Arm heeft tijdens zijn jaarlijkse Client Tech Days zijn plannen voor het komende jaar onthuld. Daarbij geeft het een uitgebreide blik op de 'bouwstenen van de bouwstenen' die je de komende jaren in Arm-socs van diverse fabrikanten voor onder meer smartphones en tablets kunt verwachten. Uiteraard speelt AI daarin een grote rol, en natuurlijk worden de cpu- en gpu-cores weer een stukje krachtiger en zuiniger. Arm gaat echter ook zijn service uitbreiden; het ontwerpbedrijf gaat voortaan bijna kant-en-klare ontwerpen voor 3nm-productie voor zijn cores aanleveren, waar het voorheen enkel de bouwstenen daarvoor leverde.
CSS
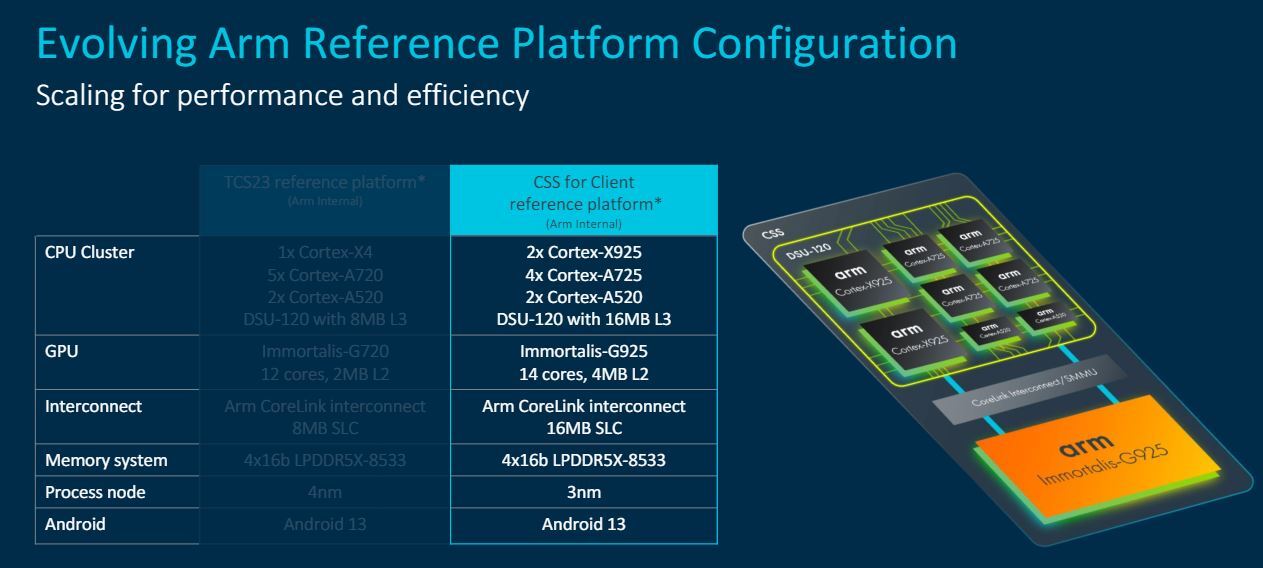
De term CSS heeft niets met de opmaak van webpagina's te maken, maar wordt al langer gehanteerd in de servertak van Arm. Voor die servermarkt leverde Arm namelijk al een tijdje Neoverse Compute Subsystems, ofwel CSS. Dat zijn bijna complete, geoptimaliseerde ontwerpen die in een chipdesign gebruikt kunnen worden. Voor de clientafdeling leverde Arm tot dusver alleen zogeheten rtl-ontwerpen, die slechts een schematische voorstelling van de gebruikte gates en transistors vormen. Met de stap naar CSS levert Arm complete ontwerpen, die bekendstaan als GDSII, voor zijn cores. Zo'n ontwerp is eigenlijk een compleet ontwerp voor een fabrikant als TSMC of Samsung: de zogeheten tape-out.
Arm Tech Day 2024: CSS tape-out
Het voordeel van CSS for Client, zoals Arm dit initiatief noemt, is meerledig. Zo kunnen socfabrikanten, denk bijvoorbeeld aan MediaTek, Qualcomm en Samsung, de Arm-ontwerpen veel sneller in hun producten integreren. Dat betekent minder kosten voor de implementatie en een kortere periode tussen ontwerp en productie. Bovendien heeft Arm de optimalisaties al voor zijn klanten uitgevoerd. Zo zijn de GDSII-ontwerpen helemaal geoptimaliseerd voor hun 'target node', zodat ze zoveel mogelijk prestaties uit zo weinig mogelijk vermogen halen.
Die target node is voor deze eerste generatie CSS for Client de 3nm-node van TSMC en de 3nm-node van Samsung. Klanten kunnen dus kiezen bij welke foundry ze hun producten laten maken. De voorloper van CSS for Client, sinds 2021 bekend als Total Compute Solutions, was de laatste twee jaar geoptimaliseerd voor 4nm-chips. Met de verkleining van de node en de optimalisaties van Arm zelf, dat zijn ontwerpen natuurlijk als geen ander kent, is de kloksnelheid van de nieuwe generatie ook verhoogd. De snelste cores, de X-cores dus, hebben als doelkloksnelheid 'meer dan 3,6GHz' gekregen. In de praktijk blijkt die kloksnelheid zelfs 3,8GHz te zijn, terwijl eerdere ontwerpen voor 3,3GHz geoptimaliseerd waren.
