Introductie
Tweakers met een een eigen blog of website kunnen het interessant vinden te weten wie hun bezoekers nu eigenlijk zijn of welke pagina's het meest aanslaan. Daarvoor zijn meer dan genoeg tooltjes beschikbaar. Een paar jaar geleden was het een no-brainer; je installeerde Google Analytics en vervolgens verzamelde je bakken met data. Inmiddels is Google Analytics software non grata. De tool is door meerdere Europese toezichthouders verboden. Gelukkig zijn er meer dan genoeg alternatieven als je een beetje websitebezoek wilt meten. We nemen er in dit artikel een aantal onder de loep.
We testten voor dit artikel vier verschillende alternatieven voor Analytics. De selectie is redelijk arbitrair; er zijn namelijk zoveel alternatieven dat ik die nooit allemaal kan behandelen. Dit artikel is daarom ook geen klassieke review, maar meer een overzicht van hoe de verschillende tools eruitzien en wat je ermee kunt. De tools in dit overzicht zijn gratis of in ieder geval als freemiummodel te gebruiken. Ik heb geprobeerd tools te zoeken die van elkaar verschillen. De ene is erg uitgebreid; de andere juist erg simplistisch. De ene komt uit Europa, terwijl de andere uit Amerika komt. Goed om te benadrukken: dit is een redactioneel artikel. Wat we hier testen, heeft niets te maken met de analytics tools die Tweakers op zijn website gebruikt. De tools die we hier tonen en de beschrijving ervan zijn mogelijk interessant voor lezers met een eigen website, maar staan dus compleet los van de website Tweakers.net.
Testsite
Jullie klikten massaal op onze testwebsite.
Een vergelijking moet je natuurlijk zo objectief mogelijk doen, dus heb ik een praktijktest gedaan. Begin deze week riep ik jullie op om een website te bezoeken waar de tools op draaien die ik heb bekeken. Die website kun je nog steeds online vinden via www.tweakersanalyticstestsite.nl. De tools die daarop draaien zijn Matomo, Plausible, Umami en Clicky. Die hebben allemaal hun voor- en nadelen, maar vormen samen een redelijk brede selectie van wat er aan analytische tools beschikbaar is.
Alle tools die ik in dit artikel test, zijn als cloudversie te gebruiken. Dat betekent dat je het ook kunt beheren zonder dat je er specifieke serverruimte voor nodig hebt. Sommige tools, zoals Plausible, kun je ook lokaal hosten als je wilt. In dat geval ben je volledig verantwoordelijk voor de data die je verzamelt en hoe je je bezoekers daarover inlicht. Voor dit artikel heb ik alleen de cloudversies bekeken.
Kijk je naar wat de tools in de praktijk kunnen, dan kun je zelfs na het testen van vier van de honderden beschikbare analyticstools al voorzichtige conclusies trekken. Een ervan is dat Google Analytics bij uitstek een van de uitgebreidste is. Plausible, Umami en Clicky vallen totaal in het niet bij de bergen data die Google Analytics binnen kan halen. Als je op zoek bent naar zo'n alternatief, dan kom je met Matomo het meest in de buurt, maar drie van de vier tools die ik voor dit stuk bekeek, kunnen hooguit wat simpele stats binnenhalen, zoals browsergebruik, maar om die in de uitgebreide rapportages te bestuderen zoals je dat met Google kunt, zit je bij de meeste van deze tools niet goed.
/i/2006013570.png?f=imagenormal)
Toch nog Google?
Er is iets voor te zeggen om toch Google Analytics te blijven gebruiken: onlangs werd een van de grootste obstakels van die tool weggehaald. De Europese Commissie stemde in juli in met het Data Privacy Framework. Dat is een datadoorgifteverdrag waarmee gebruikersgegevens van Europeanen 'met een passend niveau van bescherming' naar de VS kunnen worden gestuurd. Dat was een van de belangrijkste redenen waarom toezichthouders waarschuwen voor Google Analytics. Het Nederlandse onderzoek van de Autoriteit Persoonsgegevens naar Google Analytics 'loopt nog', zegt een woordvoerder.
Resultaten van dat onderzoek laten dan ook op zich wachten, maar mogelijk wordt dat overbodig. "De doorgifte van persoonsgegevens naar de VS via Google Analytics zou mogelijk zijn zonder extra maatregelen te nemen, als Google gecertificeerd is onder het Data Privacy Framework en Google Analytics in die certificering is inbegrepen", zegt een woordvoerder van de AP. "De Europese Commissie heeft namelijk besloten dat het Data Privacy Framework een ‘passend niveau van bescherming’ biedt voor persoonsgegevens van Europeanen. Het is aan organisaties zelf om bij Google na te gaan of het product Google Analytics gecertificeerd is onder het Data Privacy Framework." Bovendien komt Google Analytics 4 eraan. Daarin worden helemaal geen IP-adressen meer verzameld.
Software om bezoekers te tracken is er genoeg; je hoeft om keus niet verlegen te zitten. Zie dit artikel niet als een ultieme eindvergelijking, maar als een eerste inzicht in wat verschillende tools kunnen. In ieder geval bedankt als je mee hebt geholpen met het testen. We hebben onze accounts inmiddels verwijderd en de data van de trackingtools laten verwijderen.
