Focus op mobiel
Traditiegetrouw hield Arm zijn jaarlijkse Tech Day, waar het bedrijf zijn nieuwe platform voor mobile computing uit de doeken doet. In de voorgaande jaren werden tijdens dat event onder meer de overstap naar Arm v9 bekendgemaakt en toonde Arm zijn eerste X-cores. Dit jaar staat in het teken van nog meer rekenkracht, nog meer cores en, misschien nog wel belangrijker, Arm hamerde op nog minder energie. Overal waar mogelijk probeert het zijn processors, gpu's en socs nog zuiniger te maken. Want wat heb je aan alle rekenkracht ter wereld als je accu binnen no-time leeg is.
Voor we dieper op de nieuwe cores en nieuwe gpu's die Arm aankondigde, ingaan, even een klein overzicht van Arm en zijn producten. Die laatste zijn er fysiek eigenlijk niet, want Arm maakt geen hardware. Wel ontwerpt Arm hardware, of eigenlijk de bouwstenen daarvoor. Dat intellectual property, of IP, wordt via licentiemodellen aan bedrijven verkocht, die ermee aan de slag gaan om system-on-chips voor bijvoorbeeld smartphones, tablets, laptops of zelfs servers te maken. Ook zitten Arm-cores in te veel microcontrollers om op te noemen, van ssd-controllers tot Arduino's. Dikke kans dat als je elektronica een microcontroller heeft, daar iets van Arm in zit. De Tech Day draaide echter om de consumententak, en dan vooral de bouwstenen die Arm voor je telefoon, tablet of laptop ontwerpt.
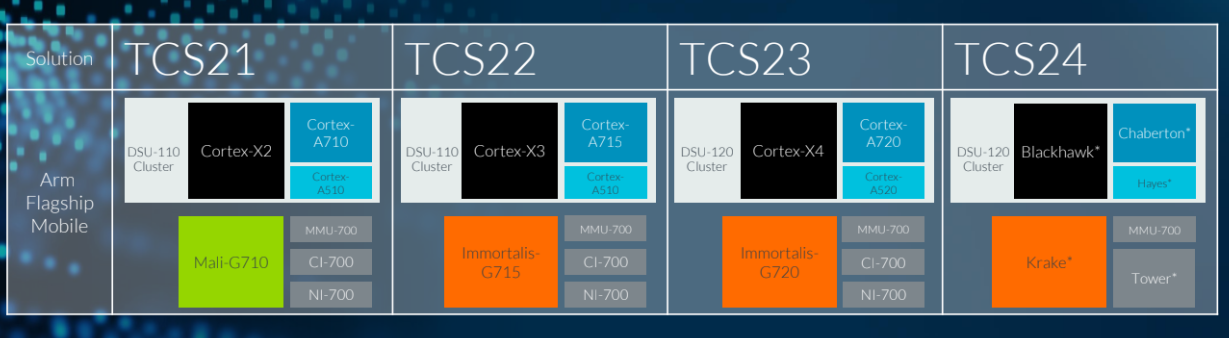
Het hart van Arms IP-aanbod zijn de Total Compute Solutions, inmiddels aangekomen bij TCS23. Daarmee krijgen hard- en softwareontwikkelaars alle tools en bouwstenen in handen om eigen socs te ontwikkelen en daar ook de benodigde softwarestacks omheen te schrijven. In een notendop bestaat TCS23 uit een basis van de Arm v9-architectuur, met daarbovenop de soc-componenten als gpu- en cpu-cores, modems en interconnects, met als afdeklaag software en tools. In dit achtergrondstuk kijken we vooral naar de bouwstenen voor de hardware: de nieuwe cpu-cores en de gpu van TCS23, en de verbindende elementen als de dsu en Corelink Interconnect.
/i/2005794124.png?f=imagenormal)
Cpu-cores: de Cortex-X4
Cortex
De cores met Arm-IP worden Cortex-cores genoemd en voor mobiele platforms zijn daar drie families relevant. Dat zijn de krachtigste X-cores, de midcores in de A7xx-serie, en de kleine, zuinige cores in de A5xx-serie. Het huidige platform, TCS22, maakt gebruik van achtereenvolgens de Cortex-X3, Cortex-A715 en Cortex-A510. Die cores zijn voor het nieuwe platform TCS23 flink aangepakt en kregen de aanduidingen Cortex-X4, Cortex-A720 en Cortex-A520. We lopen de grootste veranderingen in die cores even door. Kloksnelheden zijn natuurlijk sterk afhankelijk van de configuratie van de socs, maar Arm geeft de volgende richtlijnen door. De X4-core zou op ongeveer maximaal 3,4GHz moeten werken, de A720-cores op 2,5GHz tot 3GHz en de A520-cores zouden onder de 2GHz moeten blijven.
