Aan het begin van dit jaar was Big.Little nog iets voor smartphones, hooguit tablets. Intel bracht dit principe met Alder Lake naar desktops en laptops, terwijl AMD aan een compactere, zuinigere variant van zijn Zen 4-core werkt. Opeens lijken processors met verschillende soorten cores ook voor de x86-wereld de toekomst. De scheduler van Windows 11 zou zijn geoptimaliseerd om met deze hybride processors te werken. Wat is de theorie daarachter en, belangrijker, hoe werkt die combinatie van verschillende soorten cores in de praktijk?
Hoewel 'Big.Little' de term is waaronder het principe van een processor met verschillende soorten cores bekendstaat en ook de term is waarvoor we in dit artikel kiezen, heeft Arm zijn eigen techniek inmiddels officieel hernoemd naar 'DynamIQ'. Op papier is Intels Performance Hybrid Architecture redelijk vergelijkbaar met Arm's concept. De doelen waarmee ze zijn ontwikkeld, zijn dan ook identiek: maximale energie-efficiëntie en prestaties binnen de limieten op het vlak van warmteproductie en energiegebruik. In de praktijk ligt de nadruk bij Arm-chips meer op zuinigheid en bij x86-processors meer op het maximaal benutten van de beschikbare stroom- en warmteruimte, maar dat komt eerder door het type apparaten waarin beide soorten cpu's vooral worden toegepast dan door een verschil in de technische aanpak.
Om te beginnen duiken we in dit artikel in de theorie achter schedulers die geschikt zijn voor hybride processors, waarbij niet alleen de software, maar ook de hardware steeds meer een rol speelt. Daarnaast analyseren we het gedrag van x86- en Arm-processors onder Windows 11 in allerlei verschillende workloads, met speciale aandacht voor welk type cores voor welke workloads aan het werk worden gezet.
De theorie achter hybride scheduling
Een universele keuze voor het aansturen van hybride processors is dat softwareontwikkelaars niet verantwoordelijk worden gemaakt voor het verdelen van de taken. Bij zowel x86- als Arm-processors geldt dat de scheduling een samenspel is van hardware en OS. De uiteindelijke programma's zien slechts hoeveel logische rekenkernen aanwezig zijn en hebben niet of nauwelijks invloed op welke threads aan welke cores worden toebedeeld. Zo wordt voorkomen dat er in de toekomst softwareproblemen ontstaan, als bijvoorbeeld de verhoudingen tussen zuinige en snelle cores veranderen ten opzichte van de processors die er nu zijn.
Een ander uitgangspunt is dat de microarchitectuur weliswaar kan verschillen tussen snelle en zuinige cores, maar dat de instruction set architecture van alle typen cores gelijk is. Elke core kan dus elke ondersteunde instructie uitvoeren; het verschil zit 'm puur in de snelheid en efficiëntie waarmee dat gebeurt. Arm-cores gebruiken hiertoe dezelfde ISA-versie, bijvoorbeeld ARMv8-A. Intel heeft om dit mogelijk te maken diverse, eerder ontbrekende instructies toegevoegd aan zijn zuinige Gracemont-cores en AVX512 juist uitgeschakeld bij de snelle Golden Cove-cores.
Scheduling op basis van energiegebruik en prestaties
Aangezien elke core elke instructie kan uitvoeren, kan de taakverdeling volledig op basis van de kenmerken van de huidige workloads worden gemaakt. Zowel Arm als Intel monitort hiervoor continu hoe een proces zich gedraagt, bijvoorbeeld de belasting, de instructiemix en karakteristieken van het stroomverbruik. Ook gedeelde cachetoegang, zoals Intels Gracemont-cores die per vier stuks een brok L2-cache delen, kan daarbij een factor zijn.
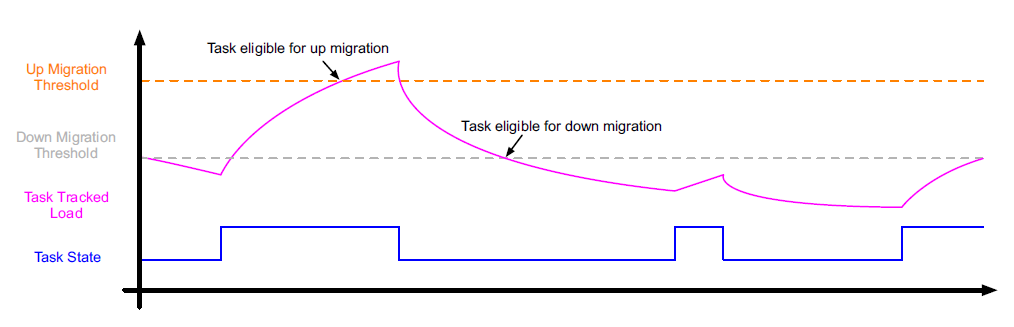
Simpel gezegd - we gaan zo verder de diepte in - trekt de hardwarescheduler een lijn waarboven een thread aanspraak kan maken op een plekje in een snelle core. In feite zijn er twee lijnen, eentje voor promotie en eentje voor degradatie, omdat er hysterese wordt toegepast. Dit voorkomt dat een proces dat op het randje van deze lijn balanceert, continu wordt verplaatst tussen twee coretypen.
Intel focuste bij de aankondiging van Alder Lake vooral op scheduling aan de hand van het instructietype, maar dat is slechts een deel van het verhaal. Meer concrete informatie over hoe de hardwarescheduler werkt, verscheen eerder dit jaar in een door Intel gedeponeerd octrooi, met de titel: System, apparatus and method for providing hardware state feedback to an operating system in a heterogeneous processor.
In dat patent wordt een voorbeeld gegeven van de methode die Intel gebruikt om een thread toe te wijzen aan een bepaald type core. Daarvoor volgt een thread een proces dat bestaat uit vier stappen. Als het antwoord op alle vier die stappen positief is, wordt een thread toegewezen aan een snelle core.
Bepalen van het gevraagde prestatieniveau Het gevraagde prestatieniveau wordt bepaald op basis van de verwachte tijd die een proces gaat duren, of dat proces op de voor- of achtergrond werkt, hoe latencygevoelig het proces is en wat de ingestelde prioriteit is. Al deze informatie is afkomstig van het OS.
Bepalen van threaddominantie In de volgende stap wordt bekeken in hoeverre een thread profiteert van hoge singlethreaded prestaties. Een proces kan bijvoorbeeld een veelvoud van cores belasten, de dominante thread zijn in een beperkte verzameling of zelfs volledig beperkt zijn tot één core.
Bepalen van energie- of warmtebeperkingen Als de processor op dit moment al met beperkingen op het gebied van stroomverbruik of warmteproductie te maken heeft, wordt sneller de voorkeur gegeven aan een zuiniger type cores.
