OpenAI en Microsoft zouden onderzoeken of DeepSeek de api's van OpenAI-diensten hebben misbruikt om output van OpenAI-modellen te vergaren. Daarmee zou DeepSeek zijn V3- en R1-modellen hebben getraind.
Microsoft, die clouddiensten levert aan OpenAI, wees de maker van ChatGPT afgelopen najaar op de ongebruikelijke activiteit, meldt Bloomberg. Accounts gelinkt aan DeepSeek zouden restricties omzeilen om zoveel mogelijk output via de api's te verzamelen.
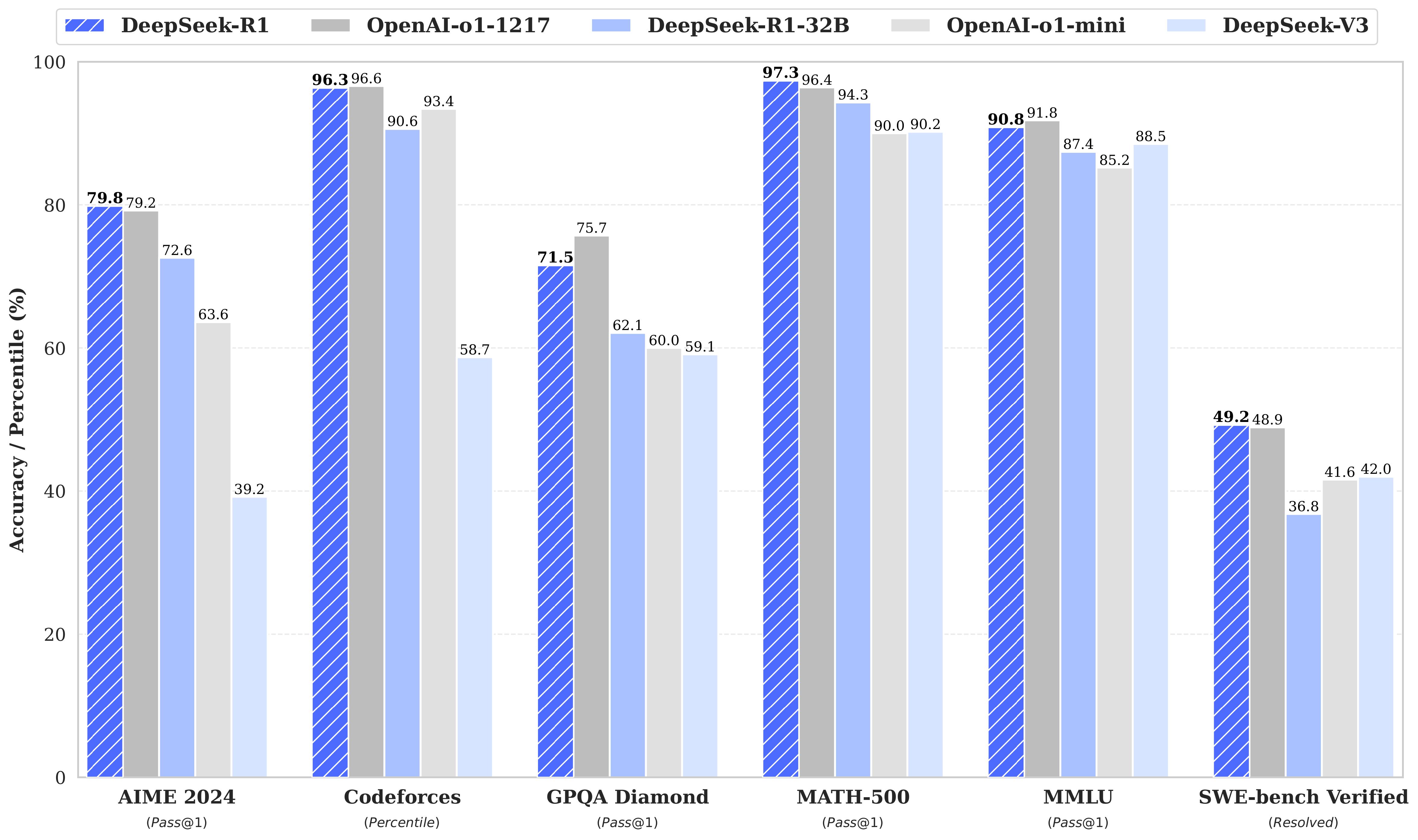
Die data zou DeepSeek gebruiken om zijn modellen V3 en R1 te trainen. Dat systeem heet destillatie, waarbij het kleinere model vrijwel even goed kan presteren als het model waaruit het destilleert, maar veel minder data en training nodig heeft. DeepSeek claimt dat V3 getraind is met 2,788 miljoen gpu-uren, waarvan veruit de meeste in pretraining. Dat is uitzonderlijk weinig.