Arm Tech Day 2024: referentieplatform
Arm levert voor alle duidelijkheid geen complete soc. Dat deed het niet met de verschillende TCO-varianten en dat doet het niet met CSS. Wel levert het net als vroeger alle losse bouwstenen. Alleen zijn de bouwstenen voor de cpu- en gpu-cores nu optioneel leverbaar als kant-en-klare bestanden die naar TSMC of Samsung voor 3nm-productie gestuurd kunnen worden. Het bouwen van de rest van de soc moet nog wel gewoon gebeuren, al zijn de overige onderdelen wel wat minder 'kritisch' dan de cores. Er is overigens wel een referentieplatform en Arm begeleidt desgewenst ook de ontwikkeling van de overige onderdelen van de soc. Naar die cores en de overige onderdelen kijken we op de volgende pagina's.
De nieuwe cpu-cores
Arm splitst zijn cpu-cores al sinds jaar en dag op in grote en kleine cores. Sinds een paar jaar zijn daar de X-cores bovenop gekomen: de krachtigste cores die het bedrijf ontwerpt. De DSU, of DynamIQ Shared Unit, knoopt alle cores aan elkaar. De voormalige grote cores, ooit de big cores in het big.Little-tijdperk, zijn met de introductie van die X-cores eigenlijk midcores geworden. De kleine cores zijn nog steeds de kleine cores en omdat daar heel weinig mee gebeurd is voor de nieuwe generatie CSS for Client, beginnen we daarmee.
Arm Tech Day 2024: overzicht Cortex-cores
A520
De kleinste cores hebben geen nieuwe naam gekregen, zo weinig is eraan veranderd. Vorig jaar, als onderdeel van TCS2023, noemde Arm de kleine, zuinige cores al Cortex-A520. Voor CSS for Client (let op: Arm noemt geen jaartallen meer) heten de ukkies nog steeds A520. Ze zijn wel geoptimaliseerd voor de 3nm-node van Samsung en TSMC, indachtig het aanbieden van productiebestanden in de vorm van GDSII. Dat brengt optimalisaties met zich mee wat energiegebruik en prestaties betreft. De power-performancecurve van de nieuwe A520 zou bij gelijke prestaties tot 15 procent zuiniger zijn dan de A520 van TCS23.
Arm Tech Day 2023: Cortex-A520
A725
De midcores zijn de cores die in de praktijk een groot deel van het werk voor hun rekening nemen. De kleine cores doen vooral kleine achtergrondtaken, terwijl de grootste cores vooral bursty workloads voor hun rekening nemen: korte, intensieve taken, zoals het starten van apps. Omdat de A7xx-cores veel werk moeten verrichten, is powerefficiency een belangrijke focus voor de cores. Om de prestaties te verbeteren, is de microarchitectuur dan ook aangepakt. Daarmee moeten met name gaming- en AI-prestaties worden verbeterd. De cores worden daarbij weer geholpen door optimalisaties voor productie op 3nm. Die node-shrink maakt het onder meer mogelijk om twee keer zoveel L2-cache aan de cores te geven, terwijl de dieoppervlakte gelijk blijft.
Arm Tech Day 2024: Cortex-A725
De A725 werd, behave voor efficiency, vooral geoptimaliseerd voor twee belangrijke taken: gaming en AI-toepassingen. Beide profiteren van meer geheugensnelheid, maar met name AI-toepassingen zijn sterk geheugenafhankelijk. De grotere L2-cache, tot 1MB per core, moet die workloads dan ook versnellen. Naast caches zou ook een toename in geheugenbandbreedte naar de DSU prestatiewinst opleveren, maar dat zou ten koste gaan van de efficiency van de cores. Wel is de microarchitectuur op diverse vlakken verbeterd: de registers en reorder buffers zijn aangepast en de core heeft voortaan vier issue qeueus voor instructies, waar dat er bij de A720 nog drie waren.
Arm Client Tech Day 2024: A725
Al die verbeteringen moeten de A725 aanzienlijk efficiënter maken. Arm spreekt van een efficiencywinst voor prestaties van maar liefst 35 procent ten opzichte van de A720. De powerefficiency is met 25 procent gestegen en een van de grotere energieslurpers, toegang tot het in de DSU gelegen L3-cache, is dankzij een betere prefetcher met 20 procent verbeterd. Dat resulteert in de behoorlijk naar rechts opgeschoven curve voor prestaties versus vermogen van de A725 ten opzichte van de A720. Het resultaat is dat de midcores meer kunnen doen met minder vermogen. Zo verlengen ze de accuduur van je telefoon, verbeteren ze het verbruik van een ander apparaat waarin de A7xx-cores een hoofdrol spelen of schroeven ze juist de prestaties op.
X925
De krachtigste core heet niet X5, zoals je misschien zou verwachten op basis van eerdere generaties, maar X925. Daarmee impliceert Arm ook dat het een andere weg inslaat met de ontwikkeling van deze supersnelle cores. De veranderingen zijn dan ook veel uitgebreider dan bij de A725- en A525-cores. De belangrijkste daarvan is een flinke stap in rekenkracht. Bij gelijke kloksnelheden en overige configuratie moet de X925 tot 15 procent sneller zijn: een flinke ipc-winst dus. De verwerking van AI-workloads is, afhankelijk van de toepassing, met 20 tot 30 procent versneld. Als de referentie-X4-cores worden vergeleken met de X925-cores compleet met systeem- en softwareoptimalisaties, is de winst zelfs 36 procent. Net als bij de overige cores optimaliseert Arm daarbij niet specifiek voor benchmarks. Die vormen immers geen eerlijke afspiegeling van normale werkzaamheden. Sterker nog, een van de caches is verkleind omdat die alleen voor benchmarks interessant is, maar voor normaal gebruik onnodig.
