikt. Goldmont (2014) bracht de mogelijkheid om drie instructies per kloktik te decoderen; bij Tremont (2020) werd dat nog eens verdubbeld.
Featureparity bij Alder Lake
Zo komen we op het punt dat Intel bij Gracemont, de kern die we kennen als de E-core van Alder Lake en Raptor Lake, alleen nog ondersteuning voor AVX- en FMA3-instructies toe hoefde te voegen om featureparity met de reguliere 'Core-cores' te bereiken, die Intel om hem te onderscheiden van de Efficient-core tenslotte Performance-core is gaan noemen. Diefeatureparity was nodig omdat besturingssystemen niet kunnen omgaan met verschillende mate van ondersteuning voor isa-extensies per core. Overigens heeft de Performance-core van Alder Lake, Golden Cove, ook een extensie moeten inleveren om dit doel te bereiken: AVX512 wordt met ingang van die generatie niet langer ondersteund op Intels consumentenprocessors.
Een schematisch overzicht van de Intel Gracemont-core
Hetzelfde antwoord met een andere methode
Hoewel Gracemont nu hetzelfde kan als een reguliere core, is de manier waarop het antwoord op een instructie tot stand komt, nog altijd verschillend. Kort samengevat ademt het interne ontwerp van de E-core in vergelijking met dat van de P-core nog altijd eenvoud en daarmee efficiëntie. De E-core heeft bijvoorbeeld geen hyperthreading en geen micro-opcache, waarmee een van de drie manieren waarop een micro-op bij een P-core in de queue terecht kan komen, geheel ontbreekt. In de backend is het ontwerp van E-cores veel breder, wat betekent dat er meer executionports zijn dan bij een P-core, maar per stuk kunnen die ports dan weer veel minder verschillende taken uitvoeren dan bij de P-cores het geval is. Wil je alles weten over hoe de microarchitectuur van Gracemont precies werkt, lees dan de pagina daarover in onze Alder Lake-review nog eens terug.
E-core versus P-core
De praktische uitwerking daarvan is dat de Gracemont-cores een stuk kleiner zijn. Het is lastig om een directe vergelijking met de Performance-core te maken, omdat de E-cores per vier verpakt zitten in combinatie met een gedeelde L2-cache van 4MB. Bij de P-cores heeft iedere core een losse L2-cache van 2MB. Volgens de metingen die de bekende cpu-analyticus Locuza uitvoerde voor SemiAnalysis, is een losse Gracemont-core 1,6mm² groot en een compleet cluster inclusief cache 8,3mm² groot. Een complete Golden Cove-core inclusief L2-cache is 7,5mm² groot. Je kunt dus stellen dat er ruwweg vier E-cores op de plaats van één P-core passen.
Vanzelfsprekend zijn de E-cores langzamer dan de P-cores. In de eerste plaats omdat ze simpelweg lager geklokt zijn en in de tweede plaats omdat ze minder instructies per kloktik kunnen verwerken, oftewel een lagere ipc hebben. Voor een artikel over de Windows 11-scheduler hebben we eens uitgezocht welk deel van de cores van een Core i7-12700K-processor (8P+4E) verantwoordelijk was voor welk deel van de prestaties. Daaruit bleek dat een P-core bij die processor goed was voor ruim 2400 punten, terwijl een E-core 950 punten opleverde. Een P-core levert dus tweeënhalf keer zoveel prestaties, maar neemt zoals we net zagen vier keer zoveel fysieke ruimte in op de chip.
Cinebench R23 - MT op Intel Core i7-12700K (8P+4E)
Totaalscore
Score P-cores
Score per P-cores
Score E-cores
Score per E-core
22619
19264
2408
3799
950
AMD's Zen 4c
Toen we net gewend waren geraakt aan Intels E-cores, kondigde AMD voorzichtig de komst van Zen 4c aan, met de c van compact. Dat is in elk geval een gelijkenis tussen de 'zuinige' cores van beide fabrikanten, want elke andere gelegenheid grijpt AMD aan om te benadrukken dat ze radicaal anders zijn.
Type core
Grootte
Zen 4 met L2-cache
3,84mm²
Zen 4c met L2-cache
2,48mm²
Waar Intels E-core een ander soort core is, met een afwijkende interne werking, is Zen 4c kortgezegd een reguliere Zen 4-core die te heet gewassen is. Het aantal rekeneenheden in de processor en de manier waarop die met elkaar communiceren, is identiek aan de Zen 4-cores die we kennen sinds de introductie van de Ryzen 7000-serie. De ipc is gelijk en ze kunnen allebei smt gebruiken.
Als je gaat inzoomen, kom je nog enkele verschillen tussen de Zen 4 en 4c tegen. Zo heeft AMD de through-silicon via's om 3D V-Cache-chiplets aan te sluiten achterwege gelaten: die zitten normaal gesproken in álle desktopchiplets, waardoor AMD exact dezelfde chipjes kan gebruiken voor een Ryzen 7 7800X3D als voor een reguliere 7700X. Ook gebruikt AMD een compacter referentieontwerp van TSMC voor de sram-geheugencellen die op diverse plekken in de core zitten.
Alle cpu's met Zen 4c-cores die tot nu toe zijn uitgekomen, hebben daarnaast de helft minder gedeelde L3-cache. Die zit buiten de cores zelf, en in het verleden bracht AMD ook regelmatig chips met minder L3-cache op de markt, zoals processors voor laptops en de daarvan afgeleide Ryzen 5000G-apu's voor desktops.
Zen 4c is vrijwel identiek aan Zen 4, maar klokt lager
Dat Zen 4c letterlijk een verkleinde versie van Zen 4 is, klinkt bijna te simpel. Als die Zen 4-core zoveel kleiner kon, waarom heeft AMD dat dan niet ook bij de reguliere varianten gedaan? Een kleinere chip is goedkoper om te maken en heeft ook nog eens een hogere efficiëntie, omdat de interne stroompaden korter zijn en dus minder verlies kennen.
De crux zit 'm in de kloksnelheden. Doordat alle onderdelen in de processor dichter op elkaar zitten, wordt de geproduceerde hitte over een minder grote oppervlakte verspreid en is er minder 'headroom' voor hoge klokfrequenties. Effectief kunnen de Zen 4c-cores werken op een snelheid rond de 3GHz, terwijl een goed gelukte grote Zen 4-core tot boven de 5,5GHz kan klokken.
Not all cores are created equal
De eerste processors met Zen 4c-cores waren Epyc-chips voor servers, maar inmiddels gebruikt AMD ze ook in specifieke varianten van zijn Ryzen 7040U-processors voor laptops. In eerste instantie deed de fabrikant daar behoorlijk vaag over. AMD telde de hoeveelheid Zen 4- en 4c-cores simpelweg bij elkaar op. Nadat diverse journalisten daar kritiek op uitten, geeft AMD inmiddels aan welke combinaties van cores er worden gebruikt in zijn productdatabase. De Ryzen 3 7440U is bijvoorbeeld een quadcore met drie Zen 4c-cores en één grote Zen 4-core.
In zijn marketingslides kondigde AMD de Ryzen 3 7440U aan als een '4-core'. In feite gaat het om een processor met 1x Zen 4 en 3x Zen 4c.