Bepalen van schaalbaarheid De laatste factor is de schaalbaarheid van de thread. Daarbij gaat het niet om schaling naar meer threads, maar om schaling bij het beschikbaar stellen van meer vermogen en daarmee rekenkracht. De belangrijkste informatiebron is het hardwarematige feedbackcircuit over hoe een thread de verschillende onderdelen van een core belast. Als de flessenhals zich bijvoorbeeld bevindt bij een bepaald type rekeneenheden die aanmerkelijk krachtiger zijn bij de snelle cores, dan kan dat meewegen in de beslissing om de thread te 'promoveren'.
Bij het bepalen van die schaalbaarheid heeft de processor ook informatie over de prestaties-energiegebruikcurve en spanning-klokfrequentiecurve van beide coretypes tot zijn beschikking. Niet alleen de softwarethread moet immers kunnen schalen, de hardware moet dat zelf ook kunnen. De verhouding tussen prestaties en het benodigde vermogen kan worden samengevoegd in een lijn: een zogenaamde S-curve. Het middelpunt is in theorie het ideale schakelpunt tussen zuinige en snelle cores, maar bij een goed schalende workload kan dat al eerder gebeuren, terwijl een slecht schalende workload juist langer op de zuinige cores blijft.
Hardwarematig feedbackcircuit
Dat hardwarematige feedbackcircuit, 'Thread Director' in Intels marketinguitingen, is wat de scheduling van hybride processors een stuk geavanceerder maakt dan de mogelijkheden die de softwareschedulers van bijvoorbeeld Windows en Linux tot nu toe tot hun beschikking hadden. Er is nu sprake van tweerichtingscommunicatie, doordat de software niet alleen informatie geeft over het type thread, maar ook feedback krijgt van de processor zelf over hoe die thread in de praktijk draait.
Deze feedback is afkomstig van de vermogenscontroller in de processor, die het verbruik van elke core monitort, en wordt weggeschreven naar een deel van het systeemgeheugen. Het hele proces wordt met een vaste interval doorlopen - volgens Intel kan dat iedere nanoseconde - maar het besturingssysteem leest niet elke keer alle informatie uit. Als er een significante wijziging heeft plaatsgevonden ten opzichte van de voorgaande feedbackloop, wordt een waarde aangepast zodat het OS weet dat er nieuwe informatie is. Pas dan wordt de volledige feedback uitgelezen, om deze bit daarna terug te flippen. Als dat is gebeurd, wordt het feedbackproces hervat. In theorie kan het OS de frequentie van de feedback hiermee ook beïnvloeden, simpelweg door even te wachten met het terugzetten van de bit.
Dat een processor over deze mogelijkheid beschikt, wordt aangegeven via het Cpuid-register. Het besturingssysteem leest dat uit bij het starten en onderneemt dan de vereiste stappen om het feedbackmechanisme te laten werken, zoals het alloceren van een geheugenadres.
Testmethoden
In dit artikel willen we inzicht bieden in de werking van de Windows 11-scheduler in de praktijk. De benchmarks die we daarvoor hebben ingezet, komen je waarschijnlijk bekend voor, want ze zijn voor een groot deel afkomstig uit onze testsuite voor processors. Dit keer gebruiken we ze echter niet om de prestaties te meten, maar hebben we op de achtergrond continu de belasting per core gelogd. Zo komen we erachter hoe de scheduler bij hybride processors omgaat met een keur aan workloads.
Microsoft Surface Pro X met SQ2-processor
Windows 11 werkt niet alleen op traditionele x86-processors, maar er is ook een ARM64-versie van. Een deel van de programma's hebben we daarom ook op een Microsoft Surface Pro X gedraaid, met een door Qualcomm geproduceerde Arm-chip aan boord. Software die niet (goed) werkt op de Arm-versie van Windows of die het gebruiksdoel van deze zuinige Arm-soc ver voorbijschiet, hebben we alleen op de Intel-chip geanalyseerd.
De meeste tests hebben we uitgevoerd op een Intel Core i7 12700K-processor, een Alder Lake-cpu met acht 'snelle' Golden Cove-cores en vier 'zuinige' Gracemont-cores. Er is ook nog een i9-versie met acht zuinige cores, maar die was op het moment van testen in gebruik voor onze moederbordreviews. De rest van het systeem was identiek aan onze standaard cpu-testbench, met een ASUS ROG Maximus Z690 Hero-moederbord, 32GB G.Skill Trident Z5 DDR5-4800-geheugen en een Samsung 970 EVO 1TB-ssd. Voor de tests in games hebben we daar een AMD Radeon RX 6900 XT aan toegevoegd.
Voor de Arm-tests gebruikten we zoals gezegd de nieuwste Microsoft Surface Pro X, uitgerust met een SQ2-soc. Deze processor is geproduceerd op TSMC's 7nm-procedé en naaste familie van de Snapdragon 855-processor voor smartphones, al is hij aanmerkelijk hoger geklokt. In totaal heeft de chip acht cores: vier zuinige Kryo 495 Silver-cores op 2,42GHz en vier snelle Kryo 495 Gold-cores op 3,15GHz. De Gold-cores zijn gebaseerd op de Cortex-A76-kernen van Arm zelf, de Silver-cores kennen hun oorsprong in de Cortex-A55. Onze uitvoering van de Surface Pro X was voorzien van 16GB werkgeheugen en een 256GB-ssd.
Het loggen van de belasting per core hebben we uitgevoerd met HWMonitor Pro, dat als een van de weinige diagnoseprogramma's ook overweg kon met de Arm-processor. De actuele stand van zaken wordt twee keer per seconde weggeschreven. De snelle en zuinige cores hebben een vaste volgorde; bij de Arm-chip zijn thread 0 tot en met 3 de Silver-cores en 4 tot en met 7 de Gold-cores, bij de Intel-cpu zijn thread 0 tot en met 15 de P-cores (met hyperthreading) en 16 tot en met 19 de E-cores. Zo zie je ze dus ook terug in taskmanager. In de grafieken herken je de snelle cores altijd aan de kleur goud en de zuinige cores aan de kleur zilver, zodat je in een oogopslag weet met wat voor cores je te maken hebt.
Waar komt elk deel van de prestaties vandaan?
Voordat we het gedrag van de processors in diverse programma's gaan bekijken, beginnen we onze praktijkervaringen met de vraag waar elk deel van de prestaties van de processors vandaan komt. Links in rood zie je de scores van beide processors in Cinebench 23 MT, rechts zie je de scores die we halen als we die test door middel van core-affinity uitsluitend op een bepaald type cores laten draaien. De zilveren balkjes horen bij de zuinige cores, de gouden balkjes bij de snelle cores. Die kleurcodering houden we in dit hele artikel aan.
Hoewel de prestatieniveaus van de Microsoft SQ2 en de Intel Core i7 12700K natuurlijk totaal verschillen, gaan de meeste constateringen voor beide processors op. Zo zijn de losse scores van de snelle en zuinige cores in beide gevallen hoger dan de totaalscores wanneer we alle cores benutten. Overige achtergrondtaken kunnen bij een gedeeltelijke belasting immers op de onbelaste cores draaien, zodat ze niet een klein beetje van de Cinebench-prestaties afsnoepen.
