
Simpel gezegd kan compressie, en dus beduidend kleinere filmbestanden, alleen gerealiseerd worden door niet alle informatie tot op de pixel nauwkeurig voor elk frame in kaart te brengen. Er moet als het ware informatie genegeerd worden. Daarmee is de compressie doorgaans lossy; het eindresultaat voor de consument is een benadering van de originele content en zal niet exact dezelfde kwaliteit hebben als het origineel. De efficiëntie van compressiemethodes, de effectiviteit van de toegepaste algoritmen en de mate van informatie die wordt genegeerd, zijn grofweg bepalend voor het kwaliteitsverlies ten opzichte van het ruwe materiaal.
Hoe gaat de compressie in zijn werk en hoe zijn daar verbeteringen in aan te brengen? We willen niet vervallen in een gedetailleerde bespreking van de combinaties van verschillende technieken en de achterliggende complexe wiskunde. We kijken slechts hoe standaardcompressietechnieken in beginsel werken en hoe dat proces bij h264 en veel andere codecs is verbeterd.
Voorspellende gaven
Stel je een denkbeeldige scène uit een video voor, waarbij de camera stilstaat en is gericht op een boom waaraan een bonte specht zich vastklampt en met zijn snavel af en toe in de boomstam hakt. In het eerste frame is de vogel nog met zijn kop van de stam verwijderd, maar in het volgende frame zit ie al met zijn snavel tegen de boomschors. In dit voorbeeld heeft alleen de vogel bewogen. De rest, zoals de boom, de lucht en de takken op de achtergrond, is grotendeels onveranderd tussen de twee frames. Zonder compressie zouden volledige beschrijvingen van de scène in beide frames moeten worden worden verstuurd. Met compressietechnieken valt de beeldinformatie in elk frame weliswaar te comprimeren, maar moet nog altijd behoorlijk wat data worden verstuurd. Dat komt mede doordat elk frame afzonderlijk wordt gecomprimeerd, ook al haalt het tweede frame nogal wat informatie uit het eerste.


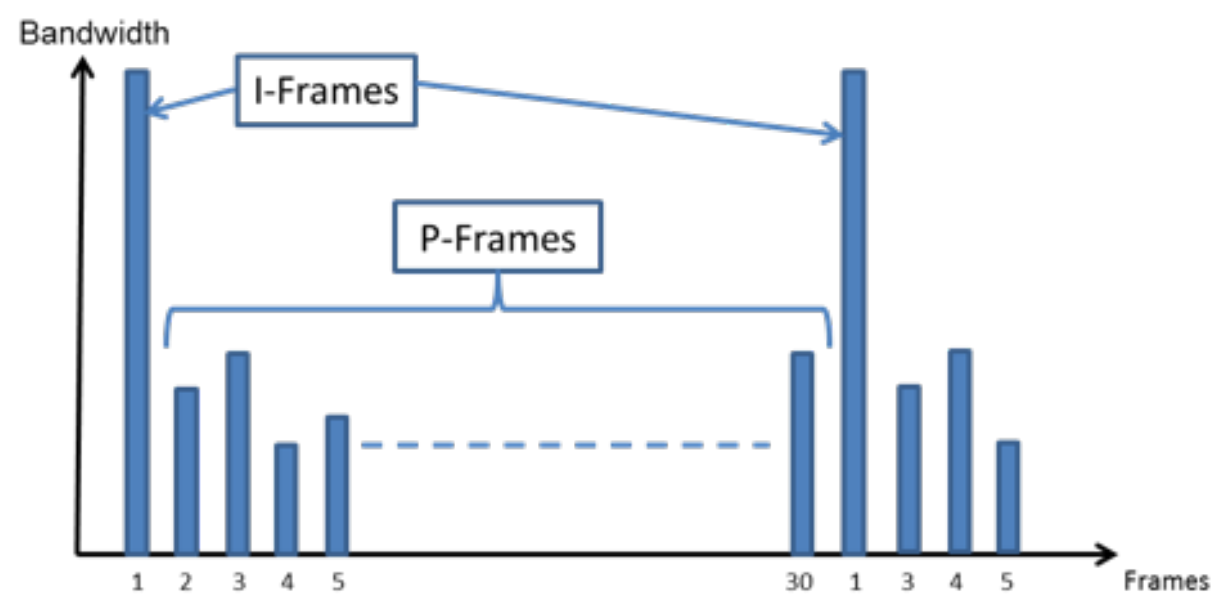
Die herhaling en de daarmee gepaard gaande extra data is eigenlijk overbodig, want in deze specifieke scène hoeft alleen rekening gehouden te worden met de beweging van de specht. Om compressie op basis hiervan mogelijk te maken, vormt het eerste frame de basis. Dit wordt ook wel het I-frame, keyframe of referentieframe genoemd. Na het decoderen van dit frame kan het volledige beeld worden weergegeven. Het staat dus op zichzelf en is niet afhankelijk van andere frames. Het tweede frame met de specht die op de boomschors inhakt, staat niet op zichzelf en is gebaseerd op het I-frame. Dit wordt het P-frame genoemd met de p van predictive. Dit frame is gebaseerd op een voorspelling vanuit het vorige frame. In plaats van het hele beeld te versturen, wordt bekeken welke gebieden zijn veranderd ten opzichte van het vorige beeld. Zijn er delen die niet veranderd zijn, zoals in dit geval het grootste deel van de boom en de achtergrond, dan wordt die informatie niet opgeslagen of verzonden. Bij de delen waar wel verandering is, volgt compressie. Dan zijn er ook nog B-frames, die wat beeldinformatie betreft zijn gebaseerd op eerdere en toekomstige frames.