Wie niet in AMD's productdatabase, het equivalent van Intels Ark-database, rondneust, zal diezelfde processor al gauw platgeslagen zien worden tot 'een quadcore met een maximale boostklok van 4,7GHz'. Nu is het op zich niet ongebruikelijk dat slechts één of enkele cores die maximale kloksnelheid kunnen bereiken en de kloksnelheden bij gelijktijdige belasting van alle cores lager liggen door beperkingen in de stroomtoevoer en koeling. Maar in het geval van bijvoorbeeld de aangehaalde Ryzen 3 is het verschil tussen één core die 4,7GHz kan en drie cores die niet hoger klokken dan ongeveer 3GHz, erg groot. Dat heeft in dit geval niets te maken met koeling of voeding die niet voldoet, maar is een ingebouwde limiet van het type cores.
Vergelijking
Op de vorige pagina's zijn we al dieper in de werking van Intels E-cores en AMD's Zen4c-cores gedoken; daaruit bleek dat ze een heel andere herkomst hebben.
Formaat
Toch hebben AMD's Zen 4c-cores en Intels E-cores een belangrijke overeenkomst: ze zijn een stuk kleiner dan de reguliere cores van beide fabrikanten. De grootte per vier stuks is bij Intel met 8,3mm² wat kleiner dan de 9,9mm² bij AMD. Bij Intel passen er ongeveer vier E-cores in de oppervlakte van een P-core. Bij AMD is dat verschil kleiner: een Zen 4c-core is 35 procent kleiner dan een normale Zen 4-core. Dat komt doordat de normale Zen 4-cores van AMD een stuk kleiner zijn dan de P-cores van Intel.
Prestaties
Wat prestaties betreft, lijkt AMD een duidelijk voordeel te hebben. Een E-core van Intel kan ongeveer half zoveel rekenkracht leveren als een P-core bij een gelijke kloksnelheid. Bij AMD zijn de prestaties per kloktik juist identiek tussen de Zen 4 en Zen 4c. Dat verschil wordt deels gecompenseerd doordat de Intel-cores hoger kunnen klokken. Afhankelijk van het model kunnen die werken op maximaal 4,4GHz, terwijl de Zen 4c-cores blijven steken rond de 3GHz. Als je daarvoor compenseert en bedenkt dat een Golden Cove-core sowieso een procent of zeven rapper is dan een Zen 4-core, levert een Intel E-core tegen de tachtig procent van de prestaties van een Zen 4c-core.
Andere verschillen zijn dat Intels E-cores geen ondersteuning bieden voor AVX512-instructies, net zo min als de P-cores trouwens, en dat ze geen HyperThreading ondersteunen. Zen 4c ondersteunt wel AVX512 en smt.
Intel E-core
AMD Zen 4c
Instructies per kloktik
+- 50% van Golden Cove
Identiek aan Zen 4
Kloksnelheid
Max. 4,4GHz
+- 3GHz
SMT / HyperThreading
Nee
Ja
Formaat per 4 cores
8,3mm² (Intel 7)
9,9mm² (TSMC N5)
L2-cache per 4 cores
4MB
4MB
Wel of geen scheduleraanpassingen?
Intels E-core heeft een geheel andere microarchitectuur dan zijn P-core, met andere sterktes en zwaktes. Daarom is niet altijd van tevoren bekend welk type core het geschiktst is om een bepaalde softwarethread te draaien. Om feedback daarover aan de scheduler van het besturingssysteem te geven, die bepaalt welk proces op welke core draait, heeft Intel voorafgaand aan de release van zijn eerste hybrideprocessors samen met Microsoft de scheduler van Windows 11 geoptimaliseerd. Aan de hand van allerlei factoren, waaronder een hardwarematig feedbackcircuit dat Thread Director wordt genoemd, wordt dynamisch bepaald welke cores het geschiktst zijn om een thread te draaien. Hoe dat allemaal precies werkt, zetten we eerder al eens uiteen.
Omdat Zen 4 en Zen 4c zo op elkaar lijken, zijn er volgens AMD geen aanpassingen nodig aan de scheduler van het besturingssysteem. De scheduler prefereert namelijk al automatisch cores die hoger kunnen klokken: dat zijn dus de grote Zen 4-cores. Maar wat de scheduler niet weet, is dat de Zen 4c-cores efficiënter zijn bij lage belastingen. Als er weinig te doen is en het OS maar één of een paar cores wakker hoeft te houden, zal het dat dus bij willekeurige cores doen, terwijl het in theorie efficiënter was geweest om in dat geval als eerste de grote cores uit te schakelen.
Conclusie
Nu AMD en Intel allebei twee soorten cores kunnen toepassen in hun processors, was het hoog tijd om ze eens met elkaar te vergelijken. Voor wat van een afstandje ongeveer hetzelfde concept lijkt, hebben ze opvallend veel meer verschillen dan overeenkomsten.
Hetzelfde doel, maar andere middelen
Ze zijn dan wel allebei compact en hebben een hogere efficiëntie als doel, maar hoe AMD en Intel aan hun compacte cores komen, is totaal verschillend. De E-cores van Intel zijn een doorontwikkeling van wat ooit de Atom-core was, en werken vanbinnen anders dan de reguliere P-cores. AMD heeft simpelweg zijn Zen 4-core wat kleiner gemaakt, waardoor de maximaal haalbare kloksnelheden omlaaggaan, maar de werking en functionaliteit identiek blijven. Zelfs gecompenseerd voor de lagere kloksnelheid blijven de Zen 4c-cores dan ook ruim sneller dan Intels E-cores. Ze zijn wel wat groter, voor zover dat beeld niet vertroebeld wordt doordat AMD en Intel een ander procedé gebruiken.
Transparantie is gewenst
Bij de aankondiging van de eerste consumentenprocessors met Zen 4c-cores, zoals de Ryzen 5 7545U, draafde AMD zelfs zo ver door in zijn 'Zen 4 en Zen 4c zijn identiek'-verhaal dat het de cores gemakshalve bij elkaar optelde. Hoewel de cores in theorie gelijk zijn, vind ik dat toch een brug te ver. Het maximale prestatieniveau van een Zen 4c-core ligt door de lagere kloksnelheid immers een stuk lager. Het zou AMD sieren als het daar transparanter over wordt en bijvoorbeeld net als Intel de maximale kloksnelheid per type core gaat vermelden.
Is er een winnaar?
Is een van beide soorten zuinige cores nu beter dan de andere? Wat mij betreft niet. AMD en Intel kiezen een andere aanpak voor hetzelfde probleem. Intels aanpak met fijnmazige scheduling, waarbij taken ook bewust op de zuinigere cores worden geplaatst, zou je eleganter kunnen noemen. AMD's aanpak is wat ruwer en haalt wellicht niet de maximale efficiëntie uit het hybrideconcept, maar die eenvoud zorgt er ook voor dat softwareaanpassingen niet nodig zijn en er geen eerder wel ondersteunde instructies hoefden te worden uitgeschakeld om featureparity te bereiken, zoals AVX512 bij Intel.