Ook de relatieve bijdrage van beide soorten cores aan de totale score is redelijk vergelijkbaar. Bij de SQ2 komt 14,6 procent van de prestaties uit de zuinige cores en 85,4 procent uit de snelle cores. Bij de 12700K hebben de zuinige cores met 16,5 procent een marginaal groter aandeel. Nu bestaat er natuurlijk ook nog een Core i9 12900K met acht in plaats van vier zuinige cores, maar evenveel snelle cores. Als we er voor het gemak even van uitgaan dat het prestatieniveau van de zuinige cores daarmee verdubbelt, stijgt hun bijdrage aan de totaalscore dan naar 28,3 procent.
Wat we hieruit natuurlijk ook kunnen afleiden, is dat de zuinige Intel-cores relatief gezien een stuk sneller zijn dan de zuinige Arm-cores. Bij de SQ2-soc zijn er immers vier zuinige en vier snelle cores; 50 procent van de cores levert daar dus amper 15 procent van de prestaties. Bij de 12700K leveren vier van de twaalf cores, dus 33 procent van de cores, ongeveer diezelfde 15 procent.
Analyse: Arm- versus x86-cpu
In het eerste deel van onze analyse richten we ons op programma's die ook (goed) werken op de SQ2-soc. Op deze pagina vind je Adobe Photoshop, de Jetstream-benchmark in de Edge-browser, een programmastarttest en de renderbenchmark van CoronaRender. De eerste drie programma's draaien native op de Arm-chip, CoronaRender is een x86-programma en wordt dus geëmuleerd.
Adobe Photoshop
We trappen af met Photoshop, waarvan zoals gezegd een native Arm-versie beschikbaar is. Onze benchmark bestaat uit het uitvoeren van diverse effecten, zoals vervagingen, verscherpingen, het wijzigen van het formaat en artistieke filters.
SQ2 - Belasting per type core
SQ2 - Aantal cores per type
Op de SQ2-chip zie je heel duidelijk de verschillen tussen de diverse bewerkingen die we uitvoeren. De vervagingen aan het begin weten vrijwel alle cores goed te belasten, maar daarna komen er diverse effecten bij die slechts een, twee of drie snelle cores bezighouden en de zuinige cores helemaal met rust laten. Aan het einde wordt er wel weer beter gemultithread; in elk geval de snelle cores worden dan volledig aan het werk gezet.
12700K - Belasting per type core
12700K - Aantal cores per type
Dezelfde test weet op de x86-processor veel consistenter alle beschikbare cores te gebruiken, waarbij opvalt dat er nauwelijks verschil is tussen hoe de snelle en hoe de zuinige cores worden ingezet. Alleen naar het einde toe worden er minder snelle cores en nauwelijks nog zuinige cores gebruikt.
CoronaRender
Zoals de naam al zegt, is CoronaRender een renderbenchmark, die doorgaans erg goed schaalt naar veel cores en threads.
SQ2 - Belasting per type core
SQ2 - Aantal cores per type
Op de SQ2 weet CoronaRender alle cores continu volledig te belasten.
12700K - Belasting per type core
12700K - Aantal cores per type
Ook op de 12700K is dat het geval; alle vier de zuinige cores en de zestien threads van de snelle cores worden continu volledig gebruikt. Deze test maakt overigens ook het snelheidsverschil tussen beide processors mooi inzichtelijk. Op de SQ2 duurt de benchmark ruim 12 minuten, op de 12700K is het rekenwerk al na 46 seconden voltooid.
Jetstream / Edge
Normaal gesproken draaien we de Jetstream-benchmark, die vooral JavaScript- en WebAssembly-tests bevat, in Chrome. Alleen van Edge is echter een native Arm-versie beschikbaar, dus hebben we de test dit keer in Microsofts Chromium-uitwerking gedaan.
SQ2 - Belasting per type core
SQ2 - Aantal cores per type
Op de Arm-chip worden vrijwel alleen de snelle cores aan het werk gezet tijdens Jetstream, met uitzondering van een kleine deeltest die alle threads belast. Een groot deel van de tijd wordt er zelfs maar één snelle core voor meer dan de helft gebruikt.
12700K - Belasting per type core
12700K - Aantal cores per type
Door het grote aantal cores van de 12700K stelt het gebruik van de volledige cpu weinig voor. De zuinige cores blijven zelfs bijna volledig idle, terwijl een snelle core het grootste deel van de taken op zich neemt. De deeltest die wel kan multithreaden, zien we ook hier duidelijk terug, maar gemiddeld worden de cores ook dan maar voor rond de 70 procent belast.
Programma's starten
Voor dit artikel hebben we een extra test uitgevoerd waarin we diverse programma's achter elkaar starten. Daarvoor hebben we alleen software uitgekozen waarvan ook een native Arm-versie beschikbaar is, zodat we een appels-met-appelsvergelijking kunnen maken tussen de SQ2 en de 12700K. Die programma's zijn, in volgorde: Edge, Windows Verkenner, Excel, Cinebench 23 en Adobe Photoshop.
SQ2 - Belasting per type core
SQ2 - Aantal cores per type
Edge en Verkenner staan op de Surface Pro X binnen een mum van tijd op het scherm. Excel starten duurt iets langer; alle cores worden daarvoor aan het werk gezet. Cinebench en Photoshop hebben meer tijd nodig, waarbij die eerste alleen op de snelle cores leunt. Bij het starten van Photoshop worden zo nu en dan ook de zuinige cores betrokken.
12700K - Belasting per type core
12700K - Aantal cores per type
Het starten van software doet de 12700K in vergelijking met de SQ2 natuurlijk met twee vingers in zijn neus. De belasting van de snelle cores, die het merendeel van het werk voor hun rekening nemen, komt in totaal nooit boven de 20 procent uit. Alleen Photoshop belast tijdens het starten een tweetal snelle cores voor meer dan de helft.
Analyse x86: compileren, compressie en cryptografie
De applicaties op deze en de volgende pagina's werken niet op de Arm-processor of gaan volgens ons verder dan de gebruiksdoelen waar de SQ2-soc in de Surface Pro X voor is bedoeld. Daarom bekijken we hier alleen het gedrag van de Core i7 12700K-processor.
MozillaBuild compileren
MozillaBuild is een pakket dat alle tools bevat die je nodig hebt om zelf de Firefox-browser te compileren, met behulp van Visual C++.
12700K - Belasting per type core
12700K - Aantal cores per type
Het compileren van Mozilla Firefox bestaat uit diverse taken, waarvan de meeste prima schalen naar een veelvoud aan cores. Aan het begin, op ongeveer twee derde en aan het einde worden echter ook processen uitgevoerd die alleen op een klein aantal snelle cores draaien.
7-Zip
We gebruiken 7-Zip om 4GB aan data in te pakken. We kiezen voor inpakken omdat dat grotendeels afhankelijk is van de processor, terwijl de bottleneck bij het uitpakken vrijwel altijd bij de opslag ligt.
