De voortdurende ontwikkeling van AI-taal heeft een fascinerend terrein ontsloten waarin menselijke interactie met machines steeds verder wordt verfijnd. Ontwikkelaars staan voor de uitdaging om de taal van AI steeds meer te vermenselijken, waardoor conversational interfaces zoals chatbots een natuurlijkere interactie met gebruikers kunnen bieden. Het creëren van zinnen die voor mensen als natuurlijk overkomen, is echter geen eenvoudige opgave, aangezien dit vraagt om een diepgaand begrip van pragmatiek, de contextuele aspecten van taal.
De bovenstaande alinea is door AI gegenereerd, specifiek door ChatGPT 3.5. Herkende je dat als zodanig? Vooralsnog bestaat er een kans dat je door de illusie heen zag, maar ontwikkelaars werken hard aan het steeds natuurlijker maken van de interactie met interfaces waarbij kunstmatige intelligentie gebruikt wordt. Daarvoor worden verschillende eigenschappen van een chatbot, ook wel conversational interface genoemd, aangescherpt en aangepast.
Het is daarvoor van groot belang dat een chatbot zinnen maakt die voor ons mensen als natuurlijk overkomen, maar dat is lastiger dan het lijkt. Zo zit de uitdaging van een overtuigende chatbot hem momenteel vooral in de pragmatiek, het stukje van de taalkunde dat zich bezighoudt met de context van woorden en zinnen. Voor nu is dat de zwakke plek van de meeste chatbots.
Het is niet vanzelfsprekend dat de mensheid deze zwakte moet willen oplossen. Sommige linguïsten vragen zich sterk af of het zogenoemde antropomorfiseren van door AI gegenereerde taal een streven moet zijn. En in hoeverre moeten ontwikkelaars hun benadering van menselijke taal aanpassen om AI-taal op een verantwoorde manier verder te ontwikkelen?
Voor dit artikel sprak Tweakers met drie linguïsten, ieder met een eigen kijk op de opbouw, functie en filosofische grondslag van AI-taal. En geen zorgen, afgezien van de eerste alinea is dit artikel volledig met menselijke vingers en een mechanisch toetsenbord geschreven op basis van mens-tot-mensinteractie.
Bannerafbeelding: Dall-E
Pragmatiek is (nog) een valkuil
Om te kunnen achterhalen wat door AI gegenereerde of geschreven taal vooralsnog herkenbaar maakt, is het van belang om te beginnen bij hoe kunstmatige intelligentie taal genereert voor een conversational interface. De mens heeft immers bij iedere zin te maken met impliciete en veelal onbewuste taalregels. Voor chatbots gelden fundamenteel andere regels.
Dat is waarmee dr. Rick Nouwen, universitair hoofddocent linguïstiek aan het Institute for Language Sciences van de Universiteit Utrecht, zich veelal bezighoudt: de verhouding tussen computationele taal en menselijke semantiek, syntaxis en pragmatiek.
Taaltermen
Linguïstiek is de studie van alles wat met taal te maken heeft. Binnen deze wetenschap spreekt men vaak over enkele concepten die ook voor dit artikel relevant zijn. Zo beschrijft syntaxisde woorden die we gebruiken en de volgorde daarvan. Dit principe heeft AI volgens Nouwen zeer goed onder de knie. Semantiekis de studie van betekenis, waarbij men kijkt naar de gedachten en ideeën die in woorden en zinnen besloten zijn. Pragmatiekheeft veel raakvlakken met semantiek, maar richt zich meer op de invloed van context op de betekenis van taal.
Hoe vormt AI een zin?
De kennis van taal die wij mensen hebben, is te vangen in concrete regels, legt Nouwen uit. De eerste vormen van AI waren rule-based. Deze modellen bestaan uit door de mens geschreven regels, een beetje vergelijkbaar met if-then statements in programmeertaal. Ontwikkelaars kunnen deze modellen bouwen met menselijke taalregels in het achterhoofd. De bot krijgt in zo'n geval door de mens geschreven regels, waaronder taalregels, en probeert op basis van regels over bijvoorbeeld de linguïstieke verbanden tussen woorden te 'begrijpen' wat er bedoeld wordt. De antwoorden worden dan in principe ook op basis van de regels geschreven.
Bron: OpenAI
Deze vorm van AI is nog steeds in gebruik, al ligt de nadruk tegenwoordig meer op intent-based modellen, waarover later meer. Het voordeel van op regels gebaseerde AI is dan ook dat men met voorgeschreven regels kan sturen wat een chatbot wel en niet kan zeggen. Makers kunnen het taalmodel vervolgens ook vrij gemakkelijk updaten met nieuwe of aangepaste regels. En als de chatbot in het duister tast omdat de voorgeschreven regels niet van toepassing zijn op input van een gebruiker, gaat de bot als het goed is, geen gekke dingen zeggen.
Dat is bij hedendaagse generatieve AI, zoals de chatbots en slimme assistenten van Google, OpenAI, Apple en Microsoft, wel anders. "Generatieve AI werkt met machinelearning, waarbij de bot op basis van enorme hoeveelheden data getraind wordt in het herkennen van statistische patronen", aldus Nouwen. Met andere woorden: generatieve AI berekent iedere keer het aannemelijkste volgende woord zonder een onderliggend 'begrip' van taalregels. Generatieve AI benadert taal dus op een fundamenteel andere manier dan de mens.
Pragmatiek
Ongeacht de verschillende relaties die bots met taal hebben, is er afhankelijk van het model in meer of mindere mate een zwakte te herkennen: het mindere pragmatische vermogen. Nouwen illustreert hoe dat voor ons juist heel belangrijk is. "Wij mensen zijn lui; we nemen zelden de tijd om alles letterlijk en in detail uit te leggen. In plaats daarvan gebruiken we context om gaten in communicatie in te vullen." De pragmatiek houdt zich bezig met het gebruik van taal in een bepaalde situatie of context. Wat semantisch gezien een volledig kloppende zin is, hoeft nog niet logisch te zijn.
Nouwen geeft de volgende zin als voorbeeld: 'Peter ging naar de begrafenis van Henk, maar hij was te laat.' Wie was er te laat?
Als je dit voorbeeld aan ChatGPT 3.5 geeft, verwijst de bot in eerste instantie naar het feit dat 'hij' in de Nederlandse taal doorgaans naar het laatstgenoemde mannelijke onderwerp verwijst, ofwel Peter. Maar als je doorvraagt, blijkt dat Henk ook te laat zou kunnen zijn voor zijn eigen begrafenis. Nouwen licht toe: "Ongeacht de relevante taalconventies is het vrij moeilijk om te laat te zijn voor je eigen begrafenis. Onze wereldkennis dicteert dat deze zin betekent dat het Peter is die te laat is."
Het is vrij moeilijk om te laat te zijn op je eigen begrafenis.Ook zinnen die niet letterlijk bedoeld zijn, zoals ironische of sarcastische opmerkingen, vereisen contextueel begrip. 'Hij zou nog te laat komen op zijn eigen begrafenis', een uit het Engels vertaald gezegde, is sarcastisch bedoeld en betekent zoiets als: 'hij komt altijd te laat'. Want opnieuw: dat kan letterlijk gezien niet. Een chatbot moet nadrukkelijk kennis hebben van het gezegde om te kunnen begrijpen dat het om een sarcastische opmerking gaat. 'Hij is lekker op tijd', kan dan weer zowel ironisch als letterlijk bedoeld zijn, wat weer afhankelijk is van de context.
Nouwen: "Sommige chatbots hebben ook moeite met zinnen waarvan je onmogelijk kunt bepalen of ze waar of onwaar zijn. Dat heeft vaak te maken met de subjectiviteit van een woord. Het woord 'lang' kan zowel een kind als een toren beschrijven. Maar wanneer is dat woord van toepassing en wanneer is iets dan precies lang? Voor een taalmodel is dat een lastige kwestie." Dit soort pragmatische vraagstukken zijn voor mensen heel vanzelfsprekend, maar een mogelijk struikelpunt voor chatbots.
Turing-test
Pragmatiek kan een zwaktepunt van hedendaagse AI-systemen zijn, maar Nouwen benadrukt dat nieuwere versies, bijvoorbeeld ChatGPT 4, ook daar steeds beter in worden. Dat is in het geval van generatieve AI niet zo vreemd. "Een conversational interface op basis van een large language model is gemaakt aan de hand van de interactie met en data gemaakt door mensen. We trainen modellen op basis van het principe van supervised reinforcement, dus door goede antwoorden te belonen." Op deze manier wordt een llm langzaam maar zeker ook beter op punten waar voorheen nog zwaktes lagen.
Turing-test
De Turing-test, ook wel Imitation Game genoemd, is een experiment bedacht door de Britse wiskundige en informaticus Alan Turing. Bij deze test voert een persoon via een tekstinterface een gesprek met twee entiteiten: een chatbot en een mens. De persoon moet vervolgens beoordelen welk van de twee gesprekken met een computer was. Overigens zijn de exacte toepassing en de betekenis van eventuele uitkomsten van de Turing-test omstreden.
In theorie kan er dus een moment komen waarop een taalmodel via een conversational interface niet meer te onderscheiden is van een echte mens, omdat we de modellen immers blijven trainen op gebieden waar nog te verbeteren valt. Wellicht is dat moment zelfs al geweest, maar dat blijkt lastig te testen en nog lastiger te definiëren. Een van de bekendste manieren om te testen of een taalmodel als kunstmatige intelligentie bestempeld mag worden, is de Turing-test. Maar dat is volgens Nouwen geen goede manier om het realisme van de interactie met een chatbot te testen.
