
Onze developers hebben dinsdag development-iteratie #146 opgeleverd. Tijdens deze sprint hebben we een nieuwe databaseserver in gebruik genomen en de duiding van gesponsorde gebruikersreviews verbeterd.
Nieuwe databaseserver
Afgelopen maandag hebben wij een nieuwe databaseserver in gebruik genomen. Dankzij de replicatie van MySQL ging dit vrijwel zonder overlast voor de gebruikers.
Traditiegetrouw herhalen we bij een nieuwe databaseserver de specs van de voorgangers vanaf de eerste Artemis uit 2000. In ongeveer achttien jaar hebben wij de databasesever geüpgraded van twee singlecore PIII's op 733MHz naar twee zescore-3,4-4,0GHz Xeon 6128 Gold-cpu's. Ook het geheugen is aardig gegroeid sinds de eerste Artemis en de nieuwe server heeft met 512GB geheugen maar liefst 341 keer meer dan zijn tegenhanger in 2000.
Om ervoor te zorgen dat de database na een reboot ook nog data bevat, hadden we in de eerste iteratie de beschikking over drie 18GB-Cheetah's in raid-5 die 15.000 keer per minuut een rondje draaiden. De laatste databaseserver heeft uiteraard geen ronddraaiende platters meer, maar heeft de beschikking over vier 960GB Intel S4500-ssd's in raid-10. De volledige lijst met servers die trouw jullie reacties en forumposts hebben opgeslagen, staat hieronder.
| Naam | Cpu | Geheugen | Opslag |
|---|---|---|---|
| Artemis 1 | 2x PIII 733MHz-1GHz | 1,5GB-4GB PC133 sdr | 1x 20GB ata 3x Seagate Cheetah X15 18GB |
| Apollo 1 | 2x PIII 1GHz | 2GB-4GB PC133 sdr | 2x Quantum Atlas 10K II 18GB |
| Artemis 2 | 2x Athlon MP1600+ 1,4GHZ | 2GB ddr-266 | 1x 20GB ata 5x Seagate Cheetah X15 18GB |
| Apollo 2 | 2x Athlon MP 1900+ 1,6GHz | 3,5GB ddr-266 | 1x 20GB ata 5x Seagate Cheetah 36XL 36GB |
| Artemis 3 | 2x Opteron 246 2,0GHz | 4GB ddr-266 | 2x Seagate Cheetah 18XL 9GB 4x Seagate Cheetah 10K.6 36GB |
| Apollo 3 | 2x Opteron 242 1,6GHz | 6GB ddr-266 | 6x Seagate Cheetah 10K.6 36GB |
| Artemis 4 | 2x Opteron 254 2,8GHz | 8GB ddr-333 | 2x Seagate Cheetah 10K.6 36GB 6x Seagate Cheetah 15K.3 36GB |
| Apollo 4 | 2x Opteron 244 1,8GHz | 8GB ddr-333 | 2x Seagate Cheetah 10K.6 36GB 6x Seagate Cheetah 15K.3 36GB |
| Artemis 5 | 2x Xeon X5355 2,66GHz | 16GB ddr2-667 | 2x Seagate Savvio 10K.2 73GB 15x Seagate Cheetah 15K.5 73GB |
| Apollo 5 | 2x Xeon 5160 3,0GHz | 16GB ddr2-667 | 2x 73GB 10K SAS 15x Fujitsu MAX3036RC 36GB 15K sas |
| Artemis 6 | 2x Xeon X5570 2,93GHz | 72GB ddr3-800 | 2x Seagate Savvio 10K.3 300GB 6x Samsung-ssd 50GB |
| Apollo 6 | 2x Xeon 5660 2,80GHz | 48GB ddr3-1066 | 2x Seagate Savvio 10K.3 300GB 6x Samsung-ssd 50GB |
| Artemis 7 | 2x Xeon E5-2643 3,3GHz | 256GB ddr3-1600 | 2x IBM 250GB sata 6x Intel 256GB-ssd |
| Apollo 7 | 2x Xeon E5-2643 3,3GHz | 256GB ddr3-1600 | 2x IBM 500G sata 6x Intel S3500 240GB-ssd |
| Artemis 8 | 2x Xeon E5-2643 v3 3,4GHz | 256GB ddr4-2133 | 2x HP 80GB Value-ssd 6x HP 240GB Value-ssd |
| Apollo 8 | 2x Xeon E5-2643 v4 3,4GHz | 256GB ddr4-2400 | 2x 1TB sata 6x Intel S3510 800GB |
| Artemis 9 | 2x Xeon 6128 Gold 3,4GHz | 512GB ddr4-2666 | 2x 240GB m2-ssd 4x Intel S4500 960GB-ssd |
De oude databaseserver krijgt een nieuw leven als onderdeel van onze developmentomgeving.