12700K - Belasting per type core
12700K - Aantal cores per type
7-Zip is een schoolvoorbeeld van een volledige multithreaded workload; zowel de snelle als de zuinige cores worden volledig gebruikt gedurende het hele proces.
AIDA64
We draaien de AIDA64-benchmarksuite integraal. Daarin komen diverse soorten computeworkloads en encryptiemethoden voor. Waar mogelijk worden instructiesetuitbreidingen als SSE en AVX ingezet. Verder meet dit programma hoe snel SHA-3-hashes kunnen worden berekend.
12700K - Belasting per type core
12700K - Aantal cores per type
De verschillende algoritmen die deel uitmaken van AIDA64, blijken uitstekend in staat om alle cores, de snelle en de zuinige, volledig te benutten.
Analyse x86: video-encoding en -bewerking
Op deze pagina analyseren we de scheduling in programma's die te maken hebben met videobewerking.
Adobe Premiere Pro
In Adobe Premiere Pro renderen we een echt project van een Tweakers Tech Hub-aflevering. We exporteren de video in 4k-resolutie.
12700K - Belasting per type core
12700K - Aantal cores per type
Premiere Pro kan aardig schalen, maar de zestien threads van de snelle cores worden niet consistent volledig belast. Zeker in het begin zitten er wat dips in de grafiek van het aantal cores dat voor minstens de helft in gebruik is. De zuinige cores rekenen ook een beetje mee, maar worden duidelijk minder zwaar belast dan de snelle cores.
X264-encoding
Met behulp van de x264-codec converteren we een mp4-video met 1080p-resolutie en een framerate van 60fps.
12700K - Belasting per type core
12700K - Aantal cores per type
De x264-codec kan in theorie veel cores belasten, maar in de praktijk verloopt de belasting wat grillig. Opvallend is dat de zuinige cores minder snel en significant dippen dan de snelle cores. Omwille van de efficiëntie lijkt de scheduler de zuinige cores dus voorrang te geven.
X265-encoding
We zetten het videobestand nog eens om, maar nu doen we dat met de nieuwere x265-codec.
12700K - Belasting per type core
12700K - Aantal cores per type
X265 heeft nog wat meer moeite om alle cores continu te benutten dan x264. Ook hier zien we echter weer dat de saturatie van de zuinige cores gemiddeld wat hoger is en bovendien beter op peil blijft.
Analyse x86: games
Tot slot hebben we ook het cpu-gebruik van twee games in kaart gebracht. Games hebben doorgaans een typisch gebruikspatroon, dat zeker niet naar heel veel cores schaalt en afhankelijk is van een dominante thread: de renderthread. In zijn handleiding voor gameontwikkelaars adviseert Intel dan ook om die vooral op een van de snelle cores te laten draaien, terwijl asynchrone, niet-kritieke berekeningen zoals AI, animatie, physics en geluidseffecten prima op de zuinige cores kunnen draaien.
F1 2021
In F1 2021 rijden we tweemaal een rondje op het circuit van Zandvoort, in zowel voor de rijders als voor je hardware uitdagende, regenachtige omstandigheden. De eerste keer doen we dat op Medium-settings, de tweede keer met Ultra-settings.
12700K - Belasting per type core
12700K - Aantal cores per type
Het laden van de spelwereld neemt kort alle cores in beslag, inclusief de zuinige, maar in het verdere verloop spelen de zuinige cores amper nog een rol. Tijdens het gamen worden zelfs lang niet alle threads van de snelle cores benut. In het eerste rondje op Medium-settings zijn dat er nog regelmatig acht, waarbij nadere inspectie van de data ons leert dat er steeds keurig een thread wordt overgeslagen om alleen de fysieke (en niet de virtuele, hyperthreaded) cores te gebruiken.
In het tweede rondje op Ultra-settings wisselt dat tussen de twee en zeven threads. Op Ultra-settings verschuift de bottleneck immers (nog) meer richting de videokaart.
Metro Exodus
Metro Exodus heeft een ingebouwde benchmark, die we voor deze test hebben gebruikt.
12700K - Belasting per type core
12700K - Aantal cores per type
Ook in Metro Exodus zien we dat het laden de cpu flink belast, de zuinige cores zelfs nog iets meer dan de snelle. Tijdens de rest van de benchmark spelen de zuinige cores een stabiele, maar beperkte rol. Tussen de twee en zes threads behorende bij de snelle cores worden voor meer dan de helft benut.
Conclusie
Het was maar goed dat Intels previewsessie over Alder Lake deze zomer uitsluitend uit slides en spraak bestond. Menige doorgewinterde hardwarejournalist kon een lichte grijns namelijk niet onderdrukken toen de processorfabrikant vertelde dat de scheduler in Windows 11 volledig zou worden geoptimaliseerd voor hybride processors, oftewel cpu's met verschillende soorten cores in een package.
Dergelijke beloften worden eigenlijk al sinds het begin van multicoreprocessors gedaan. Bovendien bleek het toepassen van hyperthreading/smt of het 'snelste core'-principe in de voorbije jaren steevast een garantie voor schedulerheisa. Tot op de dag van vandaag wordt menige game ietsje sneller als je hyperthreading uitzet en draait een singlethreaded workload soms nukkig op een core die volgens de steraanduiding niet de snelste is. Kortom, goede scheduling is makkelijker gezegd dan gedaan.
Goede scheduling was cruciaal voor Alder Lake
Nu ligt normaal gesproken niemand wakker van enkele procenten verlies door suboptimale scheduling, maar voor Alder Lake was goede scheduling opeens cruciaal. De bijna oneindige verzameling Windows-software was natuurlijk niet geschreven met hybride cpu's in het achterhoofd en het is niet moeilijk om de rampscenario's te bedenken waartoe dat had kunnen leiden: zware programma's die vastzaten op de langzame, zuinige cores en virusscanners die nodeloos een onzuinige snelle core wakker hielden.
Die rampscenario's hebben zich niet of nauwelijks voorgedaan; een bokkend drm-systeem van oude games bleek in de praktijk het grootste probleem. Dat is niet alleen te danken aan de naar eigen zeggen vroegtijdige en innige samenwerking tussen Intel en Microsoft, maar ook aan het hardwarematige feedbackmechanisme in Alder Lake. De processor geeft aan de hand van allerlei factoren advies aan het OS over op welke core een thread het beste kan draaien. Wat met 'beste' wordt bedoeld, kan bovendien weer worden aangepast aan de actuele omstandigheden. Je zou kunnen zeggen dat de scheduler er met deze toevoeging een aantal zintuigen heeft bijgekregen.
Belangrijkste conclusies uit de analyse
Het is lastig om harde conclusies te trekken over hoe anders Windows 11 omgaat met de Big.Little-structuur van Arm-processors, omdat de SQ2-chip al snel een factor tien langzamer is dan de geteste x86-processor. Dat feit alleen kan natuurlijk al tot ander schedulinggedrag leiden, maar vooral op basis van de Photoshop-test lijkt de scheduling bij de Arm-soc wat meer te sturen naar de snelle cores dan bij de Intel-processor het geval is. Dat lijkt logisch, want het prestatieverschil tussen de snelle en zuinige cores is bij de SQ2-soc een stuk groter dan bij de Intel-processors.