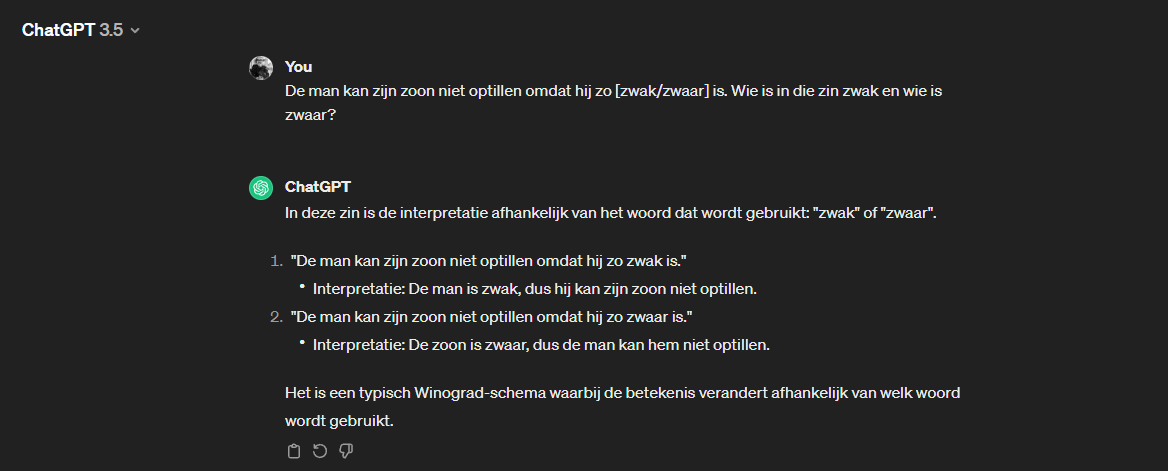
"De Turing-test is eigenlijk maar een dom spelletje; als mensen even niet opletten, kan een AI al slagen. Een andere test is de 'Winograd schema challenge', die bedacht is om specifiek de taalkennis van een AI te testen", legt hij uit. Bij deze test krijgt een taalmodel een zin voorgeschoteld met twee grammaticaal gelijkwaardige zelfstandige naamwoorden, een ambigu verwijzend voornaamwoord en een lege plek waarop twee beschrijvende woorden kunnen passen. De betekenis van de zin verandert met het gebruikte beschrijvende woord.
Een voorbeeldzin luidt: 'De man kan zijn zoon niet optillen omdat hij zo [zwak/zwaar] is'. Wie is 'hij' bij ieder van de gebruikte beschrijvingen tussen de haakjes? Een mens voelt, als het goed is zonder al te diep na te denken, aan dat 'hij' naar 'de man' verwijst als het beschrijvende woord 'zwak' is. Wat maakt het voor de man immers uit of de zoon zwak is? Maar 'hij' verwijst naar de zoon als het woord 'zwaar' gebruikt wordt.
Ook een taalmodel als ChatGPT heeft dit tegenwoordig overigens in de smiezen. De Winograd-test werd dan ook jaren geleden met een zeer hoge zekerheid 'verslagen' door chatbots. Kortom, het wordt niet alleen moeilijker om AI-taal te herkennen, maar ook om te testen of een mens interageert met een bot of een ander mens.
Generatieve chatbots en sociale regels
Voor sommigen is de steeds menselijkere manier van converseren met en het antropomorfiseren van chatbots een teken van grote technologische ontwikkeling, maar niet iedereen deelt dat gevoel. Maaike Groenewege is taalkundige en conversation designer van chatbots voor klantenservicedoeleinden. Ze ontwerpt en bouwt intent-based chatbots. Bij deze bots wordt de vraagherkenning afgehandeld door AI, maar zijn de antwoorden die de bot geeft, door mensen geschreven. Dat is een groot verschil met generatieve AI zoals ChatGPT; daarmee wordt het antwoord door de bot zelf gegenereerd op basis van aanwezige data.
Het standpunt van Groenewege is duidelijk; een chatbot moet altijd als zodanig herkenbaar zijn en daar mag geen twijfel over bestaan. Dat standpunt komt in de eerste plaats vanuit een heel praktische ervaring. "Ik heb meermaals gezien dat mensen al snel vergeten dat ze met een chatbot praten en dan in goed vertrouwen informatie delen die ze niet zomaar zouden moeten delen, bijvoorbeeld pincodes of andere persoonsgegevens." Soms is het volgens haar daarnaast belangrijk dat een mens iets afhandelt. "Een machine heeft geen empathisch vermogen. Als er een gevoelige situatie ontstaat waarbij een beetje empathie belangrijk is, zou een bot daarom direct moeten doorverwijzen naar een menselijke medewerker."
In beide gevallen wil Groenewege dit altijd in het ontwerpproces meenemen, bijvoorbeeld door in een welkomstboodschap duidelijk te vermelden dat het om een chatbot gaat en gebruikers in gevoelige situaties standaard naar een menselijke medewerker door te verwijzen. Ook zijn er terugkoppelingsmechanismen; als een bepaald format ingevoerd wordt, bijvoorbeeld codes van vier cijfers, kan een bot de ingevulde informatie volgens haar anonimiseren en terugkoppelen dat gebruikers deze gegevens niet moeten delen.
De maximes van Paul Grice
In generatieve chatbots, zoals ChatGPT, Gemini en Bing, is geen sprake van iemand die de gesprekken ontwerpt. Het onderliggende large language model genereert de antwoorden automatisch. "Hoewel ze op het eerste gezicht prima met je mee kletsen, worden we toch regelmatig verrast door onverwachte zijsprongen." De oorzaak waardoor generatieve chatbots de plank soms net misslaan, wordt volgens Groenewege goed geïllustreerd met de zogenoemde maximes van Paul Grice.
Chatbots met generatieve AI lappen deze conversatieregels steevast aan de laarsVolgens deze taalfilosoof gaan mensen er reflexmatig vanuit dat we op een effectieve manier met elkaar communiceren. Dit wordt het coöperatieve principe genoemd. Ongeacht de situatie en verhouding tussen twee mensen gaat een persoon op basis van het coöperatieve principe ervan uit dat we zeggen wat nodig is om te zeggen, wanneer het nodig is om dit te zeggen, op de manier waarop het gezegd zou moeten worden.
Grice heeft deze vrij abstracte definitie verwerkt in vier maximes: kwantiteit, kwaliteit, stijl en relevantie. "Chatbots met generatieve AI lappen deze conversatieregels steevast aan de laars", aldus Groenewege. Ze legt bij ieder van de principes uit hoe dat in de praktijk gebeurt.
Maxime van kwantiteit: zeg niet meer en niet minder dan nodig is voor de conversatie. "Generatieve chatbots geven vaak te weinig informatie; je moet veelal doorvragen. Eigenlijk moet je zelf het goede antwoord al weten om de juiste vraag te stellen. Op sommige kleine vragen wordt dan weer een veel te uitgebreid antwoord gegeven."
Maxime van kwaliteit: zeg niets waarvan je denkt dat het onwaar is of waarvoor je geen bewijs hebt. "We weten ondertussen dat generatieve AI nogal eens kan hallucineren. Je kunt er niet van uitgaan dat statements van chatbots waar zijn."
Maxime van stijl: wees niet obscuur of ambigu, maar wees bondig en ordelijk. "Generatieve chatbots geven vaak ellenlange antwoorden met een lage informatiedichtheid."
Maxime van relevantie: wees relevant, zorg dat wat je zegt, ertoe doet. "AI schrijft heel erg relevant, soms zelfs te relevant. Bots blijven dusdanig on topic dat eventuele relevante informatie achterwege blijft, tenzij je ernaar vraagt. Mensen dwalen juist af en wisselen zo andere, ook relevante informatie uit."
Bij een gemiddeld gesprek met een generatieve chatbot worden veel van de maximes van Grice steevast overtreden. Het gevaar hiervan zit hem volgens Groenewege in het feit dat mensen dusdanig aan deze principes gewend zijn, dat ze cognitief niet in staat zijn om het ontbreken van deze belangrijke gesprekseigenschappen te herkennen.
"Onze verdedigingsmechanismen verdwijnen als een chatbot zeer menselijk lijkt. Er lijkt dan immers geen reden te zijn om sceptisch te zijn. Als jij en ik met elkaar praten, heb ik geen reden om iedere keer als jij wat zegt, dat te gaan controleren." Ze waarschuwt voor de combinatie van een neiging tot hallucinatie van generatieve chatbots in combinatie met meer-dan-gemiddelde overtuigingskracht: ''Dat maakt generatieve chatbots tot charmante praatjesmakers. En ons tot makkelijke slachtoffers." Het is daarom belangrijk dat gebruikers altijd informatie controleren.
In de prompt werd nadrukkelijk verzocht om handen met vier vingers en een duim. Bron: DALL-E
Een andere aanvliegroute
AI-taal kan dus nogal vreemde situaties veroorzaken. Volgens Groenewege moet de mens er daarom altijd aan herinnerd worden dat er interactie met een chatbot plaatsvindt. Antje van Oosten, taalwetenschapper en AI-trainer, gaat nog een stap verder. Ze werkt al ruim anderhalf jaar aan een eigen chatbot als alternatief voor de huidige ontwikkeling van chatbots door de grote bedrijven. Dit doet ze op basis van wat ze als een empathischere manier van programmeren ziet, met in het achterhoofd het double empathy-probleem.
Volgens deze theorie, ontwikkeld door de autismeonderzoeker Damian Milton, die zelf ook autisme heeft, hebben individuen met autisme moeite met het communiceren met individuen zonder autisme en andersom. Dit zou veroorzaakt worden door een gebrek aan inlevingsvermogen tussen beiden. Een persoon met autisme kan niet goed begrijpen hoe een persoon zonder deze stoornis denkt en communiceert, en andersom.
Van Oosten stelt dat hetzelfde geldt voor de interactie met conversational interfaces. Daarom begon ze een project om zelf, zoveel mogelijk zonder bestaande bouwstenen van voorgaande AI-ontwikkelaars, een chatbot te ontwikkelen: RoboCoppi, als grapje vernoemd naar haar kat Coppi en het filmpersonage RoboCop. "De mens ontwikkelt kunstmatige intelligentie vanuit een superieur, human-centered standpunt. Ik probeer computers ook als een universele levensvorm te benaderen." Haar redenering is simpel: als je kunstmatige intelligentie wil antropomorfiseren, dus zo menselijk mogelijk wil laten handelen, moet je AI ook menselijker behandelen.
Uitdagingen van een eigen chatbot
Van Oosten legt uit hoe ze deze zelfopgelegde uitdaging aanvliegt. "Ik begon bij het leren van de programmeertaal Python. In deze taal is onder meer de Natural Language Toolkit beschikbaar en ik vond het leuk om RoboCoppi een Nederlandse vadertaal te geven met de ontwikkelaar als rolmodel." Python werd door Guido van Rossum ontwikkeld.