Matomo
Wat is het?
Jarenlang was Piwik een van de belangrijkste tegenhangers van Google Analytics. Dat was een opensourceproject dat in 2007 opkwam, maar inmiddels is Piwik opgesplitst in twee varianten. Het is een ietwat ingewikkelde constructie die de makers hier proberen te duiden, maar die er in het kort op neerkomt dat er Matomo is voor wat kleinere websites en Piwik PRO voor serieuze zakelijke gebruikers. In dit artikel kijken we naar die eerste. Matomo is namelijk niet gratis, maar wel open source beschikbaar en je kunt het on-premises downloaden en dat maakt de tool net iets privacyvriendelijker.
Matomo is op twee manieren te gebruiken. De eerste is als webdienst. Die werkt simpel door een stukje JavaScript in de header van je website te plakken en naar [websitenaam].matomo.cloud te gaan, vergelijkbaar met hoe je Google Analytics gebruikt. Daarin staat een dashboard met wat lijkt op honderden verschillende metrics die je ook nog eens kunt customizen. Matomo is daarnaast uniek omdat het ook lokaal te gebruiken is.
/i/2006013528.png?f=imagenormal)
Daarnaast heeft Matomo een eigen on-premises installatiemogelijkheid. Het bedrijf waarschuwt dat daar 'technische kennis' voor vereist is, maar in de praktijk kan de tool met een simpele wget worden geïnstalleerd en het enige dat je er verder voor hoeft te doen, is een koppeling met je database leggen. Matomo heeft tot slot een WordPress-plug-in waarmee de tool direct in het cms kan worden geplaatst.
Wat kost het?
De twee soorten Matomo-tools, de cloudversie en de on-premises versie, hebben een heel verschillende prijsstructuur. Opvallend is dat de betaalde versie meer beperkingen kent. Je betaalt minimaal 19 euro per maand voor de tool, wat flink aan de prijs is. Je kunt daarvoor 50.000 hits per maand ontvangen, met 1,90 euro per 5000 extra maandelijkse hits. Matomo heeft verder prijzen die oplopen tot 13.900 euro voor 100 miljoen hits, maar voor dat bedrag kun je net zo goed iemand fulltime in dienst nemen om een on-premises installatie te beheren.
Bij de betaalde variant ben je beperkt in het aantal websites, teamleden, doelen en segmenten dat je kunt installeren. Ook wordt ruwe data na twee jaar weer verwijderd, al blijven rapportages onbeperkt houdbaar. Dat lijken flinke limieten, maar professionele gebruikers krijgen voor die 19 euro per maand wel allerlei extra tools, zoals integratie met WooCommerce, heatmaps, A/B-testing en advertentieconversie. Dat zijn bij de on-premises hosting allemaal betaalde add-ons.
De on-premises variant is verder wel volledig gratis te gebruiken en volgens de makers blijft dat ook zo. Dat komt voort uit de filosofie van het bedrijf, dat de software graag open source aanbiedt. In de GitHub-repo is de broncode te vinden van praktisch iedere tool die Matomo maakt, van de trackingtool tot de WordPress-plug-in en tooltjes als een devicedetector. De software is beschikbaar onder een GNU General Public License v3 waarmee andere gebruikers die uitgebreid kunnen delen.
Hoe installeer je het?
Je kunt de tool op twee manieren installeren. Voor deze test heb ik alleen de cloudversie van Matomo geprobeerd, maar wie door de tutorial scrolt, ziet dat een lokale installatie niet ingewikkeld is. Met SSH-toegang kan dat met één commando worden gerepareerd, anders is het nodig een paar bestandjes te downloaden en via FTP te uploaden. Daarna volgt een handleiding waarin de systeemeisen worden gecontroleerd en een nieuwe databasetable wordt aangemaakt. Een kind kan de was doen.
/i/2006013534.png?f=imagenormal)
Het instellen van de cloudversie werkt zoals alle andere tools door een stukje JavaScript-code in de head van een website te zetten. Matomo is echter een opvallend uitgebreide tool voor personen die graag volledig de controle nemen. In het dashboard kun je bijvoorbeeld instellen dat je alle bezoekers in een keer op alle subdomeinen trackt of juist niet, je kunt outlinks wel of niet meenemen of customparameters voor specifieke campagnes meten. Die worden dan direct in de code voor de header verwerkt.
Hoe werkt het praktisch?
Matomo toont een gigantisch dashboard met bakken aan informatie, opvallend veel meer dan de andere tools die we hebben getest. Dat dashboard is bovendien te personaliseren door veelgebruikte functies er via kaarten in te plaatsen. Wie niets verandert aan de tool, ziet vooral de realtimebezoeken en daaronder een uitgebreide lijst met recente individuele bezoeken. Daarin staat direct waar de gebruiker vandaan komt, welke browsertaal er is ingesteld en welke browser, welk besturingssysteem en welk apparaat die gebruikt. Bij het doorklikken verschijnt een pop-up met veel informatie over de individuele bezoeker, met ook bijvoorbeeld de schermgrootte, waar die vandaan komt, welke subdomeinen en pagina's er zijn bezocht en zelfs welke outboundlinks de bezoeker heeft aangeklikt.
