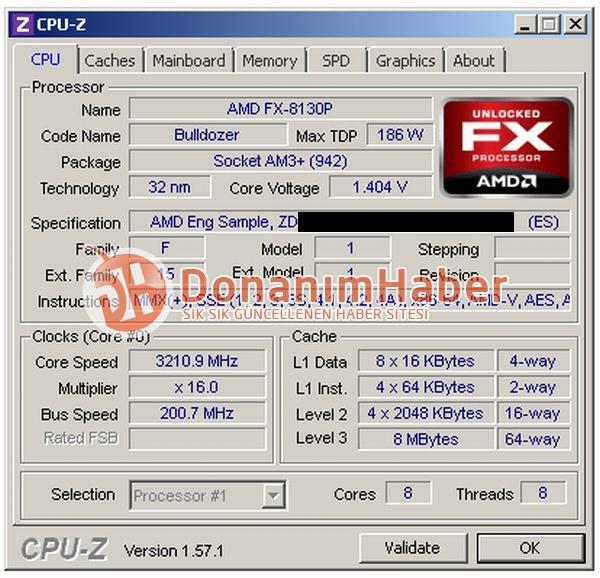
De Turkse website Donanimhaber heeft een engineering sample van een AMD Bulldozer-octacore weten te benchmarken. De sample had een kloksnelheid van 3,2GHz en werd samen met 4GB ddr3-geheugen en een GTX580-videokaart getest.
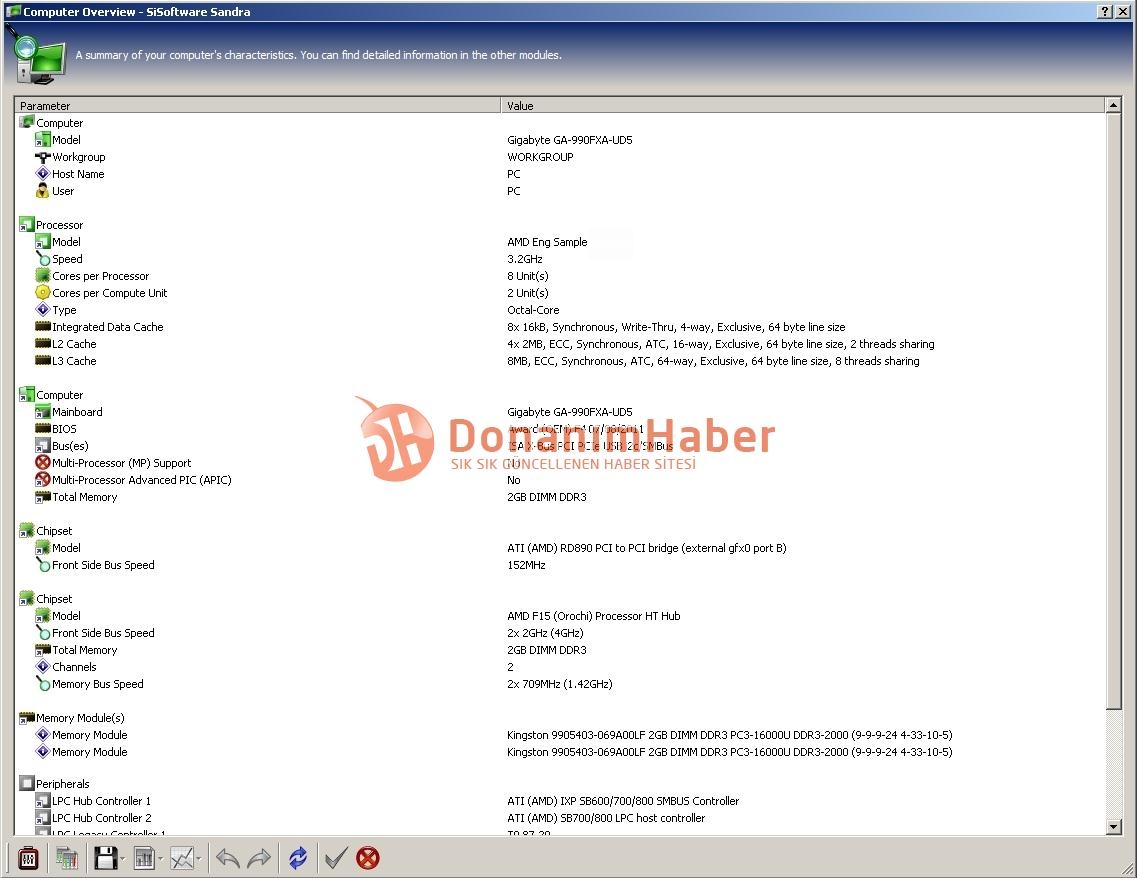
:fill(white)/i/1273567304.jpeg?f=thumb "Amd logo 2") Donanimhaber prikte de onderdelen op een Gigabyte 990FX-UD5-moederbord en onderwierp ze vervolgens aan enkele benchmarks. De achtkoppige engineering sample had een kloksnelheid van 3,2GHz.