David Sacks, die voor de regering-Trump verantwoordelijk is voor beleid rond AI en cryptovaluta, claimt volgens Bloomberg ook dat DeepSeek via destillatie OpenAI-data heeft gebruikt. Doorgaans gebruiken AI-diensten destillatie alleen op eigen modellen, om zo kleinere modellen aan te bieden.
De betrokken bedrijven reageren niet inhoudelijk. OpenAI erkent wel de praktijk van destillatie door Chinese bedrijven. "We weten dat in China gevestigde bedrijven - en andere - voortdurend proberen om de modellen van toonaangevende Amerikaanse AI-bedrijven te distilleren. Als toonaangevende AI-ontwikkelaar nemen we tegenmaatregelen om ons intellectueel eigendom te beschermen, waaronder een zorgvuldig proces voor het opnemen van grensverleggende mogelijkheden in vrijgegeven modellen, en we zijn ervan overtuigd dat het van cruciaal belang is dat we nauw samenwerken met de Amerikaanse overheid om de geavanceerdste modellen zo goed mogelijk te beschermen tegen pogingen van tegenstanders en concurrenten om Amerikaanse technologie te stelen."

:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
:strip_exif()/i/2007212562.jpeg?f=fpa)
/i/2004618396.png?f=fpa)
:strip_icc():strip_exif()/u/1128253/crop683ccc0b0255b_cropped.jpg?f=community)
/u/208006/Zagor%2520small.JPG?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)
/u/411953/crop6089ca36ea4b5_cropped.png?f=community)
:strip_exif()/u/8178/hitchhikersguidethemoviesmall.gif?f=community)
/u/152942/crop687206d7bca78.png?f=community)
:strip_icc():strip_exif()/u/63694/crop6a6312e79bbab_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/20646/crop68f8089046714_cropped.jpg?f=community)
/u/767409/crop62335cccc4f1d_cropped.png?f=community)
:strip_icc():strip_exif()/u/42559/crop68b894d172ae2_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/235816/crop596740581e453_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/561033/kermit.jpg?f=community)
/u/88794/dj_henk4b.png?f=community)
:strip_icc():strip_exif()/u/35767/images.jpg?f=community)
/u/330457/Knipsel.JPG?f=community)
/u/710404/crop5e9f7de15e964_cropped.png?f=community)
/u/269200/crop6336d139a4afb_cropped.png?f=community)
:strip_icc():strip_exif()/u/92809/crop577f58c1b8795.jpeg?f=community)
:strip_icc():strip_exif()/u/80495/crop6411d3c747b15_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/476420/crop5623d9ad036cf_cropped.jpeg?f=community)
/u/30465/billgates2.PNG?f=community)
:strip_icc():strip_exif()/u/204061/crop591d528256d44.jpeg?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/319678/Battlecruiser_SC2_Head1.jpg?f=community)
/u/39/crop6936c84f55170_cropped.png?f=community)
:strip_exif()/u/267506/crop6737556602b99.gif?f=community)
:strip_icc():strip_exif()/u/312250/crop58172eb91ebc5_cropped.jpeg?f=community)
/u/48718/crop619e5ed546e66_cropped.png?f=community)
:strip_icc():strip_exif()/u/312233/crop5f4f3f7c861dd_cropped.jpeg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_icc():strip_exif()/u/440019/crop5aa7bdc8528cb_cropped.jpeg?f=community)
/u/1277712/crop6979d0c48fc7b.png?f=community)
:strip_icc():strip_exif()/u/1607268/crop634e98e02c084.jpg?f=community)
/u/16/crop691b65c4ced7c_cropped.png?f=community)
{kind=link}
{kind=link}
{kind=link}