Cpu's met E-cores van Intel zijn al de nodige tijd verkrijgbaar voor laptops en desktops. AMD past zijn Zen 4c-cores nu toe in een handvol laptopchips, maar het is waarschijnlijk dat ook de Ryzen 8000G-apu's voor desktops voor een deel Zen 4c-cores zullen krijgen. Die komen in het eerste kwartaal van 2024 uit.
@Tomas Hochstenbach bij het stukje over out-of-order (OoO) execution van Intels E-cores beschrijf je de werking verkeerd.
Bij Silvermont (2013) werd out-of-order execution toegevoegd, waardoor de core door kan gaan met andere instructies, terwijl hij op gegevens wacht.
Bij OoO execution optimaliseert de processor op hardware niveau de instructies, om niet te lang moeten wachten op het resultaat van een instructie. Een (theoretisch) voorbeeld is:
b = a + b; // deze instructie duur 1 cycle
c = b * a; // deze instructie duur 2 cycles
d = a / 3; // deze instructie duurt 4 cycles
Totale duur van dit stukje software is 7 cycles. Echter het resultaat van d is onafhankelijk van de berekening in d en gebruikt een ander deel van de processor (namelijk de adder, multiplier en division unit). Wat OoO doet, is kijken (helemaal hardwarematig) of hij software kan optimaliseren. In dit geval zal de OoO unit, eerst de deling doen, dan terwijl de deling bezig is de optelling en vermenigvuldiging doen. In dat geval is de CPU in 4 cycles (ipv 7) klaar. Een flinke winst, maar dit kost je wel veel hardware en dus power.
Wat jij beschrijft is Simultaneous Multi Threading (SMT ook wel bekend als hyperthreading). Daar ben je stukje software A en stukje software B. Stukje software A draait, moet wat data laden en heeft een cache mis. Dit moet uit het geheugen komen, wat zomaar 30-50 cycles kan duren, nu kan de processor wachten, maar hij kan die 30-50 cycles ook stukje software B uitvoeren, die wel al in cache stond geladen. Dit is volgens mij wat jij beschrijft.
Overigens kost SMT een hoop hardware om te kunnen doen. Aan 1 kant moeten bijna alle registers in een processor dubbel worden uitgevoerd, daarnaast moet je cache groot genoeg zijn om zowel software A als B in te hebben staan (het heeft immer geen zin om eerst software B uit het geheugen te moeten laden). Dit is ook een verschil tussen Intel en AMD (zoals aangegeven in het artikel), AMD kiest er voor om SMT wel te ondersteunen Intel niet.
Daar haalde ik even wat dingen door elkaar inderdaad. Nu is het doel van dit artikel natuurlijk niet om uit te leggen hoe OoOE werkt, maar voor zover je technisch correct kunt zijn als je een ingewikkeld concept als OoOE in een bijzin moet vatten, is het dat nu wel
Daar haalde ik even wat dingen door elkaar inderdaad. Nu is het doel van dit artikel natuurlijk niet om uit te leggen hoe OoOE werkt, maar voor zover je technisch correct kunt zijn als je een ingewikkeld concept als OoOE in een bijzin moet vatten, is het dat nu wel
Nee hoor, het statement in het artikel is absoluut correct. De beschrijving hierboven van @Lethalshot is ook een veels te sterke oversimplificatie van wat een OoO processor doet. Een optimalisatie zoals hij daar beschrijft is echt iets van de allervroegste dagen van OoO processoren zoals de Tomasulo scheduling in de IBM System 360/91 uit 1967, wellicht
Moderne OoO processoren speculeren wel 300+ instructies diep, berekenen de dependency chains (afhankelijkheids boom? Ik weet niet hoe ik dit in het Nederlands moet uitleggen ) tussen al deze instructies en gaan dan instructies uitvoeren zo vroeg als het kan, over vele paralelle executie units, dus potentieel compleet out of order. Dit gaat vooral ook om het lezen van gegevens uit geheugen, aangezien dat de grootste latency heeft in een moderne micro-architectuur en je daar dus zo min mogelijk op wil wachten.
Je wil dat je core zoveel mogelijk 'memory level parallelism', of MLP, heeft waarbij hij zoveel mogelijk overlappende geheugen requests uit heeft staan. Hierbij laat ik in het midden of deze geheugen requests uiteindelijk uit een cache, andere core, of DRAM terug komen - dat doet er niet toe want dat weet de core vooraf ook niet. Een DRAM access kost je zo 300-500 of meer cycles, waarin je je core zoveel mogelijk onafhankelijke andere dingen wil laten doen, en dan vooral uitvinden wat de volgende geheugen locaties zijn die hij moet aanvragen want de overige berekeningen zijn relatief triviaal.
Kan jij mij vertellen waar ik kan lezen over deze diepe OoO pipelines? Als ze tegenwoordig inderdaad zo diep zijn is mijn kennis achterhaald, want zover mijn kennis reikt haalt een x86 processor 4/5 instructie per tick op. Deze worden omgezet in rond de 4 micro-ops, welke vervolgens worden geoptimaliseerd. Maar dan zit ik nog steeds ruim onder de 100 ops die worden gebruikt (4 instructies x 4 micro-ops x 5 stage decoder pipeline). Maar ik leer graag bij.
Je moet hier naar kijken als twee compleet verschillende dimensies; de breedte (4-wide fetch/decode/rename, x-wide execution units, y-wide commit/retire), en de diepte (OoO-window size/Reorder Buffer size, load/store queue sizes, issue queues, etc etc). De breedte van de frontend (fetch/decode/rename) bepaald hoeveel instructies je maximaal per clocktick aan je OoO executie engine kan toevoegen. De dependencies zijn dan bepaald, zodat de backend weet wanneer hun inputs klaar zijn om de instructie te executeren.
De breedte (dus het aantal van) de execution units geeft weer hoeveel instructies er dan werkelijk tegelijk in parallel kunnen executeren wanneer ze alle data beschikbaar hebben. Dit is vaak veel meer dan de breedte van de frontend, ook omdat je executie units hebt voor specifieke klasse van instructies. De breedte van retire/commit is dan weer de hoeveelheid instructies die 'permanent' gemaakt kunnen worden per clock, dus hoeveel er, in programma-volgorde, de out of order executie engine kunnen verlaten wanneer ze allemaal succesvol geexecuteerd zijn.
Abstract zou je het kunnen zien als een groot vat wat je met een kraantje vult aan de top (front-end breedte), en onderaan (commit/retire) er weer uit laat lopen. De inhoud van het vat is de grootte van de OoO-Window, de grote grabbelton aan instructies waarvan je de dependencies weet. De ton is een grote wachtruimte voor ze, totdat ze uitgevoerd kunnen worden, of als ze al uitgevoerd zijn, totdat ze werkelijk volgens de programma volgorde voltooid kunnen worden. Dat is het punt waar de grote winst/magie zit van OoO.
De grootte van je OoO-window geeft dus aan hoe ver je vooruit kan werken, en daarom ook hoeveel geheugen referenties je kan laten overlappen. Maar je kan het window alleen heel groot hebben als je goed genoeg kan voorspellen (branch prediction) welke instructies er werkelijk geexecuteerd zullen worden.