/i/2006013536.png?f=imagenormal)
De informatie die je via het Bezoekers-tabblad kunt vinden over een lezer, is bij Matomo veel uitgebreider dan bij de andere tools, misschien wel iets té uitgebreid. Bij Matomo is het erg makkelijk om een fingerprint op te stellen van je bezoekers, zelfs als je alle privacyinstellingen maximaal instelt.
Matomo biedt verder een uitgebreid overzicht van alles wat je van je bezoekers wilt weten. Dat gaat diep: de standaardweergave toont bijvoorbeeld direct aan welke versies van besturingssystemen gebruikers hebben of welke browserversie ze gebruiken en zelfs welk specifiek toestel. Je kunt bovendien op al die zaken filteren, zodat je alleen alle Apple- of alle Xiaomi-bezoekers te zien krijgt. Verder zijn cijfers op te delen in momenten van de dag, per locatie en praktische zaken als bouncerates. Daarmee is Matomo minstens zo uitgebreid als Google Analytics.
De tool maakt het tot slot mogelijk om je bezoek te optimaliseren, bijvoorbeeld door doelen toe te voegen op basis van conversie of andere metrics die je kunt vaststellen, zoals het aantal bezoekers op een bepaalde URL of die op een bepaalde manier binnenkomen. Je kunt je bezoek ook optimaliseren via A/B-tests en heatmaps.
/i/2006013538.png?f=imagenormal)
Privacy
Het interessante aan Matomo is dat je dat als beheerder net zo privacyvriendelijk kunt instellen als je zelf wilt. Dat begint natuurlijk al bij het bepalen of je een selfhosted versie wil: in dat geval ben je als eindgebruiker zelf verantwoordelijk voor de gegevens die je verzamelt en wanneer je die verwijdert. Maar Matomo geeft je ook in de cloudversie een hele rits aan opties om de privacy van gebruikers te beschermen. Dat begint bij het verzamelen van IP-adressen, iets waar uitgerekend Google Analytics vorig jaar hard op werd afgerekend door toezichthouders. Matomo pseudonimiseert IP-adressen standaard. Dat kan op meerdere manieren, bijvoorbeeld volledig, zodat bezoekers allemaal een uniek ID krijgen, of met een, twee of drie bytes waarmee alleen een deel van het IP-adres wordt afgeschermd, zodat je alleen 192.168.xxx.xxx ziet.
 Verder is het mogelijk gebruikers-ID's als pseudoniem op te slaan of om bepaalde ID's te anonimiseren als die bijvoorbeeld gekoppeld zijn aan een webshopplug-in. Het 'probleem' van Matomo is dat het volledig aan de beheerder is om die instellingen aan of uit te zetten voor andere gebruikers. De superuser kan ook met terugwerkende kracht de IP-anonimisering uitschakelen. In dat geval kun je het IP-adres van alle eerdere bezoekers alsnog terugzoeken. Het is dan wel mogelijk oude ruwe data na een bepaalde periode geautomatiseerd te anonimiseren. Dat kan met IP-adressen, maar ook specifiek met locatiegegevens over user-ID's. Maar ook dat ligt volledig bij de beheerder. Matomo kan daarmee anoniem worden ingezet, maar je bent als bezoeker wel afhankelijk van hoe de tool is ingeregeld door de beheerder.
Verder is het mogelijk gebruikers-ID's als pseudoniem op te slaan of om bepaalde ID's te anonimiseren als die bijvoorbeeld gekoppeld zijn aan een webshopplug-in. Het 'probleem' van Matomo is dat het volledig aan de beheerder is om die instellingen aan of uit te zetten voor andere gebruikers. De superuser kan ook met terugwerkende kracht de IP-anonimisering uitschakelen. In dat geval kun je het IP-adres van alle eerdere bezoekers alsnog terugzoeken. Het is dan wel mogelijk oude ruwe data na een bepaalde periode geautomatiseerd te anonimiseren. Dat kan met IP-adressen, maar ook specifiek met locatiegegevens over user-ID's. Maar ook dat ligt volledig bij de beheerder. Matomo kan daarmee anoniem worden ingezet, maar je bent als bezoeker wel afhankelijk van hoe de tool is ingeregeld door de beheerder.
Matomo staat standaard ingesteld om do-not-trackverzoeken te negeren. Je kunt dat wel switchen, maar het was sterker geweest als dit een opt-infunctie was geweest in plaats van een opt-out.
Matomo heeft een uitgebreide gids waarin staat hoe gebruikers aan de AVG moeten voldoen en hoe ze hun cookiemelding moeten weergeven. De tool biedt ook een makkelijke manier om een cookiewaarschuwing weer te geven waarmee gebruikers meteen een opt-out kunnen doen voor het verzamelen van data. Die kun je simpel met een div in de websiteheader zetten. Een mooie bijkomstigheid is dat je die waarschuwing makkelijk kunt personaliseren met je eigen tekst en stijl, in plaats van een kant-en-klare banner te implementeren.