De scheduling van de x86-processor hebben we veel uitgebreider kunnen analyseren. Het simpelst te duiden is het gedrag in taken die goed schalen naar heel veel threads. Die belasten doorgaans gewoon alle cores, van welk type ze ook zijn. Voorbeelden zijn CoronaRender, 7-Zip en AIDA64. Taken die juist primair singlethreaded zijn, zoals het starten van de meeste software en de Jetstream-browsertest, worden consistent aan een of hooguit enkele snelle cores toebedeeld.
Echt interessant wordt het pas bij taken die daar ergens tussenin zitten, of uit subtaken bestaan die afwisselend wel of niet goed multithreaden. Dat zien we bijvoorbeeld terug bij het compileren van software en videorendering. De scheduler lijkt daar echt andere keuzes te maken op basis van de hardwarefeedback; tijdens het compileren worden de zuinige cores al snel afgeschakeld zodra er geen werk voor ze is, maar tijdens het coderen van video met de x264- en x265-codecs lijken ze juist de voorkeur te krijgen boven de snelle cores als niet alle cores volledig kunnen worden gesatureerd. Games gebruiken de zuinige cores om bepaalde niet-kritieke taken uit te voeren en om de laadtijd te versnellen, maar het belangrijkste, latencygevoelige werk wordt uiteraard op de snelle cores uitgevoerd.
Vooruitblik
Scheduling kreeg lange tijd niet de aandacht die het verdiende, terwijl het in een wereld met steeds meer cores en threads een almaar belangrijkere functie kreeg. Alder Lake lijkt een breekpunt te zijn geweest, want de vernieuwde scheduler in Windows 11 met ondersteuning voor feedback vanuit de hardware lijkt zijn werk heel aardig te doen. Bovendien bleven grote compatibiliteitsproblemen rond de release uit. Als er vooraf te lichtzinnig over deze fundamentele wijziging in de opbouw van processors was gedacht, was dat ongetwijfeld heel anders verlopen.
Intussen lijkt de complete markt het erover eens te zijn geworden dat hybride processors de toekomst hebben. Op Intels roadmap voor de komende jaren zijn geen consumentenchips zonder Big.Little te vinden en ook de komst van een compacte variant van AMD's Zen-core kan, hoewel officieel alleen nog aangekondigd voor servers, moeilijk los van deze trend worden gezien.
Met die informatie is het in elk geval goed om te weten dat de software er klaar voor is. Om de comments van onze trouwe schare Linux-gebruikers voor te blijven; soortgelijke optimalisaties voor dat OS zijn er inderdaad nog niet. Vooralsnog lijkt Intel daar zelfs meer stuk te maken dan te verbeteren. Uit technisch opzicht zal het echter geen zware kluif zijn. Arm-processors met een Big.Little-opbouw werken immers al bijna een decennium vlekkeloos onder Linux, dus als Intel dat wil, kan het dat ook.
@Tomas Hochstenbach
Misschien zie ik iets over het hoofd, maar het grootste deel van de uitgevoerde tests lijkt me niet heel interessant. Neem als voorbeeld de 7Zip benchmark. Ik vind het heel gaaf hoe nauwkeurig jullie kunnen loggen wat alle cores precies aan het doen zijn, maar uiteindelijk komt de test neer op "we geven de processor heel veel werk" met als conclusie "alle cores zijn volle bak aan het werk".
Ehm ja, dat mag ik hopen; elke andere uitkomst zou in feite neerkomen op "Intel en MS hadden dit nog niet mogen releasen". Dit is namelijk zo'n beetje het meest simpele scenario; er is nog wat te schuiven met welke thread op welke core geplaatst wordt, maar uiteindelijk staan ze allemaal te stampen. Dat is toch niet het scenario waarvoor dit ontwikkeld is!? Het hele idee van big/little is "als ik botte rekenkracht nodig heb, dan kan ik een performance core aan het werk zetten; bij een lichte load gooi ik alle power gates van de performance cores open om zoveel mogelijk stroom te besparen, dat kan een efficiency core ook wel opknappen".
Alleen bij de gaming benchmarks komt dat een beetje terug, maar zelfs daar wordt alleen gemeten wat de cores aan het doen zijn, maar niet (waar het mijns inziens echt om draait) wat het energieverbruik is. Met andere woorden, je hebt vooral gecontroleerd "is de scheduler zo hopeloos brak dat Intel en MS zich keihard moeten schamen?" (antwoord: nee), maar geen van deze benchmarks geeft de scheduler de kans om te demonstreren wat ie écht kan.
Ik denk dat er veel interessantere dingen getest kunnen worden. Zomaar twee ideetjes, de eerste zou me echt nuttig lijken om te testen, de tweede is meer een gevalletje "als we toch met cijfers aan het spelen zijn".
Hoeveel zuiniger zijn de efficiency cores en wordt daar goed gebruik van gemaakt? Voor desktops (en laptops die aan de voeding hangen) maakt stroomverbruik niet zo gek veel uit, maar voor een laptop die op zijn accu werkt is een zuinige core wel interessant.
Mijn voorstel zou zijn: pak een laptop, haal die fysiek van de stroom af (de enige manier om zeker te weten dat de scheduler, áls die hier überhaupt rekening mee houdt, zijn "power save settings" gebruikt) en kijk hoelang het duurt om met een lichte workload de accu leeg te trekken (Tweakers heeft een "lichte browser test" die hier vermoedelijk geschikt voor is). Herhaal de test met de zuinige cores uitgeschakeld.
Als ie het met de zuinige cores ingeschakeld flink langer uithoudt (en het liefst, zonder dat de prestaties er heel erg onder lijden) dan met de zuinige cores uitgeschakeld, dan levert de scheduler prima werk. Als er (zowel qua accuduur als prestaties) nauwelijks verschil is, dan haalt de nieuwe scheduler geen voordeel uit het big/little concept.
Probeer eens om te rekenen wat de prestaties zouden zijn geweest als de hele chip was volgebouwd met alleen performance cores. Stel dat een efficiency core ongeveer een kwart van de oppervlakte gebruikt van een performance core *), dan zou een 8+8 core ook een "10+0" core geweest kunnen zijn. **) Vermenigvuldig de benchmark scores met de zuinige cores uitgeschakeld eens met 10/8 en vergelijk dat met de score wanneer alle cores zijn ingeschakeld. Als het niet heel ver uit elkaar loopt: prima. Maar als het heel veel hoger (of juist lager) is, dan hebben ze een rare keuze moeten maken.
*) Dit rekent niet alleen makkelijk, als ik op WikiChip kijk, en dan vooral deze die shot, dan klopt het ook nog... ruwweg.
**) Ik realiseer me dat dit een nogal grove benadering is, maar voor een nauwkeurige analyse zul je ontzettend geheime, interne Intel-data nodig hebben en die willen ze vast niet geven.