Ik zou niet zo snel weten wat een goeie resource zou zijn om hier over te lezen - vaak zijn er wel goeie deep-dives op sites zoals Anandtech, en Wikichip heeft vaak gedetailleerde informatie. Bijvoorbeeld de Golden Cove core in Alder Lake heeft blijkbaar een OoO-window van wel 512 instructies, waar zijn voorgangen Sunny Cove slechts 352 entries had.
Intel gebruikte deze pipelines als basis voor een instructieset om locking te vereenvoudigen. Je kun dan lockvrij programmeren door het zetten van een rollbackpunt, dan de kritische code, en dan een controle-instructie die controleert of het lock gebroken is. En als het lock gebroken is dan zijn als die instructies vanaf het rollbackpunt dus "niet gebeurd".
Geen idee hoe lang die codereeks kon zijn, en de instructies werden uitgeschakeld omdat ze te buggy waren. Een soort 2nd order rollback was dat.
Ja, ik ben inmiddels Principal CPU Performance Architect bij Arm, in Cambridge. Ik werk vooral aan tooling en methodologie die helpt om nog betere CPUs te ontwerpen, en spreek ook met enige regelmaat met onze architecten.
Leuk voorbeeld. Wat m.i. OoO nog leuker maakt, is bij een stukje code als:
a=trage_array[idx] / 7
b = b+a
a=snelle_array[idx]/9
b = b+a
Hoewel het vanuit een taal als C niet logisch is om dezelfde variable naam te hergebruiken voor verschillende berekeningen, wordt dat in assembly code wel veel gebeurd. Registers zijn schaars en dus als de eerste deel van de berekening klaar is wil je graag verder met de tweede deel. Je kan daarvoor dezelfde registers gebruiken: want na de deling door 7 wordt het resultaat bij b opgeteld en is register a weer vrij in gebruik. Een moderne processor z'n microcode probeert daarmee instructies te schedulen voor optimaal gebruik van hardware.
Nu heb ik even als voorbeeld aangegeven dat de tweede berekening sneller verloopt dan de eerste (bijvoorbeeld vanwege cache). Een in-order processor zal stallen totdat eerst de data van de eerste berekening binnen is en daarna de snelle berekening doen. Een OoO processor zal register renaming toepassen. Na renamen kan het iets zijn als:
De register namen zijn nu niet meer afhankelijk van elkaar. De berekeningen van a23 en a25 blijken naast elkaar uitgevoerd te kunnen of zelfs in omgekeerde volgorde als de data eerder binnen is. Als het programma echter voorbij b26 wilt komen, dan moet natuurlijk wel alles bekend zijn. Maar als de rest van de code allemaal vlot doorloopt, dan kan dat een kwestie zijn van een diep genoege buffer aanleggen om dat op te vangen.
Processors hebben daarom tot wel honderden instructies 'in flight'. Die zijn afhankelijk van andere resultaten, branches die wel/niet genomen worden (speculatief), of simpelweg compacte code die op deze wijze wordt uitgerold om zo parallel mogelijk te kunnen draaien.
[Reactie gewijzigd door Hans1990 op 22 juli 2024 19:36]
Intel heeft altijd een sterke samenwerking met Microsoft.
Niet raar, dat Intel voor Win11 een Thread Director heeft geintroduceerd om betere thread verdeling over de hybride processors te krijgen.
AMD is hier veel minder sterk in.
Dat AMD denkt dat er geen aanpassingen nodig zijn, lijkt me ongeldig.
Het OS moet op de hoogte zijn van de CPU architectuur om de verdeling van de threads over de hybride CPU architectuur het maximale effect te krijgen.
Zo wil je achtergrond taken op je compacte cores en game threads op je performance cores.
Dat is bij AMD dus niet gegarandeerd.
Gezien de hechte samenwerking tussen Intel en Microsoft en het feit dat Intel software levert voor maximale thread distributie, verwacht ik niet dat Microsoft op zichzelf aanpassingen aan hun OS gaan doen om voor een AMD scenario het meest maximale effect te behalen.
En gezien AMD dat ook niet doet, is het maar de vraag hoe goed de hybride AMD CPUs straks gaan werken...
Niet raar, dat Intel voor Win11 een Thread Director heeft geintroduceerd om betere thread verdeling over de hybride processors te krijgen.
Dat is niet het geval, de Thread Director is een hardwarematig onderdeel van Intels processor. De aanpassing in Windows is het aanleveren van de juiste data daar aan.
Ik vind het wel een vreemde zaak dat AMD niets heeft om Windows van informatie te voorzien welke cores zuinig zijn. Als een random core gekozen word nu, wat is dan het hele nut van die c cores.
Ja, dat.
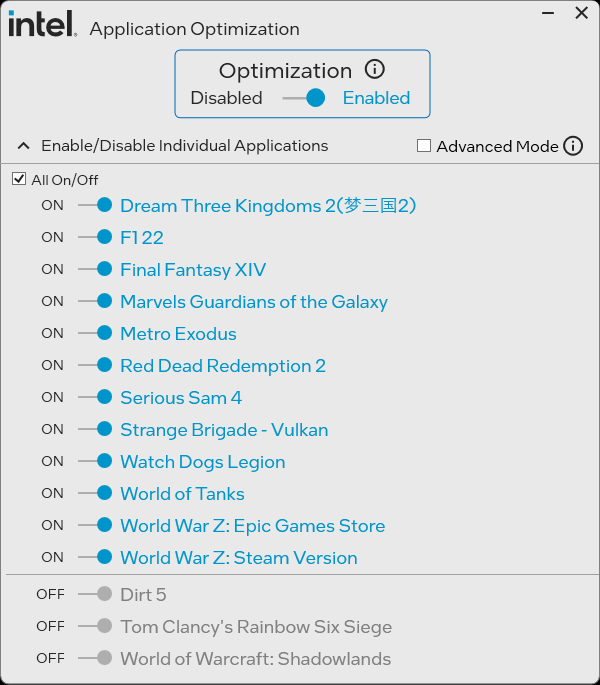
Bovendien laat Intel met "Application Optimization" zien dat de huidige thread verdeling op W11 voor games alles behalve optimaal is.
Door simpelweg met applicatie specifieke kennis de threads beter te verdelen over de cores, kunnen ze zo nog 30% extra performance pakken. https://www.intel.com/con...000095419/processors.html
Dat zegt wel iets over het feit dat een generiek OS (zoals W11) eigenlijk nog bij lange na niet geschikt is om complexe hybride CPU architectuur goed te ondersteunen.
Vergeet niet, dat Intel nu al de 3e generatie hybride architectuur heeft geintroduceerd.
Intel heeft zijn scheduling shit alleen maar aan zichzelf te danken door andere architectuur te gebruiken. Intel APO toont gewoon aan hoe shitty hun eigen architectuur is met P en E cores.
