Microsoft heeft een nieuwe generatie van zijn kleine taalmodel Phi aangekondigd. Phi-4 telt 14 miljard parameters en zou vooral goed zijn in wiskundige vraagstukken. Phi-4 komt vanaf volgende week ook beschikbaar via Hugging Face.
Microsoft zegt dat het model voornamelijk goed is in het oplossen van wiskundige problemen. Het zou op dat vlak gemiddeld veel hoger scoren dan alternatieve kleine taalmodellen zoals Llama en GPT-4o, maar zelfs ook beter dan llm's zoals Gemini Pro 1.5 en Claude 3.5 Sonnet. Microsoft heeft het model bij wijze van proef getest op vraagstukken van de American Mathematics Competitions van de Amerikaanse Mathematical Association.
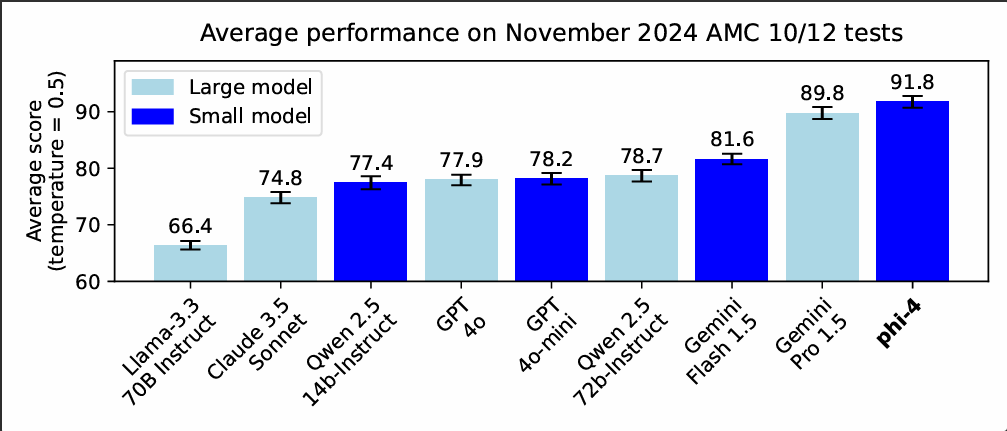
Phi-4 is vooralsnog alleen nog via Azure AI Foundry te gebruiken, het nieuwe ontwikkelaarsplatform van Microsoft zelf. Dat kan voorlopig alleen nog onder een Microsoft Research License Agreement, maar 'volgende week' komt het model ook beschikbaar via AI-platform Hugging Face, al is het onduidelijk onder welk licentiemodel dat gebeurt.
Het model is een opvolger van het vorige model dat Microsoft eerder dit jaar aankondigde. Dat model, Phi-3 Mini, telde 3,8 miljard parameters. Dat zijn er relatief weinig en veel minder dan Phi-4, dat er volgens Microsoft 14 miljard telt. Microsoft geeft verder weinig details over het model, behalve dat het dat heeft getraind op 'synthetische datasets van hoge kwaliteit'.
/i/2007136072.png?f=imagegallery)

:strip_exif()/i/2004677808.jpeg?f=fpa)
/i/2007013324.webp?f=fpa)
:strip_exif()/i/2006285086.jpeg?f=fpa)
/i/2004607120.png?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2005500190.jpeg?f=fpa)
:strip_exif()/i/2006765338.jpeg?f=fpa)
/i/2004838090.png?f=fpa)
:strip_exif()/i/2005559674.jpeg?f=fpa)
/u/12436/p1_normal.png?f=community)
/u/2008130/crop6536ebba0daf2_cropped.png?f=community)
:strip_icc():strip_exif()/u/63694/crop6a6312e79bbab_cropped.jpg?f=community)
/u/183354/day.png?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)