De stadia van de X925: frontend, core en backend, zijn alle drie aangepakt om de ipc-verbeteringen, samen met een lager verbruik, mogelijk te maken. In de frontend is de instruction window size verdubbeld, want realworldapplicaties hebben overwegend complexere instructies dan benchmarks. De daaraan gekoppelde branch prediction is verbeterd. De windowsize bepaalt hoelang van tevoren instructies klaargezet kunnen worden en de branchprediction zorgt ervoor dat voorspeld kan worden welke dat moeten zijn. Samen zorgen ze ervoor dat er alvast instructies worden klaargezet en uitgevoerd, terwijl voorgaande bewerkingen nog bezig zijn en de out-of-order-core gevoed blijft met uit te voeren instructies. Verkeerde voorspellingen zijn daarbij natuurlijk ongewenst, want die leveren onnodige en onbruikbare resultaten op. Het aantal verkeerde voorspellingen is verminderd over een scala aan workloads. Ook het ophalen van instructies, of de instruction fetch, gaat sneller, opnieuw om de core bezig te houden. De L1-instructiecache is verdubbeld in bandbreedte en de bijbehorende tlb is in afmetingen verdubbeld.
Dankzij de verbeterde frontend kan de daadwerkelijke core optimaal bezet zijn. De zogeheten breedte daarvan is nog steeds 10, maar met een optimalisatie om de pipelines beter gevuld te houden. Dat zou effectief een 'bredere' core opleveren. Voor met name AI-workloads is de vectorisation-bandbreedte, of de bandbreedte van de SIMD/FP-executionunits, flink vergroot: van 4 naar 6 paden van 128bit per kloktik. Om die bezig te houden, is de issuequeue daarvoor verdubbeld. Ook voor hele getallen (integers) is meer bandbreedte beschikbaar voor de ALU-pipelines (Arithmetic Logic Unit) en kunnen vier in plaats van twee multiply-acties per tik worden uitgevoerd. Ook de floating point compare is verdubbeld en de core kan nu dankzij een verbeterde reorderbuffer tot 1500 instructies in de pipeline vasthouden.
Voor de backend is het aantal load pipelines van 3 naar 4 uitgebreid en is de bandbreedte van de L1-datacache verdubbeld. Zo kan de cpu voldoende 'gevoed' blijven. Verder is de backend aangepast om latency naar het geheugen op te vangen, aangezien dat veel tijd kost. De out-of-order structures zijn met 25 tot 40 procent uitgebreid en de dataprefetchers zijn verder verbeterd. Dat alles moet de prestaties van echte workloads en AI-toepassingen verbeteren. En net als voor de overige cores stelt Arm voor de X925-core geoptimaliseerde 3nm-ontwerpen beschikbaar die naar TSMC of Samsung gestuurd kunnen worden.
DSU-120
De cpu-cores worden aan elkaar geplakt met de DSU-120, ofwel de DynamIQ Shared Unit. Hoewel de DSU-120 dezelfde naam als vorig jaar heeft, zijn er aanpassingen aan gedaan. Het maximumaantal van 14 cores per DSU is onveranderd en het staat fabrikanten, klanten van Arm dus, vrij om de cores in te delen zoals ze willen. Zo zouden voor laptops alleen X-cores gebruikt kunnen worden en voor embedded toepassingen juist een paar kleine A520-cores, of combinaties van alle drie de cores natuurlijk. Naast de dubbele ringbus om de cores onderling te verbinden, bevat de DSU ook de L3-cache. Aangezien dat een behoorlijke plak silicium is, heeft Arm het energiegebruik daarvan verder aangepakt.
Arm Tech Day 2024: DSU-voorbeeldconfiguraties
De L3-cache, en de toegang tot het ram, is verdeeld in vier slices en die kunnen selectief uitgeschakeld worden. Nieuw daarbij is een zogeheten Half Slice Powerdown-feature, waarbij de helft van de slices uitgeschakeld kan worden. Daarnaast kan de helft van de geheugentoegang van alle slices uitgeschakeld worden of kan slechts één slice actief zijn. Voor maximale energiebesparing, bijvoorbeeld in stand-bymodus, kan de cache uitgeschakeld worden en alleen het snoop filter (voor ramtoegang) aan blijven. Ook kan de helft van alle L3-cache van alle slices uitgeschakeld worden, maar dit alles leverde Arm nog niet genoeg energiebesparing op. Daarom werd L3 Quick Nap Mode ontwikkeld, dat zoals de naam impliceert, het L3-cache eventueel snel kan uitschakelen. Dat levert extra besparingen op, waarbij lekstromen van ongebruikte transistors tot minder verbruik leiden.
De vernieuwde DSU-120 gebruikt tot 50 procent minder energie tijdens gewone workloads. Dat is onder meer te danken aan de overstap naar 3nm en beter energiebeheer, samen met reducties in dynamisch verbruik, als er transistors gebruikt worden dus. Specifiek van belang voor geheugenintensieve (lees: met name AI-)workloads is het 60 procent lagere energiegebruik ten gevolge van cachemisses.