AMD heeft deze fix al in scheduler zitten. dit heeft niks met MS + Intel te maken, als je denkt dat MS niet met AMD eenzelfde r&d lijn heeft dan heb je het goed mis en dit allemaal omdat ze niet meer P cores in een package kunnen steken omdat dan de power nog verder uit zijn voegen gaat en hun productie proces nog erger is kwa uitval en bruikbaarheid.
daarom is er dus een algemeen statement van AMD dat alles al voorzien is. De GHZ en boost techniek was al voorzien en de cache techniek is ook beschikbaar. Het probleem stelt zich alleen als er meer perfromance cores nodig zijn dan er effectief in een CPU zitten... of in het geval dat er meer cores nodg zijn met X3D cache dan dat eronder zitten . Je zou dus de game of app effectief moeten kunnen forceren met max X aantal cores te gebruiken. (iets wat ze dus met APO doen.....boost-cache-cores afiinity opzetten, iets dat al jaar en dag bestaat maar niet in standaard MS OS scheduler)
[Reactie gewijzigd door d3x op 22 juli 2024 19:36]
Ik heb niet het vermoeden dat AMD het allemaal goed voor elkaar heeft.
Kijk bijvoorbeeld naar multi-CCD packages, zoals een 5900X of 5950X.
De performance van deze multi-CCD processors is doorgaans slechter bij gaming dan een single CCD (zoals de 5800X), omdat de helft van de game op de ene CCD draait en de andere helft van de game op de andere CCD.
En communicatie van 1 CCD naar een andere is erg "duur".
Je zou verwachten van een slimme scheduler, dat zodra de game start en voor 1 CCD kiest, dat alle threads uit de game dan naar dezelfde CCD wordt gestuurd.
Dan kan je alle niet-game threads op de andere CCD uitvoeren en daarmee zou 5950X sneller moeten zijn (ook in gaming) dan de 5800X.
Voor de X3D zie je hetzelfde. 1 CCD heeft de extra cache, de andere CCD niet.
Games wil je draaien op de CCD met de extra cache, omdat de game hier enorm van profiteert.
Ook hierom zie je dat een 7800X3D doorgaans sneller is dan de 7950X3D, terwijl in theorie de 7950X sneller zou moeten zijn.
Er moet echt nog een heleboel verbeteren aan de generieke schedulers, voordat al deze hybride architecturen werkelijk goed tot hun recht komen.
De reden dat er geen aanpassingen nodig zijn voor AMD is dat de scheduler al jaren geoptimaliseerd is om de best presterende core te gebruiken. Dus als je een Zen 2 chip hebt zoekt de scheduler zelf uit welke core de hoogste clock kan halen, als er een taak dan hoge clocks nodig heeft wordt dat op die core gedaan. Bij Zen 2 was dat gewoon toevallig een core die het iets beter doet dan de rest omdat het productieproces niet perfect is.
Een hybride Zen 4c en Zen 4 chip kan je ook zien als een Zen 4 chip met een aantal cores die heel slecht clocken. Als de scheduler dat al kon met een klein verschil kan het dat waarschijnlijk ook met een groot verschil.
Het is frappanter dat het artikel de oplossing van Intel eleganter noemt omdat daarbij de scheduler eerst moet checken dat een taak niet multithreaded is en moet bepalen of de taak belangrijk is of niet belangrijk is. Als een proces op een grote core draait kan die niet worden verplaatst naar een kleine core of andersom zonder ingewikkelde trucs in het OS. Volgens mij is er in Windows ook geen mogelijkheid om aan te geven of een proces een achtergrond proces is, dus een game kan zomaar op een e core terecht komen terwijl steam op de p core zit.
Een echt elegante oplossing zou het inderdaad zijn als taken netjes als voorgrond en achtergrond gekenmerkt kunnen worden door developers van verschillende apps en dat op een nette manier door iedereen wordt gedaan. Maar nu heeft Intel samen met Microsoft een beoordelingsalgoritme geschreven voor welke taak naar de e cores kunnen. Dat is een logische oplossing maar dat soort algoritmes zijn alles behalve elegant.
Volgens mij is er in Windows ook geen mogelijkheid om aan te geven of een proces een achtergrond proces is
Zit er al vele jaren in en dat kan kan je zelfs handmatig doen in task manager: Priority op "below normal" of "low" zetten.
Voeg in task manager bij de details tab maar eens de kolom base priority toe. Dan zie je dat bepaalde tools die achtergrond processen moeten zijn de priority op low hebben staan.
Maar je kan dus ook zelf een proces op low zetten. Als je bv een rendering tool hebt die 100% cpu vergt, dan kan je die op low of below normal zetten en kun je ongestoord andere dingen doen, terwijl die tool op de achtergrond de cpu power die je over hebt gebruikt, zonder dat je vertraging ervaart in de andere dingen die je doet.
[Reactie gewijzigd door mjtdevries op 22 juli 2024 19:36]
Denk je nou werkelijk, dat wanneer je als eindgebruiker het handmatig kunt instellen, dat een developer geen optie heeft dat voor zijn app in te stellen?
Uiteraard hebben ze die opties als developer ook.
Uiteraard gaat de scheduler van een recente Windows versie wel op de hoogte zijn van de AMD architectuur.
AMD zegt nergens dat er geen aanpassingen wenselijk zijn, alleen is een "c" core in principe gewoon een core net als alle andere cores en dus compatibele met programmatuur waardoor er geen aanpassing nodig is.
MS zal wel moeten met of zonder hulp van AMD: ze willen ook graag server versies van Windows verkopen en Epyc doet al zen4c. Aangezien in een datacenter niet alleen windows staat is de druk gewoon bij ms om dit goed te regelen. Intel maakt er een marketing feest van door te roepen dat ze samen met na dit varkentje gewassen hebben. Maar dat is dan dus gewoon verkapte reclame.
Dit staat toch letterlijk in het artikel:
"AMD's aanpak is wat ruwer en haalt wellicht niet de maximale efficiëntie uit het hybrideconcept, maar die eenvoud zorgt er ook voor dat softwareaanpassingen niet nodig zijn..."
Mijn statement: die aanpassingen zijn WEL nodig, omdat je anders random software runt op random cores ipv dat je probeert het maximale uit je hybride architectuur te halen.
Dat kan voor gaming zelfs nadelig uitpakken, indien je de verkeerde threads op de verkeerde cores draait en moet je mogelijk performance inleveren.
Ik vertrouw helaas het artikel hier niet honderd procent. Daar zou ik graag zekerheid over willen hebben. Ik bedoel, er zal vast na te vragen zijn in de CPU wat voor core het is. Dat je daar geen complete ThreadScheduler architectuur voor nodig hebt is een andere zaak.
[NB niks over gevonden inderdaad. En AMD beweerd Windows Thread Scheduler niet aan te hoeven passen. Dat lijkt me geen probleem bij zware workloads maar wel bij minder zware workloads - er vanuit gegaan dat die beter draaien op een 4c - maar dat weet ik ook niet zeker. Ik zou als ik AMD was aanraden om in ieder geval de cores in een CPU te kunnen identificeren]
[Reactie gewijzigd door uiltje op 22 juli 2024 19:36]
Natuurlijk komen hier aan passingen voor als het nodig is, daar twijfel ik echt geen moment aan
Dat kan voor gaming zelfs nadelig uitpakken, indien je de verkeerde threads op de verkeerde cores draait en moet je mogelijk performance inleveren.
