Het is geen redriver, het is een
clock buffer. Deze zit fysiek tussen de CPU en de individuele geheugenchips, dus bij definitie zal deze chip ook actief zijn in een AMD-systeem - hoewel wellicht niet met de ideale instellingen.
DDR5 heeft een databus met een breedte van 64 bits. Op een
traditioneel geheugenstickje zijn dat fysiek bijvoorbeeld 8 chips, die elk verantwoordelijk is voor een 8-bit breed stukje van de databus. Iedere chip heeft dus zijn eigen dataverbinding direct naar de CPU, waardoor er superhoge snelheden te halen zijn.
Maar, er moeten ook controlesignalen naar de module gestuurd worden - en deze moeten naar
alle chips gaan. Hierdoor moet de CPU op deze pins niet één chip aansturen, maar acht! Dit zorgt voor een hogere belasting, en het indirecte signaal is gevoeliger voor dingen als interferentie en reflecties. En tot overmaat van ramp komt het kloksignaal ook nog eens op nét wat andere momenten aan bij de individuele chips...
Bij consumenten-geheugen maken ze nu dus gebruik van een "Client Clock Driver (CKD, vraag mij niet waar de K vandaan komt)". Dit is een chip die het kloksignaal ontvangt van de CPU, stabiliseert, en vermengvuldigt naar de individuele geheugenchips. Hierdoor hoeft de CPU maar één chip aan te drijven in plaats van acht, en de geheugenmodule kan zelf compenseren voor de fysieke lengte van klokbron naar geheugenchip. Ook is het minder gevoelig voor verstoringen: de CKD heeft een eigen interne klok, die net als een schommel iedere keer een "zetje" krijgt van de CPU-klok. Daardoor lopen ze in fase en frequentie gelijk, maar hebben kleine variaties op de klok-invoer geen invloed op het uiteindelijke kloksignaal.
De andere controlepins spelen met hetzelfde verhaal, maar zijn veel minder kritiek. Hoewel er maar één inkomend kloksignaal is, is DDR5 intern onderverdeeld in twee subkanalen van 32 bits. De controle-signalen hoeven daardoor maar naar de helft van de chips te gaan - en zijn sowieso al minder storingsgevoelig dan het kloksignaal. Maar bij