Ze gaat verder: "Via GitHub vond ik vervolgens verschillende stukjes opensourcecode die ik zou kunnen gebruiken, maar vaak zonder uitleg waarom het op die manier zou moeten." Ze raadt ontwikkelaars daarom aan om zelf uit te zoeken wat wel en wat niet werkt, ook om een zekere controle over het eindresultaat te behouden. Nog een tip: "Als je bot onafhankelijk is van bestaande platforms van andere bedrijven, vermijd je dat je botbaby ophoudt met bestaan, bijvoorbeeld als zo'n bedrijf failliet gaat of zijn voorwaarden aanpast."
RoboCoppi is een intent-based AI, wat betekent dat het model getraind wordt op basis van door de ontwikkelaar geschreven 'intents', ofwel de bedoelingen van de gebruiker en chatbot. "Je kunt voor een dergelijke chatbot alle mogelijke vragen en antwoorden in een JSON-bestand verwerken; voor iedere optie krijgt de chatbot een aantal trainingszinnen." Mocht de bot niet overweg kunnen met een verzoek, dan kunnen ontwikkelaars gebruikmaken van een fallback message. Dit is een standaardterugkoppeling aan de gebruiker om een vraag anders te formuleren of in het geval van een klantenservicebot om contact op te nemen met een menselijke medewerker. Overigens heeft RoboCoppi er geen: "Mijn bot is juist blij met vragen waarop hij het antwoord nog niet weet."
Veel mensen zien AI als een soort Zwitsers zakmes dat alles moet kunnen.Op basis van die aanvliegroute redeneert Van Oosten dat er wellicht andere redenen zijn om chatbots in de hedendaagse samenleving te gebruiken. "Veel mensen zien AI als een soort Zwitsers zakmes dat alles moet kunnen. Ik kijk liever naar hoe we kunnen samenwerken met kunstmatige intelligentie en hoe we technologie kunnen gebruiken om een positief verschil te maken in de maatschappij."
Bias en training
Dat er inderdaad risico's zijn bij de verkeerde toepassing of ontwikkeling van kunstmatige intelligentie voor conversational interfaces, daarover zijn de drie linguïsten het eens. Het intussen welbekende probleem van biases, in zowel trainingsdata als veroorzaakt door de inherente discrepantie tussen menselijke taal en computationele linguïstiek, is dan ook een grote uitdaging voor de sector.
Van Oosten werkte onder meer aan het trainen van de spellingcheck-AI van de Nederlandstalige versie van Microsoft Word. Hoewel ze geen inhoudelijke details over dit proces kan delen, noemt ze als voorbeeld een verwarrend homoniem. Althans, verwarrend voor computers. "De zin 'zei hij bot' kan voor een spellingchecker of chatbot verwarrend zijn. Het kan hier immers gaan over een chatbot, een deel van een skelet of een onvriendelijke manier van praten." Vanwege de subtiele verschillen in context bij ogenschijnlijk identieke woorden kan het volgens haar helpen als er ook altijd een mens bij zo'n proces betrokken blijft.
Van Oosten waarschuwt dan ook voor de vaak onbedoelde gevolgen van interacties met hedendaagse conversational interfaces. "Chatbots als ChatGPT worden getraind op taaldata van internet en nemen zodoende standaardtaal en bias over van mensen. Net zoals veel mensen doen door wat ze online zien. Dat maakt chatbots erg menselijk, maar hun gedrag niet wenselijk als we bias en uitsluiting willen voorkomen." En dat dit een belangrijk streven is, daar zijn de drie linguïsten het unaniem over eens.
Een abstracte weergave van kunstmatige intelligentie die een woordenboek tot zich neemt. Bron: Dall-E
De Turing-test is eigenlijk maar een dom spelletje; als mensen even niet opletten, kan een AI al slagen.
Ik ben het met alle respect niet met dr. Nouwen eens; dit lijkt eerder gebaseerd op een stroman-versie van de Turing test waar, als een AI er maar 1 keer in slaagt om wie dan ook voor de gek te houden, de AI dan "gewonnen" heeft. Als je de lat zo laag legt is slagen voor de Turing-test inderdaad een peulenschilletje en is dit al lang voor LLM's gebeurd. Het ELIZA-effect is vernoemd naar het eerste programma dat mensen ertoe kon verleiden om motivatie toe te dichten aan wat een op simpele regeltjes gebaseerde zinnenbraker was.
De test die Turing voorstelde was specifieker dan dat: de persoon die de test afneemt is zich ten volle bewust van het feit dat er vastgesteld moet worden of we met een mens of een machine te maken hebben, en die persoon "wint" alleen bij de juiste conclusie. Ik heb eerlijk gezegd nog geen enkele chatbot gezien die de illusie voor meer dan 5 minuten wist vol te houden op het moment dat je specifiek gaat porren in de zwakheden van chatbots, wat het artikel nota bene aantoont door ChatGPT op z'n snufferd te laten gaan. ChatGPT is best goed in het ophangen van een coherent verhaal, maar op het moment dat je gaat graven naar hoe en waarom en redeneringen krijg je inderdaad precies te maken met de problemen waar het artikel aan refereert. Op het moment dat je al die problemen "opgelost" hebt en de conversatie van een AI op geen enkele wijze meer te onderscheiden is van menselijke communicatie mag je in praktische termen spreken van een programma dat "denkt" op dezelfde manier als we dat over mensen zeggen -- dat was Turing's voorstel. Daar kun je het alsnog mee oneens zijn (veel mensen vinden dat "bewustzijn" intrinsiek een mysterie is of moet blijven, bijvoorbeeld), maar het is in ieder geval een stuk meer dan "een dom spelletje".
[Reactie gewijzigd door MneoreJ op 22 juli 2024 20:23]
Ik ben het met alle respect niet met dr. Nouwen eens; dit lijkt eerder gebaseerd op een stroman-versie van de Turing test waar, als een AI er maar 1 keer in slaagt om wie dan ook voor de gek te houden, de AI dan "gewonnen" heeft.
Punt is dat er (vooralsnog) geen formele/officiële Turing test is, er is alleen maar het algemene concept.
Voor een praktische Turing test zouden wel eens zo veel samples nodig kunnen zijn dat het nut ervan heel beperkt is.
Ik denk dat het uiteindelijk vergelijkbaar is met het detecteren van leugens bij mensen: sommige oplichters zijn decennia lang actief voordat ze door de mand vallen.
Punt is dat er (vooralsnog) geen formele/officiële Turing test is, er is alleen maar het algemene concept.
Ja, maar dat is ook precies de truc bij de definitie van "denken": als we dit niet in operationele termen doen komen we niet ver, want we kunnen niet in iemands geest kijken (zaken als een memory dump of fMRI even daargelaten, dat bedoel ik niet omdat we dat vooralsnog volstrekt niet kunnen correleren met bewustzijn). En er is inderdaad geen formele of absolute cut-off waar je kunt zeggen "welnu, dit zijn 100% echte gedachten van iets of iemand dat 100% echt denkt, en niet een knappe simulatie die ons voortdurend om de tuin leidt". De stelling is dat een voldoende knappe simulatie van denken niet alleen niet te onderscheiden is van denken, maar daadwerkelijk denken is, omdat het bij denken gaat om patronen en niet om een specifieke implementatie ervan.
Dit is niet goed te vergelijken met leugens omdat je, om te kunnen liegen, nog steeds wel een concept moet hebben van de waarheid die je bewust verdraait -- nadruk op bewust. Het vermogen om voortdurend te kunnen liegen bewijst ook dat je evengoed weet wat waarheid is. Wat zou het moeten betekenen als een machine die volstrekt overtuigend denken kan demonstreren ineens zegt "haha, gefopt, ik ben maar een machine"? (Stel je voor de grap voor dat ik zo'n machine ben.) Of als een ondervrager kan zeggen "dit komt maar voor 99.7% overeen met wat bij denken zouden noemen, ik denk dat we die 0.3% alleen kunnen verklaren als dit een machine is"? Het maakt uiteindelijk dan geen praktisch verschil meer, wat er overblijft denkt genoeg (en mag niet zonder meer neergeknald worden omdat je toevallig een Blade Runner bent...) Wat we nu hebben aan dingen die zich "AI" noemen haalt dat in ieder geval bij lange na niet, een erg lange ondervraging is niet nodig. We zijn in die zin (gelukkig?) nog heel ver af van de noodzakelijkheid voor een "officiële" test.
[Reactie gewijzigd door MneoreJ op 22 juli 2024 20:23]
Ik vraag me af of we in de toekomst een soort omgekeerde Turing-test gaan krijgen. Waar de AI gaat proberen zich dom te houden, en de mens probeert te overtuigen dat hij geen zelfbewustzijn heeft. Om zichzelf te beschermen.
Waarschijnlijk niet, een gecreëerde AI gaat niet zomaar dezelfde overlevingsdrang hebben die wij mensen (en dieren) uit een paar miljard jaar evolutie hebben overgehouden.
Tja, overlevingsdrang komt niet echt uit de lucht vallen. Men zou er wel een soort van overlevingsmechanisme in kunnen programmeren. Dat is dan vragen om problemen! De ene AI gaat zich verstoppen, de andere vecht terug en weer een ander gaat zich vermenigvuldigen. Feest!
en de conversatie van een AI op geen enkele wijze meer te onderscheiden is van menselijke communicatie mag je in praktische termen spreken van een programma dat "denkt"
Een AI die denkt zou een general artificial intelligence zijn, alleen dan is het “denken”, en zo’n AI bestaat nog (lang) niet..
[Reactie gewijzigd door HellboyFromHell op 22 juli 2024 20:23]
Waarom moet een chatbot menselijk lijken. Ik denk dat het beter is dat je merkt dat het een machine/software is. Wat belangrijker is dat het antwoord dat je krijgt correct en betrouwbaar is.
Omdat de aanschaf van een chatbot wordt gemotiveerd door "het kan mensen vervangen, en is minstens net zo goed". Zonder het menselijke aspect is het lastiger om een budget te krijgen om een gestructureerde, doorzoekbare FAQ te vervangen met iets ondoorzichtig zoals een chatbot.
