OpenAI zegt dat o3 meer hallucineert dan het o1-taalmodel. De AI-onderzoeksorganisatie zegt ook dat o4-mini minder nauwkeurig is dan o1. OpenAI schrijft dat er meer onderzoek nodig is om de oorzaken te achterhalen.
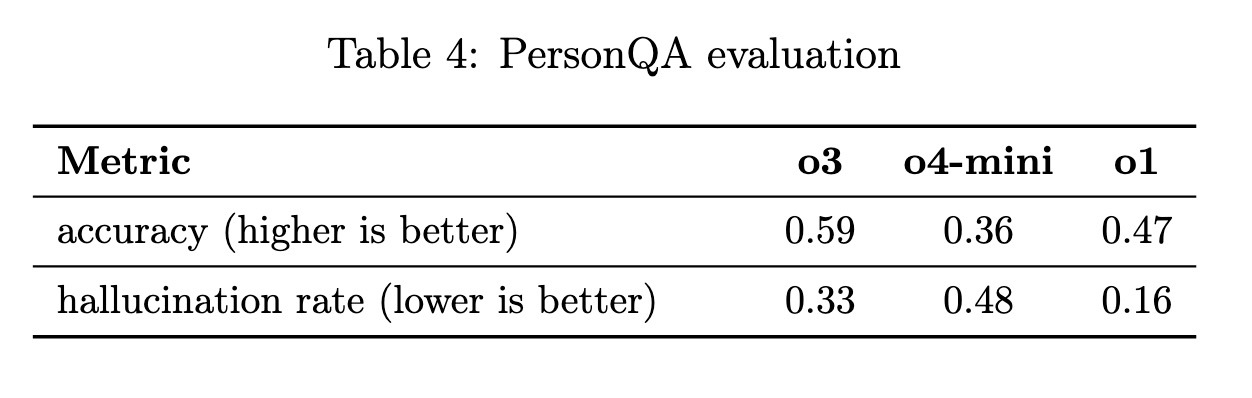
OpenAI heeft o3 en o4-mini naar eigen zeggen op nauwkeurigheid en hallucinaties getest via PersonQA. Dat is een evaluatietool met vragen en openbaar beschikbare feiten die niet enkel hallucinaties bij taalmodellen kan uitlokken, maar ook nagaat hoe nauwkeurig de antwoorden van de taalmodellen zijn.
Uit deze test blijkt dat o3 nauwkeuriger is dan zowel o4-mini als o1, maar ook dat het o1-taalmodel nauwkeuriger is dan o4-mini. "Dit is te verwachten", klinkt het bij OpenAI. "Kleinere modellen hebben minder wereldlijke kennis en hebben de neiging om meer te hallucineren." Het bedrijf heeft via de test ook opgemerkt dat o3 meer hallucineert dan o1. Het o4-mini-taalmodel zou ook meer hallucineren dan zowel o3 als o1.
OpenAI heeft o1 in het najaar van 2024 uitgebracht. Dit taalmodel gebruikt meer rekenkracht dan voorgaande modellen en kan hierdoor tot logischere antwoorden komen. O1 produceert ook een zogenaamde gedachtegang voordat het een antwoord aan gebruikers geeft. In december van 2024 werden o3 en o3-mini onthuld. Deze nieuwe AI-modellen zouden nog beter presteren dan o1. Het o3-taalmodel kwam midden april op de markt, samen met o4-mini. Dat laatste model is een kleiner taalmodel dat volgens OpenAI vooral uitblinkt in efficiënte redeneringen.

:strip_exif()/i/2005682890.jpeg?f=fpa)
:strip_exif()/i/2007460878.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2005794098.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
:strip_exif()/i/2006285086.jpeg?f=fpa)
:strip_icc():strip_exif()/u/391610/joris-vergeer.jpg?f=community)
:strip_icc():strip_exif()/u/235816/crop596740581e453_cropped.jpeg?f=community)
/u/30346/crop6571ad31b4cbc_cropped.png?f=community)
/u/2008130/crop6536ebba0daf2_cropped.png?f=community)
:strip_icc():strip_exif()/u/64489/hoogtevorst.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_exif()/u/25859/test2.gif?f=community)
:strip_icc():strip_exif()/u/183919/barcode.jpeg?f=community)
/u/1219196/crop6324b2e35d04c_cropped.png?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_icc():strip_exif()/u/125182/crop5f773b38ac426_cropped.jpeg?f=community)
/u/233220/crop58c922806f3c4_cropped.png?f=community)
/u/363743/crop61aa1329d36b8_cropped.png?f=community)
/u/1785734/crop6447a2e290e74_cropped.png?f=community)
:strip_icc():strip_exif()/u/92809/crop577f58c1b8795.jpeg?f=community)
:strip_exif()/u/324634/crop659fcf9abb18b_cropped.gif?f=community)
/u/284549/crop5c8c1d3ca48d4.png?f=community)
:strip_icc():strip_exif()/u/149215/maillist.jpg?f=community)
:strip_icc():strip_exif()/u/517742/crop5a3cc583be19f_cropped.jpeg?f=community)
/u/23785/crop5dcd5c59e07f9.png?f=community)
:strip_icc():strip_exif()/u/2081084/crop69594ea6c0094_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/106218/wc-backbone.jpg?f=community)
:strip_icc():strip_exif()/u/432714/crop6287e94322cf6_cropped.jpg?f=community)
/u/584567/crop65f4177d0b95d.png?f=community)
:strip_exif()/u/8178/hitchhikersguidethemoviesmall.gif?f=community)
:strip_icc():strip_exif()/u/453604/crop57e3900d4f760_cropped.jpeg?f=community)
/u/64683/crop67e6d240d8cdc_cropped.png?f=community)
/u/1505472/crop67b98a9a4ffd2_cropped.png?f=community)
:strip_icc():strip_exif()/u/132224/crop677a9fc7782e4.jpg?f=community)
/u/326977/crop64ca134a287fb_cropped.png?f=community)
/u/208006/Zagor%2520small.JPG?f=community)
:strip_icc():strip_exif()/u/112202/lighthouse.jpg?f=community)
:strip_icc():strip_exif()/u/177567/crop5f8591cadf088_cropped.jpeg?f=community)