Plausible
Plausible is een vaak genoemde analyticstool die zichzelf ook in de markt zet als privacyvriendelijk. Daar heeft het goede redenen voor: Plausible is open source, gebruikt geen cookies om gebruikers te volgen en alle gegevens worden in Europa opgeslagen. Daarnaast, zeggen de makers, is de tool makkelijker in gebruik en lichter dan Google Analytics. Dat klinkt alsof de tool ook relatief weinig opties heeft. Plausible belooft dat simpeler te maken, maar lukt dat ook?
Wat is het?
Plausible is een Europees bedrijf met een hoofdkwartier in Estland. De publieke bèta van de tool kwam in januari 2019 uit, kort daarna begon het bedrijf met betaalde abonnementen en sinds 2021 is het bedrijf ook financieel stabiel. Plausible onderscheidt zich voornamelijk op twee manieren van Google Analytics: het is simpeler en het is openbaar. De broncode van de tool is op GitHub te vinden. Het bedrijf is er trots op Europees te zijn en financieel alleen van abonnementen afhankelijk te zijn. Misschien is het daarom dat het bedrijf de lokale hosting een beetje verstopt op de website. Je kunt Plausible lokaal hosten, met een paar beperkingen, en dat kost niets. Voor dit artikel hebben we alleen naar de cloudversie gekeken en niet naar de lokale hosting. De software is beschikbaar onder een GNU Affero General Public License v3.0. Die staat veel verspreiding toe.
/i/2006013542.png?f=imagenormal)
Wat kost het?
Plausibles cloudversie begint bij negen euro per maand. Daarvoor kun je maximaal 10.000 pageviews analyseren, verdeeld over vijftig websites. Een jaarabonnement kost negentig euro. Er zijn nog meer tiers, oplopend van 100.000 pageviews voor 19 euro per maand tot 10 miljoen pageviews per maand voor 169 euro per maand. De prijs is het enige dat per tier verandert. Bij ieder pakket kun je vijftig websites koppelen, krijg je e-mailrapportages en worden datasets voor altijd bewaard. Je kunt ook aan ieder pakket een ongelimiteerd aantal gebruikers koppelen. Handig om te weten: voor de gratis trial heb je geen creditcard nodig.
De lokale hosting is gratis te gebruiken. De beperking zit dan vooral in de releases; de lokale versie is een longtermsupportrelease die twee keer per jaar wordt voorzien van nieuwe features. Ook biedt Plausible geen klantenserviceondersteuning voor lokale installaties. Wel is er ondersteuning op GitHub voor wie tegen problemen aanloopt.
/i/2006013544.png?f=imagenormal)
Hoe installeer je het?
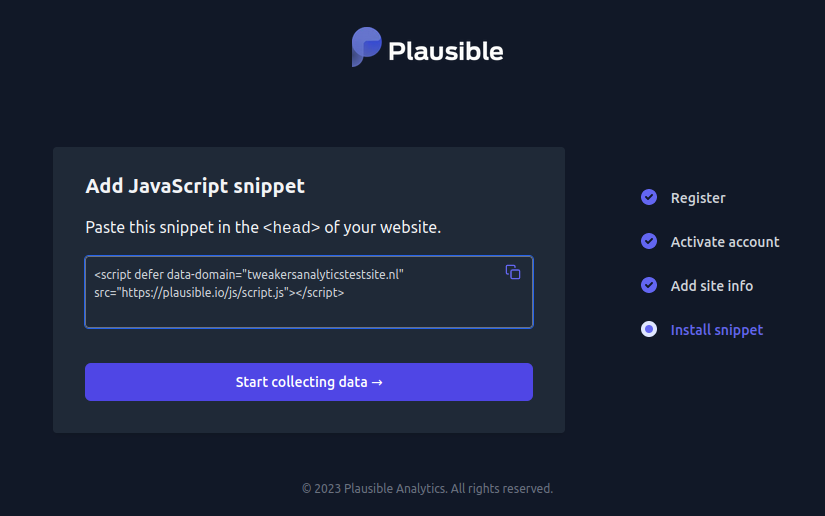
De cloudversie van Plausible is, net als de andere tools, simpel te installeren met een enkele regel JavaScript in de header van een website. Dat script wordt standaard opgehaald van de website van Plausible. De makers hebben daarnaast instructies online gezet voor hoe je Plausible via een proxy inlaadt om adblockers te vermijden.
/i/2006013546.png?f=imagenormal) Je kunt de tool ook lokaal hosten. De code staat op GitHub, maar de installatiedocumentatie is beduidend minder simpel dan bij Matomo. Je moet een database in Docker aanmaken, wat niet voor iedere gebruiker even soepel zal gaan. Plausible heeft wel een gratis WordPress-plug-in beschikbaar.
Je kunt de tool ook lokaal hosten. De code staat op GitHub, maar de installatiedocumentatie is beduidend minder simpel dan bij Matomo. Je moet een database in Docker aanmaken, wat niet voor iedere gebruiker even soepel zal gaan. Plausible heeft wel een gratis WordPress-plug-in beschikbaar.
Hoe werkt het praktisch?
