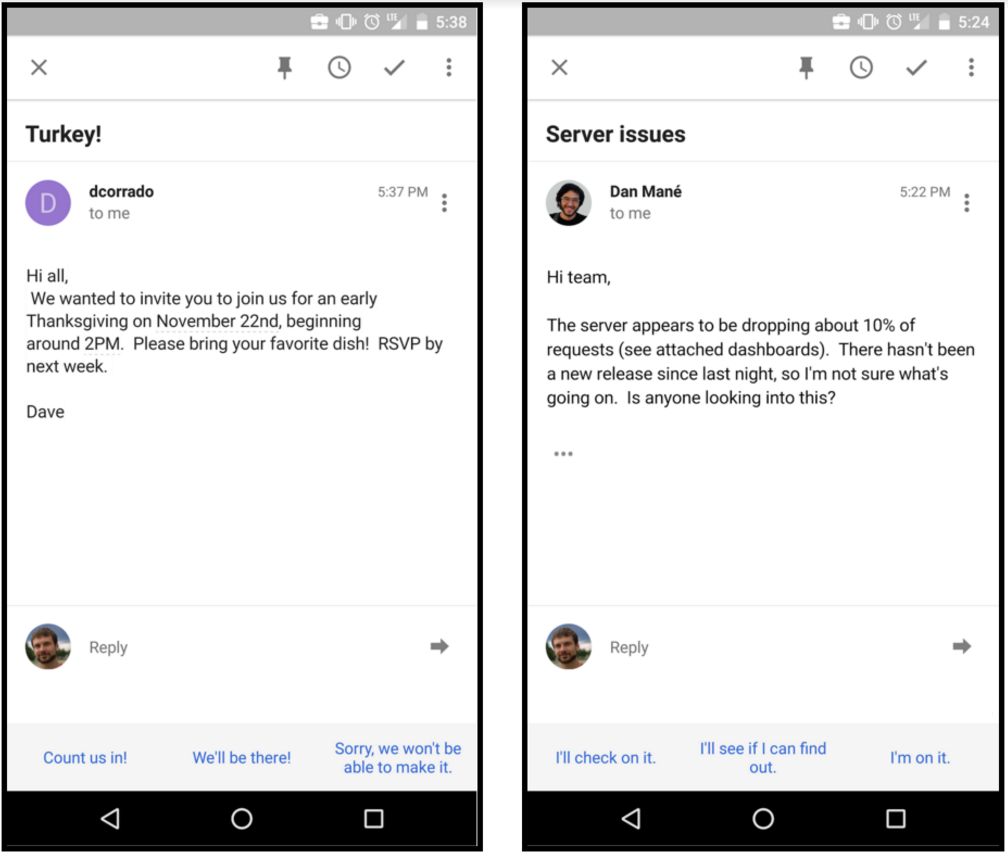
Google's Gmail-app Inbox gaat antwoordopties aanbieden als 'Smart Reply'-functie. Smart Reply suggereert drie antwoorden die gebaseerd zijn op de e-mails die de gebruiker krijgt. Voor e-mails die slechts een snel antwoord nodig hebben, 'bedenkt' Inbox drie verschillende, snelle antwoorden.
In eerste instantie zal de functie alleen beschikbaar zijn in het Engels. Gebruikers die hun taal op Engels hebben ingesteld, kunnen de update 'later deze week' als update verwachten, schrijft het Gmail-team op zijn blog. Het systeem wordt 'slimmer' naarmate het meer gebruikt wordt. Als het goed is, zijn de antwoorden 'sfw' ofwel geschikt voor de werkvloer.
Om tot de antwoorden te komen, heeft Google een neuraal netwerk opgezet dat als basis voor de Smart Reply-functie dient. In een uitgebreide blogpost op Google Research beschrijft onderzoeker Greg Corrado hoe het onderzoek om tot de automatische antwoordfunctie te komen, uitgevoerd werd. Het slimme antwoordsysteem is gebouwd op twee recurrent neural networks om inkomende e-mail te coderen en een om mogelijke antwoorden te voorspellen. Het coderende netwerk 'leest' de woorden van de binnenkomende e-mail woord voor woord. Daaruit maakt het een vector of lijst met nummers. Die vector moet de essentie van wat er gezegd wordt pakken, zonder te blijven steken op taalgebruik of woordkeus. Als voorbeeld geeft Corrado dat 'Are you free tomorrow?' vergelijkbaar moet zijn voor de vector als 'Does tomorrow work for you?'. Het tweede netwerk begint vanaf die gedachtevector en maakt hiervan twee grammaticaal correcte antwoorden, ook weer woord voor woord. Het verbazingwekkende is volgens Corrado dat 'de hele handeling van het netwerk volledig geleerd is, alleen maar door het model te trainen om mogelijke antwoorden te voorspellen'.