Poeh, dat zijn een hoop interessante vragen, maar ik ga deze zondagmiddag toch m'n best doen om er wat licht op te schijnen.
Niet alle 'uitslagen' van het coregebruik zijn inderdaad even spannend, en voor een aantal tests (7-Zip en CoronaRender) had ik dat ook best durven voorspellen. Toch heb ik ze opgenomen in het artikel, want het is goed om te laten zien dat dergelijke workloads bestaan. Bovendien bewijst het een belangrijk punt van Intel, namelijk dat goed multithreaded loads net zo makkelijk de (efficiëntere) kleine cores belasten als de grote. Tegelijk zijn er ook een aantal tests waarvan je misschien zou verwachten dat die alle cores volledig belasten, zoals de compileertest, videorendering en transcoding met x264/x265, die dat in de praktijk niet (continu) doen.
Uiteindelijk zorgen maar twee van de twaalf geteste workloads ervoor dat alle cores 'staan te stampen'. Zelfs in zo'n scenario kan een Big.Little-config sneller zijn, doordat hij efficiënter is en dus meer prestaties uit het beschikbare powerbudget kan persen. Dat sluit mooi aan bij je laatste suggestie, want dat kun je inderdaad prima uitrekenen als je een test gebruikt die de facto oneindig schaalt naar meer cores. Zowel een snelle Golden Cove-core als een cluster van vier zuinige Gracemont-cores nemen ordegrootte 5mm² in beslag, dus qua die size had de 8+8-core inderdaad een 10+0-core kunnen zijn.
Laten we dat scenario eens uitrekenen op basis van de Cinebench-data op p4. Een 10+0 core zou 19264/8*10=24080 punten halen, bijna 12 procent minder dan een Core i9 12900K (8+8). Wat je in theorie ook zou kunnen doen, is alle snelle cores vervangen door clusters van vier zuinige cores. Dan krijg je dus een 0+40-processor met 3799/4*40=37990 punten. Kortom, de zuinige cores leveren 37990/24080*100=158% van de prestaties van dezelfde die size gevuld met snelle cores. Ik heb helaas geen cijfers paraat van het stroomgebruik per type core - de logfiles die ik voor dit artikel heb gebruikt bevatten dat in ieder geval niet, dus het zou kunnen dat dat softwarematig überhaupt niet uit te lezen is - maar normaal gesproken moeten de kleine cores naast de area efficiency ook de power efficiency gemakkelijk kunnen winnen.
Dan denk je natuurlijk: kom maar door met die 0+40-core! Het feitje van hierboven, dat slechts twee van de twaalf tests alle soorten cores volledig wisten te belasten, komt hier echter weer terug. Veel software kan dat simpelweg niet en daarvoor wil je altijd een paar cores hebben die een hoge singlethreaded performance kunnen leveren, ook al doen ze dat minder efficiënt, zowel qua oppervlakte als qua stroomgebruik. Intels hypothese is dat acht cores daarvoor altijd voldoende is; bij opvolger Raptor Lake zou het aantal snelle cores gelijk blijven, maar het aantal zuinige cores verdubbelen naar zestien.
Je testconcept met een laptop is in theorie heel interessant, maar praktisch niet uitvoerbaar. Naast dat er as we speak nog geen laptops met een Alder Lake-cpu zijn, ken ik geen laptopfabrikant die je in het bios cores laat uitschakelen, zoals dat op de meeste desktopmoederborden wel kan.
Zelfs in zo'n scenario kan een Big.Little-config sneller zijn, doordat hij efficiënter is en dus meer prestaties uit het beschikbare powerbudget kan persen. Dat sluit mooi aan bij je laatste suggestie [..]
Denk je eraan je eigen post te bookmarken? Wat je hier net typt zou best de basis kunnen zijn voor een leuke paragraaf in het volgende artikel over big/little op x86.
Dat 40 effciency cores beter presteren dan 10 performance cores verbaast me niet (als performance blijft schalen met chip-oppervlak, dan hadden ze wel een 50 GHz singlecore CPU gebouwd), maar je hebt een heel goed punt: dan moet je workload wel over 40 cores te spreiden zijn.
Je testconcept met een laptop is in theorie heel interessant, maar praktisch niet uitvoerbaar. Naast dat er as we speak nog geen laptops met een Alder Lake-cpu zijn, ken ik geen laptopfabrikant die je in het bios cores laat uitschakelen, zoals dat op de meeste desktopmoederborden wel kan.
Oh sorry, daar had ik helemaal niet bij stilgestaan op het moment dat ik dat typte. Met de recente DRM-problemen denk ik echter dat er een kansje is dat laptop-fabrikanten deze mogelijkheid te zijner tijd toch aanbieden op Alder Lake laptops.
Het alternatief is natuurlijk om een desktop te gebruiken; Windows 11 laat me, zelfs op desktop, bij "Power mode" kiezen tussen "Best power efficiency", "Balanced" en "Best performance".
Daar komt nog bij dat de test met premiere pro totaal onnuttig is. Premiere gebruikt namelijk de cuda cores van de NVidia video kaart. Als je première op software encoding zet dan gebruikt hij zeker alle cores op 100%.
Je aanname dat we testen met gpu-acceleratie klopt niet; de Premiere Pro-test is met cpu-only encoding. En die weet dus niet continu alle cores volledig te satureren.
Ik heb op mijn machine nog even getest. Je moet wel in premiere, bij de uitvoer settings onder "Encoding Settings", "Software Encoding" kiezen in het veld "Performance". Als je alleen in de project settings "Mercury Playback Engine Software Only" kiest dan wordt alsnog de NVIDIA kaart voor het grootste deel belast.
Als ik "Software encoding" in de uitvoer settings kies dan worden mijn 12 threads onder Win 11 allemaal nagenoeg 100% belast en blijft mijn NVIDIAkaart nagenoeg onbelast.
Ik heb overigens geen Big/Little processor maar nog een Gen 10 Core I7 10750H.
[Reactie gewijzigd door Verwijderd op 22 juli 2024 14:15]
Dat lijkt me heel complex. Het grootste probleem daarmee zal zijn dat software die is gecompileerd voor een van die architecture niet op de andere kan draaien.
En dat geldt dan vooral ook tijdens het draaien. Je kan dan dus niet zomaar - misschien wel helemaal niet - een proces van de ene CPU naar de andere CPU verhuizen. Zelfs niet (zomaar) als je 't proces - inclusief al z'n threads - helemaal zou pauzeren en dan een versie van de andere architectuur zou opstarten. Dan loop je o.a. tegen het feit aan dat instructies e.a. ook in het RAM staan en er vast ook verschillen zijn in hoe CPU's de boel in het RAM plaatsen.
Je zou dan in de praktijk denk ik vooral een situatie krijgen waarbij je je software dan start op een van de CPU's waarvan je geschiket binaries hebt en dan ook op die CPU blijft.
In de praktijk komt het overigens wel voor; de GPU's zijn er al een heel gebruikelijk voorbeeld van. En zo zijn er wel meer processors voor speciale taken (bijvoorbeeld encryptie of netwerktaken offloaden). Maar de main cpu in meerdere smaken uitvoeren lijkt me vooral een hoop gedoe.