Games en Applicaties pakken (zoals ook in het artikel staat) automatisch de snelste core, dus er zal in dat geval weinig prestaties mislopen, wellicht wel wat prestatie laten liggen als de c cores niet gebruikt worden voor achtergrond taken
Andere verschillen zijn dat Intels E-cores geen ondersteuning bieden voor AVX512-instructies, net zo min als de P-cores trouwens
De grap is dat de P-cores zélf er origineel wel ondersteuning voor hebben, maar dat is door Intel uit gezet.
We weten van Samsung dat verschillende instructiesets voor heterogene core setups geen briljant idee is, maar het blijft apart dat ze liever een nieuwe instructieset-uitbreiding willen bedenken dan er een oplossing voor te zoeken - zoals bijvoorbeeld een software-implementatie aangeroepen door een "trap" en scheduling hints naar het OS om AVX512 threads naar de P-core te schoppen.
Wat ik nog een veel grotere grap zou vinden is hoe snel Intel het weer gaat toevoegen in processoren omdat AVX512 net een beetje is ingeburgerd bij het ontwikkelen van games.
Door de lange ontwikkeltijd van games hebben we dit nog niet altijd in de praktijk gezien.
Maar wanneer bij installatie van een game gecheckt wordt welke processor er in zit en daarna de versie geïnstalleerd wordt waarbij de unreal engine gecompiled is met AVX512 enabled, zie je grote performance winst!
Er mist in dit artikel een belangrijke achtergrond over de Zen 4c chips. Van Intel wordt wel verteld waar de originele architectuur vandaan komt; de originele Atom chips en zuinige consumentenspace. Bij AMD was de overweging echter heel anders en is het gebruik van Zen 4c in de consumenten markt eerder een bijkomstigheid. AMD heeft de Zen 4c namelijk primair ontwikkeld om meer grip te krijgen op de lucratieve cloud markt.
Cloud providers zijn op zoek naar dichtheid voor hun machines (zoveel mogelijk cores per machine/eenheid rackspace). Cloud providers zitten echter absoluut niet te wachten op heterogeniteit. Als een product eenmaal gelanceerd is, is het onmogelijk of zeer lastig om ooit nog uit te faseren. Een andere Core is een apart product. Cloud providers hebben echter hun compute per core type al in verschillende smaken aangeboden staan; General Purpose (normale clocks, maar goedkopere cores), Compute Optimized (hoge clocks. dure cores), Memory Optimized, etc.
AMD speelt daar dus super goed op in door exact dezelfde core aan te bieden in een denser formaat. Dit is pure efficiency winst voor cloud aanbieders. 35% kleiner is 50% meer cores in dezelfde package en het is een drop in replacement voor een product wat ze toch al aanbieden, maar met veel hogere efficiency.
Belangrijk daarbij is ook dat de IPC hetzelfde is. Voor de general purpose compute gebruikten cloud aanbieders altijd al chips met de hoogste core count die een grote all-core load verstouwen, dus van boost is nauwelijks sprake. Die SKU's draaiden altijd al met lagere core clocks ten gunste van meer cores per chip. Een 3Ghz max clock is dus nauwelijks een beperking voor die markt maar de efficiency winst is groot.
Op de eerste pagina staat daar wel een verwijzing naar hoor:
Al gauw liet AMD doorschemeren ook wel iets te zien in zo'n hybrideprocessorarchitectuur. Als zuinige core zet het Zen 4c in, een kleinere versie van zijn reguliere Zen 4-core die oorspronkelijk werd ontwikkeld voor Epyc-serverprocessors met extreem veel cores.
In de aankomende Meteor Lake Laptop chips heeft een nieuwe type low-power E-core op de SOC tile. Deze E-cores wijken af van de normale E-cores en zijn extra zuinig. Wanneer de CPU weinig te doen heeft kan de compute-tile met de normale cores helemaal uitgeschakeld worden.
Misschien was het nuttig geweest om daar ook iets over te noemen in dit artikel?
Zie ook: https://www.pcworld.com/a...%20secondary%20functions.
[Reactie gewijzigd door Zeerob op 22 juli 2024 19:36]
Interessant artikel maar ik kan eigenlijk niets concreets terug vinden over het verbruik. Wat is dan het verschil in verbruik tussen een e en p core? En is de 4c core van AMD zuiniger of minder zuinig dan de e core van Intel? Dat is toch uiteindelijk waar het om draait. Ik had graag een test gezien waarin de p cores uitgeschakeld werden en het stroom verbruik gemeten werd en vice verca.
Beetje lastig, maar zen4 is al erg efficient,
Zeker op wat lagere clocks.
Je kan een 7950x op 70 wat laten draaien
Met relatief weinig verlies in perf
Op 3ghz moet dat dus wel echt cheap te doen zijn. En dan nog kortere paths
Beste is mogelijk naar de super veel cores van de nieuwe epics kijken en delen per core.
Kom je op maar 3 watt per core uit ongeveer
Begamo heeft 360/400w 128 cores
Op 3.1-3.7 (boostclock) ghz
Das dus echt wel zuinig.
Kan geen directe data vinden van een normale zen4 op dezelfde clocks
Maar denk dat het niet extreeeem
Veel zal uitmaken
Gezien 70w op 4.5-5.7ghz voor 16 cores met een nette undervolt (vooral minder boost ook)
Dus dat is 70/16 is grofweg 4.3w dus niet extreem veel hoger en hogere clock
[Reactie gewijzigd door freaq op 22 juli 2024 19:36]
je weet wat ze zeggen van aannames... en je doet hier nogal wat aannames.
Leg dan maar eens uit hoe hier een 'mislukkingen' uit kan komen?
Het is gewoon speculatie daar is die ook niet geheimzinnig over ofso, als je dat in je achterhoofd houd is er niks aan de hand, zelfs als er niks van klopt.
[Reactie gewijzigd door watercoolertje op 22 juli 2024 19:36]
Ja je kan gewoon downclocken
Ik ga het alleen niet doen met mijn workstation (van mijn baas enzo 😂)
De 4090 powerlimit heb ik wel verlaagd anders smelt ik mijn thuiskantoor uit in de zomer… of eigenlijk altijd…
Maar daar hoef ik de bios niet voor in (msi afterburner in mijn geval)
[Reactie gewijzigd door freaq op 22 juli 2024 19:36]
Dat is helaas een stuk ingewikkelder dan het lijkt. Zoals je zelf al zegt is het niet mogelijk om alle P-cores uit te schakelen en dus een test met alleen de E-cores actief te doen. Apparaten met Zen 4c-cores hebben we trouwens nog helemaal niet ons testlab, dus die kunnen we per definitie nog niet testen. Als die er komen, zullen dat in eerste instantie laptops zijn, die vaak een behoorlijk dichtgetimmerde bios hebben als het op dit soort opties aankomt.
Wat ik denk dat belangrijk is om mee te nemen uit dit artikel, is dat efficiëntie in de zin van stroomverbruik lang niet de enige reden is waarom Intel en AMD meerdere soorten cores combineren in één processor. Efficiëntie in de zin van 'prestaties per mm² die size' of 'prestaties binnen een vermogens / thermal budget' is in de x86-wereld soms een stuk belangrijker, en je ziet de fabrikanten daar dus ook meer op focussen.