Cortex-X4
We beginnen natuurlijk bij de krachtigste core, de X4. Waar de X1 nog op de oudere Armv8-architectuur gestoeld was, waren de X2- en X3-cores op de nieuwe v9-architectuur gebouwd. De X4-core is een doorontwikkeling daarvan, maar maakt gebruik van de v9.2-architectuur, net als de andere twee, kleinere cores overigens. Eventueel zijn de oude v9- en nieuwe v9.2-cores te combineren in een soc, maar ze kunnen dan geen threads onderling delen, wat het hele 'big-little'-concept geweld aandoet. Je wilt immers je processen optimaal over krachtige en minder krachtige cores verdelen en ze migreren als dat vanuit een energie-efficiencyoogpunt logisch is. Als voorbeeld zou je op je telefoon de applaunch op de X-cores kunnen laten plaatsvinden, zodat je app lekker snel opstart, om het proces vervolgens over te dragen aan de midcores, die dan het normale gebruik voor rekening nemen.
De X4-core moet een flinke stap vooruit in performance opleveren. De core is, met alle parameters als cache, procedé, kloksnelheden, hetzelfde, ongeveer 15 procent sneller dan de X3-core. Hij is dan ook, zoals net aangegeven, gemaakt om kortstondige, rekenintensieve taken snel te volbrengen. De ipc-winst komt door verbeteringen in de front- en backend van de core, en in de out-of-orderexecutionunits. De L2-cache mag groter dan bij de voorgaande X-cores zijn: de X4-core ondersteunt L2-caches van 2MB. Dat moet vooral in realworldtaken voordeel opleveren: die hebben vaak uitgebreidere instructies dan bijvoorbeeld benchmarks, waardoor de winst vooral in de praktijk merkbaar moet zijn.
In de frontend van de core is vooral gewerkt aan de instructionfetch: die heeft meer bandbreedte gekregen, waardoor tien instructies verstuurd kunnen worden naar de core, waar dat er bij de X3-core nog zes of acht waren. Ook is de 'penalty' voor het verkeerd voorspellen van een instructie iets verbeterd, waardoor minder tijd kwijtgeraakt wordt als de branchpredictor fout zit. Aan die branchpredictor is niet veel veranderd: dat was al de focus van de verbeteringen aan de X3-core, maar ook bij de X4-core is daaraan gewerkt.
/i/2005794140.png?f=imagenormal)
De instructies worden door de frontend naar de daadwerkelijke core gestuurd, waar de berekeningen of operaties plaatsvinden. De out-of-ordercore van de Cortex-X4 heeft flink meer rekenkracht gekregen. Hij heeft een kwart meer alu's, meer branchunits, twee in plaats van één mac en een pipelined floating point divider. De out-of-orderbuffer, het aantal instructies waaruit de core kan putten, is uitgebreid van 320 naar 384 instructies. Sommige van die onderdelen waren bij de stap van de X2- naar de X3-core overigens ook al verbeterd.
|
Core
|
Cortex-X4
|
Cortex-X3
|
Cortex-X2
|
Cortex-X1
|
|
Alu's
|
8
|
6
|
4
|
4
|
|
Branchunits
|
3
|
2
|
2
|
2
|
|
Integer mac
|
2
|
1
|
1
|
1
|
|
MCQ/ROB
|
384x2
|
320x2
|
288x2
|
224x2
|
|
L2-cache
|
2MB
|
1MB
|
1MB
|
1MB
|
|
iFetch (instructies/klok)
|
10
|
6
|
5
|
5
|
De backend ten slotte zorgt dat de resultaten van de executiecores worden weggeschreven. Daartoe heeft de X4-core een extra Load/Store-generator, een verbetering van 25 procent. De L1-tlb-data is verdubbeld van 48 naar 96 entries. Ook de grotere L2-cache van 2MB, zonder extra latency overigens, zorgt ervoor dat meer data sneller kan worden weggeschreven.
