Microsoft introduceert Security Copilot, een tool bedoeld voor professionals die zich bezighouden met cybersecurity. De tool is grotendeels gebaseerd op GPT-4 en combineert data van verschillende systemen om netwerken te monitoren en medewerkers te assisteren.
Microsoft zegt dat Security Copilot een handige tool kan zijn voor securitymedewerkers om snel bedreigingen te detecteren, op dreigingen te reageren en een beter begrip te krijgen voor het gehele digitale landschap van aanvallen en bedreigingen. Het idee is dat cybersecuritymedewerkers beter zien wat er gebeurt, waarbij Security Copilot kan leren van bestaande informatie en verbanden tussen dreigingsactiviteiten kan herkennen.
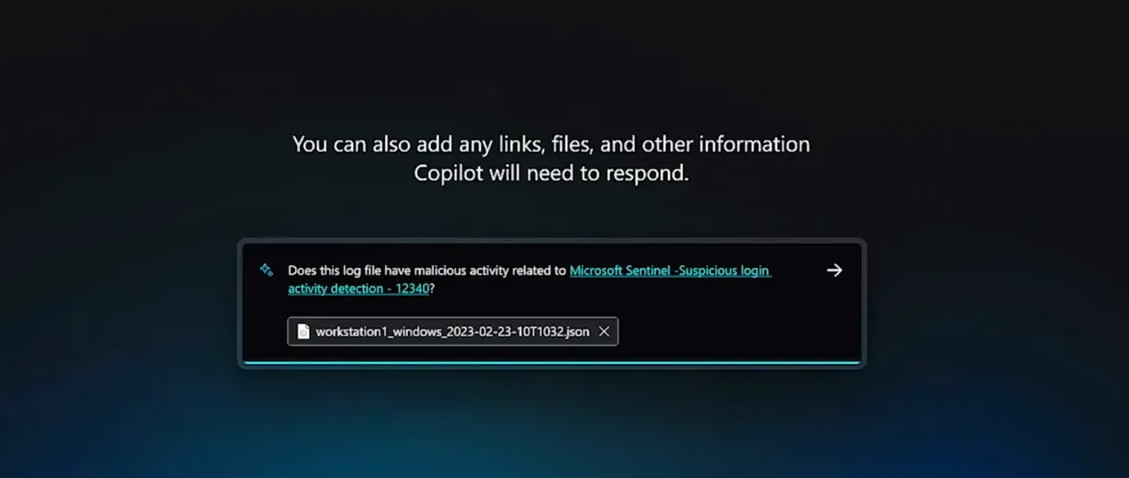
Security Copilot wordt voor een belangrijk deel gebaseerd op GPT-4 en Microsofts eigen securitymodel. Dat laatste model put onder meer uit informatie van Microsoft Sentinel en Microsoft Defender, maar ook overnames zoals die van RiskIQ and Miburo moeten bij het model helpen. Microsoft zegt dat er gebruik wordt gemaakt van 65 biljoen dagelijkse signalen die verzameld worden als onderdeel van inlichtingen over bedreigingen.
De tool ziet eruit als een simpel venster van een reguliere chatbot waar medewerkers onder meer kunnen vragen wat alle securityincidenten binnen het bedrijf zijn, waarna de bot ze samengevat weergeeft. Het is dan ook vooral bedoeld als een tool die medewerkers moet assisteren en niet zozeer vervangen.
Security Copilot is momenteel alleen beschikbaar als private preview en is vooralsnog alleen te gebruiken door een paar bedrijven. Wanneer de tool breder beschikbaar komt, is nog onbekend.

:strip_exif()/i/2004648164.jpeg?f=fpa)
:strip_exif()/i/2004677808.jpeg?f=fpa)
:strip_exif()/i/2005626738.jpeg?f=fpa)
/i/2004612546.png?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
:strip_exif()/i/2005684064.jpeg?f=fpa)
/i/2005672948.png?f=fpa)
:strip_exif()/i/2005559674.jpeg?f=fpa)
/i/2004765172.png?f=fpa)
/u/590416/crop5d8a8f12228ba_cropped.png?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/97374/crop5de67e3f09be9_cropped.jpeg?f=community)
/u/522811/crop5bd8c294db113_cropped.png?f=community)
/u/253895/crop5fddbb24425ea_cropped.png?f=community)
/u/2801/crop5ccb23f820755.png?f=community)
:strip_icc():strip_exif()/u/417493/crop58174774d1256.jpeg?f=community)
:strip_exif()/u/8178/hitchhikersguidethemoviesmall.gif?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/141718/crop68960f6a25222_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/204061/crop591d528256d44.jpeg?f=community)
/u/92059/crop6744f4439caa9_cropped.png?f=community)
:strip_icc():strip_exif()/u/572004/fox.jpg?f=community)
:strip_icc():strip_exif()/u/63694/crop6a6312e79bbab_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/162143/crop5b6d888e9cc79_cropped.jpeg?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_icc():strip_exif()/u/21673/crop65674aee06c6d_cropped.jpg?f=community)
:strip_exif()/u/119419/candc-60px.gif?f=community)
:strip_icc():strip_exif()/u/11499/morphie.jpg?f=community)
:strip_icc():strip_exif()/u/51314/crop65e716f8e88b9_cropped.jpg?f=community)
/u/237439/cloudy-small-orange.png?f=community)
:strip_icc():strip_exif()/u/411972/crop56b8bc889d57e_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/149215/maillist.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)