/i/2002396052.jpeg?f=imagegallery)
Duiding van gesponsorde gebruikersreviews
Om de achtergrond van een reviewer beter te duiden, tonen we bij productreviews van gebruikers die regelmatig gesponsorde reviews schrijven, hoeveel reviews zij in het afgelopen jaar hebben geproduceerd en welk percentage daarvan gesponsord was. Deze informatie wordt alleen getoond bij users die twee of meer volledig of gedeeltelijk gesponsorde reviews hebben geschreven.

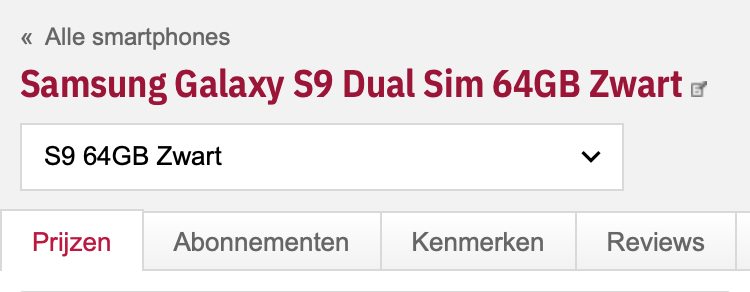
Switchen tussen uitvoeringen op mobiel
Op mobiele devices hebben we het makkelijker gemaakt om te wisselen tussen uitvoeringen van een product door een selectbox met de uitvoeringen onder de productnaam weer te geven. Voorheen was het niet mogelijk om op mobiel snel naar andere uitvoeringen van hetzelfde product te navigeren.
Ingebruikname Thumbor voor afbeeldingen in Vraag & Aanbod
In Vraag & Aanbod maken we nu net als in redactionele artikelen en de Pricewatch gebruik van Thumbor voor het verkleinen van afbeeldingen. Dit levert een sneller uploadformulier op, omdat het maken van verkleiningen op verzoek en asynchroon plaatsvindt.
/i/2000621227.png?f=fpa)
/i/2001558181.png?f=fpa)
:strip_icc():strip_exif()/u/496922/Balance%252060x60.jpg?f=community)
/u/1830/acm.png?f=community)
/u/8/oog3.png?f=community)
:strip_icc():strip_exif()/u/268386/crop56fea987ec56c_cropped.jpeg?f=community)
:strip_exif()/u/47900/baph.gif?f=community)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
:strip_icc():strip_exif()/u/63694/crop6a6312e79bbab_cropped.jpg?f=community)
:strip_exif()/u/4143/crop673c629560e43_cropped.gif?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/5964/crop56503163e97a5.jpeg?f=community)
/u/4024/burne.png?f=community)
:strip_icc():strip_exif()/u/230241/crop5db74093e7dc1_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/76569/garfield14.jpg?f=community)
/u/29147/crop685ebf24d1183_cropped.png?f=community)
/u/461196/crop5ef06eeb3da93_cropped.png?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
:strip_icc():strip_exif()/u/56108/STRESSED_1.jpg?f=community)
/u/98401/crop57b85f51b147a.png?f=community)
:strip_exif()/u/42444/nimic_icon60.gif?f=community)
/u/1/femme.png?f=community)