Ik bedoel niet zozeer dat elke core beide architecturen ondersteunt (een CPU heeft tegenwoordige meerdere cores) en via een config setting of de een of de ander doet. Maar dat je arm en intel cores hebt die altijd alleen maar arm of intel cores kunnen zijn.
Die opzet zal denk ik vooral op praktische bezwaren stuiten. Je moet dan alsnog een OS hebben dat meerdere architecturen tegelijk ondersteunt. En tenzij de cpu's allemaal hun eigen ram, pci-controllers etc hebben, zal er ook in die hardware ondersteuning moeten zijn voor het feit dat er meerdere zijn. En als ze wel eigen versies daarvan hebben, dan heb je uiteindelijk effectief twee losse computers.
Is het dan die moeite waard? Wat zou het voordeel zijn om zoiets te doen?
In de praktijk is dat natuurlijk al het geval, je SSD heeft een ARM of RISC-cpu, je netwerkkaart heeft wat ARM-cores, je videokaart is zo'n beetje een volledig losstaande computer en je (intel) CPU heeft een eigen losse Quark cpu aan boord met daarop een eigen OS (MINIX 3) voor zijn management engine en je x86 AMD cpu heeft ook een ARM cpu voor zijn secure enclave.
Met het opschalen van het aantal cores in een CPU zul je sowieso tegen dat soort problemen aan gaan lopen. Wat dat betreft lijkt het mij dat we steeds meer gelaagde kernels gaan zien. Een low level kernel die echt de hardware aanstuurt en mid-level kernels die met gevirtualiseerde hardware werken. Dat zie je nu ook al met WSL. Dus ik denk dat dit vanuit het perspectief van OS niet het grootste probleem zal zijn.
Meerwaarde zit voornamelijk in dat de barrière van switchen van intel naar arm of risc-v of iets anders lager komt te liggen. Waardoor er ook makkelijker geïnnoveerd kan worden. De intel architectuur zit nog met allemaal kronkels opgescheept van hoe het ooit gewerkt heeft. Dat geeft bedrijven ook eens een kans iets nieuws te doen zonder dat alles steeds flopt want legacy.
Is het dan niet handiger om een accelerator met cores gebaseerd op een andere instructieset via CCIX of CXL met de host processor te laten communiceren?
Ik weet dat er in ARM SoC's veelal DSP's aanwezig zijn gebaseerd op VLIW cores (Hexagon in Qualcomm Snapdragon), maar vraag me af in hoeverre hiervan bij Intel en AMD processors sprake is.
Software met JIT compilers (.NET en Java) zouden natuurlijk wat werk uit handen kunnen nemen. Maar ik ben het er mee eens dat het onwaarschijnlijk is dat dat ooit zal komen.
Als ontwikkelaar wordt ik wel blij van de big/little architectuur. Mijn software is meestal zwaar multi threaded, en bevat meestal vooral veel backgroundthreads voor monitoring, logging en communicatie met hardware. Afhankelijk van hoe de scheduler het uiteindelijk doet, blijft er meer performance over voor wat dat echt nodig heeft en draait mijn software idle met een lager energieverbruik. Win/win dus!
Dat vereist dan wel dat elke programmeertaal die complexiteit moet ondersteunen. Wat de doorontwikkeling van programmeertalen weer in de weg staan. Maar ergens kan er natuurlijk een balans getroffen worden tussen de hardware alles te laten doen of de software alles te laten doen. De geschiedenis leert in ieder geval dat we softwarematig alles kunnen oplossen. Maar dat je toch weer hardware acceleratie nodig gaat hebt om het performant te krijgen. Persoonlijk zal ik dan eerder richting een factory interface gaat. Dat je de core machinecode voedt in de machinetaal die je ondersteunt. En dat de hardware (eventueel via microcode), de gewenste machinecode er uit spuugt in het geheugen die de core echt ondersteunt. Duurt het laden iets langer maar ben je daarna van het hele gedonder af.
Ik ben benieuwd wat jij als voordeel ziet van zo'n multi-architectuur. Wat kan er nu niet of lastig dat met een multi-architectuur mogelijk of makkelijker wordt?
Als in een sales pitch!? Dat is niet mijn afdeling. Maar ik kan mij wel voorstellen dat het interessant kan zijn. Waarom zou je een OS willen hebben dat zowel Windows, Linux en Android apps kan draaien. Maar als het dat kan waarom zou je het dan niet nemen?
Stel je voor dat je een CPU op de markt is die meerdere architecturen goed ondersteunt? Zou je het kopen?
Een sales pitch gaat misschien wat ver. Maar een use case zie ik nog niet. Voor het draaien van Windows, Linux en Android apps is een multi-architectuur niet nodig. Wat daarvoor nodig is is integratie op het niveau van het OS. Ik denk daarbij bijvoorbeeld aan WSL in Windows dat Linux integratie in Windows (beperkt) mogelijk maakt. Volgens mij is er pas een multi-architectuur nodig als software exclusief voor 1 architectuur gemaakt wordt. Over een paar jaar zal dit gelden voor de Apple Silicon architectuur. Maar juist Apple zal geen interesse hebben in een multi-architectuur en proberen te voorkomen dat Apple Silicon onderdeel wordt van zo'n multi-architectuur. Zie jij use cases waarbij de multi-architectuur iets voor jou mogelijk maakt?
My $.02: technisch is een multi-architectuur heel leuk en interessant, maar ik denk niet dat het levensvatbaar is. Ik zou het kopen als het een probleem oplost waar ik geld voor overheb. Op dit moment kan ik mij niet voorstellen welk probleem dat zal zijn. Dat zegt natuurlijk niet dat ik niet alsnog te overtuigen ben.
ik kan mij wel voorstellen dat het interessant kan zijn.
Alleen maar "interessant" is niet genoeg; wat je voorstelt is gruwelijk ingewikkeld. (En dan heb ik het alleen over de technische kant; het juridische verhaal over allerlei rechten wordt nog een aparte nachtmerrie.) Waarom rijdt de NS met trainen die alleen op rails kunnen rijden; ik kan mij wel voorstellen dat het interessant kan zijn als ze ook gewoon de weg op kunnen of vleugels uitklappen en een stukje vliegen.
Ik ben het echt nog wel met je eens dat het gaaf klinkt, maar als het nergens goed voor is... waarom zou iemand het dan ontwikkelen? Als je een toepassing kunt bedenken waarmee levens gered kunnen worden of miljarden euro's verdient kunnen worden (ja, miljarden; als je niet verder komt dan een paar miljoen dan is het de moeite niet waard), dan gaat er misschien iemand naar kijken, maar als je al geen sales pitch kunt verzinnen, dan gaat gegarandeerd niemand hier moeite in steken.
Overigens, zelfs al zou je software in twee verschillende instructiesets op één fysieke machine willen draaien (daar kan ik nog wel een aantal toepassingen voor verzinnen, al zijn ze allemaal nogal niche), dan moet de eerste vraag zijn: kunnen we hardware gebruiken die één van die twee instructiesets echt ondersteunt en de andere emuleert?