De gpu's
We zouden de nieuwe generatie gpu's voor CSS for Client weer kunnen opsplitsen in drie segmenten, zoals bij de cpu-cores. Hoewel dat tot op zekere hoogte opgaat, zijn de gpu's eigenlijk allemaal hetzelfde. De segmentering zit niet zozeer in de features, maar in het aantal cores. De kleinere gpu's heten Mali, terwijl de topmodellen onder de Immortalis-vlag worden uitgebracht, specifiek de Immortalis-G925. Die laatste moet ten minste tien cores bevatten en hardwarematige raytracing ondersteunen. Over die cores en raytracing zodirect meer. De middelgrote gpu is de Mali-G725, die geen raytracing hoeft te doen en 6 tot 9 cores aan boord heeft. De kleinste gpu is de Mali-g625, met 1 tot 5 cores. Aangezien de cores in principe gelijk zijn, kijken we naar de verbeteringen in de grootste gpu: de Immortalis-G925.
Arm Tech Day 2024: gpu-overzicht
Net als bij de cpu's zijn ook gaming- en AI-workloads belangrijke focuspunten voor de gpu's. De benchmarks die Arm voor dat eerste scenario liet zien, tonen een flinke prestatiewinst van de G925 versus de G720: pakweg 30 tot 70 procent in een aantal mobiele games. Dat is wel een vergelijking van 14 tegen 12 cores, maar Arm stelde dat beide gpu's eerder tegen koel- en vermogensgrenzen oplopen dan dat de extra cores een groot praktijkverschil opleveren. Ook op het vlak van machinelearning en het paraplubegrip 'AI-toepassingen' zouden de nieuwe G925-gpu's 30 tot 50 procent sneller zijn dan de G720.
AI-verbeteringen
De AI-verbeteringen zijn onder meer het resultaat van een samenwerking met Unity. Het Sentis-framework van dat bedrijf ondersteunt FP32-berekeningen en Arm heeft samen met Unity aan INT8-ondersteuning gewerkt. Dat laatste moet een flinke verbetering in prestaties voor AI-workloads opleveren. Arm spreekt van een winst tot 44 procent vergeleken met FP32 en INT8 zou op de G925 tot 32 procent sneller zijn dan op de G720-gpu van vorig jaar. Op vragen waarom AI-workloads niet beter op een gespecialiseerde npu zouden moeten draaien, is Arm's antwoord dat ze ervoor kiezen de gpu en cpu voor dergelijke workloads te optimaliseren. De npu wordt volgens onderzoek namelijk relatief weinig ingezet; tot 70 procent van de AI-toepassingen zou overwegend op de cpu en gpu draaien. Daar komt natuurlijk bij dat Arm geen npu-ip in het assortiment heeft, dus die cpu/gpu-optimalisatie is Arm's enige optie om AI te faciliteren.
Arm Tech Day 2024: verbeteringen in machinelearning en artificial intelligence
Gameoptimalisaties
De grootste optimalisatie voor gaming waaraan Arm heeft gewerkt, heeft te maken met het renderen van overbodige objecten. Voor een willekeurige grafische scène moeten heel veel objecten worden gerenderd, maar die zijn niet allemaal zichtbaar. Denk bijvoorbeeld aan een auto in beeld; alles wat achter die auto zit, kun je niet zien en hoeft dus niet gerenderd te worden. In voorgaande gpu-generaties werden daar al technieken voor ingezet, zoals z-tests die naar diepte kijken en overlappende objecten niet renderen. De nieuwste toevoeging aan het arsenaal is Fragment Prepass.
Arm Tech Day 2024: verbeteringen in gameprestaties
Daarmee worden de prestaties van voorgaande technieken verbeterd en kan nog meer energie worden bespaard. Fragment Prepass werkt door eerst alle geometrische vormen te berekenen en daarop een zichtbaarheidstest, of dieptetest, te doen. De zichtbare fragmenten worden dan opnieuw gerenderd en dan pas gaan de shaders aan de gang om ze in te vullen. Voor Fragment Prepass is geen cpu-intensieve object sorting nodig, waardoor frames sneller en met minder energie gerenderd kunnen worden. Bovendien levert het energiebesparing voor geheugentoegang op; er hoeven immers geen onnodige, want ongebruikte textures uit het geheugen te worden geladen.
Raytracing
Twee jaar geleden, met de introductie van de Immortalis G715, bracht Arm hardwarematige raytracingondersteuning naar de Arm-soc. Afgelopen jaar, met de G720, werd dat verder verfijnd en kregen ze een eigen power island, zodat ze volledig uitgeschakeld konden worden. De raytracingunits in de G925 hebben nog steeds hun eigen eilandje en beslaan pakweg 4 procent van de shader core. Plannen om die net als bijvoorbeeld bij Nvidia los te trekken, zijn er niet. Aangezien workloads voor de rtu ook afhankelijk zijn van de overige gpu-onderdelen, zou dat weinig praktisch nut hebben. Wel zijn de raytracingprestaties verbeterd door developers te laten kiezen tussen meer performance of juist realistischer beeld. Beide scenario's vragen iets minder toegang tot het geheugen, al is die reductie in de 'high performance, less accuracy'-modus veel groter dan wanneer de nauwkeurigheid gehandhaafd blijft. Hoe die geheugenreducties precies zijn gerealiseerd, moet Arm in het midden laten, aangezien de feature niet volledig zelfstandig ontwikkeld is.
