Github heeft Copilot, een AI-gestuurde pair programmer die ontwikkelaars helpt bij het schrijven van code, uitgebracht voor het brede publiek. De tool kost 10 dollar per maand of 100 dollar per jaar. Studenten en medewerkers van populaire opensourceprojecten hoeven niet te betalen.
GitHub bracht een jaar geleden een preview uit van Copilot en die werd volgens Github op twaalf maanden tijd door meer dan 1,2 miljoen ontwikkelaars gebruikt. In projecten waarbij de AI-gestuurde pair programmer werd ingeschakeld, werd bijna 40 procent van de code door Copilot geschreven.
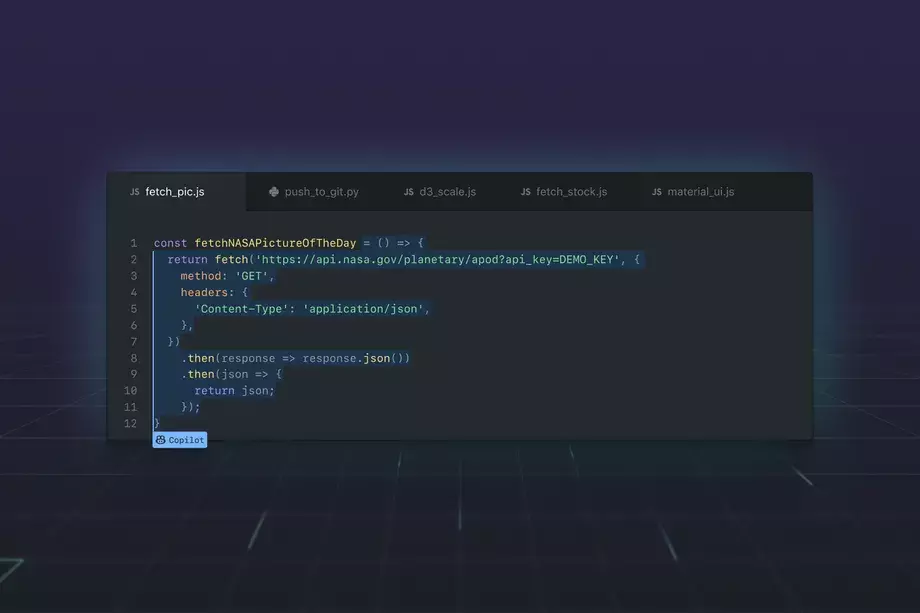
Copilot is ontwikkeld in samenwerking met OpenAI en maakt gebruik van de OpenAI Codex. De AI-toepassing geeft tijdens het programmeren suggesties voor nieuwe regels code, maar ook voor complete functies. De tool analyseert hiervoor de huidige code van het project. Copilot kan ook opmerkingen omzetten in code, repetitieve code aanvullen en functies uittesten tijdens het schrijven. Gebruikers kunnen suggesties die aangereikt werden door de tool, toevoegen aan hun project of gewoonweg negeren. Voorgestelde code kan ook manueel aangepast worden.
Copilot is volgens Github meer dan een autocomplete. De tool leert bijvoorbeeld van de context, maar ook uit vooraf geschreven code. Het begrijpt wanneer er een docstring wordt getypt, een opmerking, een functienaam of een reguliere regel code. De tool is als een extensie te downloaden voor Microsoft Visual Studio Code, Neovim en verschillende JetBrains IDE's.

/i/2001590657.png?f=fpa)
:strip_exif()/i/2005684064.jpeg?f=fpa)
/i/2004697898.png?f=fpa)
:strip_exif()/i/2004648162.jpeg?f=fpa)
:strip_exif()/i/2004607446.jpeg?f=fpa)
:strip_exif()/i/2005559674.jpeg?f=fpa)
/i/2004765172.png?f=fpa)
:strip_exif()/i/2004816210.jpeg?f=fpa)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
/u/576549/crop6392069a982d9_cropped.png?f=community)
/u/1219196/crop6324b2e35d04c_cropped.png?f=community)
/u/1177382/crop5f217a548e95a_cropped.png?f=community)
/u/23785/crop5dcd5c59e07f9.png?f=community)
:strip_icc():strip_exif()/u/278471/crop6a01c645c1e6b_cropped.jpg?f=community)
/u/28273/crop69e9fdd0bbefc_cropped.png?f=community)
:strip_icc():strip_exif()/u/789283/crop65b0dfe4af024_cropped.jpg?f=community)
/u/47542/crop5835c0be871d0_cropped.png?f=community)
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
:strip_icc():strip_exif()/u/46692/wiegel.jpg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/30388/Sesame50.JPG?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
/u/581347/crop64beea7e7f624_cropped.png?f=community)
:strip_icc():strip_exif()/u/14521/usericon.jpg?f=community)
:strip_exif()/u/677/crop5e62ccc026e5a_cropped.gif?f=community)
/u/331213/crop56ef13408ff38_cropped.png?f=community)
/u/286895/icon1.png?f=community)
:strip_icc():strip_exif()/u/1434986/crop649350276f23c_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/279447/crop593f3db0b456b_cropped.jpeg?f=community)
/u/1123253/crop6a0cfad2c4b89_cropped.png?f=community)
/u/228830/crop5f12f640b47c9_cropped.png?f=community)
:strip_exif()/u/30814/newgot.gif?f=community)
:strip_icc():strip_exif()/u/714982/crop566812d61015a_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/417493/crop58174774d1256.jpeg?f=community)
:strip_icc():strip_exif()/u/233767/crop5db03cbc075aa.jpeg?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_icc():strip_exif()/u/1485486/crop5fb58952a8657.jpeg?f=community)
:strip_exif()/u/120134/Cucco.gif?f=community)
:strip_icc():strip_exif()/u/264356/crop6798ef4c9f503_cropped.jpg?f=community)
:strip_exif()/u/843369/crop59fc41cc1102d_cropped.gif?f=community)
:strip_exif()/u/490207/Einstein.gif?f=community)