ChatGPT heeft in Europa bij betalende klanten de functie gekregen om gesprekken te onthouden. De functie Memory, of Geheugen in het Nederlands, was elders al langer beschikbaar.
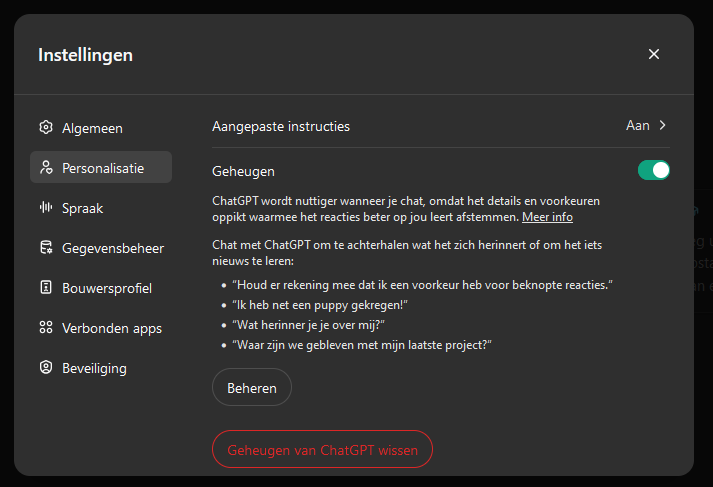
De functie is te vinden onder Instellingen-Personalisatie, zo merken diverse klanten op. Tweakers heeft met een eigen account kunnen verifiëren dat de functie beschikbaar is. Het was al langer duidelijk dat de functie ook in Nederland beschikbaar zou worden gesteld. De Britse ontwikkelaar Mike Grant ontdekte enkele weken geleden dat de faq alleen nog vermeldde dat de functie in 'Korea' niet beschikbaar is, waar voorheen Europa daar nog bij stond. OpenAI heeft niets gezegd over het beschikbaar stellen van de functie, die het mogelijk maakt om gesprekken te onthouden en zo voorkeuren en informatie mee te nemen in nieuwe gesprekken. Dat moet de antwoorden relevanter maken. De functie is niet beschikbaar voor gebruikers van de gratis versie.

:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/u/581347/crop64beea7e7f624_cropped.png?f=community)
:strip_icc():strip_exif()/u/86283/crop_south-park-s12e11-pandemic-2-the-startling_4x3.jpg?f=community)
:strip_icc():strip_exif()/u/137578/crop684839b85b72a.jpg?f=community)
:strip_exif()/u/165492/Kerst%252070.gif?f=community)
/u/204872/crop65a1d5f52b87f.png?f=community)
:strip_icc():strip_exif()/u/48297/diamond-2.jpg?f=community)
:strip_icc():strip_exif()/u/159233/cheetahDM2103_60x60.jpg?f=community)
:strip_icc():strip_exif()/u/563369/crop560071793b003_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/241618/crop5628ac183aa12_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/484495/crop5cdaccf9e200d_cropped.jpeg?f=community)
/u/590416/crop5d8a8f12228ba_cropped.png?f=community)
:strip_exif()/u/295799/cryava.gif?f=community)
:strip_icc():strip_exif()/u/369695/android%252060x60.jpg?f=community)
:strip_icc():strip_exif()/u/11499/morphie.jpg?f=community)
:strip_icc():strip_exif()/u/391610/joris-vergeer.jpg?f=community)