Arm Tech Day 2024: verbeteringen in raytracing
Wat Arm wel heeft bekendgemaakt over verbeteringen aan de gpu, betreft de hardwarematige aanpassingen om het maximale aantal cores in de gpu te vergroten. De Immortalis-gpu ondersteunt voortaan geen 16, maar 24 cores, waardoor extra doorvoer van onder meer de tiler en (warp-)dispatch-units nodig is. Die tiler heeft in optimale gevallen twee keer de doorvoersnelheid van voorheen gekregen, omdat hij met primitives van vier in plaats van drie zijden kan werken. Waar voorheen slechts één driehoekje tegelijk mogelijk was, kan de nieuwe tiler twee driehoekjes aan, mits ze een zijde delen. De vernieuwde Command Stream Frontend heeft hardware-implementaties gekregen voor functies die in oudere versies nog geëmuleerd moesten worden, ondersteunt nieuwe bitwise-instructies en heeft meer hardware-interfaces gekregen.
De gpu is verder verbeterd met ondersteuning voor 2MB grote pages in plaats van enkel 4kB grote pages, zodat tabellen minder vaak geraadpleegd moeten worden. Dat moet de prestaties verbeteren. Het aantal CVT-units in de executionunits van de shadercores is verdubbeld. Die Convert-units zijn nu in evenwicht met de FMA-units. Voor machinelearning passeerde de verbeterde performance van INT8 al eerder de revue; daarnaast zijn voor gaming de VRS-prestaties verbeterd.
Net als de cpu-cores zijn ook de gpu-cores als kant-en-klare 3nm-bestanden bij Arm verkrijgbaar. Let wel: dat betreft geen complete gpu's, maar enkel de cores, waar de optimalisaties en validaties voor het lastige 3nm-procedé het meest complex zijn.
Software en slot
Met CSS for Client heeft Arm weer een stap gezet in een aanpak die je holistisch zou kunnen noemen. Het levert niet alleen de bouwstenen voor de cores, maar beweegt steeds meer naar een complete aanpak. Met Total Compute Solutions heeft Arm sinds 2021 al een flinke stap in die richting gezet, maar met CSS gaat het veel verder. Dankzij co-optimalisaties van hard- en software kan het maximale uit de chips gehaald worden. De hardwarekant hebben we uitgebreid besproken, zowel wat het ontwerp betreft als wat de optie betreft om de TSMC- danwel Samsung-fähige architecturen, geoptimaliseerd voor 3nm-productie af te nemen. Dat scheelt fabrikanten veel tijd en moeite om hun socs productiegereed te krijgen en belangrijke aspecten als voltage frequency tuning voor de diverse cores uit te voeren. De architectuur, en de complete soc, functioneert echter maar zo goed als de software die er gebruik van maakt, en ook daar timmert Arm verder aan de weg.
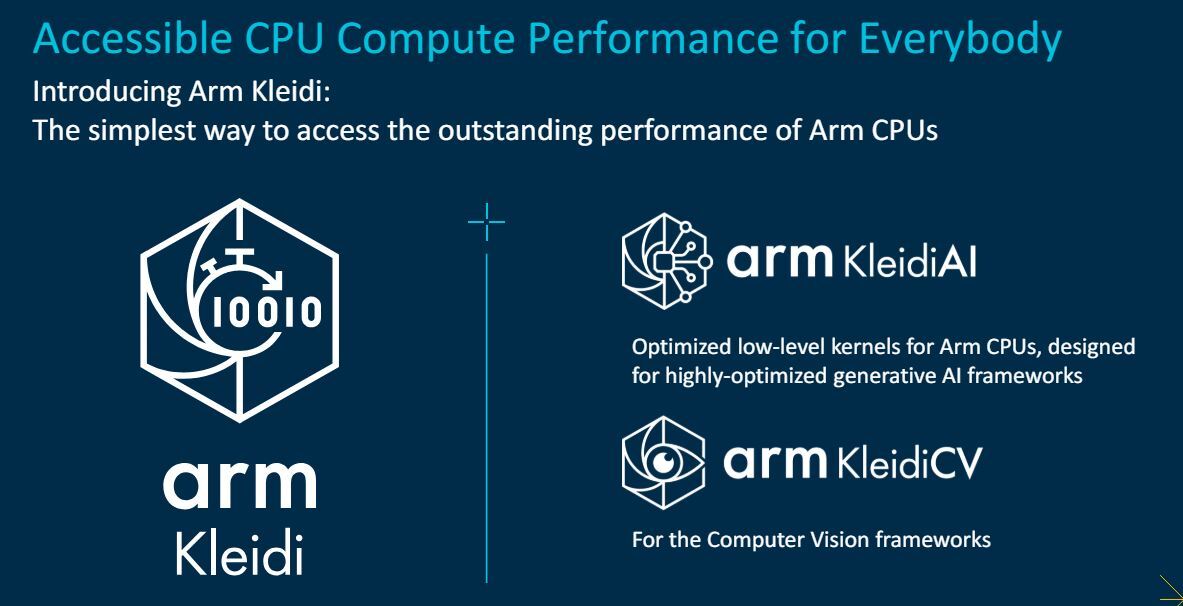
Want terwijl de hardwareproductcyclus steeds sneller gaat, moeten developers die ontwikkelingen wel bij kunnen houden en gebruik kunnen maken van nieuwe features. Een van die features is de onvermijdelijke AI, die in rap tempo in toepassingen en ontwikkelingen groeit. Een sprekend voorbeeld is imagegeneratie op een Pixel 7 Pro. In oktober 2022 duurde dat met Stable Diffusion en PyTorch nog 300 seconden; iets meer dan een jaar later was dat 8,5 seconden met InbstaFlow + Dreamshaper met ONNX. In plaats van op één paard te wedden wil Arm daarom optimale prestaties op zoveel mogelijk apparaten en met de 'software du jour' mogelijk maken. Arm heeft de hardware daarvoor geschikt gemaakt, zonder npu, met onder meer verbeterde INT8- en andere instructies om inference en vectorberekeningen te versnellen. Aan de sofwarekant heeft het bedrijf daartoe nieuwe library's ontwikkeld. De belangrijkste library voor AI heet Kleidi, dat device- en softwareagnostisch goede prestaties mogelijk moet maken. Voor AI-toepassingen is er KleidiAI en voor aan computervisie gerelateerde toepassingen KleidiCV.