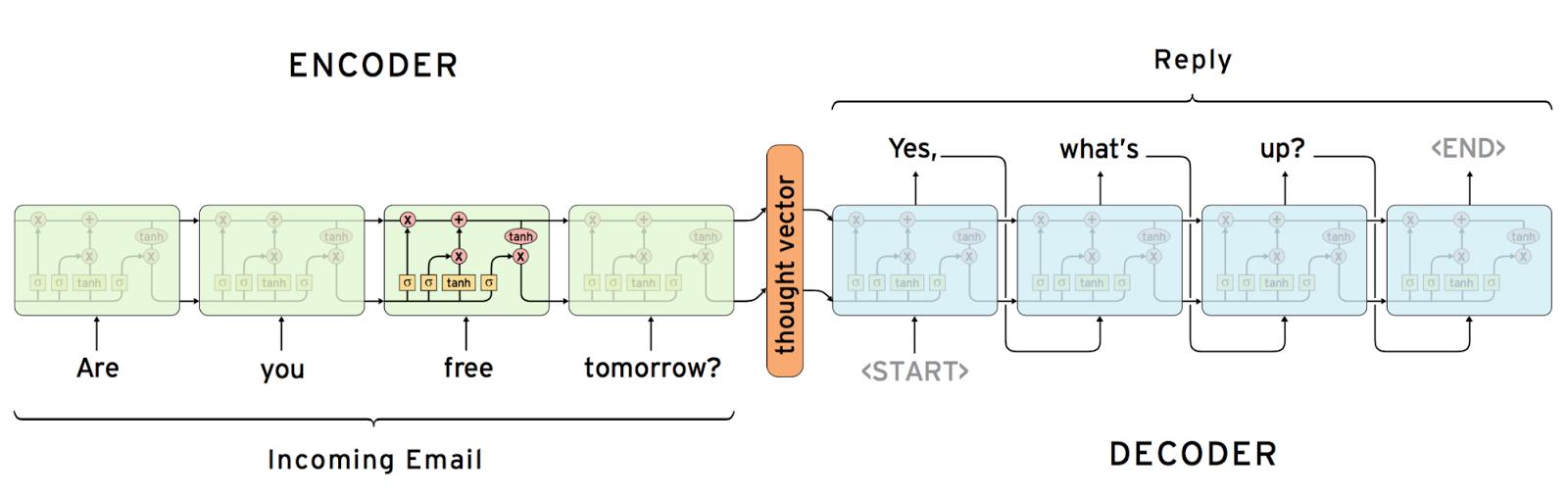
Een van de grootste uitdagingen is dat een e-mail vaak honderden woorden lang is. Daar komt een speciaal type neurale netwerken om de hoek kijken, een zogenaamd 'long short-term-memory'-netwerk of lstm-netwerk. Dit soort netwerken onthoudt informatie voor een lange tijd, iets wat recurrent neural networks, of rnn's ook doen, maar in praktijk kunnen die slechter informatie goed koppelen die verder uit elkaar ligt. Omdat lstm's dat beter kunnen, weet dit soort netwerken een zinvol antwoord te verzinnen vanuit de relevante zinnen, zonder afgeleid te worden door tussenliggende informatie.
In het eerste prototype van het systeem zat een aantal wonderlijke reacties en andere rare grillen. Zoals het genereren van kandidaat-antwoorden leidde tot drie vergelijkbare antwoorden die heel dichtbij elkaar lagen, zoals 'zullen we morgen bij elkaar komen', 'zullen we morgen afspreken' en 'hoe zit je morgen?'. Daarna werd er een systeem om natuurlijke taal in kaart te brengen toegevoegd, waardoor antwoorden diverser werden. Maar het systeem deed meer gekke dingen, zoals standaard 'I love you' als antwoord voor te stellen, iets wat niet heel bruikbaar is als antwoord in de meeste gevallen.
Uiteraard wijst Corrado nog op de veiligheid van het systeem, dat de privacy wordt gewaarborgd en er geen echte mensen meelezen. Iets wat direct problemen oplevert voor onderzoekers, omdat ze met datasets werken die ze zelf niet kunnen lezen. Iets als 'een puzzel oplossen terwijl je geblinddoekt bent'.

/i/2000581470.png?f=fpa)
/i/2001948899.png?f=fpa)
/i/2000658159.png?f=fpa)
/i/1354191453.png?f=fpa)
:strip_exif()/i/1296218968.gif?f=fpa)
:strip_exif()/i/1336040302.jpeg?f=fpa)
:strip_exif()/i/1171896603.gif?f=fpa)
/i/1316504693.png?f=fpa)
:strip_exif()/i/1187352419.jpg?f=fpa)
:strip_exif()/i/1398151713.jpeg?f=fpa)
/i/1198048718.png?f=fpa)
/i/1263287364.png?f=fpa)
/u/246423/crop5979eb9e5c60f_cropped.png?f=community)
/u/420420/crop590752c61ff42_cropped.png?f=community)
:strip_icc():strip_exif()/u/378936/crop689e60d837b65_cropped.jpg?f=community)
/u/657400/crop573db8c9de87a_cropped.png?f=community)
:strip_icc():strip_exif()/u/112202/lighthouse.jpg?f=community)
/u/152942/crop687206d7bca78.png?f=community)
:strip_icc():strip_exif()/u/538020/crop56d8095ba0e76_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/82118/crop5e8496328224b_cropped.jpeg?f=community)
:strip_exif()/u/411081/crop62fd038e12a38_cropped.gif?f=community)
:strip_icc():strip_exif()/u/295081/crop643e9f0d388cb_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/53639/iconstar.jpg?f=community)
:strip_icc():strip_exif()/u/330697/crop5fe36d93cacc0_cropped.jpeg?f=community)
:strip_exif()/u/7013/spunky_main.gif?f=community)
:strip_exif()/u/41628/Tigerweb.gif?f=community)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
:strip_icc():strip_exif()/u/302313/crop58766c1b38923_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/531080/crop55d21e245d3bd_cropped.jpeg?f=community)
/u/155722/Looneytunes.png?f=community)
:strip_icc():strip_exif()/u/64465/crop5db09addab56c_cropped.jpeg?f=community)
/u/35505/flx_70x70.png?f=community)
/u/36659/crop65f402601bb24_cropped.png?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
:strip_exif()/u/489455/7750.gif?f=community)
:strip_icc():strip_exif()/u/18149/catfish60.jpg?f=community)
:strip_icc():strip_exif()/u/233767/crop5db03cbc075aa.jpeg?f=community)
/u/123066/crop5db977bf69322.png?f=community)
:strip_icc():strip_exif()/u/345166/korn.jpg?f=community)