Macroblocks
Dat negeren van de beeldinformatie ten opzichte van eerdere frames gebeurt door een frame op te delen in vakjes, ofwel macroblocks. Zie het als een raster dat over het frame wordt geplaatst. Bij een P-frame wordt geanalyseerd welke blocks wel en niet zijn veranderd. Bij geen verandering worden die blocks niet verwerkt. De blocks die wel zijn veranderd, worden gecomprimeerd. Op deze manier kan bij het tweede frame een aanzienlijke hoeveelheid data worden bespaard, oplopend tot 80 procent of meer.
Verbeteringen bij h265 ten opzichte van h264
Dit concept vormt de basis van h264, waarbij de individuele blocks een formaat van maximaal 16x16 pixels kunnen hebben. H265 gebruikt ook nog steeds de blocks als basis en gebruikt verder een vergelijkbare aanpak bij het coderen, maar verbetert de prestaties van voorganger h264 onder meer door meer flexibiliteit bij de blocks toe te passen. Het maximale formaat is bij h265 een stuk groter en gaat tot 64x64 pixels. Deze blocks worden bij h265 coding tree blocks genoemd, omdat ze kunnen worden onderverdeeld in subgedeeltes. Een ctb van 64x64 kan bijvoorbeeld worden verdeeld in vier blocks van 32x32, die op hun beurt zijn te verkleinen in blocks van 16x16 of 8x8. Deze kleinere blocks binnen een ctb worden coding units genoemd. Deze kunnen vervolgens weer worden opgedeeld in transform units van 32x32, 16x16, 8x8 of 4x4. Deze units vormen de basiseenheid voor de voorspelling binnen de h265-compressiestandaard.
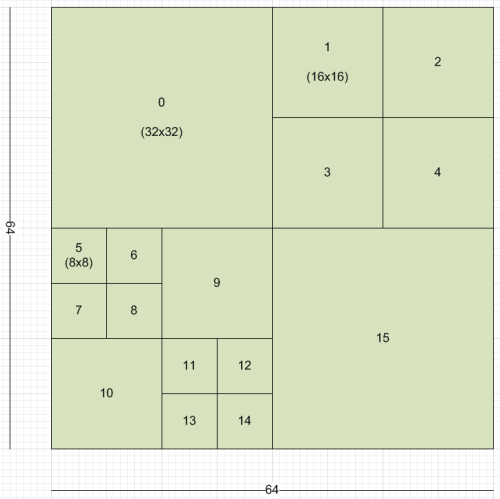
Grotere ctb's leiden tot een hogere efficiëntie, maar vergen ook meer codeertijd. Die hogere efficiëntie komt voort uit de hogere mate van flexibiliteit die coding en transform units mogelijk maken. Kleine units worden vaak gebruikt bij gedetailleerde gebieden, zoals hoeken van objecten, terwijl grotere units vaak gebruikt worden om egale gebieden of gebieden met weinig beweging te voorspellen. Door de grotere ctb's en de kleinere units zijn meer vormen mogelijk en kan een codeersysteem een beeld veel efficiënter opbreken in grote blocks, terwijl waar nodig kleinere blocks worden ingezet voor de fijne details. Dat levert een flinke besparing in de bandbreedte op en leidt door de optie van kleine units voor de details niet tot een verslechtering van de beeldkwaliteit ten opzichte van h264.