/i/2005794138.png?f=imagenormal)
De 15 procent ipc-winst is één kant van de medaille; je kunt de core, mede dankzij de verbeteringen in vooral caches en energiebesparingen, namelijk ook als een veel zuiniger core benutten. Bij gelijke prestaties, en weer met alle andere eigenschappen gelijkgetrokken, is de X4-core tot 40 procent zuiniger dan een gelijkpresterende X3-core. Zo kun je dus nog beter de soc configureren om ofwel zuinig, ofwel snel te zijn, of een mooie balans daartussen te zoeken.
De Cortex-A720 en A520
A720
Voor de midcores, ofwel de A720, heeft Arm zich voornamelijk op de efficiency gericht, met als doel dus het energiegebruik te reduceren. Dat wil niet zeggen dat de prestaties niet verbeterd zijn, maar omdat de midcores de werkpaarden van een mobiele soc zijn, is het belangrijk ze zuinig te krijgen.
/i/2005794160.png?f=imagenormal)
De verbeteringen van de A720 zitten in de frontend, waar de penalty voor brachmispredictions voortaan elf cycles kosten, in plaats van twaalf bij de A715. Ook dit zou bij benchmarks weer niet zo'n verschil maken, maar wel in de praktijik, zo benadrukt Arm.
In de ooo-core heeft het A720-team de pipelined fdiv/fsqrt-unit overgenomen, wat bepaalde floatingpointberekeningen aanzienlijk moet versnellen zonder een grotere core nodig te hebben. Ook de issuequeues, zeg maar de wachtrij met instructies voor de core, en de executionunits waar die instructies verwerkt worden, zijn verbeterd zonder een toename van die-oppervlak.
Ten slotte is de latency voor toegang naar de L2-cache verlaagd van tien naar negen kloktikken en is het prefetchen van data uit die L2-cache verbeterd, weer met dank aan het Cortex-X-team. Dat alles zorgt ervoor dat de A720-core op vrijwel alle fronten een stukje beter presteert én zuiniger is dan de A715-core. De performancewinst en energiebesparingen zijn afzonderlijk met een procent of 4 of 5 niet zo imposant als bij de X-cores, maar toch zorgen alle verbeteringen samen voor een efficiëntieverbetering van 20 procent.
A520
De kleinste cores zijn de A520-cores. Anders dan de X-cores en A720-cores zitten die twee aan twee in een cluster. De twee cores delen sommige componenten, waaronder de L2-cache. Ze zijn vooral bedoeld voor achtergrondtaken, als je telefoon in je zak zit bijvoorbeeld, zoals periodiek berichten checken. Een zuinige A5xx-core is dus belangrijk voor een lange accuduur van je telefoon. Ook voor andere apparaten, bijvoorbeeld smartwatches, zijn deze cores van groot belang.
Arm heeft de A520 dan ook vooral zo zuinig en klein mogelijk geprobeerd te maken. De prestatiewinst van de A520 moet daarom komen van handelingen die niet veel energie kosten, zoals het prefetchen van data en de branchpredictionunit. Verbeteringen daarin, en in bijvoorbeeld de issue-engine van de executioncore, moeten andere energiebesparende maatregelen compenseren. Zo verwijderde Arm een van de drie alu-pipelines van de A510, zodat de A520 er nog twee heeft. Toch presteert de A520 nog altijd 8 procent beter dan de A510, terwijl het complex toch zo'n 3 procent zuiniger is. Dat levert bij gelijke prestaties een vermogenswinst van 22 procent op.
De DSU-120
We schreven aan het begin al dat Arm een Total Compute Solution biedt. Een integraal onderdeel daarvan is de DynamIQ Shared Unit, ofwel de DSU. Die doet dienst om de verschillende cpu-cores aan elkaar te knopen door een dubbele (bidirectionele) ringbus, maar bevat daarnaast ook een interface naar de CoreLink-interconnect, diverse poorten voor onder meer accelerators en last but not least: de L3-cache.