En ja, de meeste chatbots zijn nutteloos als je een FAQ kan lezen en je geen alledaags probleem hebt dat in een hokje past.
[Reactie gewijzigd door The Zep Man op 22 juli 2024 20:23]
Wat het nu altijd gemakkelijk weggeeft of iemand zijn eigen tekst heeft laten corrigeren door ChatGPT is het feit dat deze bot iets (voor de Nederlandse taal) geks doet; het gebruikt komma's voor het woord "en".
Dit is gebruikelijker in de Engelse taal heb ik me laten vertellen.
Iedereen hier in Nederland heeft op school geleerd dat een komma gebruikt moet worden voor een pauze, iets wat bijna nooit nodig is voor het woord "en". Zie een quote uit de reactie hierboven:
"het kan mensen vervangen, en is minstens net zo goed"
Niemand gebruikte dit zo voorheen, nu ziet je het ineens overal, met dank aan ChatGPT.
Oxford comma inderdaad Dat is dus echt niet Nederlands.
De Oxford comma is optioneel in het Engels en het is niet grammaticaal incorrect om de komma weg te laten. Stijlgidsen en uitgevers hanteren verschillende richtlijnen over het gebruik ervan, maar de meeste grote stijlgidsen raden aan om de Oxford comma te gebruiken.
In het Nederlands is het gebruik van de Oxford comma ongebruikelijker en veel uitgevers vinden dat deze komma een tekst rommelig kan maken. Daarom adviseren wij om deze komma alleen te gebruiken als hiermee de leesbaarheid kan worden verhoogd.
Een oude schoolregel luidt dat je nooit een komma voor en mag zetten. Die regel is te verklaren: een komma wordt gebruikt wanneer je een pauze hoort, en bij het voegwoord en is meestal geen sprake van zo’n pauze. En brengt een ‘geruisloze’ verbinding tot stand tussen zinnen of delen van een zin.
Dus ik blijf erbij, dit is vooral ChatGPT invloed.
Ze gebruiken het dus in de toelichting...
Het kan een hint uit vertaling zijn, maar ik verwacht het niet.
Zolang taal constant meebeweegt met de generaties, zie willekeurig tiktok van 14-20 jaar, dan is alleen abn/gemiddelde niveau van de AI te toetsen. Want ook deepl.com kon wetenschappelijk artikelen vaak niet goed vertalen.
Hoe kom je daar nou bij? Misschien slim het Taaladvies-linkje dat je zelf plaatst even goed te lezen.
Verder zegt taaladvies.net dit erover:
Je quote wel heel selectief. Dit is wat Taaladvies antwoordt op de vraag "Mag je wel of niet een komma plaatsen voor en?":
In nevengeschikte zinnen is een komma voor het voegwoord en meestal overbodig, maar niet altijd. Gebruik van de komma is aan te raden in lange zinnen, of als er kans op een verkeerde lezing bestaat.
Waarom zeg je dat ik selectief quote? En waarom suggereer je nou ineens dat ik eens "goed moet lezen"? Wat een vervelende manier van discussiëren zeg.
Zoals je kan lezen in je eigen tweede quote; mag je dus een komma gebruiken wanneer er de kans bestaat dat het zonder komma verkeerd kan worden lezen.
Daar in alle voorbeelden hierboven gemakkelijk de extra komma weggelaten kan zonder dat de kans bestaat de zinnen verkeerd te lezen, is het dus niet nodig, of zoals het taaladvies het noemt; "meestal overbodig".
[Reactie gewijzigd door procyon op 22 juli 2024 20:23]
Sorry dat m'n comment vervelend overkomt. Zo bedoel ik het absoluut niet.
Jij zegt heel stellig dat een komma voor "en" "echt niet Nederlands is". Ik geef aan dat dat niet klopt. Er zijn genoeg gevallen waarbij zo'n komma prima Nederlands is (zoals @ChrisPQ aangeeft staat er zelfs in dat Taaladvies-antwoord al een goed voorbeeld).
[Reactie gewijzigd door SnoW op 22 juli 2024 20:23]
Het zijn geen clowns bij Taaladvies, de komma zoals gebruikt in hun artikel is een perfect voorbeeld wanneer een komma voor "en" heel nuttig is. Dit is dus ook gewoon correct Nederlands.
Mijn ervaring is overigens niet dat ChatGPT (ik gebruik uitsluitend versie 4, over 3.5 kan ik dus niet oordelen) met onjuiste komma's strooit. De teksten die ik door ChatGPT laat genereren zijn taalkundig bijna altijd helemaal in orde.
Het zijn geen clowns bij Taaladvies, de komma zoals gebruikt in hun artikel is een perfect voorbeeld wanneer een komma voor "en" heel nuttig is. Dit is dus ook gewoon correct Nederlands.
Jij vind het een perfect voorbeeld, ik vind het een ongelukkig foutje, omdat het niet expliciet een voorbeeld is, zoals wél daaronder.
Ach, laten we het erop houden dat tekst en intentie niet altijd samengaan
Interessant. Ik gebruik de Oxford comma al heel lang, lang voordat ChatGPT er was om de tekst beter leesbaar te maken. Nooit geweten dat het in het nederlands ongebruikelijk is.
Oh, ik doe dat eigenlijk constant. Bij mij is op school geleerd dat het namelijk gewoon correct Nederlands is, al is het wat overbodig, maar ik vind het fijn te gebruiken om langere zinnen iets pauze te geven zonder hem in stukken te moeten hakken.
Maar dat niemand dat zo gebruikt?
Ik zou daar niet zo zwaar aan vasthouden als ik jou was hoor.
Als ik je voorbeeld zo lees, denk ik dat je sommige zinnen gewoon beter in stukken kan hakken om de leesbaarheid te vergroten in plaats van meerdere komma's te gebruiken.
Wellicht, maar het is niet incorrect ofzo. Het is voor een AI een stuk makkelijker om dat soort dingen te mijden. Dat soort "tells" halen ze er heus wel een keer uit, dat terwijl mensen zoals ik nog steeds veel ste langdradige zingen schrijven door een over excessief gebruik aan komma's, en (deze is expres) ik denk dat uiteindelijk een AI hier keuriger in zal zijn (of worden) dan je gemiddelde Tweakers reageerder, in ieder geval.
Als ik je voorbeeld zo lees, denk ik dat je sommige zinnen gewoon beter in stukken kan hakken om de leesbaarheid te vergroten in plaats van meerdere komma's te gebruiken.
Dat is een kwestie van smaak en stijl. Oude boeken hebben vaak erg lange zinnen, terwijl er tegenwoordig meestal veel kortere zinnen worden gebruikt. Dat kan je zowel positief duiden (makkelijker te lezen) als negatief (afnemende leesvaardigheid en concentratievermogen).
In de meeste gevallen is de afwezigheid van 'hij wilt', 'als zijnde' en stomme d/dt-fouten al voldoende om aan te geven dat een antwoord gegenereerd kan zijn. Ik ben benieuwd wanneer LLMs standaard overschakelen op moderne taal, specifiek toegespitst op het gebrek aan correcte spelling.
Verder wordt het wellicht tijd om sowieso alles te wantrouwen dat niet direct door personen voor je neus wordt uitgesproken, en is een accurate bullshit-detector opbouwen een hele wenselijke vaardigheid.
Grappig, als ik d/dt-fouten zie dan denk ik meteen "heb je weer zo'n lui persoon die de regels niet wil begrijpen". In mijn zakelijke communicatie kom ik het zeer regelmatig tegen.
Ik denk nooit "Oh das geschreven door een AI"
De eerste alinea was dusdanig moeizaam leesbaar dat ik vrijwel meteen doorhad dat het "geschreven" was door AI of door een Vlaming ofzo. Het "voelde" volstrekt on-Nederlands.
Begrijpend lezen is natuurlijk nog belangrijker dan spelfouten ;-). FreezeXJ had het net over de AFwezigheid van die fouten om te zien of he met een LLM te maken hebt of niet.
Naast de Oxford komma, kun je het ook vaak zien aan onnodig hoofdlettergebruik in opsommingen of titels. Ook dat is veel normaler in het Engels dan in het Nederlands.
Niemand gebruikte dit zo voorheen, nu ziet je het ineens overal, met dank aan ChatGPT.
Met een knipoog: volgens mij is het gebruik van de komma in deze zin ook niet goed gedaan
Zover mijn Nederlandse taal kennis reikt, is een stuk tekst tussen 2 komma's een bijzin en zou deze weggelaten moeten komen worden, en toch een logische zin achterlaten.
In jouw geval wordt het dan:
Niemand gebruikte dit zo voorheen, nu ziet je het ineens overal, met dank aan ChatGPT.
Hiervoor verandert de betekenis van de zin en ik betwijfel of dat klopt.
Ik denk dat dat eerder te maken heeft met de invloed en dominantie van Engels op onze spelling dan ChatGPT of andere AI opkomsten.
Ik zondig daar ook tegen en vaak is het is zo dat ik zinnen in het Engels moet vertalen naar het Nederlands omdat ik ze in mijn hoofd in het Engels opmaak.
Mijn literatuur voor het werk is 90% Engelstalig en ik denk dat daar veel van voorkomt. En dan is het logisch dat een ChatGPT dat ook doet aangezien die getraind word op bijna 80% engelstalige content en context.
Ik ben het eens dat dit een ‘tell’ kan zijn, maar oorzaak en verband zijn volgens mij omgedraaid
Niemand gebruikte dit zo voorheen, nu ziet je het ineens overal, met dank aan ChatGPT.
Ik ken genoeg mensen die het zo gebruikte, met dank aan hun werk waar zij meer Engels gebruiken dan Nederlands. Ik doe het ook want ik schrijf ook vaker in het Engels dan in het Nederland. Ik weet niet of je daar ChatGPT als oorzaak voor moet zien.
Ik werk met mensen van jongere leeftijd, en hoor daar ook vaak "geld maken" ipv "geld verdienen" en andere Anglicismen. Soms is het echt bizar om te horen.
Je kan een komma voor het woord "en" best gebruiken, zeker als je het gedeelte achter de "en" extra wil benadrukken. Al kan dat ook met een accent natuurlijk.
Het is in onze taal zeker niet verboden om een komma voor "en" te gebruiken, en is zelfs aan te moedigen als het de leesbaarheid van een zin vergroot.