Arm Client Tech Day 2023: Arm KleidiAI en KleidiCV
Kleidi kan met ArmV9-specifieke instructies als SVE2 en het toekomstige SME2 overweg, maar werkt ook op oudere, bestaande Armv8-apparaten via NEON. Met KleidiAI werd, als proof of concept, een prestatiewinst van 190 procent binnen 24 uur gerealiseerd met Llama3 en Phi3, twee (ChatGPT-achtige) languagemodels. De truc daarbij is dat ze lokaal draaien, zodat je je privacygevoelige data niet naar de dure cloud hoeft te sturen. Kleidi is per direct toegankelijk via GitLab en wordt door onder meer Google en MediaPipe ondersteund. KleidiCV kan onder meer ingezet worden in de verwerking van camerabeelden op je smartphone, bijvoorbeeld om een bokeheffect aan je foto's toe te voegen. Dat is, zoals je in de afbeelding in de gallery hierboven kunt zien, een workload die nogal heen en weer wordt verplaatst tussen cpu en npu, reden om dat ook in de cpu-cores te versnellen.
Arm heeft aan diverse andere software- en prestatieoptimalisaties gewerkt, van gaming tot browsing. Voor gaming wordt bijvoorbeeld Lumen, onderdeel van de Unreal Engine, voor raytracing voortaan in nieuwe Immortalis-gpu's ondersteund. WebGPU wordt gezien als alternatief voor OpenGL en OpenCL. Samen met opnieuw Google heeft Arm meegewerkt aan een WebGPU-implementatie in Chrome: Dawn, waarbij 15 procent hogere framerates werden gerealiseerd. Om dat soort verbeteringen in kaart te brengen, is Arm Mobile Studio op de schop genomen en heet het nu Arm Performance Studio. Daarmee kan onder meer de performance van Android-applicaties geoptimaliseerd worden. Daarbij helpt ook het Android Dynamic Performance Framework, waarmee developers het vermogen en de prestaties van de soc kunnen afstemmen op hun applicatie.
Tot slot
Twee aspecten schitterden niet echt door afwezigheid, maar bleken wel ondergeschoven kindjes te zijn. Arm wil niet beginnen aan de ontwikkeling van een eigen npu, terwijl veel fabrikanten die steeds prominenter naar voren schuiven. Over een core die je niet hebt, kun je niet praten, maar Arm hamerde er wel graag op dat die npu's, denk aan Googles Tensor of Qualcomms Hexagon-npu, veel minder gebruikt worden dan je zou denken. Veel toepassingen, of developers, vinden het lastig om van de cpu of gpu te switchen naar de npu. Daardoor draait volgens Arm maar liefst 70 procent van de AI-workloads op de cpu of gpu. In plaats van een eigen npu te ontwikkelen verbetert het daarom liever de AI-prestaties in die 70 procent. Ter indicatie: de cpu-clusters halen 'tot 50 procent meer Tops', waarschijnlijk vergeleken met X4-cores, en 14 Immortalis-X925-gpu's halen 20Tops.
Een tweede bijna afwezige is Windows. Slechts twee sheets, waaronder de allerlaatste, werden aan het Windows op Arm-ecosysteem besteed, met de opmerking dat steeds meer toepassingen nu native op Arm draaien. De andere sheet sprak van de 'ultieme prestaties' voor laptops, met 12 Cortex-X925-cores of een mix van 4 X925-cores en 4 A725-cores voor meer mainstreamlaptops. Als we echter kijken naar wat fabrikanten in petto hebben voor notebooks en convertibles met Windows in combinatie met Arm-socs, lijkt Arm behoorlijk omzichtig.
Aan de volgende generatie cores wordt al volop gewerkt. Volgend jaar moeten de cores Travis, Gelas en Nevis hun opwachting maken, verbonden door de Pilatus-DSU. Het topmodel gpu draagt codenaam Immortalis Drage en net als dit jaar zal Arm volgend jaar die cpu- en gpu-cores als 'fysieke implementaties' beschikbaar stellen. Eerst moeten fabrikanten echter de nu aangekondigde generatie daadwerkelijk in socs verwerken. De eerste producten met deze eerste CSS for Client-generatie zullen pas tegen het eind van het jaar verschijnen.
Ik zat er gister al op te wachten, meestal lopen Arm NDAs af op een dinsdag, en meestal de laatste dinsdag van Mei. Maar we zijn er .
Wat mij opvalt. Algemeen
De nieuwe aangekondigde GPUs zijn wederom ARMv9.2, we krijgen geen geüpdate instructieset.
Arm rekent zwaar op 3nm processen voor het verhogen van kloksnelheden.