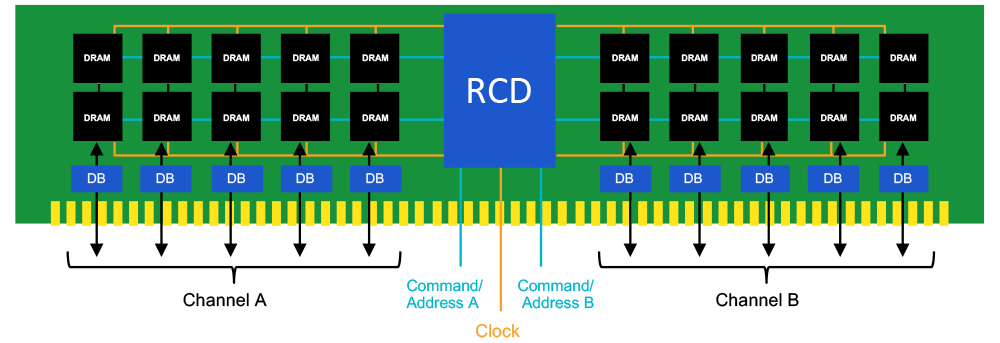
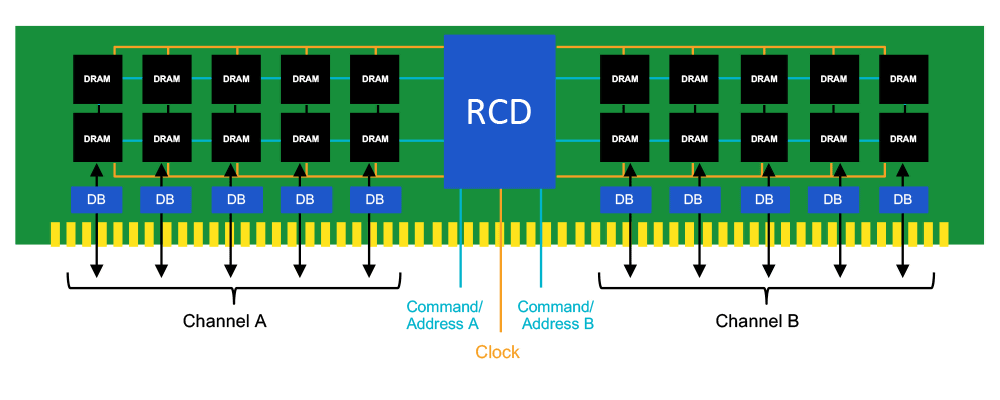
grotere geheugensticks voor servers is dit alsnog een probleem. De modules zijn ineens 72 bits breed (de extra bits zijn voor ECC) en gebruiken daardoor 5 ipv 4 chips, én er is vaak een tweede setje chips voor extra capaciteit (een extra "rank"). Die signalen moeten ineens niet naar 4 chips, maar naar 10! De oplossing is de "Registering Clock Driver (RCD)" van DDR5 RDIMMs. Dit is in essentie een CKD, maar die óók werkt als repeater voor de controlesignalen. Bij de dual-rank geheugenmodules zitten de data-pins van de twee ranks aan elkaar verbonden: er is steeds maar één rank actief, hoewel de inactieve rank alsnog voor wat extra belasting van de drivers zorgt. In het ideale geval zitten de twee ranks niet boven elkaar zoals in de illustratie, maar op de voor- en achterkant van de module. Hierdoor is de extra afstand naar de tweede chip minder dan een millimeter.
Dual-rank geheugen kán je overigens gebruiken zónder RCD - mits je rekening houd met de extra busbelasting. Voor consumentenbordjes kan het bijvoorbeeld interessant zijn om twee dual-rank modules van elk 16G te gebruiken in plaats van vier single-rank modules van elk 8G: de traces tussen de twee module-slots zorgen voor vrij veel storing. Zie bijvoorbeeld deze specs van een willekeurig moederbord:
Max. overclocking frequency:
1DPC 1R Max speed up to 6666+ MHz
1DPC 2R Max speed up to 5600+ MHz
2DPC 1R Max speed up to 4000+ MHz
2DPC 2R Max speed up to 4000+ MHz
1DPC 2R is dus duidelijk een stuk beter dan 2DPC 1R - zelfs als je fysiek
precies dezelfde chips gebruikt! Intel gaat tegenwoordig zelfs zo ver dat de
aanwezigheid van het tweede setje geheugenslots (zelfs als ze leeg zijn) al een snelheidsbeperkende factor is. Het is ineens dus een héél stuk aantrekkelijker om een moederbord te kopen met slechts twee geheugenslots. Je levert weliswaar wat uitbreidingsmogelijkheden in, maar je krijgt er extra snelheid voor terug.