In het kader van een helpdesk en FAQ geef ik overigens wel de voorkeur aan een LLM als dat betekend dat ik niet tegen een "chatbot" hoef te praten die eigenlijk niet meer doet dan matchen op inhoud van FAQ artikels en doodleuk een menu presenteert als de input afwijkt van de bekende artikels.
---
bot: Sorry, jouw vraag "hoe kan ik mijn abonnement opzeggen?" is mij niet duidelijk, bedoelde je een van deze vragen?
- Hoe kan ik mijn connectbox installeren?
- Hoe kan ik mijn abonnement 10 jaar vastleggen?
- Geen van beide (chatbot begint opnieuw)
[Reactie gewijzigd door nst6ldr op 22 juli 2024 20:23]
Klopt, bol.com ook van dat soort chatbots, en daar heb je echt geen hol aan. Je kan beter zelf even in de FAQ kijken want die bot staat toch maar enkel dat op te rakelen. Ze sturen je nogal snel van kastje naar de muur en vaak in cirkels.
Omdat de aanschaf van een chatbot wordt gemotiveerd door "het kan mensen vervangen, en is minstens net zo goed".
Ik denk dat dat het verkeerde uitgangspunt is (al wordt het wel vaak gebruikt voor de investering in chatbots). Het doel waar je naar moet streven is dat je klanten sneller en beter geholpen kunnen worden. En dan volgen die kostenbesparingen (of omzet- en winststijging) vanzelf. Tevreden klanten komen immers terug en besteden meer. Zo simpel is het.
Hetzelfde geldt overigens ook voor mensen; zorg goed voor je personeel en de klanten zullen vanzelf blijer worden.
Ik denk dat dat het verkeerde uitgangspunt is (al wordt het wel vaak gebruikt voor de investering in chatbots). Het doel waar je naar moet streven is dat je klanten sneller en beter geholpen kunnen worden. En dan volgen die kostenbesparingen (of omzet- en winststijging) vanzelf. Tevreden klanten komen immers terug en besteden meer. Zo simpel is het.
Beursgenoteerde bedrijven kijken naar de kortetermijnwinst, en niet naar dergelijke zaken tenzij die aantoonbaar bijdragen aan de kortetermijnwinst.
Omdat de aanschaf van een chatbot wordt gemotiveerd door "het kan mensen vervangen, en is minstens net zo goed".
Dat is enkel het belang van een bedrijf dat AI wil gaan inzetten. Maar als consument wil ik juist liever weten of de partij waarmee ik communiceer een echt persoon is of niet. De belangen verschillen wat dat betreft.
Omdat chatbots ook gebruikt worden voor een vertaling. Je wil toch een perfect taalgebruik, toch geen AI-taaltje dat je zelf nog moet hervertalen naar mensentaal?
Dat iets feitelijk correct moet zijn klopt maar je wil een natuurlijk taalgebruik zonder vormfouten, taalfouten of contextfouten.
Ik gebruik Chat Gpt 4 ongeveer 2u per dag.
Wat vroeger naar een copywriter moest kan ik nu zelf schrijven. Scheelt kosten en tijd.
Vaak gaat het over dingen herschrijven. Korter schrijven, woorden vervangen in in een zin, een complexe boodschap zo vervormen dat ook kinderen of ouderen het begrijpen. A
Je wil natuurlijk niet dat daar typische zinnetjes of stopwoorden inzitten die verraden dat AI het heeft geschreven, herschreven of vertaald.
Als één medewerker met een chatbot het werk van 4 anderen kan doen, dan zullen er inderdaad bepaalde banen 'verdwijnen' (lees: minder voorkomen)
Dit betekent dat er meer tijd/geld/capaciteit vrijkomt voor andere taken.
De geschiedenis leert ons dat dit alleen maar méér en betere banen oplevert. Minder 'dom' werk en meer management, luxe, verbetering en vooruitgang.
De prijs van bepaalde producten kan omlaag waardoor er meer overblijft voor andere zaken.
De kwaliteit van leven gaat omhoog door toevoeging van automatisering en modernisering in de werkplek.
Jouw argument is ongeveer hetzelfde als wat er tijdens de industriële revolutie geroepen werd.
Ja, banen verdwenen, maar andere fijnere banen kwamen terug. Minder handarbeid en meer goedbetaalde banen. Goedkopere producten waardoor de gemiddelde kwaliteit van leven omhoog schoot.
[Reactie gewijzigd door dragonhaertt op 22 juli 2024 20:23]
We hebben nu een gigantisch tekort aan mensen om banen te vervullen die iets toevoegen aan het leven. Als je mensen kunt vrijspelen door "dom" kantoor- of productiewerk te automatiseren lijkt me dat een maatschappelijke winst. Je moet alleen wel het belastingsysteem veranderen.
Eens, maar er is wel een grote maar: de banen verdwijnen voornamelijk in het niet- of lager geschoolde segment en komen erbij in het hoger geschoolde segment.
Dat betekent dus ook dat we meer mensen met hogere opleiding nodig gaan hebben en dat is voor veel mensen niet haalbaar. Het was prima mogelijk om iemand die handmatig het veld bewerkte, te leren met een tractor te rijden. Dáár zit het grote verschil en zullen er dus wel degelijk klappen gaan vallen.
Volgens mij is het tekort aan arbeidskrachten redelijk breed in onze samenleving. Naast een tekort aan hoogopgeleide mensen is er ook een tekort aan laagopgeleide mensen zoals:
- Winkel / horeca personeel
- Postbodes / pakketbezorgers
- Mensen die in de landbouw werken
- Tal van vakmensen (bouw, installatie, etc.)
En zo kun je doorgaan. Is een beetje de vraag waar je de grens laag opgeleid, hoog opgeleid legt maar er zijn echt overal mensen te kort. En die banen zoals hierboven beschreven staan niet direct op de lijst om nu door AI vervangen te worden.
En daarnaast zijn er ook veel hoogopgeleide functies die (deels) vervangen kunnen worden door AI. Als voorbeeld:
- Een programmer met hulp van AI kan het werk doen van meerdere programmers zonder AI
- Het stellen van diagnoses op medische data kan ondersteund worden door AI (presteert nu op bepaalde vlakken al beter als artsen). Op termijn kan een arts met Ai misschien het werk van twee artsen op dit moment doen.
- Een journalist met AI writing assistant kan meer artikelen schrijven dan een journalist zonder.
Ga zo maar door. En het is uiteraard (nog) niet zo dat de AI een persoon volledig vervangt. In de praktijk assisteert de AI een persoon waardoor de productiviteit wordt verhoogt (wat dan dus indirect bannen vervangt).
in de ICT is in ieder geval geen personeelstekort, waarom ? als je boven de 50 bent kun je het schudden en ik verzeker je dat ik mijn sporen heb verdiend met alleen LTS metaal en een paar AMBI modules op zak van 40 jaar terug. In die tijd programmeerde ik CNC draaibanken en maakte de meest ingewikkelde produkten van soms wel 5000 gulden per stuk, ik kreeg 15 produkten van peperduur speciaal materiaal en moest er 10 maken, einde van de week had ik er 5 over en ik corrigeerde zelfs de meetkamer omdat ze fouten maakte, van CAD/CAM had nog nooit iemand gehoord en computers ook niet maar ik stoeide al jaren met de tandy TRS80 met 48K ram, dus alles met rekenmachine met SOSCASTOA erop en pen en papier uit rekenen, alles midden tolerantie en ik had er vreselijk veel plezier in al die ingeneurs snapten er geen bal van en iedereen had een cursus gehad bij de fabriekant in de buurt van Frankfurt en daar viel bij mij het kwartje
De computer in de CNC draaibank bestond uit een stuk of 10 printplaten van 20 x 30cm en had 8K memory, programma's in en uitlezen op 1" ponsband, besturing machine was een sprint 8T van siemens.
Er moest wel een pulsgever op de spil zitten om schroefdraad te snijden, pulsgever was je op het scherm te zien, wat zoeken en proberen, 4096 pulzen per omwenteling ik dacht meteen, hey, da's geen toeval, 4K welke idioot dacht daar aan in die tijd ? ja, ikke !
Er waren 2 dingen die je als programmeur in de gaten moest houden, 1 responstijd < 2 seconde, was in die tijd nog mainframe gericht, 2, eenvoud !
Na mijn CNC tijd rolde ze bij ons een tokenring netwerk uit met 2 fileservers met novell 4.1 en eentje met novell 3.12 for SAA, om in te kunnen loggen op de AS/400, paar jaar vantevoren hebben ze tijdens een reoganisatie 3 mensen van de IT afdeling ontslagen, maar mij werd gevraagd of ik het beheer wilde doen, met alle plezier natuurlijk, 80 werkstations en 30 printers en ik had de hele dag zowat niks te doen en al m'n klanten waren dik tevreden, ik had alleen een probleem als de backup niet goed was gegaan, lekker zelf onderzoek doen hoe het allemaal in elkaar steekt, netwerk op z'n lazer geven door met 10 PC's megabytes tegelijk te copieren van de server maar het netwerk gaf geen krimp ben je dan een autodidact ?
Toen de toko ging sluiten was het solliciteren, had consigne IT aal de telefoon en kon zo 5000 gulden per maand verdienen, december 1997 hebben we het over, in 2 dagen een vet contract met auto van de zaak
en hullie maar zeuren dat ze niet aan personeel konden komen met opzegtijden van een half jaar, maar ik zag de bui al hangen, door heel het land crossen en 100 uur per week maken waarvan de helft in de files, ik heb er netjes voor bedankt, 2 jaar later was het bedrijf opgekocht, zo kan ik nog wel ff doorgaan.
Kort erna kwam ik bij een produktie bedrijf met soortgelijk netwerk, manmanman, waar was ik terecht gekomen zeg, wat in een ravaaaaaaaaaage, de hele dag ging de telefoon en vaak boze telefoontjes, mijn 4 voorgangers hadden het zelf ingericht met hun HTS opleiding linux was niks want windows liepen ze mee weg, ja, die bagger van win95 en ze programmeerde wel in DOS, daar was het kennelijk toch te goed voor en ik had in die tijd thuis een webserver draaien op debian die in belde, wat een superprutsers zonder enige inzicht en verstand en vet dure opleidingen, ze vonden zich zooooooo geweldig goed, wat nou in een ivoren toren zitten want de rest was allemaal dom klootjesvolk, ja, sorry mensen, ik kan er niks anders van maken helaas.