Donanimhaber prikte de onderdelen op een Gigabyte 990FX-UD5-moederbord en onderwierp ze vervolgens aan enkele benchmarks. De achtkoppige engineering sample had een kloksnelheid van 3,2GHz.
In 3DMark 11 wist de Bulldozer-cpu in combinatie met de GTX580 een score van 6265 punten neer te zetten, vergelijkbaar met een Core i7 2600 van Intel, die een kloksnelheid van 3,4GHz heeft.
Bij PCMark 7 werd een totaalscore van 3045 punten genoteerd, met 4310 punten in het cpu-intensieve Computation-subonderdeel. Daarmee was de sample in die specifieke subtest iets sneller dan een Intel 2500K op 3,3GHz.
De cpu wist de SuperPi-benchmark, waarin het getal pi zo snel mogelijk tot een miljoen cijfers achter de komma berekend wordt, in 19,5 seconden te doorlopen. Recente Intel-cpu's hebben daarvoor, op een vergelijkbare kloksnelheid, ongeveer de helft van de tijd nodig.
Cpu-z geeft aan dat de processor een tdp van 186W heeft, maar vermoedelijk klopt die waarde niet. Volgens AMD krijgen de nieuwe chips een maximaal tdp van 125W.
Omdat het om een engineering sample gaat, kunnen nog weinig conclusies getrokken worden uit de scores. In het derde kwartaal van dit jaar, als AMD zijn nieuwe, op de Bulldozer-architectuur gebaseerde cpu-lijn introduceert, wordt pas echt duidelijk hoe de nieuwe chips afsteken tegen het aanbod van Intel.




:strip_icc():strip_exif()/i/1318405457.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/1318254838.jpeg?f=fpa_thumb)
/i/1311233526.png?f=fpa_thumb)
/i/1314184240.png?f=fpa)
/i/1300092790.png?f=fpa)
:strip_exif()/i/1295600046.gif?f=fpa)
/i/1241443636.png?f=fpa)
/i/1252595503.png?f=fpa)
/i/1253627114.png?f=fpa)
/i/1305885688.png?f=fpa)
/i/1251207549.png?f=fpa)
/u/175440/crop5b5f0d899a5e8_cropped.png?f=community)
:strip_icc():strip_exif()/u/83337/countess6-nice.jpg?f=community)
/u/180271/av.png?f=community)
/u/203831/ts2.PNG?f=community)
/u/18715/1.JPG?f=community)
:strip_icc():strip_exif()/u/105829/crop5dafb3f448ec1_cropped.jpeg?f=community)
/u/122723/crop57c6099178a15.png?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/159609/caffeine_is_the_shit_60x60.shkl.jpg?f=community)
:strip_icc():strip_exif()/u/61660/crop66280cd1bbb54_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/346437/evil.jpg?f=community)
:strip_icc():strip_exif()/u/301226/Noblelogo_60.jpg?f=community)
/u/166246/unixCopy.JPG?f=community)
/u/192123/Amiga%2520boing%2520cropped%2520to%252060x60.png?f=community)
:strip_icc():strip_exif()/u/348588/crop607373081ef34_cropped.jpg?f=community)
:strip_exif()/u/35573/0sm.gif?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/116283/crop5814e3224425d_cropped.jpeg?f=community)
{kind=link}