:strip_exif()/i/2003740750.jpeg?f=imagegallery)
Een andere belangrijke verbetering ten opzichte van h264 is de manier waarop h265 inspeelt op bewegende objecten. Door effectief in te spelen op beweging kan ook aanzienlijk worden bespaard op de bandbreedte of opslagruimte. Stel dat er in een video een auto voorbijrijdt. Bij een stilstaande camera beweegt alleen de auto in een serie frames. Grote delen van het beeld zien er dan vaak in opeenvolgende frames hetzelfde uit, alleen zijn bepaalde delen naar een nieuwe positie verschoven. De koplampen van de auto zitten bijvoorbeeld net in een ander block ten opzichte van een vorig frame.
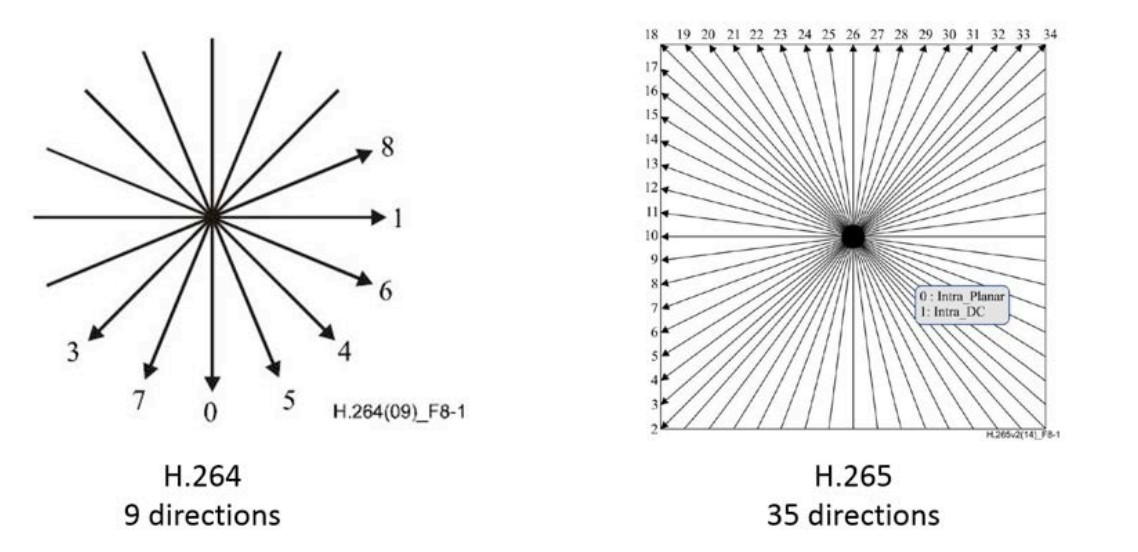
De richting van die verschuiving wordt aangeduid als de motion vector. Het gaat hier om intra prediction: het proberen om informatie te halen uit de omliggende blocks. Het valt echter niet altijd mee om die overeenkomende blocks precies te laten overeenkomen tussen de verschillende frames, dus is het ook nodig om kleine veranderingen bij een block door te geven. H264 heeft maximaal negen richtingen om de beweging van een block aan te geven, terwijl dat er bij h265 in totaal 34 zijn. Door de negen richtingen bij h264 lukt het lang niet altijd om de beweging exact te beschrijven en moeten vaak kleine aanpassingen worden doorgegeven. De 35 richtingen om blockbewegingen door te geven bij h265 maken dat proces veel preciezer en dus hoeft er minder informatie te worden doorgegeven voor het beschrijven van veranderingen of afwijkingen.
/i/2005626858.png?f=fpa)
/i/2005017354.png?f=fpa)
/i/2004791476.png?f=fpa)
/i/2004620250.png?f=fpa)
/i/1316076409.png?f=fpa)
:strip_exif()/i/1273482314.jpeg?f=fpa)
/i/2001904313.png?f=fpa)
/i/1317305413.png?f=fpa)
/i/1333367498.png?f=fpa)
/i/2003706442.png?f=fpa)
:strip_exif()/i/2003046176.jpeg?f=fpa)
/i/2002201373.png?f=fpa)
/i/2000609487.png?f=fpa)
:strip_exif()/i/1404378176.jpeg?f=fpa)
/i/1388770794.png?f=fpa)