Klopt, dat mis ik ook. Maar dan moet je of de performance cores kunnen uitschakelen (wellicht in bios) of een workload vinden die enkel (of grotendeels) de efficiency cores belast. Het is ook een beetje appels met peren vergelijken, want het idee achter de cores is anders. Maarja het zal vast wel kunnen. Het antwoord zal niet erg verrassend zal zijn, AMD is qua efficiëntie veel beter dan Intel met reguliere cores dus ik verwacht niet dat dat met dit type cores anders is.
Klopt, dat mis ik ook. Maar dan moet je of de performance cores kunnen uitschakelen (wellicht in bios) of een workload vinden die enkel (of grotendeels) de efficiency cores belast.
Je kunt P cores uitschakelen maar er is er altijd 1 actief. Min max power per core is te zien in HWiNFO bijvoorbeeld. Dit had allicht leuk geweest mee te nemen in dit artikel.
Met affinity (ingebakken in Windows, wel laar tijdelijk instelbaar) of een tool zoals Process Lasso kan je heel gemakkelijk zorgen dat een applicatie maar welbepaalde cores aanspreekt.
Daar ben ik inderdaad ook erg benieuwd naar, ook zeker naar de komende desktop cpu's met deze compacte cores
Het lijkt mij dat het stroomverbruik niet heel veel zal verschillende in de achtergrond programma's die dan random op een normale of compacte core draaien.
De zen 4c lijkt dus een efficiëntere core te zijn, al vindt ik die benamingen van Amd ook weer erg verwarrend.
En er wordt niet aangegeven hoeveel normale cores en hoeveel c cores er in de cpu zitten, dat moet je dus eerst gaan nakijken, wat overigens ook voor Intel geldt
Voor de gemiddelde consument wordt het er niet makkelijker op, en ook de gemiddelde tweaker zal even moeten checken welke cpu hij / zij wil hebben
Leuk uitzoek werk
@Tomas Hochstenbach Lees ik er nu overheen of heb je niets geschreven over Intel's Application Optimization tool? (Microsoft Store link). Het lijkt me een goede toevoeging aan het artikel gezien er met deze scheduler optimalisatie wel echt winst te behalen is (in het geval van APO voor een handje vol games (enkel op de 14k serie, windows 11, met een specifieke bios, etc etc.... maar toch)).
Gamers Nexus heeft er recent trouwens ook een video over gemaakt: link
evenals Hardware Unboxed: link
Disclaimer: dit soort tools doen natuurlijk niets af aan de feiten dat:
1. Het enorm jammer is dat scheduling niet beter werkt voor de verschillende soorten apps (in dit geval games).
2. De Intel 14k series geen 'mooie' processoren zijn. e-cores waar maar weinig mensen echt op zitten te wachten en een abnormaal hoog stroomverbruik. Nee, dat doet AMD dan momenteel toch stukken beter. #proudAMDuser
[Reactie gewijzigd door Gody op 22 juli 2024 19:36]
APO heb ik samen met de nodige andere zijdelings aan 'big.Little op de desktop' gerelateerde zaken bewust weggelaten. Dit artikel probeert geen allesomvattend naslagwerk over dat concept te zijn, maar een vergelijking van Intels E-cores en AMD's Zen 4c-cores die de verschillen in aanpak helder maakt. Eerder hebben we Intel APO natuurlijk wel uitgebreid getest: review: Intel Application Optimization - Fors meer fps in games met nieuw foe...
Het is echt niks meer dan een manier voor Intel om nog verschil te kunnen maken tussen 13e en 14e gen Processoren
Ik denk dat je met je reactie te kort door de bocht gaat. Here's why:
Is de 14-serie een goede koop/upgrade, nee, wat mij betreft niet. Hebben ze kansloos hoog verbruik, ja. Maar het feit blijft dat scheduling optimalisatie wel degelijk impact kan hebben; zeker wanneer er efficiente cores aanwezig zijn. En dus ook ongeacht of dat in het OS gebeurt of er aparte applicaties gebruikt kunnen worden om dat te bereiken.
Handje vol games? ik weet niet hoe klein jouw handen zijn maar het is letterlijk op maar 2 games, die zonder deze tool al extreem hoge FPS halen
Intel spreekt zelf al over meer games, die niet per se out of the box al zeer hoge fps hebben:link
...maar ze zeggen helaas ook dit (ipv een fatsoenlijk KB artikel te hebben):
Is there a list of supported applications for Intel® Application Optimization (APO)?
No. Intel® Application Optimization does not offer a list of applications/games at this time. User installed games that are optimized will show up in the UI list, which is available for download through Microsoft Store.
Ik vond de reactie eigenlijk niet echt te kort door de bocht, zeker niet omdat onderstaand gewoon waar is:
Het is echt niks meer dan een manier voor Intel om nog verschil te kunnen maken tussen 13e en 14e gen Processoren
Het zijn exact dezelfde dies als de 13e generatie, het is een rebrand. En natuurlijk levert het een tastbare hoeveelheid extra performance op, maar APO is werkelijk alleen beperkt tot de 14e generatie zodat er in ieder gevaal eem reden is om die te kopen. Want anders dan dat, is het een kansloze rebrand van een toch al zeer sterk tegenvallende serie. Zo kort door de bocht is die stelling niet, het is gewoon de simpele waarheid.
Maar veel belangrijker is je screenshot een grote leugen van Intel is. Ik hoop dat je gewoon een oprechte fout heb gemaakt, want je bent nu de marketing onzin van intel aan het herhalen. Je hebt die screen hier vandaan (althans dit is de originele bron):
Let ook op wat er bij staat: "Expanded view with detected applications list (example only). This list will vary for from user to user."
Leuke voorbeeld lijst, maar deze lijst stond ook online toen alleen metro exodus en rainbow six ondersteund werden: https://youtu.be/JjICPQ3ZpuA?t=229 (screenshot zelf komt op 4:10 langs)
Ik kan uberhaupt nergens een officiele lijst (of zelfs maar een reddit thread) met ondersteunde applicaties vinden, dus ik ben bang dat het niet veel meer is dan dit?
[Reactie gewijzigd door Thekilldevilhil op 22 juli 2024 19:36]
De afbeelding komt inderdaad van die pagina. En ja, mogelijk een oprechte fout. Het is echter onduidelijk of de screenshot als voorbeeld moet dienen en die games dus:
1. wel APO ondersteuning hebben en het ‘example only’ deel hier enkel slaat op het gegeven dat games alleen getoond worden als de gebruiker ze geïnstalleerd heeft.
2. geen APO ondersteuning hebben en Intel weer loopt te liegen.
Het blijft in ieder geval kansloos dat ze geen duidelijke lijst met games willen vermelden én dat ze de 13K serie niet willen ondersteunen.
Zoals ik zei, het is niet een mogelijke fout, het is een fout. De vraag was alleen op je het bewust had gelinkt, maar niet dus. Gelukkig maar.
Bekijk nog even de gelinkte video en je zult zien dat het optie 2 is. Ik heb je al naar het stuk gelinkt waar de screenshot besproken wordt. Die staat er al sinds het moment op dat er nog maar support was voor 2 games. En ook op dit moment is er geen APO ondersteuning voor die specifieke games. Althans, ik kan letterlijk niets vinden voor geen van de "sample" titels. Het is dus gewoon een dikke leugen met "sample" erbij voor de hint van plausible deniability.