Cache neemt altijd flink veel oppervlakte van een chip in beslag en met 24 of zelfs 32MB L3-cache is de DSU-120 behoorlijk groot. Dat brengt echter ook het nodige energiegebruik met zich mee, en dat probeert Arm juist zoveel mogelijk te beperken, zo ook bij de DSU. Ten eerste wordt het actieve stroomverbruik gereduceerd dankzij verbeteringen in de cachestructuur en de logica erachter. Zo is het actieve verbruik, of de dynamicpower, 7 procent lager dan in voorgaande generaties en kosten cache misses 18 procent minder energie.
Een grote winst zit in het powermanagement van de cache; hij is namelijk gedeeld tussen alle Cortex-cores, maar hij is niet monolitisch opgebouwd. In plaats daarvan is hij in maximaal 8 slices, een soort compartimenten, georganiseerd, die ieder afzonderlijk een snoop filter, die helpt bij de cache misses, en energiebeheer hebben. Zo kunnen cacheslices geheel of gedeeltelijk in slaapstand gezet worden, waarbij hun inhoud bewaard blijft. Ze kunnen ook geheel uitgeschakeld worden, waardoor ze nog minder stroom verbruiken. Dat levert een heel fijnmazige regulering van het verbruik van de cache op, waarmee zo'n 18 procent energie bespaard wordt.
Als die L3-cache zo groot is en energie kost, waarom maakt Arm hem dan zo groot, vraag je je wellicht af. Dat is omdat cache nog altijd veel zuiniger is dan helemaal naar het systeemgeheugen uitwijken om data op te halen of weg te schrijven. Door dat zoveel mogelijk te voorkomen, kan het TCS23-platform veel meer energie besparen dan het aan caches besteedt. En door de caches selectief uit te schakelen, kunnen de kleinste cores nog steeds over wat L3-cache en bijbehorende data beschikken, zonder dat het dram wakker gemaakt hoeft te worden.
Socs bouwen
Met de vernieuwde, verbeterde bouwstenen in de vorm van de Armv9.2-cores, de vijfde generatie gpu's en de verbeterde DSU-120, kun je bijna een soc bouwen. Waar de DSU-120 de verschillende cores met elkaar verbindt, doet de CoreLink CI-700, of de andere variant interconnect, dat voor de rest van de soc. Dat betekent dat een soc, voor zover die enkel met Arm-IP wordt gebouwd, uit een corecomplex van DSU-120 met een mix van X4-, A720- en A520-cores bestaat. Een 5th Gen-gpu wordt via de CI-700 met het complex verbonden, en met andere randapparatuur als een geheugencontroller.
/i/2005794184.png?f=imagenormal)
Het computecluster met DSU-120 en de Arm-cores beschikt niet alleen over meer gedeelde L3-cache, maar kan ook meer cores bevatten. Waar de DSU-110 van de vorige TCS22-generatie met maximaal 12 cores overweg kon, is dat voor deze generatie 14 cores. Arm laat klanten uiteraard vrij in hun configuratie, maar raadt een aantal configuraties aan. Zo zou een cluster van 1 X4-core, 3 A720-cores en 4 A520-cores een combinatie zijn die tot 33 procent betere prestaties leidt dan de TCS22-1+3+4-configuratie. Omdat de midcores krachtiger én zuiniger gemaakt zijn, zou een TCS23-1+5+2-cluster net zo zuinig zijn als een TCS22-cluster met 1+3+4-configuratie, maar wel 27 procent beter presteren.
Desgewenst zouden klanten er echter ook voor kunnen kiezen 14 X4-cores bij elkaar te prakken, al zou dat niet de meest logische configuratie zijn, ook niet voor laptops. Overigens kunnen ook meerdere clusters gecombineerd worden, zodat nog grotere socs met nog meer cores gemaakt kunnen worden. Ook dat is grotendeels theoretisch, want van de huidige generatie worden veelal combinaties van een of twee X-cores gebruikt, aangevuld met enkele midcores en twee tot vier kleine cores.
De gpu: de vijfde generatie
De vierde generatie Arm-gpu's luisterde nog naar de codenaam Valhall, maar voor de vijfde generatie is de Noorse mythologie achterwege gelaten: de vijfde generatie is simpelweg de 5th Gen GPU Architecture. Die vijfde generatie moet de rekenkracht leveren voor games die steeds complexer worden wat geometrie, textures en belichting betreft. De G720 Immortalis-gpu moet dan ook, vergeleken met de G715, 15 procent beter presteren, twee keer de hdr-renderkracht krijgen en 15 procent meer performance per watt leveren.