Plausible ziet er op het eerste gezicht simplistisch uit, precies zoals het bedrijf het belooft. Je kunt doorklikken in de tool om alsnog meer informatie te zien, maar wie de krachtige opties en rapportages zoekt die Google Analytics biedt, komt van een koude kermis thuis. Het homepagedashboard, dat niet aan te passen is, geeft basale informatie als het aantal bezoekers in de afgelopen maand, het gemiddelde aantal views per bezoek en een bouncerate, met aparte cards met informatie over de locatie van bezoekers, het apparaat of besturingssysteem dat ze gebruiken en uit welke bronnen ze afkomstig zijn. Je moet lang doorklikken om meer informatie te zien; bij Instagram krijg je dan bijvoorbeeld te zien of een link uit een story of een post komt en als je op Devices op Firefox klikt, krijg je meer details te zien over de browserversie die gebruikers inzetten.
 Daar blijven de metrics wel bij. Plausible geeft je net genoeg informatie om wat basale inzichten te krijgen in je bezoek, maar je moet hier niet zoveel van verwachten. Ook is de gui er niet op ingesteld om makkelijk individuele pagina's te volgen. De tracking voor die pagina's is er, maar je moet lang doorklikken voor je er bent. Dat is niet logisch en kan frustrerend zijn als dit een belangrijk meetpunt voor je is.
Daar blijven de metrics wel bij. Plausible geeft je net genoeg informatie om wat basale inzichten te krijgen in je bezoek, maar je moet hier niet zoveel van verwachten. Ook is de gui er niet op ingesteld om makkelijk individuele pagina's te volgen. De tracking voor die pagina's is er, maar je moet lang doorklikken voor je er bent. Dat is niet logisch en kan frustrerend zijn als dit een belangrijk meetpunt voor je is.
Maar wat Plausible vooral nekt, is dat je geen individuele gebruikers kunt 'volgen', zoals dat bij Matomo wel kan. Je kunt dus niet zien welke stappen een individuele bezoeker zet, hoe die binnenkomt en wat zijn profiel is. Dat is voor eindgebruikers een goede zaak; het is juist ook een duidelijke belofte die Plausible doet, bijvoorbeeld in zijn privacybeleid. Dat beleid heeft echter een keerzijde en daar moet je je bewust van zijn. Als je je bezoekers uitgebreid wilt tracken, zit je met Plausible niet zo goed. Vooral bezoeken zijn lastig te meten, omdat meerdere bezoeken van dezelfde bezoeker als één bezoek worden gemeten.
Als je met Plausible een 'goal' aanmaakt, is dat lastiger dan zou moeten. Dat kan niet vanuit Plausibles gui. Wil je weten wanneer een x-aantal gebruikers op een bepaalde pagina komen, dan moet je eerst een custom-css-snippet maken en op die pagina zetten. Vervolgens moet je de trackingcode aanpassen om die css-snippet te volgen. Als je meerdere doelen instelt, wordt de trackingcode vanzelf erg groot en zwaar, terwijl dat juist is waar Plausible zich zo mee onderscheidt.
Privacy
Plausible mag dan wel de minst uitgebreide analyticstool zijn, daar staat een sterk privacybeleid tegenover. Plausible trackt bezoekers niet over verschillende apparaten, maar alleen op dat moment. Dat betekent dat de dienst ook geen cookies plaatst. Een bijkomend voordeel: je hebt geen cookiewall nodig. Plausible verzamelt naast de bezochte URL en de referer ook nog de browser en browserversie, het besturingssysteem, apparaattype en een locatie tot op stadsniveau. Die worden vervolgens niet gekoppeld aan gebruikersprofielen.
/i/2006013550.png?f=imagenormal)
Plausible haalt wel het IP-adres van bezoekers op, die samen met de useragent worden voorzien van een dagelijks roterende salt en vervolgens worden gehasht. Daardoor ontstaat een unieke identifier, maar die wordt na 24 uur weer verwijderd. Daar heb je als beheerder overigens niets aan, want je kunt die identifier niet gebruiken om individuele gebruikers te volgen. Plausible geeft ook toe dat dat strenge privacybeleid betekent dat het moeilijk is om bijvoorbeeld nieuwe versus oude bezoekers te vergelijken met elkaar.
De gegevens die wel worden verzameld, zoals de gehashte identifiers, worden in Europa bewaard. Dat gebeurt op servers van het Duitse Hetzner. Daardoor vindt er geen dataoverdracht plaats naar andere landen, zoals de Verenigde Staten.
Umami
Wat is het?
Umami is een simplistische analyticstool waar je niet zoveel mee kunt als zware alternatieven als Google Analytics, maar die twee belangrijke voordelen heeft. Ten eerste is het mogelijk de tool zelf te hosten. Sterker nog, de makers willen vooral dat je dat doet: de clouddienst lijkt vooral optioneel. Het tweede grote voordeel is dat Umami gratis is, althans, voor kleine websites met maximaal 10.000 'events' per maand en met wat beperkingen.
Umami is een wat mysterieus bedrijf. In tegenstelling tot Plausible is Umami kortaf over zijn ontstaan en heeft het een juridisch en onleesbaar privacybeleid. Daarin staat, ietwat verstopt, dat Umami een Amerikaans bedrijf is waarvan gebruikersdata ook wordt opgeslagen in dat land. Het bedrijf geeft verder weinig informatie over welke data het van bezoekers verzamelt en hoe het informatie beveiligt. Ook dat lijkt voornamelijk een teken dat het lokaal en in eigen beheer moet worden gebruikt, maar er is ook een cloudversie beschikbaar. Om deze tool te testen, heb ik vooral naar de cloudversie gekeken, maar ik heb de lokale versie wel kort uitgeprobeerd om te zien of daar verschillen in zitten. Die zijn er weinig te vinden, althans niet in de gui.