Cortex-X925
Fancy naampje hoor! Valt nu wel makkelijker te plaatsen met de andere modellen.
Ze claimen de hoogste instruction per clock (IPC), maar geven vervolgens geen percentage ten opzichte van Cortex-X4. Wel +36% Geekbench, maar dat is met kloksnelheden dankzij 3nm erbij.
10-wide decode and dispatch width. Even breed als Cortex-X4 en Apple M4, maar nog steeds serieus werk.
6x128b SIMD engines (X4 was 4x128b). Erg interessant, ondanks dat ARM zelf met Scalable Vector Extension (SVE) ook 256 of 512 bit SIMD executie toestaat, blijven ze zelf bij de 128-bit width die NEON ook al had, zelfs bij hun grootste core.
Grotere caches, issue queues, Out-of-Order window, bla die bla. Exact wat je verwacht.
Fancy curves die niet ISO-process of frequency zijn. Hebben we weinig aan.
+50% theoretische TOPS. Als je van 4x naar 6x SIMD engines gaat klopt dat idd. Ben benieuwd of het geheugensysteem dit ook aan kan.
Cortex-A725
De meest interessante core. Hierbij moet je namelijk daadwerkelijk afwegingen maken tussen formaat en performance, in plaats van alles zo groot en hoog mogelijk. Interessante trade-offs!
New 1MB L2 cache configuration. Denk niet dat we die veel gaan zien, gezien hoe slecht SRAM schaalt naar 3nm.
Grotere issue queue en reorder buffer. Geen nummers helaas.
Wacht is dit alles? Dit is nauwelijks een nieuwe core te noemen?
Weer fancy grafiekjes. Meeste zal te verklaren 5nm naar 3nm te zijn.
Vroeger vergeleek Arm nog ISO-proces...
Cortex-A520
Identiek aan vorig jaar, maar kan 15% zuiniger zijn dankzij 3nm
Interessant aan de A520 is dat het nog steeds een in-order core is, terwijl vrijwel alle andere small-cores ondertussen wel out-of-order execution hebben. Daarmee is deze kern veel kleiner en zuiniger dan de grote cores, maar ook veel minder krachtig. Apple's "efficiency" cores zijn out-of-order superscalars en daarmee veel meer vergelijkbaar met de Cortex-A7xx serie.
Tot slot
Voelt als een klein jaar vorm Arm Cortex CPUs. Ondanks de flinke claims leunen ze zwaar op wat 3nm zou moeten brengen.
SVE (Scalable Vector Extension) en SME (Scalable Matrix Extension) zijn helemaal niet benoemd. Beide kunnen een hoop brengen in AI-performance. Arm ziet dus blijkbaar hun CPUs niet meer als plekken waar AI-modellen thuis horen. Wat begrijpelijk is met de GPUs en NPUs van tegenwoordig (hoewel CPUs altijd flexibeler blijven en breeder inzetbaar).
Vergeleken met het Apple-geweld die tussen mei vorig jaar en nu zijn gelanceerd (A17 Pro, M3 en M4), en Qualcomm die een SOTA Arm core heeft met Oryon, voelt dit alsof Arm niet in dezelfde versnelling zit. Maar wellicht verrast de X925.
Bonus: De GPUs
Ik weet iets minder van de GPUs, maar toch een paar punten.
Let niet te veel op de namen, de onderliggende architectuur is hetzelfde. Het aantal cores maakt natuurlijk wel een hoop uit.
Immortalis = verplicht ray tracing ondersteuning, Mali = optioneel (meestal dus niet)
Maximale aantal cores gaat van 16 naar 24. Grootste implementatie die we met G720 hebben gezien was MP12 (in MediaTek's Dimensity 9300), dus dat kan nu dus 2x zo groot. Wellicht leuk voor high-end laptops ontwerpen (of draagbare consoles).
Fancy techniek voor Hidden Surface Removal (HSR), genaamd Fragment Pre-pass. Snap ik weinig van, maar zou de CPU moeten ontlasten.
Er is een nieuwe ray tracing API om doelen aan te wijzen als ‘ingewikkelde objecten’, die de G925 vervolgens met verminderde resolutie traceert. Kan rond de 15% ray tracing performance opleveren (als die API gebruikt wordt).
Als je er twee cores bij gooit (12 naar 14) én op 3nm implementeert, kan je 30% tot 40% meer performance halen, en in een enkel AI of ray-tracing scenario 50%. Wat waarschijnlijk minder is dan dat je GPU gedeelte van je chip nu duurder is.
20 peak int8 TOPS in AI, voor de 14-core G925.
[Reactie gewijzigd door Balance op 22 juli 2024 16:51]
SVE (Scalable Vector Extension) en SME (Scalable Matrix Extension) zijn helemaal niet benoemd. Beide kunnen een hoop brengen in AI-performance. Arm ziet dus blijkbaar hun CPUs niet meer als plekken waar AI-modellen thuis horen. Wat begrijpelijk is met de GPUs en NPUs van tegenwoordig (hoewel CPUs altijd flexibeler blijven en breeder inzetbaar).
SVE/SVE2 zit in al deze cores en deelt met NEON de 6x128 units in de Cortex-X. Er is al SVE/SVE2 ondersteuning sinds de Cortex-X2.