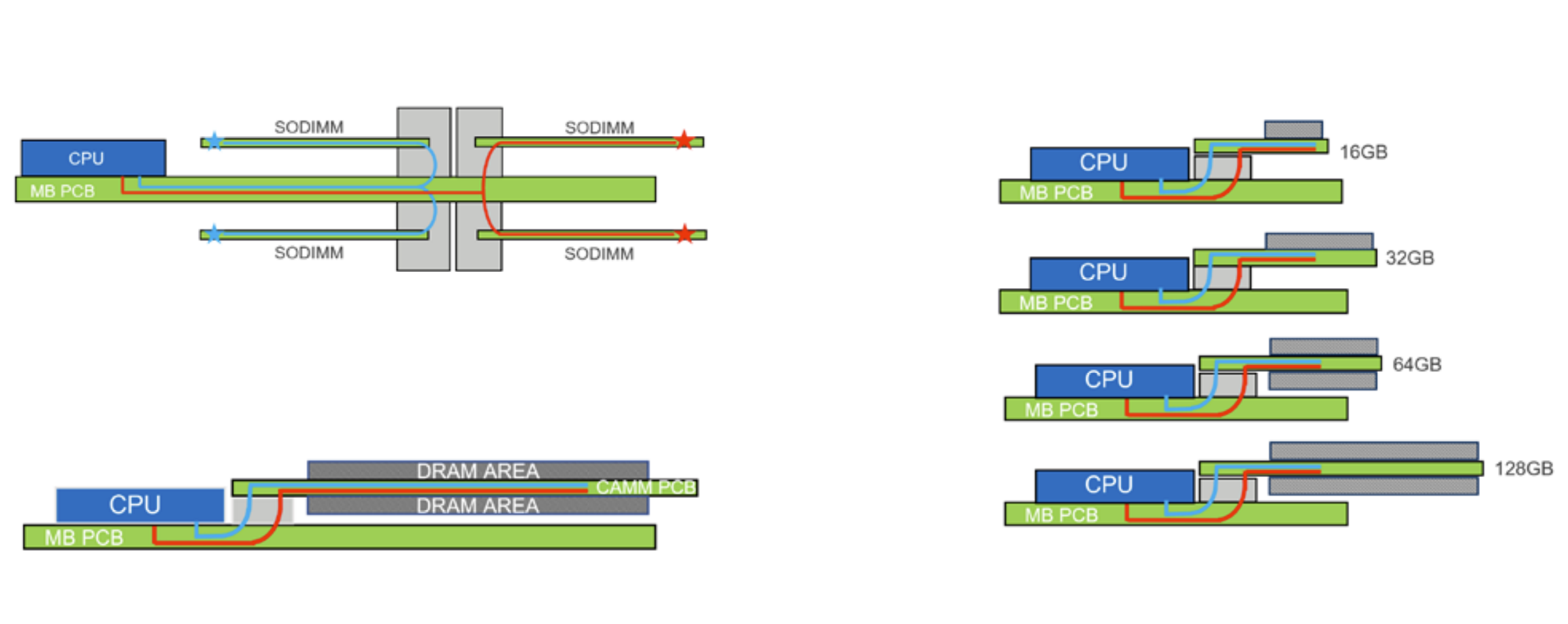
Maar het kan altijd nog erger. Er zijn ook modules met
vier ranks. Combineer dat met twee modules per geheugenkanaal, en je hebt ineens een enorme belasting op de data-pins. DDR5 LRDIMM lost dit op met een
data buffer op de geheugenmodule. De vier ranks hebben allemaal een verbinding naar de buffer, maar van de buffer gaat er maar één signaal naar de CPU. Dit verminderd de bus-belasting met 75%.
:strip_exif()/i/2007014994.jpeg?f=imagegallery)
/i/2007014996.webp?f=imagegallery)

:strip_icc():strip_exif()/i/2007001196.jpeg?f=fpa_thumb)
:strip_exif()/i/2007890856.jpeg?f=fpa)
:strip_exif()/i/2007621288.jpeg?f=fpa)
:strip_exif()/i/2006176668.jpeg?f=fpa)
/i/2007172738.webp?f=fpa)
:strip_exif()/i/2006987450.jpeg?f=fpa)
/i/2006990524.png?f=fpa)
:strip_exif()/i/2006624230.jpeg?f=fpa)
:strip_exif()/i/2006851794.jpeg?f=fpa)
:strip_exif()/i/2007025996.jpeg?f=fpa)
/i/2007015794.png?f=fpa)
:strip_exif()/i/2006992792.jpeg?f=fpa)
:strip_exif()/i/2006022142.jpeg?f=fpa)
/u/420938/crop69171d543a1bf_cropped.png?f=community)
:strip_icc():strip_exif()/u/314773/crop67b05f161113e_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/362142/crop5c5080164c7ac_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/305736/rogcropped2.jpg?f=community)
:strip_icc():strip_exif()/u/334861/crop5fe3838ae0c5c_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/19330/crop634f032e3966a_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/341611/crop59bdeb03f3805_cropped.jpeg?f=community)
:strip_exif()/u/591794/crop61a251d10f7b3.gif?f=community)
:strip_icc():strip_exif()/u/22888/bee-1-Photo-P-Perry2-70x70.jpg?f=community)
:strip_icc():strip_exif()/u/1597840/crop69ed231feaa91_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/1128253/crop683ccc0b0255b_cropped.jpg?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}