Arm sprak eigenlijk alleen over het topmodel, de Immortalis-G720. Dezelfde vijfdegeneratiearchitectuur wordt ook in de kleinere gpu's, de Mali-G720 en de Mali-G620, gebruikt, maar dan met minder cores. De Immortalis-G720 moet ten minste 10 cores hebben én de raytracingcores ingeschakeld hebben. De Mali-G720 heeft die laatste eis niet, maar moet wel 6 tot 9 cores bevatten. De kleinere Mali-G620 mag het met 5 of minder cores doen.
Waar de cpu-cores al extra cache kregen om het energiehongerige pad naar het systeemgeheugen zo veel mogelijk te beperken, is dat bij de gpu nog belangrijker. Al die complexe textures vergen natuurlijk flink wat ruimte en een aanzienlijk deel van het powerbudget van de Arm-gpu's gaat dan ook op aan geheugentoegang. Bij de G715 was ongeveer een derde van het powerbudget voor geheugentoegang, terwijl dat bij de G720 nog maar een kwart is. Samen met de andere optimalisaties moet dat voor grote energiebesparingen zorgen, maar betere graphics opleveren.
Een van de belangrijkste vernieuwingen in de vijfde generatie gpu's is deferred vertex shading, of dvs. Dat is grotendeels verantwoordelijk voor de reductie in geheugentoegang. Voorheen werden vertices en fragments met forward vertex shading na elkaar van kleur en helderheid voorzien, waarbij er relatief veel tijd zit tussen beide. Daarom moet relatief veel data gebufferd worden in het geheugen. Met deferred shading worden die berekeningen tegelijk uitgevoerd, zodat data in lokale buffers en niet in het dram opgeslagen kan worden.
Een andere vernieuwing is een efficiencyverbetering bij het genereren van polygonenlijsten door de tiler. Die kan slimmer selecteren welke triangles wel en niet berekend moeten worden en overbodige triangles weggooien. Ook het versturen van die informatie naar de shaders verloopt efficiënter en de tiler heeft grotere tiles, zodat de data minder versnipperd is. Verder zijn er nog tal van kleinere verbeteringen, onder meer in de snelheid waarmee variable rate shading verloopt en nieuwe shaderinstructies die offloads naar het geheugen moeten voorkomen.
De ray tracing units hebben in Gen 5 een eigen powerisland gekregen, zodat ze volledig uitgeschakeld kunnen blijven wanneer ze niet gebruikt worden. Dat levert weer een stroombesparing op. Ook heeft de nieuwe generatie gpu's eigen, dedicated hardware om antialiasing voor rekening te nemen.
Alle verbeteringen en wijzigingen samen moeten voor een gpu zorgen die, uiteraard met alle variabelen verder hetzelfde, 15 procent hogere piekperformance en 15 procent hogere continue prestaties biedt. Daarbij zou de geheugentoegang tot 40 procent gereduceerd kunnen worden, afhankelijk van de workload.
Tot slot
We hebben het voornamelijk over de hardware van het nieuwe TCS23-platform gehad. De nieuwe cores zijn echter gebouwd op de vernieuwde v9-architectuur, Armv9.2. Die architectuur heeft aanpassingen om de prestaties, vooral op het vlak van machinelearning, te verbeteren, moet vooral voor bufferoverflowkwetsbaarheiden veiliger zijn en niet onbelangrijk: developers worden nog meer geholpen met softwaretools.
Software
Om met dat laatste te beginnen: Arm maakt het dankzij extensies in Armv9.2 makkelijker om software te optimaliseren voor de hardware, om zo extra prestaties eruit te persen. Daartoe zijn trace buffer extensions en embedded trace extensions sinds Armv9 ingebouwd, zodat traces zonder softwareoverhead gemaakt kunnen worden. Die traces worden dan met profile guided optimization gebruikt om de code te optimaliseren. Een ander voorbeeld betreft de SVE2-engine, die vooral voor beeldverwerking gebruikt wordt. SVE2 is aanzienlijk sneller dan voorganger Neon.