/i/2006013552.png?f=imagenormal)
Wat kost het?
De downloadbare variant is gratis. De code ervan staat op GitHub onder een MIT License. De clouddienst kost wel geld als je een professionele website hebt, maar er is ook een Hobby-tier, die niets kost. Die tier kun je gebruiken als je maximaal 10.000 'events' per maand krijgt. Dat definieert Umami als bezoeken naar een website, maar ook events. Dat zijn aparte elementen die je los kunt tracken. Als een bezoeker dus op een knop klikt waaraan ook een eventtag is gekoppeld, dan telt dat mee als een extra event richting je maandelijkse maximum van 10.000. De Hobby-tier heeft ook ondersteuning voor maximaal drie websites en de bewaartermijn voor data is slechts één jaar. Bovendien krijg je met het gratis pakket geen ondersteuning.
Daar staat het Pro-pakket tegenover, dat begint bij negen dollar of zo'n acht euro per maand. Dat geldt voor maximaal 100.000 events per maand, maar vanaf dat aantal loopt de prijs op naar 19 dollar voor 250.000 events tot wel 1699 dollar voor 50 miljoen events. Het Pro-pakket onderscheidt zich verder met een onbeperkt aantal websites en teamleden en het feit dat de betaalde pakketten e-mailondersteuning krijgen.
Hoe installeer je het?
De cloudversie is het simpelst. Die installeer je simpelweg met de JavaScript-trackingcode in de header die een link legt met een website-ID. Dat is echter niet het enige moment dat je de code van je site in moet duiken. Als je een event wilt aanmaken, dan moet je een property aan een element hangen. Umami geeft als voorbeeld als je een buttonelement op je website hebt staan waarvan je het gebruik wilt tracken. In zo'n geval moet je iets als data-umami-event="{event-name}" aan het element toevoegen of een nieuw JavaScript-element maken. Dat is voor veel hobbygebruikers wellicht net een stap te ver.
Umami doet zich graag voor als een perfect product voor lokale hosting, maar de installatie ervan is lastig voor wie dat nog nooit heeft gedaan. Je kunt Umami niet zomaar downloaden en op een server zetten; je moet eerst een build maken via Yarn en daarna een database configureren. Dat is niet makkelijk, zeker niet voor wie een simpel pakketje van Strato neemt, zoals ik voor dit artikel deed.
/i/2006013556.png?f=imagenormal)
Hoe werkt het praktisch?
/i/2006013560.png?f=imagenormal) Umami is de minst uitgebreide Analytics-tool in deze vergelijking. Het hoofddashboard bevat alleen wat basale informatie zoals het aantal bezoekers en bezoeken in een bepaalde periode, naast de bouncerate en de gemiddelde bezoekduur. Dat is te zien in een grafiek met unieke bezoekers versus pageviews, maar meer krijg je er niet te zien. Als je doorklikt naar 'details' word je een klein beetje wijzer, maar niet veel. Je ziet dan pagina's die bezocht zijn, naast referers en daaronder de gebruikte browser, het gebruikte besturingssysteem en het gebruikte apparaat. Vooral uit die laatste categorieën haal je weinig bruikbare informatie. Umami registreert bijvoorbeeld alleen 'Chrome' of enkel 'iOS', maar maakt geen enkel onderscheidt in welke versie dat is. Je kunt die informatie wel samenvoegen, door alle 'Linux-gebruikers op een laptop met Firefox' te bekijken. De UX heeft daarbij de vervelende eigenschap de Y-as van de statistiekentabel altijd aan te passen naar de hoogste eigenschap daarvan, ongeacht of je nu 1000 bezoekers met Chrome hebt of 2 bezoekers met Opera.
Umami is de minst uitgebreide Analytics-tool in deze vergelijking. Het hoofddashboard bevat alleen wat basale informatie zoals het aantal bezoekers en bezoeken in een bepaalde periode, naast de bouncerate en de gemiddelde bezoekduur. Dat is te zien in een grafiek met unieke bezoekers versus pageviews, maar meer krijg je er niet te zien. Als je doorklikt naar 'details' word je een klein beetje wijzer, maar niet veel. Je ziet dan pagina's die bezocht zijn, naast referers en daaronder de gebruikte browser, het gebruikte besturingssysteem en het gebruikte apparaat. Vooral uit die laatste categorieën haal je weinig bruikbare informatie. Umami registreert bijvoorbeeld alleen 'Chrome' of enkel 'iOS', maar maakt geen enkel onderscheidt in welke versie dat is. Je kunt die informatie wel samenvoegen, door alle 'Linux-gebruikers op een laptop met Firefox' te bekijken. De UX heeft daarbij de vervelende eigenschap de Y-as van de statistiekentabel altijd aan te passen naar de hoogste eigenschap daarvan, ongeacht of je nu 1000 bezoekers met Chrome hebt of 2 bezoekers met Opera.