Het is geen winst, het is opkuis van hun eigen scheduler rommel en design rommel.
omdat er games zijn die meer echte cores nodig hebben dan dat er beschikbaar zijn op een intel cpu
omdat ze niet meer P cores kunnen toevoegen omdat hun total wattage uit de bol gaat (wat nu al het geval is)
omdat ze e-cores met massa toevoegen voor magische benchmarks en meer dan ook maar nodig voor eender welke dagelijks operatie maar toch maar weer voor de prestaties en benchmarking.
omdat ze dan nog meer miserie hebben in productie met hun CPU die oppervlak met enkel meer P-cores
brengen ze SW en andere fixes uit...
je zou eerder de vraag moeten stellen, who's the fool and who is fooling who....
[Reactie gewijzigd door d3x op 22 juli 2024 19:36]
Ik ben het met je eens dat de 14k serie geen mooie processoren zijn. Veel Hz, ja, maar helaas ook een abnormaal hoog verbruik. Dat doet AMD dan toch aanzienlijk beter momenteel.
Wb de scheduler, dat is helaas een combinatie van het OS en de CPU. Hoe men dat optimaliseert maakt uiteindelijk voor sommigen onder ons minder uit; als het maar kan. Als de Windows scheduler dus een update krijgt, prima, APO achtige tools, ook prima.
De crux zit 'm in de kloksnelheden. Doordat alle onderdelen in de processor dichter op elkaar zitten, wordt de geproduceerde hitte over een minder grote oppervlakte verspreid en is er minder 'headroom' voor hoge klokfrequenties. Effectief kunnen de Zen 4c-cores werken op een snelheid rond de 3GHz, terwijl een goed gelukte grote Zen 4-core tot boven de 5,5GHz kan klokken.
Dat zal vast een rol spelen, maar dan zou het puur en alleen thermische limieten zijn die dat beperken? Het is ook zo dat logische cellen die groter zijn simpelweg sneller zijn dan kleintjes: Je kan kiezen tussen enkele opties van hoeveel tracks je logische cellen zijn. En dan is natuurlijk de vraag waarom je niet altijd kleinste zou kiezen: Omdat die ook langzaamste zijn. Niet vanwege thermische limieten, maar simpelweg omdat de kleinste transistoren erin zitten, die niet zo sterk zijn. En natuurlijk, als alles kleiner is dan hoeven ze ook niet zo sterk te zijn, maar onder de streep schaalt dat niet lineair: Als ze 30% minder sterk zijn, en 20% minder hoeven aan te sturen aan bedrading erachter, zijn ze alsnog ~10% langzamer. Eg als random Google resultaat: https://www.dolphin-ic.com/tsmc_28hpm_cell.html
Ik bedoelde daar niet per se een causaal verband mee, maar dat dat twee parallelle redenen zijn. Wat jij noemt is wat ik bedoelde met dat er minder headroom voor hoge kloks is
Ik wilde precies dezelfde paragraaf quoten! Het is inderdaad veel meer dan hitte, het gaat vooral ook over de optimalisaties in de layout en cell/transistor selectie wanneer je een core niet voor een hoge frequentie hoeft te bakken. Je hebt altijd zogenaamde kritieke timing paden in de circuits van een processor, waar je dus echt de uitdaging hebt op hoge kloksnelheden om een signaal op tijd van het ene naar het andere punt te krijgen. Dit kan opgelost worden door bijv grotere transistoren en speciale standard cells te gebruiken die een lichtere impact hebben op je timing, maar die kosten wel meer ruimte en meer energie. Bij Zen4c zal je dus zien dat de layout en fysieke implementatie van het design veel compacter en geoptimalizeerder kan omdat je niet al die speciale trucs hoeft uit te halen om een 5+ GHz frequentie te kunnen halen.
[Reactie gewijzigd door Squee op 22 juli 2024 19:36]
Op technisch gebied, zou het uitmaken dat de AMD-cores intrinsiek hetzelfde zijn als de Zen4 en de Intel niet? Iiirc b.v. support voor nieuwe Intel chips even op zich wachten vanwege de grote verschillen in CPU cores, al zal dat tegenwoordig ook wel opgelost zijn.
Het zal ze enorm veel ontwikkelings kosten schelen omdat ze niet twee compleet verschillende cores hoeven te ontwikkelen! Maar aan de gebruikers kant lijkt het me vooral een voordeel hebben voor software/compiler optimalisaties. Dus de "performance portability" zal waarschijnlijk beter zijn tussen Zen4/Zen4c.
[Reactie gewijzigd door Squee op 22 juli 2024 19:36]
Met de achterliggende gedachte dat wanneer je een 100% workload heeft, heeft BIG.little dan niet een voordeel doordat de P cores terugschalen in frequentie en eigenlijk ongeveer(?) on par liggen bij E cores? Heb er zelf niet echt concrete onderbouwing voor, maar gezien Intels keuze om voor een BIG.little design te gaan leek me vooral een manier om het energieverbruik enigszins binnen de perken te houden.
Edit;
Ah ja, even snel doorheen gelezen maar is inderdaad vermeld bij conclusie. My bad.
[Reactie gewijzigd door Verwijderd op 22 juli 2024 19:36]

/i/2006283560.png?f=imagegallery)
:strip_exif()/i/2005599762.jpeg?f=imagegallery)


/i/2006283506.png?f=imagegallery)
:strip_exif()/i/2006208818.jpeg?f=imagegallery)
:strip_icc():strip_exif()/i/2006434930.jpeg?f=fpa_thumb)
/i/2004836790.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004764144.jpeg?f=fpa_thumb)
:strip_exif()/i/2005279580.jpeg?f=fpa)
:strip_exif()/i/2006208826.jpeg?f=fpa)
:strip_exif()/i/2005832458.jpeg?f=fpa)
/u/242701/crop5e107244d1e57_cropped.png?f=community)
:strip_icc():strip_exif()/u/287731/crop6270fa65746ea_cropped.jpg?f=community)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/223199/crop5a67afd37dfed_cropped.png?f=community)
:strip_icc():strip_exif()/u/109773/ziltoid_fetid_70px.jpg?f=community)
:strip_icc():strip_exif()/u/122141/ic.tweakimg.net2.jpg?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
:strip_icc():strip_exif()/u/164703/images2.jpg?f=community)
/u/58600/got_icoon.png?f=community)
/u/172175/crop5fab02e55e7d4_cropped.png?f=community)
:strip_icc():strip_exif()/u/284419/Mexican%2520Wolf%2520Klein.jpg?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_exif()/u/267104/crop68df846c7e46c.gif?f=community)
/u/954149/crop5984ccfcadb91.png?f=community)
/u/581347/crop64beea7e7f624_cropped.png?f=community)
:strip_icc():strip_exif()/u/1157718/crop5e6d5ebf96a5f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
:strip_icc():strip_exif()/u/464574/crop5ef5b118724ae_cropped.jpeg?f=community)
{kind=link}