Arm werkt ook samen met onder meer Google, dat het Android Dynamic Performance Framework ontwikkelde. Dat is sinds Android 12 beschikbaar en is vanaf Android 14 verplicht om te gebruiken. Dat framework wordt onder andere gebruikt om workloads te voorspellen en cores op tijd wakker te maken of juist sneller te laten slapen, zodat clockcycles niet verspild worden. Ook bevat het een 'thermal api' die voorkomt dat de soc en het apparaat te warm worden en de gamemode van ADPF zorgt voor vloeiend draaiende games waarvan de framerate niet na korte tijd instort als de soc te warm wordt. Dat levert én betere prestaties én een lager verbruik op.
Armv9.2 en veiligheid
Tot slot nog een belangrijk punt: beveiliging. Arm v9.2 is een volledige 64bit-architectuur en Arm is al zo'n tien jaar bezig om de migratie van 32bit naar 64bit te bewerkstelligen. Inmiddels is het overgrote deel van apps in alle appstores 64bit, en het volgende target is de migratie naar 64bit van apparaten als tv's en settopboxen.
Armv9.x maakt gebruik van memory tagging om adressen in die 64bit-adresruimte te markeren. Een op die manier getagd adres kan niet door een ander proces gebruikt worden. Samen met twee andere technieken, pointer authentication, of pac, en branch target identification, of bti, moeten de meeste kwetsbaarheden het hoofd geboden kunnen worden. Dat zijn namelijk veelal bufferoverflows, die met pac en bti niet mogelijk zouden zijn. Beide technieken zitten inmiddels in Chromium, de basis voor de meeste webbrowsers, ingebakken, net als in de veelgebruikte Unity Game Engine. Mte wordt nog niet veel gebruikt, al heeft fabrikant Honor het wel in gebruik, net als Unity.
Armv9.2 in het wild
Wanneer er precies apparaten met de nieuwe X4-cores, of met de andere cpu-cores en de Immortalis-gpu op de markt verschijnen, is nog niet bekend. Arm geeft geen details over de toekomstplannen van zijn klanten. Na de introductie van de vorige generatie TCS22 duurde het tot eind van het jaar voor de eerste producten daarmee verschenen. Zo kwam Vivo in november 2022 met de Vivo X90 in China, maar moest de rest van de wereld daar tot februari op wachten. Oppo bracht de Find X6 in maart in China uit, maar de rest van de wereld moet nog wachten. Beide modellen zijn met een Dimensity 9200-soc uitgerust, met aan boord 1x Cortex-X3, 3x Cortex-A715 en 4x Cortex-A510. Het lijkt op basis daarvan aannemelijk dat smartphones en andere producten met TCS23-hardware pas eind dit jaar of in de eerste helft van volgend jaar verschijnen.
/i/2005794122.png?f=imagenormal)
Overigens staat de volgende generatie uiteraard al in de steigers. TCS24 moet worden opgebouwd uit de DSU-120, maar dan met Blackhawk als krachtigste core, Chaberton als opvolger van de A720-midcores en Hayes als kleinste core. De gpu heeft vooralsnog codenaam Krake gekregen en de CI-700 en NI-700 interconnects worden opgevolgd door een interconnect met codenaam Tower. Over TCS24 horen we ongetwijfeld volgend jaar meer.


























:strip_icc():strip_exif()/i/2006728156.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005190534.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004919500.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004698468.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004374656.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004086480.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2003679094.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/u/231397/crop5daf616bcc2f3_cropped.jpeg?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_icc():strip_exif()/u/1344096/crop5e51bd482905f_cropped.jpeg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
/u/1741088/crop636b6e3488036_cropped.png?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/36083/crop5dca9e34ce091_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/219059/crop5efafd1bd64af_cropped.jpeg?f=community)
/u/1957000/crop696cfa35c73d9_cropped.png?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
/u/244207/crop5c38ae2351fe1.png?f=community)
:strip_icc():strip_exif()/u/63387/crop619c2ec45e26f_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/279088/crop609fca601663b.jpg?f=community)
:strip_icc():strip_exif()/u/141198/crop6164051fbcf31.jpg?f=community)
:strip_exif()/u/115520/crop5def67c595741_cropped.gif?f=community)
:strip_icc():strip_exif()/u/335350/crop61a63ee1f224f.jpg?f=community)