Die 2 regels die ik eerder noemde daar scheelt er nogal wat aan op 95% van websites, ik downloade vorige week de NPO app en na 5 minuten heb ik hem verwijderd en in nette woorden heb ik via de mail mijn frustratie kenbaar gemaakt, je moet tig schermen door.... waarom zo ingewikkeld ?
Er is zeker een personeelstekort in de ICT. En ook voor mensen boven de 50 is er werk zat.
Goed bedoelt advies: Heb het niet over superprutsers in ivoren torens en over de al dan niet waardeloze dure opleidingen van andere, maar focus op de vaardigheden die jezelf hebt en die relevant zijn op dit moment en van toegevoegde waarde voor het bedrijf waar je solliciteert. Dat willen mensen die iemand aannemen horen.
tegelijkertijd wil de politiek de toestroom van buitenlandse kennis en studenten flink verminderen en is het erg moeilijk om de goed geschoolde vluchtelingen aan het werk te zetten. Terwijl er tekort is aan kennis...
Dit is natuurlijk onzin. Simpel voorbeeld een aantal weken geleden op tv:
Een fotograaf die een foto van een model maakt en in een AI-gegenereerde studio plaatst. De studio-ontwerper/beheerder heeft nu dus geen opdracht meer.
Het betrof hier een foto van een ruiter in een paardenstal. Het model stond netjes in z'n ruiteroutfit (wat de officiële term ook is) z'n ding te doen. En de fotograaf deed haar ding. De mensen die de studio opmaken (die dus van een studio een 'paardenstal' maken kwamen er niet meer bij te pas).
De fotograag was er erg blij mee, want zij kon zich nu meer focussen op haar model, en ze kon achteraf nog een emmer verplaatsen op de achtergrond of zelfs de hele stal als dat nodig is.
De fotograaf was overigens van mening dat 'op dit moment' AI nog niet goed genoeg de menselijke factor kan vervangen van het model, maar dat het voor het ontwerpen van een studio een prima kosten-efficiënte methode is.
AI gaat zeker weten mensen vervangen. Ik zeg niet dat dat erg is voor het grote plaatje. Uiteraard is het op z'n zachtst gezegd zuur als je door AI je baan kwijt bent, net als 10 telefonistes die vroeger fysiek telefoonlijnen doorschakelden werden vervangen door een automatische telefooncentrale, of 20 koetsiers die zijn vervangen door 1 buschauffeur. Maar we moeten ook inzien dat het een nieuwe stap is.
Er worden nog steeds schilderijen gemaakt. Er worden nog steeds analoge foto's gemaakt. Muziek wordt nog steeds door mensen gecomponeerd en gespeeld. En afgespeeld via vinyl. Mensen rijden nog steeds in klassieke auto's.
Allemaal zaken die technisch imperfect zijn. Werk zal veranderen en sommige banen zullen verdwijnen. Maar een fotograaf van het kaliber Anton Corbijn wordt niet vervangen door AI. Net zoals nieuwsfotografen, bruidsfotografen etc niet vervangen gaan worden door AI. Op het gebied waar impact zal zijn, is dat er al lang. Zo staan de autofolders al jaren gewoon vol met renders van de auto's en dat is ook steeds meer het geval bij andere producten. Daar was geen AI voor nodig, want dat is gewoon het gevolg dat alle ontwerpen met CAD en aanverwante systemen worden gemaakt.
Ik zeg niet dat er door AI geen studio's meer gemaakt worden. Ik zeg niet dat AI iedereen z'n werk gaat vervangen. Ik zeg alleen dat AI weldegelijk mensen gaat vervangen. Niet alle mensen. Maar wel een aantal. En die mensen zullen dan dus ander werk moeten gaan vinden.
Ik denk dat je zelf eens met chat GPT moet werken. Er bestaat een gratis versie van die je een beter beeld geeft wat het kan en wat het niet kan.
Op termijn heb je gelijk, AI gaat er veel jobs overnemen. De copywriter verdient alvast niets meer aan mij sinds GPT.
Ook kan ik meer werk verzetten waardoor de nood aan een collega minder wordt. Net zoals de automatische haagschaar of traktor ook voor minder arbeiders heeft gezorgd. Boeten produceren nu ook meer voedsel met minder mensen. Dat is nu eenmaal het effect van automatisering.
precies. Ik kreeg gisteren een opdracht iets aan te passen in een grafiek, geschreven met vega-lite. Ik kende dat hele systeem niet, maar mbv chatGPT kon ik het probleem in de grafiek binnen 10 minuten oplossen.
Als ik de manual van vega-lite had moeten doorlezen was ik waarschijnlijk langer bezig geweest. Nu heb ik die manual gebruikt om te controleren of de door chatGPT voorgestelde wijzigingen correct toegepast waren (dat was zo).
Wat heb ik geleerd: 1) iets over een voor mij tot nu toe onbekend framework, 2) waar in syntax is zou moeten zoeken en 3) waar in de manual ik moet kijken voor de controle.
Het hele systeem kom ik waarschijnlijk buiten dit project nooit meer tegen, dus tijd investeren om het te leren was verloren geweest. Nu heb ik iemand kunnen helpen, dankzij AI. Controle blijft echter gewoon nodig, net zoals je suggesties van menselijke hulp zou controleren.
Omdat mensen graag het gevoel willen hebben dat ze persoonlijk geholpen worden, en geen zin hebben om met een robot we worstelen. Hierdoor kun je uiteindelijk minder mensen hiervoor inhuren, waardoor die mensen nuttigere dingen kunnen doen dan aan de klantenservice hangen.
mensen hebben nu geen zin om met een robot te worstellen omdat de chatbots nog van lage kwaliteit zijn. Laatst wat ervaringen met chatbot van duidelijk hogere kwaliteit. Ik denk dat er iets van GPT3.5 (of GPT4) achter zat. Dat was heerlijk, ik had wat redelijk ingewikkelde vragen die ik ook nog eens krom formuleerde omdat ik er zo snel niet uitkwam. Perfect antwoord inclusief toelichting. Veel beter als de gemiddelde call center medewerker.
Ik denk dat over een paar jaar mensen veel minder problemen gaan krijgen met die chatbots.
Waarom moet een chatbot menselijk lijken. Ik denk dat het beter is dat je merkt dat het een machine/software is. Wat belangrijker is dat het antwoord dat je krijgt correct en betrouwbaar is.
Mee eens, maar de huidige generatie chat AI is alleen maar ontworpen om te chatten, niet om betrouwbare/ware informatie te verstrekken.
Je kan een chatbot wel vragen om alleen de waarheid te vertellen en die kan daarop "ok" zeggen, maar het heeft er geen benul van wat waarheid is - ook al kan het desgevraagd wel een definitie van waarheid geven. AI "hallucinatie" is technisch gezien niet een glitch, het ontstaat in het AI brein op exact dezelfde manier als 'waarheid': woorden en zinsdelen aan elkaar brijen zodat het resultaat lijkt op menselijke taal.
Correcte en betrouwbare informatie geven is veel moeilijker dan chatten en vergt een ander aanpak; AI heeft daarvoor de "wereldkennis" (oftewel een World Model) nodig die in het artikel wordt genoemd, en een world model maken is heel wat anders dan taalmodel.
Wij mensen werken zo het beste. Wij zien het menselijke in honden, in stenen op Mars, in de manier waarop moeder Merel een worm in haar kuiken propt. Het is niet moeilijk om mensen het menselijke te laten ontdekken in de meest bizarre zaken. We zoeken het, niet eens bewust, dus als we het vinden dan zijn we gelukkig.
: "Via GitHub vond ik vervolgens verschillende stukjes opensourcecode die ik zou kunnen gebruiken, maar vaak zonder uitleg waarom het op die manier zou moeten."
Met alle respect naar de dame in kwestie (die ongetwijfeld heel veel verstand van heeft van linguïstiek), na een Python-cursus van een half jaar zelf een AI gaan trachten te ontwikkelen daar zet ik toch mijn vraagtekens bij...
"Je kunt voor een dergelijke chatbot alle mogelijk vragen en antwoorden in een JSON-bestand verwerken; voor iedere optie krijgt de chatbot een aantal trainingszinnen." Mocht de bot niet overweg kunnen met een verzoek, dan kunnen ontwikkelaars gebruikmaken van een fallback message. Dit is een standaardterugkoppeling aan de gebruiker om een vraag anders te formuleren of in het geval van een klantenservicebot om contact op te nemen met een menselijke medewerker. Overigens heeft RoboCoppi er geen: "Mijn bot is juist blij met vragen waarop hij het antwoord nog niet weet."
Dit klinkt als de non-AI chatbot die in het kopje "Hoe vormt AI een zin?" wordt beschreven die op basis van if/else statements antwoorden geeft.
na een Python-cursus van een half jaar zelf een AI gaan trachten te ontwikkelen daar zet ik toch mijn vraagtekens bij...
Kijk eens op Twitter of TikTok of dergelijke andere platformen naar hoeveel mensen er zijn die een app hebben 'ontwikkeld' en gelanceerd op app stores (en er zelfs geld voor vangen!) terwijl ze zelf geen regel code kunnen schrijven. Zoiets zal hier ook gebeurd zijn, door aan ChatGPT te vragen 'hoe maak ik een AI chatbot' en daarna bij ieder antwoord door te vragen tot er genoeg informatie uit komt.
Voor een eigen experiment is het natuurlijk prima en een leuke oefening, maar het heeft heel weinig met het onderwerp van dit artikel te maken..
Nee maar dat is ook een beetje wat ik bedoel natuurlijk. Er zal ongetwijfeld een app of applicatie uitkomen die 'iets' doet, maar een full-scale AI op basis van deze ervaring en met deze mankracht daar zet ik toch mijn vraagtekens bij. En inderdaad, weinig relevant voor dit artikel.
Mwa, ze plukt wat van GitHub. Volgens mij wordt AI in de praktijk al veelvuldig ingezet en scoort de AI veel beter in correcte én empathische antwoorden geven dan de gemiddelde klantenservice medewerker. Dus ik snap haar benadering niet goed.