De intel Intel Core i7-14700KF
3.4 GHz (20 cores)
Doet single Core 2985 en
Multi core
Intel Core i7-14700KF
3.4 GHz (20 cores)
19443
De
Intel Xeon Platinum 8462Y+
2.8 GHz (32 cores)
doet een multicore van 22271 score bij Geekbench
Bij Geekbench
De
MacBook Pro (14-inch, Nov 2023)
Apple M3 Max @ 4.1 GHz (14 CPU cores, 30 GPU cores)
3110 single core en
MacBook Pro (16-inch, Nov 2023)
Apple M3 Max @ 4.1 GHz (16 CPU cores, 40 GPU cores)
20950
Let wel, dit is een Laptop
De M4 in een iPad
3693
Single-Core Score
13402
Multi Core Score
Dus ja, Er zijn serieus snelle ARM SoC
[Reactie gewijzigd door Jan Onderwater op 22 juli 2024 16:51]
ARM projecteert een +36% verhoging in Geekbench 6 SC met de Cortex-X925, vergeleken met een 2023 premium android telefoon.
Dat plaatst de Cortex-X925 rond ~3000 in SC score.
Zoals ik eerder schreef:
Ik edit nu op dit moment 4K video op een M1max, renderen hoef nadien niet te doen, dat gebeurd tijdens het editen in de achtergrond, zonder dat ooit de fan ook maar begint te draaien. Heb hierbij ook Logic Pro draaien voor het geluid, motion, commandopost voor de kleurcorrectie en nog meer apps in de achtergrond, doet ie met links, geen zuchtje
Apple silicon als ARM voorbeeld is hele slechte.
Wat performance gain is hardware versnellers NPU video encode en decode en wat doet de cores.
Console APU hebben zeer snel on PCB systeem geheugen zoals G-kaarten hun V-ram hebben geen dimmslot eind verder weg maar directe rond de SoC/apu Ramchips.
M serie heeft RAM in de SoC routing is op Soc package niveau. Afhankelijk van de 100 200 400 GB/s voor M1 Dat is alsof van EMM L3 L5 cache op xbox soc vergroot naar systeem geheugen dus L4 cache opgeschaald met normale mem tech als werk geheugen maar zeer breedt data bussen. Low latency.
X86 implementatie is 3nm 6Ghz en big daar heeft architectuur met heel veel stages dus optimised voor hoge kloks en dat gaat ook tenkoste van IPC.
ARM big is op dezelfde node lage klok architectuur veel minder stages en veel meer IPC real estate. Big little kan je dus lastig direct vergelijken.
Totdat je HBM APU krijgt en x86 architectuur is server desktop based wat naar laptops is gegaan ARM based is embedded naar laptop tablet en desktop en server.
Maar intel heeft de Ecores doorontwikkeling van Atom als je op die basis een bigcore maakt 4x transistoren op architectuur die maar ver vanaf 4ghz mag.
Ik ben het met je eens in zoverre dat synthetische benchmarks geen compleet beeld geven en dat als je voor een use case beter naar real world performance kan kijken. Als je dit doet dan zie je dat het gebied waar Apple haar SoC het nog aflegt tegen PC het gaat om de GPU performance die bij de High End GPU kaarten hoger ligtt. Dit merk je bv bij bepaalde games en bij renderen in bv Blender.
Datzelfde geldt nog altijd voor veel games. Niet alles is even goed te parallelliseren, daar zijn al best wat theoretische limieten aan. Laat staan voor de praktijk van game en software design met beperkte capaciteit, kennis, geld, tijd. Misschien heeft Geekbench dan wel een aardige balans gevonden voor gemiddelde software.
Nee, zulke grote cores maakt ARM nog niet. Tuurlijk, je kan een server chip kopen met 100+ cores maar voor normale workloads zijn ze er nog niet helemaal. De zwaarste Mac komt het beste in de buurt voor iets dat je praktisch kan gebruiken.
Ik edit nu op dit moment 4K video op een M1max, renderen hoef nadien niet te doen, dat gebeurd tijdens het editen in de achtergrond, zonder dat ooit de fan ook maar begint te draaien. Heb hierbij ook Logic Pro draaien voor het geluid, motion, commandopost voor de kleurcorrectie en nog meer apps in de achtergrond, doet ie met links, geen zuchtje.
Intel CPU zitten ook vol met hardwarematige versnellers, daarom zijn ze zo complex. AES instruction set bijvoorbeeld. ARM heeft in haar design ook steeds meer instructies in HW ingebakken. Dus ik begrijp je bezwaar niet.


:strip_exif()/i/2006728140.jpeg?f=imagegallery)
:strip_exif()/i/2006728124.jpeg?f=imagegallery)
:strip_exif()/i/2006728126.jpeg?f=imagegallery)
:strip_exif()/i/2006728128.jpeg?f=imagegallery)


:strip_exif()/i/2006728134.jpeg?f=imagenormal)
:strip_exif()/i/2006728130.jpeg?f=imagegallery)
:strip_exif()/i/2006728132.jpeg?f=imagegallery)








:strip_icc():strip_exif()/i/2006702746.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2006334900.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005803038.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005629582.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005190534.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004919500.jpeg?f=fpa_thumb)
/i/2004764978.png?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004698468.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004374656.jpeg?f=fpa_thumb)
/i/2004917904.png?f=fpa)
/i/2004628280.png?f=fpa)
:strip_exif()/i/2006989958.jpeg?f=fpa)
:strip_icc():strip_exif()/u/496922/Balance%252060x60.jpg?f=community)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/64204/crop5e333d1575fff.png?f=community)
/u/5402/crop59cd7f570677b_cropped.png?f=community)