/i/2006013558.png?f=imagenormal)
Je kunt verder, zoals eerder al beschreven, events tracken, zodat je specifieke elementen op je website kunt meten. Ook dat is redelijk basic; je krijgt dezelfde informatie te zien die je ook in het hoofddashboard ziet, maar dan voor specifieke elementen zoals buttons of bepaalde links. Ook uit de rapportages word je weinig wijzer. Die tracken voornamelijk hoe de verkeersstromen veranderen tussen verschillende pagina's, maar meer gedetailleerde informatie haal je er niet uit. Analyses uit de data kun je bij Umami vergeten; als je zulke conclusies wilt trekken of daar in ieder geval ondersteuning bij wilt, ben je met andere tools beter af.
Je kunt Umami configureren met bepaalde features, maar ook daarvoor moet je de code in duiken. Zo kun je code toevoegen om do-not-trackverzoeken automatisch te respecteren of om bepaalde domeinen wel of juist niet te tracken. Verder kun je via de databasetable bepaalde gebruikers uitsluiten, maar ook het IP-adres van bezoekers verzamelen.
Privacy
Het is opvallend lastig om uit te vinden hoe Umami gebruikersgegevens bijhoudt in de cloudversie. In het privacybeleid gaat het alleen over informatie die je als eindgebruiker, dus als beheerder, afgeeft. Het enige dat het bedrijf zegt, is dat het geen cookies aanmaakt van gebruikersbezoeken en dat het de verzamelde data anonimiseert, maar het is niet duidelijk hoe het die anonimisering doet en waar die informatie vervolgens wordt opgeslagen. In ieder geval is het vanuit het dashboard niet mogelijk om individuele gebruikers te volgen; die hebben geen unieke identifier en worden zelfs niet gefingerprint.
/i/2006013554.png?f=imagenormal)
Bij het aanmaken van events is het wel mogelijk de schermgrootte en taal van een gebruiker op te nemen, maar dat is niet genoeg om gebruikers handmatig te fingerprinten. Opvallend is verder dat Umami je de optie geeft om in de database de string disable_telemetry = 1 op te nemen om 'de compleet anonieme telemetrische data die Umami gebruikt om de applicatie te verbeteren' uit te schakelen. Welke data dat is? Dat zegt het bedrijf er niet bij.
Ook is het bedrijf kort over de serverlocaties die het heeft. "Umami Cloud-servers staan in de Europese Unie en voldoen aan de AVG", zegt het bedrijf, zonder daar verder over uit te wijden.
Clicky
Wat is het?
Clicky wordt vaak genoemd als goede analyticstool die ook nog eens erg privacyvriendelijk is. In tegenstelling tot Matomo en Plausible is Clicky geen Europees bedrijf, maar een product van het Amerikaanse Roxr. De tool is al behoorlijk oud; het bedrijf noemt het heel retro 'een Web 2.0-analyticstool' en heeft gebruikscijfers uit 2010 op zijn website staan. Ook de UI en UX lijken nogal oud te zijn, maar dat betekent niet dat je met Clicky niets kunt. De tool wordt al jaren aangehaald als populair alternatief en werkt makkelijk en soepel. Daarmee is het zeker goed om als Google-alternatief te proberen.
Clicky is een cloud-onlytool met een freemiumverdienmodel. Je kunt basisfunctionaliteiten gratis gebruiken, maar moet je portemonnee trekken voor geavanceerde tracking.
/i/2006013562.png?f=imagenormal)
Wat kost het?
Clicky heeft een gratis pakket voor hobbyisten dat iets anders is ingericht dan je gewend bent. Daar zit geen maandelijkse limiet op, maar een dagelijkse limiet van 3000 pageviews. Je kunt de tool daarmee op een website gebruiken. Daarnaast zijn er de betaalde abonnementen Pro, Pro Plus en Pro Platinum, waarbij je maximaal 30.000 of 100.000 dagelijkse pageviews krijgt. In de twee duurste pakketten is het mogelijk heatmaps te maken en de uptime van de site te monitoren. Verder heeft de gratis tier flink veel beperkingen in functionaliteit. De lijst met premiumfeatures is lang: langetermijnmetrics, data-export, segmenten, verschillende rapportages en campagnes zijn niet beschikbaar zonder te betalen. Ook de Spy-modus is dan niet beschikbaar. Dat is een gedetailleerde lijst van bezoekers per IP-adres.
Hoe installeer je het?
Clicky heeft geen zelfhostfunctionaliteit. Je kunt het alleen als clouddienst gebruiken. Aanmelden en installeren is vrij basaal door een account aan te maken en de trackingcode in de header te plaatsen. Clicky heeft daarnaast plug-ins voor de meeste grote cms'en, zoals WordPress, Drupal en Joomla. Ook heeft de dienst integratie voor pakketten als Angular en Ruby Rack.
Opvallend is dat de JavaScript-snippet standaard een affiliatelink bevat, die prominent op alle pagina's komt te staan. Dat is irritant, zeker omdat het standaard is, en ook niet erg gebruiksvriendelijk.