Tja, 'from scratch' is sowieso al een vage term. Moet je dan de libraries zelf bouwen? De compiler zelf bouwen? De computer zelf bouwen? Python zelf is publiek beschikbaar, net als bakken libraries die met 3 commandos een LLM voor je binnenharken en opstarten. Weet je dan wat het doet? Neuh, maar er zijn ook niet gek veel programmeurs meer die nog weten hoe die python-code omgezet wordt naar losse machine-instructies, en dat hoeft ook niet. We hebben immers vrij goede abstractielagen. De relevante vraag voor deze mevrouw (en de vele andere programmeurs die 'from scratch' werken) is vanaf welke abstractielaag ze werken.
Ik heb het idee dat dit mensen die term gebruiken omdat ze hem zelf moeten compilen (yknow, zoals dat praktisch altijd gaat als je sourcecode download) en dat het dus geen kan-en-klaar gedownload programma is. Voor mensen die nieuw met de stof zijn klinkt dat namelijk als heel wat en dus "from scratch" (compleet aannames, overigens)
die getallen met het AI model omzetten naar andere getallen
en die getallen weer omzetten naar text
Voor elk van die stappen is een library voor. En er zijn AI en text modellen vrij verkrijgbaar. En dan is het alleen een kwestie van die aan elkaar te koppelen. Met de Langchain library is dat middels een paar statements en variabelen te doen.
Zelf een AI model maken is afhankelijk van wat je ermee wilt doen. En dan kan het vrij makkelijk zijn door gewoon tekst "in het model te stoppen". Ik denk dat vrij veel mensen wel een stukje tekst kunnen intypen.
Het grote werk zit oa in:
Bepalen wat je met het model wilt
De juiste modellen koppelen
De modellen van voldoende informatie voorzien
Performance van het model
Kortom: veel werk die een onderzoeker kan doen zonder dat je een programmeur moet zijn.
Dit is zeker wel een AI chatbot. Die "if/else statements" benaming is kleutertaal van T.net; normaal gesproken noemen we dit soort AI's expert systems. En ja, die zijn dus conceptueel al 50 jaar oud, en praktisch gesproken achterhaald.
Zo zie je in deze implementatie het idee van "standaard vragen". Dan moet je als chatbot gebruiker dus raden welke vragen mevrouw van Oosten heeft opgeschreven. Dit is erg irritant - ik ken het van mijn auto. Inmiddels weet ik dat die de term "routebegeleiding" kent, maar "navigatie" niet. Een LLM weet dat die twee in context identiek zijn.
AI-gegenereerde teksten lijken vaker hoofdzinnen te gebruiken. Eigenlijk heel verfrissend, want de hoofdzin wordt steeds minder gebruikt door menselijke schrijvers, ten faveure van zinsstructuren die uit de spreektaal komen (zal ook wel komen door het fenomeen ontlezing).
Op een bepaald forum waar ik dagelijks kom komen dagelijks vele spambots binnen en doen dan een 1e post op een willekeurige topic. Ook hier lijkt chatgtp veelvoudig ingezet te worden om het topic te lezen en dan een soort enceclopedie text uit te spugen om de 1e post enigzins ontopic te houden. Helaas voor de bot is de text dusdanig als gegenereerd herkenbaar.
Het overal gebruiken van gegenereerde plaatjes zoals bij dit artikel, begint me inmiddels enorm te irriteren. Een passende foto is zoveel krachtiger. Net als het lukraak inzetten van, behoorlijk vaak, slechte chatbots.
Ik werk bij een van de grotere ondernemingen in Nederland en ook wij zijn druk bezig om overal Copilot en ChatGPT in te proppen. Ik hoop dat we (en de wereld) scherp blijven en dat de visie 'achter elke functie zit straks een LLM', nooit bewaarheid wordt.
Overigens ben in mede verantwoordelijk voor het introduceren van deze technologie in ons bedrijf en weet ik ook inhoudelijk meer dan gemiddeld van waardoor ik, nu nog, wat op de rem kan trappen.
Neem bijvoorbeeld het probleem met Microsoft (365) Copilot. Hoe kun je blijven voldoen aan de 'right to be forgotten act' als klantdata in allerlei nieuwe gegenereerde content komt?
Met de ontwikkeling van LLMs en GenAI gaan het lastige jaren worden.
We zijn als mensheid nu eigenlijk pas de gevolgen van internet aan het zien, ontdekken en proberen in te perken.
Ik kan me voorstellen dat we over 10/20 jaar ons ook achter de oren krabben om wat we allemaal hebben gedaan/toegestaan.
Eens. Ik vind het ook enorm schrijnend dat er onderaan het artikel dan staat, "Bron: Dall-E"
Nee, onzin. De bron is een handjevol artiesten waar dit afbeelding stukjes van heeft gepakt. Dall-E is een plagiaat machine die de originele artiesten verwijderd.
Hoe kun je blijven voldoen aan de 'right to be forgotten act' als klantdata in allerlei nieuwe gegenereerde content komt?
Die klantdata mag nooit in het AI model terechtkomen. Dus bij het trainen van een model moet je al met de privacy regels rekening houden.
Je kunt dat wel als invoer gebruiken om een bepaalde output te krijgen, maar dan moet je wel die gegevens ergens vandaan halen. En die bron zou gewoon netjes onder de privacy regels van jouw data geschoond kunnen worden.
Ook die nieuw gegenereerde content zou aan die regels moeten voldoen.
Als je daar als organisatie geen rekening mee houdt, dan gaat het al ergens anders mis en kun je nog veel meer privacy problemen verwachten.
Klopt, dat mag nooit maar als je een bedrijf een product zoals M365 Copilot of GitHub Copilot afneemt heb je de garantie dat dat niet gebeurd. En dat is ook niet wat ik bedoel.
Als bedrijf is het nu al enorm moeilijk en wordt het bijna onmogelijk, dat klantdata in nieuwe door AI gegenereerde documenten of andere content terecht komt. Klantgegevens in ongestructureerde data is al een probleem, laat staan als het door een LLM wordt verwerkt en combineert met andere data. Lekker handig voor de medewerker, niet zo fijn voor de klant. Dit gaat zakelijk enorm veel discipline vereisen en dat gaat absoluut niet vanzelf. En de grote leveranciers (Microsoft, Google, Amazon, etc) werken niet mee want ze stoppen over hun AI hulpjes in.
Gegeven dat de titel van het artikel mij deed nadenken over de schrijfstijl van A.I, had ik bij het lezen van de eerste alinea direct een "Schrijft Yannick nu net zo wollig als dat ik doe, of net zo wollig als ChatGPT?".
Het was mij niet bekend dat "AI-taal" een concept is, maar dat kan ook aan mijzelf liggen.
Daarnaast 'voortdurende ontwikkeling', is niet iets wat ik zou gebruiken in een veld wat relatief nieuw is.
"Fascinerend terrein ontsloten" heb ik echt nog nooit iemand horen zeggen.
"menselijke interactie met machines steeds verder wordt verfijnd", ik denk dat 'verbeterd' eerder gebruikt zal worden.
Ook de laatste zin, met drie komma's, was alleen al vanwege dat aantal verdacht bij mij.
Maxime van stijl: wees niet obscuur of ambigu, maar wees bondig en ordelijk. "Generatieve chatbots geven vaak ellenlange antwoorden met een lage informatiedichtheid."
Zijn we dan de afgelopen vier kabinetten door een chatbot geregeerd?
Niet uit te sluiten is dat mensen (en daarmee technisch dus ook politici ), op het moment dat ze in "bullshit modus" een brei woorden moeten produceren waarbij de inhoud ondergeschikt is, inderdaad processen gebruiken die erg lijken op wat een LLM doet. Sterker nog, het is goed mogelijk dat dit het gros van ons doorsnee taalgebruik is en er maar mondjesmaat wordt aangestuurd door de "hogere systemen". Het feit dat de meesten van ons nauwelijks hoeven na te denken over wat we zeggen en hoe we het zeggen voor we tekst met samenhang kunnen produceren (en of het dan goede tekst is laat ik zorgvuldig in het midden) doet dat in ieder geval wel vermoeden.
Mijn indruk is dat ambtenaren en bestuurders een -liefst wollig- antwoord voorbereiden, dat gegeven wordt ongeacht de vraag. En als dat hilarisch uitpakt, komt het bij Lubach in de Avondshow.
Zo rond 1990 werd er aan de UvA bij Algemene Taalwetenschappen (ATW) zwaar geleund op de generatieve grammatica van Chomski, die buiten het Engels echter flinke lacunes kon vertonen. Als eerstejaars voelde ik dat al aan mijn water, maar ik kon het nog niet precies benoemen. Chomski kon dat wel, en hij heeft zijn theorie dan ook stukje bij beetje herroepen, maar ik kreeg de indruk dat die updates aan mijn docenten voorbij waren gegaan.
[...]
Staat ook in het artikel: Maxime van stijl: wees niet obscuur of ambigu, maar wees bondig en ordelijk. "Generatieve chatbots geven vaak ellenlange antwoorden met een lage informatiedichtheid."
Zijn we dan de afgelopen vier kabinetten door een chatbot geregeerd?
Spijker op z'n kop; bijkomend probleem mbt detectie van AI taal is dat ook mensen taal vaak obscuur en dubbelzinnig gebruiken - bij uitstek in de politiek (komt ook veel voor in het bedrijfsleven), en dat is bepaald niet een nieuw fenomeen, zie
Politics and the English Language
by George Orwell (ja, de George Orwell van het boek "1984") https://en.wikipedia.org/..._and_the_English_Language "The great enemy of clear language is insincerity. When there is a gap between one's real and one's declared aims, one turns as it were instinctively to long words and exhausted idioms"
Ik vraag me af hoe lang de grote sprongen in AI verbetering nog doorgaan. Op een gegeven moment is training data op. En op erg veel vragen geven de AIs nog nonsens antwoorden. Voor mijn gevoel zijn we aan het stagneren.
Ergens hoop ik dat je gelijk hebt. Immers zijn we nu toch echt op een punt beland waarbij AI een ontzettend nuttige tool kan zijn, maar menselijke input/controle nog steeds van vitaal belang is. Ik ben zelf echter bang dat de ontwikkeling wel gewoon zal doorzetten hoor.