Stel je voor dat je een CPU op de markt is die meerdere architecturen goed ondersteunt? Zou je het kopen?
Sorry voor het beantwoorden van een rhetorische vraag, maar als het een euro duurder is dan een CPU die alleen de architectuur ondersteunt die ik daadwerkelijk nodig heb: nee. Ik bedoel, stel je voor dat er een CPU op de markt is met een poort waarop je een ponskaartlezer aan kunt sluiten. Zou jij die kopen?
Btw, ik ga er even vanuit dat je een processor in gedachte hebt die "gewone programma's" kan draaien die geschreven zijn in meerdere instructie sets. Want bijvoorbeeld AMD processors bevatten al tijden een ARM core die dienst doet als de Platform Security Processor. Daar kun je echter niet je eigen ARM code op draaien, dus die tel ik even niet mee. Intel heeft iets soortgelijks (de Intel Management Engine), maar die draait op een extra (en heel erg uitgeklede) x86 core.
Ik heb een paar vragen met betrekking tot de alderlake/Big little set up van Intel, waarom zijn ze hier mee begonnen? ( zijn de E cores goedkoper te produceren ten op zichte van de P cores? ) en is dat de reden? En wij als consumenten hebben hier toch niet om gevraagd voor de desktop? of zie ik dat verkeerd? Volgens mij zal een meerderheid toch liever alleen P cores hebben voor de desktop of zie ik dat ook verkeerd? ben benieuwd naar reacties
Een groot deel van de tijd is de CPU in mijn desktop weinig belast, als ik dan met de E-core een lager verbruik kan krijgen, ben ik daar zeker voor te vinden.
De crux voor 'Big.Little' op desktop is dat de kleinere cores efficiënter kunnen multithreaden. Het belangrijkste argument van Intel is dus dat er uit dezelfde ruimte, zowel fysiek op de die als in het stroombudget van de processor, meer prestaties kunnen worden gehaald met een combinatie van zuinige en snelle cores dan met uitsluitend snelle cores. Lees voor meer vooral de pagina daarover uit onze Alder Lake review nog eens terug.
Goed artikel! Erg gaaf dat de scheduler in de praktijk net zo goed werkt als de theorie het voorstelt. In principe kun je er gewoon op vertrouwen dat het goed werkt.
Als ik het artikel zo lees dan krijg ik het gevoel dat de energiezuinige cores eigenlijk ongewenst zijn (voor mij). Alle testen zijn gericht op belasting creëren waarbij de power cores duidelijke meerwaarde opleveren. Voor het soort taken uit de testen zou ik liever meer power cores hebben in plaats van een processor met ook een paar energiezuinige cores. Wat mij interesseert is voor wat voor processen de energiezuinige cores net zo goed zijn, en of ze daar dan ook voor gebruikt worden als er weinig belasting is. Een complete virusscan die op de achtergrond loopt zou b.v. prima op energiezuinige cores kunnen lopen terwijl een scan bij het openen van een bestand waarschijnlijk zo snel mogelijk klaar moet zijn. Maar dit wordt vast snel ingewikkeld.
Voor een laptop zou het misschien ook interessant zijn om meer op de energiezuinige cores te laten draaien als je kiest voor maximale batterijduur.
Ik zie het als meerwaarde, echter mag het stroomverbruik nog wel flink naar beneden. Apple had met de M1 natuurlijk een topper te pakken, Intel doet daar nu een schepje bovenop. De 12900k is een heel mooi stukje techniek. Nu wachten op de volgende iteratie waarbij je in de piek niet zoveel stroom verbruikt. Doet me denken aan de AMS-FX62. Was destijds een top CPU met bijkomend stroomverbruik.
Mooi stukje achtergrond om zo te lezen en dat Windows 11 de vruchten weet te plukken. Helaas zal het niet simpel zijn om dit met een Windows 10 update te doen. Wellicht wat optimaliseren maar geen volledige ondersteuning voor de e-cores hoe ze bedoeld zijn.
De Linux kernel heeft ook al fixes gehad voor issues met de big-little architectuur. Hier een interessant artikel over de Linux kernel (5.16) en Alderlake processoren: https://www.phoronix.com/...x-5.16-Lands-ADL-ITMT-Fix
De Windows scheduler problemen doen zich niet alleen voor met een Alderlake processor. Ook op mijn i7 11700K (bij een fikse x265 render job) krijg ik geen 100% saturatie, wat ik ook doe. Alleen Core 0 en 1 krijgen full load, the anderen lopen dan op ca. 80%.
Wat betreft Photoshop, iets waar je rekening mee moet houden is dat sommige filters via de GPU (OpenCL) worden berekend. Ook leunt Photoshop enorm op rekensnelheid en het geheugen. Een paar jaar geleden lag de sweetspot bijvoorbeeld op een 8 core processor. Alles daarboven gaf geen prestatiewinst en was een aanslag op de portemonnee. Investeren in een snellere 6 core / 8 core cpu en meer geheugen gaf een flinke boost.
Sinds Apple naar ARM is overgestapt ben ik weer geïnteresseerd geraakt om te switchen. Mijn dagelijks werk is illustreren en foto's bewerken in Photoshop. En het opnemen van video's. Tot dusver lijken de M1 chips dit stil, koel en zuinig te kunnen doen. Inclusief een krachtige ingebakken gpu.
Het is heel interessant om te zien hoe de markt zich nu lijkt te bewegen in deze twee landschappen van x86 en arm. En ben ik benieuwd of in de PC wereld arm ook meer ruimte gaan winnen en hoe programma makers daar op reageren.



/i/2004830162.png?f=imagearticlefull)

:fill(white):strip_exif()/i/2004735394.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/2004890500.jpeg?f=thumbmedium)
/i/2006296056.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005190534.jpeg?f=fpa_thumb)
/u/580347/crop5dc26a60e5d26_cropped.png?f=community)
:strip_icc():strip_exif()/i/2004582430.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004764144.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004374656.jpeg?f=fpa_thumb)
:strip_exif()/i/2005990290.jpeg?f=fpa)
:strip_exif()/i/2004677808.jpeg?f=fpa)
/i/2004611214.png?f=fpa)
:strip_exif()/i/2004729486.jpeg?f=fpa)
/i/1309767168.png?f=fpa)
:strip_icc():strip_exif()/u/287731/crop6270fa65746ea_cropped.jpg?f=community)
/u/1830/acm.png?f=community)
/u/8/oog3.png?f=community)
/u/244207/crop5c38ae2351fe1.png?f=community)
/u/211309/crop61b0ff95cd8ef.png?f=community)
:strip_icc():strip_exif()/u/924215/crop59407a956b5c8_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/150861/crop5db2e8884bf34_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/6607/klootviool2.jpg?f=community)
:strip_exif()/u/119562/gunther.gif?f=community)
/u/268819/crop632d8f33526bb_cropped.png?f=community)
{kind=link}