Je kunt de snippet op veel manieren handmatig aanpassen als je behoefte hebt aan specifiekere tracking. Je kunt gemakkelijk een noscript toevoegen waarmee gebruikers via een pixel kunnen worden gevolgd. Clicky stelt daarnaast een reverse proxy beschikbaar voor Nginx, Apache, Caddy en PHP. Verder kun je JavaScript-elementen toevoegen voor veel verschillende typen extra tracking of waar je juist functionaliteit wilt uitschakelen, zoals heatmaps op bepaalde pagina's.
Hoe werkt het praktisch?
Als je voor het eerst in Clicky's omgeving komt voor je eigen domein, vraag je je even af of je niet een paar jaar terug in de tijd bent gegooid. Je ziet er een klein grafiekje en tig willekeurig neergeplempte links met een overdaad aan pictogrammen die het hele dashboard een ouderwetse uitstraling geven. Daarachter ligt echter een verrassend uitgebreid systeem, maar je moet wel om de vele andere pictogrammen heen kunnen kijken. Bovendien maakt Clicky een aantal vreemde UX-keuzes. Om onduidelijke redenen worden individuele bezoekers bijvoorbeeld weergegeven met de naam van hun provider. Het is wel interessant dat gebruikers van achter een vpn meteen als zodanig worden aangeduid.
/i/2006013564.png?f=imagenormal)
Clicky toont je in het hoofddashboard meteen 'The Basics', zoals het zelf zegt: bezoekers, totale en gemiddelde tijd op de pagina en bouncerates, naast een paar blokjes met referentieverkeer, zoektermen waarop je site is gevonden en die providerlijst. Als je daarop doorklikt, zie je direct alle gegevens van die ene bezoeker tijdens een sessie. Daar staat naast fingerprintinginformatie als de browser, het OS, het apparaat en de schermgrootte ook een IP-adres. Dat lijkt raar, want in de standaardprivacyinstellingen staat uitgeschakeld dat je als beheerder IP-adressen verzamelt. Pas als je verder kijkt, zie je dat die IP-adressen geanonimiseerd zijn, omdat ze allemaal op .0 eindigen.
Zo anoniem ben je als individuele bezoeker overigens niet op een website. Je kunt individuele bezoekers volgen via een unieke identifier en daarmee ook precies zien wat ze allemaal nog meer op de website hebben gedaan, zoals wat de landingspagina was en waar ze allemaal nog meer naartoe gaan.
/i/2006013566.png?f=imagenormal) Je kunt in het algemeen veel informatie halen uit Clicky, veel meer dan met Umami of Plausible, al haalt Clicky het niet bij wat je uit Google Analytics trekt. Je kunt uiteraard doelen en campagnes instellen, maar ook heel specifiek zoeken naar welk type bezoeker welk soort pagina's bekijkt. Wel ontbreken goede rapportages die dat soort analyses voor je doen; je moet daarvoor de data exporteren.
Je kunt in het algemeen veel informatie halen uit Clicky, veel meer dan met Umami of Plausible, al haalt Clicky het niet bij wat je uit Google Analytics trekt. Je kunt uiteraard doelen en campagnes instellen, maar ook heel specifiek zoeken naar welk type bezoeker welk soort pagina's bekijkt. Wel ontbreken goede rapportages die dat soort analyses voor je doen; je moet daarvoor de data exporteren.
Privacy
Clicky zegt een privacyvriendelijk alternatief voor Google Analytics te zijn, maar dat is maar net hoe je het inricht. De standaard is in ieder geval sterk. Clicky plaatst geen trackingcookies en verzamelt alleen geanonimiseerde IP-adressen, maar dat kun je met een muisklik veranderen, dan verzamel je die IP-adressen wel. Je kunt dan ook instellen om cookies te laten plaatsen. Dat gebeurt onder meer om een eerste pageview te meten, maar ook om gebruikers over meerdere bezoeken te volgen.
Wat de privacyinstellingen ook zijn, Clicky verzamelt in ieder geval veel informatie om gebruikers te fingerprinten, zoals de browserversie, het apparaat, schermgrootte en meer. Het koppelt die ook aan die unieke identifier, dus hoewel het IP-adres buiten schot mag blijven, is dat ook weer niet compleet anoniem.
/i/2006013568.png?f=imagenormal)
Het bedrijf zegt in een faq dat beheerders voldoen aan de AVG, maar zegt vervolgens dat de AVG 'eist dat gebruikers data alleen mogen delen na een opt-in' en dat is pertinent onwaar. Vervolgens staat er onder in de faq: "We zijn geen advocaten en dit is geen juridisch advies. Raadpleeg je advocaat." Waarvan akte.
De gegevens die je verzamelt van je bezoekers, worden ook door Clicky gebruikt voor een tool om browseraandeel te meten. Waarom dat is, is niet bekend; het voelt een beetje willekeurig, hoewel Clicky bezweert dat die gegevens geanonimiseerd worden.

/i/2006013530.png?f=imagegallery)


/i/2006013566.png?f=imagegallery)
/i/1352652185.png?f=fpa)
:strip_exif()/i/2004882114.jpeg?f=fpa)
/i/1387804260.png?f=fpa)
:strip_exif()/i/2004743102.jpeg?f=fpa)
/i/2005583624.png?f=fpa)
/i/2004779058.png?f=fpa)
/i/2004735554.png?f=fpa)
/i/2004907440.png?f=fpa)