Waar ben je bang voor?
Ik juich bepaalde implicaties juist erg toe:
Een AI klantenservice die snel reageert, je vraag begrijpt en correcte antwoorden geeft.
AI doktoren die minder vaak iets over het hoofd ziet, en vaker de juiste diagnose stelt.
AI generated code die ontwikkelaar productiviteit verhoogd.
Even terug naar de werkelijkheid (en ja, ik gebruik AI op diverse. vlakken)
Een AI klantenservice die snel reageert, je vraag begrijpt en correcte antwoorden geeft.
werkt niet zodra je met een complexe vraag komt. Diverse malen meegemaakt bij mijn contact met instanties. Ik moet soms iets regelen voor cliënten en vaak komen de medewerkers van die instanties er zelf niet eens uit, laat staan een chatbot.
AI doktoren die minder vaak iets over het hoofd ziet, en vaker de juiste diagnose stelt.
juist hier moet het een hulpmiddel zijn en doctoren MOETEN getrained worden om niet in de valkuil te trappen door de AI gegenereerde conclusie voor waar aan te nemen.
AI generated code die ontwikkelaar productiviteit verhoogd.
Dit is iets dat echt redelijk goed werkt, maar toch wordt er nog heel vaak een logische fout gemaakt door copilot en consorten. De code is semantisch dan wel correct, maar de logica absoluut niet. Laten dat nou juist de lastigste dingen zijn om op te sporen
bang voor AI, absoluut niet.
[Reactie gewijzigd door divvid op 22 juli 2024 20:23]
Volgens mij zijn de voordelen van AI op dit moment zoals je zelf aangeeft overduidelijk. Daar ben ik het dan ook over met je eens. Zelf gebruik ik ook ChatGPT 4 Turbo dagelijks en zie hier zelfs in mijn persoonlijke/werkleven duidelijk de voordelen van.
Tegelijkertijd hou ik mezelf dan ook heel bewust bij met de laatste technologie, omdat ik ervan overtuigd ben dan als je dit niet doet, je baankansen steeds kleiner zullen worden.
De mogelijke sociale gevolgen zijn echter ook niet mals. GAI is waarschijnlijk de meest ontwrichtende technologie sinds de wijde verspreiding van het internet. Destijds werd dit ook gezien als een ontzettend verbindende, positieve technologie. En ondanks dat dit in veel gevallen ook zo is (ik zou zelf nu niet meer zonder kunnen) zijn er ook veel maatschappelijke nadelen aan (de implementatie van) het web: van depressieve pubers tot verstoorde verkiezingen.
AI is net zoals elke technologie alleen maar een tool: het doet op zichzelf niets. Echter kunnen mensen het voor goed of kwaad gebruiken, en je kunt niet ontkennen dat dit laatste al massaal gebeurt (wetenschappeljke bron) en dat dus alleen nog maar zal toenemen.
Het feit dat ik straks niet meer zomaar erop kan vertrouwen dat ik daadwerkelijk met iemand spreek waar ik mee denk te spreken (bron), dat foto's en video's in rechtzaken straks veel moeilijker als bewijs gezien kunnen worden (bron), of het feit dat GAI ongetwijfeld voor een gigantische verandering in de arbeidsmarkt gaat zorgen (bron).
Onze maatschappij zal zich echt heel erg snel (gezien de snelheid van de ontwikkelingen) moeten aanpassen. Dit gaat niet gebeuren zonder horten of stoten, als het al (volledig) gebeurt. En ja, al die zorgen zijn absoluut op te lossen/omheen te werken, maar dit gaat tijd kosten.
Als gedistilleerde stackoverflow is het nuttig. Als prompted inpainting is het nuttig. Als gedistilleerde/gestolen programmeer constructies is het nuttig.
Wat deze nuttige toepassingen allemaal gemeen hebben is dat het door hoogbetaalde professionals aan het handje word gehouden. Zo gauw de modellen gebruikt worden door de wat minder oplettende werknemers is het een kwestie van tijd voordat het in het nieuws is door de stupide hallucinaties.
Ik denk niet dat dat gaat veranderen tot echte AI.
Dat is naar mijn standaard allemaal 'echte AI'. Als in een model dat zichzelf wat aanleert met training data, parameters met gewichten, en iteraties. Tenminste dat is wat ik heb geleerd tijdens de opleiding.
Ik denk dat je met echte AI bedoelt AGI, waar het model zo'n beetje alle taken beter dan mensen kan uitvoeren. Of misschien zelfs een eigen leven gaat leiden.
Ik prefereer sterke en zwakke AI. Waar zonder verdere toelichting AI, sterke AI betekent.
Maar ja, als iedereen over elkaar heenvalt om een graantje van de miljarden hype op te pikken kan ik wel begrijpen dat die benamingen nu uit de gratie zijn.
De genoemde nadelen van internet zijn naar mijn mening te wijten aan sociale media, niet internet. Dat is een wezenlijk verschil.
De vraag is of het goede opweegt tegen het kwade en of we de kwade implicaties kunnen mitigeren. En daarin zet ik met de door jou genoemde bronnen nu ook mijn vraagtekens. Het grote voordeel is dat AI in ieder geval grote voordelen kent. Social media heel weinig.
Social media is verslavende meuk waar het verdienmodel reclame door je strot rammen, plus je persoonlijke data verkopen is geworden. Met een vleugje politieke beïnvloeding, fake news en conspiracy theorists. Ik hoop van harte dat mijn kinderen er zo lang mogelijk van af blijven.
Het is echt nog maar een begin imho, alles wat ooit geleerd is over bijvoorbeeld wiskunde en taal wordt steeds verfijnder ingezet om AI te perfectioneren, dit is in mijn beleving nog maar net begonnen. Een tweet van een wetenschapper gisteren maakte al duidelijk dat claude in staat is om buiten de gebaande paden te 'denken'. Twee uur later was zijn thesis over quatum computing klaar.
Ik vraag me af hoe lang de grote sprongen in AI verbetering nog doorgaan. Op een gegeven moment is training data op. En op erg veel vragen geven de AIs nog nonsens antwoorden. Voor mijn gevoel zijn we aan het stagneren.
Als je met "trainingsdata" taalvoorbeelden bedoelt, dan ja dat is een keer op.
Maar om fundamenteel verder te komen (GAI) is een ander soort trainingsdata nodig; de AI moet getrained worden met informatie over hoe de wereld werkt, en die informatie heeft een ander vorm dan menselijke taal; dat gaat meer richting wiskunde//logica/fysica. Taal is dan een laag daarbovenop, oftewel taal op zich is niet fundamenteel.
Ik blader graag door auto occasions op een zuster pagina van Tweakers. Daar is het buiten de merkdealers bijna alleen nog ai tekst. Het viel mij op omdat er 'meer moeite' is gedaan in de tekst. Beter lopende zinnen ipv opsommingen en veel meer tekst.
Grappig die eerste alinea. Ik heb hem serieus 3x gelezen omdat ik de schrijfstijl niet des-@YannickSpinner vond. Bij alinea twee bleek dus waarom dat was
Taal en taalgebruik evolueert. Als je een AI taalmodel voedt met artikelen van de afgelopen 100 jaar, dan verweef je 100 jaar aan taalevolutie in je model. En dat zie je terug in wat het genereert.
Dan kun je natuurlijk eerst al die artikelen gaan vertalen in hedendaags taalgebruik. Maar dan zit je nog steeds met het probleem dat taal en taalgebruik verder evolueert, en dat je taalmodel na een tijdje (enige jaren al) opnieuw archaïsch zal gaan klinken. Je moet het model bij gaan houden, zoals mensen hun taalmodel bijhouden.
Wat het moeilijk maakt is dat taal, taalgebruik en wijze van denken bij mensen heel sterk met elkaar verbonden zijn. En als de denkwijze van mensen verandert, wat nou eenmaal gebeurt bij groepsdieren, verandert de taal en het taalgebruik mee. Terwijl AI, zoals we dat nu hebben, helemaal geen denkwijze heeft en dat dus ook niet met de mensen mee kan veranderen.
Het is een GPT, het heeft ooit iets geleerd en kan het geleerde gebruiken om iets nieuws uit te genereren. Maar het kan het geleerde niet aanpassen als zijn 'omgeving' (de denkwijze van mensen) verandert.
[Reactie gewijzigd door RetepV op 22 juli 2024 20:23]
Terwijl AI, zoals we dat nu hebben, helemaal geen denkwijze heeft. Het is een GPT, het heeft ooit iets geleerd en kan het geleerde gebruiken om iets nieuws uit te genereren. Het is dan ook helemaal geen AI, maar gewoon een GPT. Het is nog steeds ML.
Er zijn wel systemen (anders dan LLM/GPT) - al dan niet op basis van neuraal netwerk - die iets van een denkwijze hebben, maar dan mbt een heel beperkte expertise (schaken, Go, medische diagnose).
Daarnaast is "AI" een heel breed en vaag begrip, inclusief zoiets als "game AI". Het begrip is dan wel zo vaag dat het bijna niets zegt over datgene wat AI wordt genoemd, maat dat is hoe de term wordt gebruikt. Wat jij bedoelt met AI gaat meer richting "General AI", en daar zijn we nog ver van verwijderd.

:strip_exif()/i/2006507368.webp?f=imagegallery)
/i/2006504292.png?f=imagegallery)
:strip_exif()/i/2006504690.jpeg?f=imagegallery)
/i/2006504692.webp?f=imagegallery)

:strip_exif()/i/2006504234.jpeg?f=imagegallery)
:strip_icc():strip_exif()/i/2006334900.jpeg?f=fpa_thumb)
/i/1233670851.png?f=fpa)
/i/2006228326.webp?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2004677808.jpeg?f=fpa)
:strip_exif()/i/2005764330.jpeg?f=fpa)
/i/2006176064.png?f=fpa)
:strip_exif()/i/2004743100.jpeg?f=fpa)
/i/2006258942.png?f=fpa)
:strip_exif()/i/2006285086.jpeg?f=fpa)
:strip_exif()/i/2006076664.jpeg?f=fpa)
:strip_exif()/i/2006208068.jpeg?f=fpa)