ChatGPT-maker OpenAI heeft een tool online gezet die beoordeelt of een tekst waarschijnlijk geschreven is door kunstmatige intelligentie of niet. OpenAI heeft de tool online gezet als 'startpunt in de discussie rond AI-geletterdheid'.
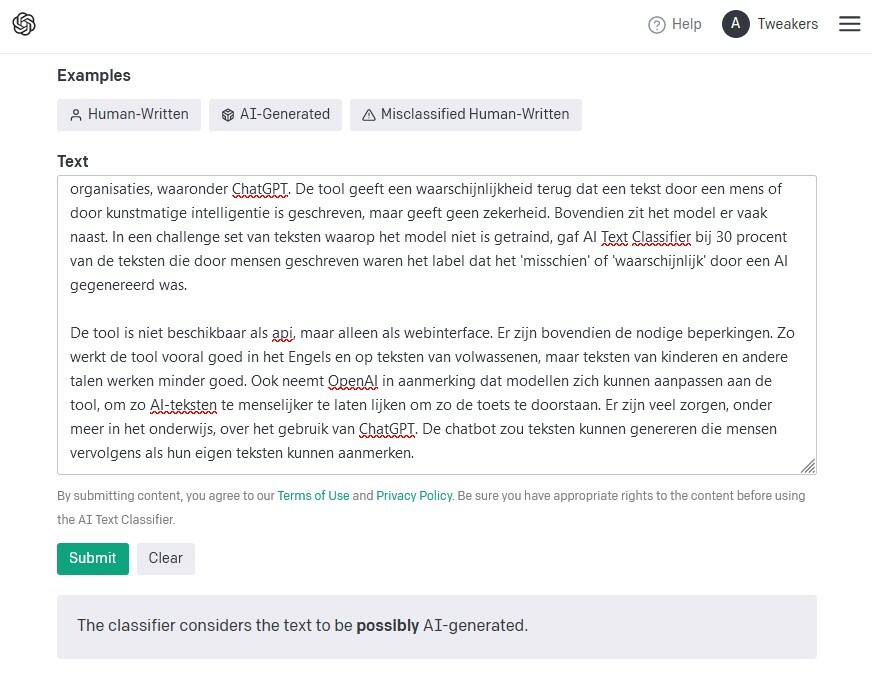
OpenAI noemt het AI Text Classifier en heeft het model getraind op 34 modellen van 5 verschillende organisaties, waaronder ChatGPT. De tool geeft een waarschijnlijkheid terug dat een tekst door een mens of door kunstmatige intelligentie is geschreven, maar geeft geen zekerheid. Bovendien zit het model er vaak naast. In een challenge set van teksten waarop het model niet is getraind, gaf AI Text Classifier bij 30 procent van de teksten die door mensen geschreven waren het label dat het 'misschien' of 'waarschijnlijk' door een AI gegenereerd was.
De tool is niet beschikbaar als api, maar alleen als webinterface. Er zijn bovendien de nodige beperkingen. Zo werkt de tool vooral goed in het Engels en op teksten van volwassenen, maar teksten van kinderen en in andere talen werken minder goed. Ook neemt OpenAI in aanmerking dat modellen zich kunnen aanpassen aan de tool, om zo AI-teksten menselijker te laten lijken om zo de toets te doorstaan. Er zijn veel zorgen, onder meer in het onderwijs, over het gebruik van ChatGPT. De chatbot zou teksten kunnen genereren die mensen vervolgens als hun eigen teksten kunnen aanmerken.
| OpenAI Text Classifier | Threshold | Aandeel door mensen geschreven tekst* | Aandeel door AI geschreven tekst* |
| Very unlikely to be AI generated | <0,1 | 5% | 2% |
| Unlikely to be AI generated | 0,1 - 0,45 | 15% | 10% |
| Unclear if it is AI written | 0,45 - 0,9 | 50% | 34% |
| Possibly AI generated | 0,9 - 0,98 | 21% | 28% |
| Likely AI generated | 0,98 - 1 | 9% | 26% |
* uit de challenge set waarmee het model is uitgeprobeerd

/i/2005490828.png?f=fpa)
:strip_exif()/i/2005676974.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005595038.png?f=fpa)
:strip_exif()/i/2005044682.jpeg?f=fpa)
:strip_exif()/i/2004611192.jpeg?f=fpa)
:strip_exif()/i/2005345144.jpeg?f=fpa)
/u/39/crop6936c84f55170_cropped.png?f=community)
:strip_icc():strip_exif()/u/140697/crop6180fb9103afa_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/327863/crop576544f956388_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/71115/plus222.jpg?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/21673/crop65674aee06c6d_cropped.jpg?f=community)
:strip_exif()/u/395565/crop583ee602f2109_cropped.gif?f=community)
/u/41514/crop5c3b77c8badbf_cropped.png?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
:strip_icc():strip_exif()/u/1483544/crop5fa7be021ded9_cropped.jpeg?f=community)
/u/28892/flo.png?f=community)
:strip_icc():strip_exif()/u/3730/oddball.jpg?f=community)
/u/200408/crop664f322f9f1bd_cropped.png?f=community)
:strip_icc():strip_exif()/u/497236/crop56388f94002d7_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/567214/crop60759ec284fe4_cropped.jpg?f=community)