Neurale netwerken zijn overal
Bijna iedereen met een computer heeft dagelijks te maken met kunstmatige intelligentie, meestal onopgemerkt als het allemaal goed gaat, maar vaak een beetje koddig als het verkeerd gaat. Hoe ziet dat er dan uit? Laten we een gemiddelde dag van iemand met een Android-telefoon nemen. Als je opstaat, krijg je van je Google Now-stream te zien of er file is op het traject naar je werk: dat doet ai voor je. Onderweg luister je misschien naar Spotify of een andere muziekdienst. Dikke kans dat je playlist gemaakt is op basis van aanbevelingen naar aanleiding van eerder beluisterde muziek en daaruit geëxtrapoleerde voorkeuren. Het werk van ai.
 In je lunchpauze kun je mooi even wat cadeautjes voor de komende feestdagen bij elkaar shoppen. Of je dat nu bij Amazon, Bol.com of een andere winkel doet, bijna allemaal maken ze gebruik van aanbevelingen en geven ze suggesties om ook andere producten te kopen, op basis van jouw eerdere koopgedrag, dat van anderen die dezelfde producten kochten, en wat populair is. Opnieuw het werk van ai.
In je lunchpauze kun je mooi even wat cadeautjes voor de komende feestdagen bij elkaar shoppen. Of je dat nu bij Amazon, Bol.com of een andere winkel doet, bijna allemaal maken ze gebruik van aanbevelingen en geven ze suggesties om ook andere producten te kopen, op basis van jouw eerdere koopgedrag, dat van anderen die dezelfde producten kochten, en wat populair is. Opnieuw het werk van ai.
Als je toevallig uit eten gaat en een plaatje schiet van je dessert om anderen jaloers te maken, wordt je foto als dessert geclassificeerd en automatisch in een lijst met soortgelijke foto's ingedeeld. Ook het zoeken naar soortgelijke afbeeldingen, zowel binnen je eigen foto's als online, is het domein van ai.
En als je 's avonds op de bank ploft en wat Netflix wil kijken en door je aanbevolen lijst films of series scrollt, worden die lijsten weer gemaakt op basis van eerder kijkgedrag en dat van anderen. Uiteraard zit ook daar weer een ai-toepassing achter.
Kortom, je dagelijks leven wordt in hoge mate geregeld door diverse vormen van kunstmatige intelligentie. Je merkt er alleen weinig van zolang het goed gaat. Pas als er een in jouw ogen volledig idiote beslissing gemaakt wordt, valt op dat er misschien een algoritme achter al die dingen zit. Tijd om in de wereld achter onze wereld te duiken.
Is een neuraal netwerk een ai?
De bekendste termen uit de wereld van kunstmatige intelligentie of de Engelstalige variant artificial intelligence zijn waarschijnlijk machinelearning, deep learning, big data en natuurlijk neural networks. Wat betekenen die termen en wat zit erachter? Leiden neurale netwerken tot echte kunstmatige intelligentie, staat Skynet op het punt om bewustzijn te krijgen of besluipt kunstmatige intelligentie, mogelijk gemaakt door neurale netwerken, onze samenleving gewoon langzaam en ongemerkt?
/i/2001747169.jpeg?f=imagenormal) Een bekende uitspraak in onderzoek naar kunstmatige intelligentie is dat het geen ai meer genoemd wordt zodra het werkt en dat alles wat nog niet lukt, ai is. Dat het steeds beter en in steeds meer toepassingen werkt, merk je aan alles. Veel bedrijven zijn er niet scheutig mee om iets als ai te classificeren, maar een neuraal netwerk in een product of toepassing wordt wel met veel tamtam aangekondigd. Het is het buzzword van 2017 en dat zal in 2018 vast niet veranderen. Om een voorbeeld te noemen: smartphonefabrikant Huawei adverteert zijn Mate 10 Pro met het vermelden van een npu of neural processing unit aan boord en AMD sprak al voor zijn Zen-architectuur van een neuraal netwerk in zijn branch predictor om zijn processors sneller te maken.
Een bekende uitspraak in onderzoek naar kunstmatige intelligentie is dat het geen ai meer genoemd wordt zodra het werkt en dat alles wat nog niet lukt, ai is. Dat het steeds beter en in steeds meer toepassingen werkt, merk je aan alles. Veel bedrijven zijn er niet scheutig mee om iets als ai te classificeren, maar een neuraal netwerk in een product of toepassing wordt wel met veel tamtam aangekondigd. Het is het buzzword van 2017 en dat zal in 2018 vast niet veranderen. Om een voorbeeld te noemen: smartphonefabrikant Huawei adverteert zijn Mate 10 Pro met het vermelden van een npu of neural processing unit aan boord en AMD sprak al voor zijn Zen-architectuur van een neuraal netwerk in zijn branch predictor om zijn processors sneller te maken.

De weg naar kunstmatige intelligentie is in het verleden al op verschillende manieren bewandeld. Een van de aspecten van ai waar we steeds vaker over horen en mee te maken hebben, zijn neurale netwerken. Ze kunnen afbeeldingen herkennen, geschreven en gesproken tekst vertalen en patronen distilleren uit grote hoeveelheden data. Hoe werken die neurale netwerken, wat is het principe erachter, wie houden zich ermee bezig en hoe verschillen die implementaties?
Laten we eerst eens naar een neuraal netwerk kijken en met een gedachte-experiment een simpel neuraal netwerk maken. Wat een neuraal netwerk niet is, is een simulatie van een stel neuronen, zoals die zich in onze hersenen bevinden. Wegens de analogie houden we wel de term 'neuronen' aan, omdat neuronen in een neuraal netwerk, net als biologische neuronen, inputs kunnen middelen en anders dan bits een variabele waarde kunnen hebben tussen 0 en 1. Een eenvoudig neuraal netwerk bestaat uit drie neuronen: een invoerneuron in de inputlaag, een verwerkingsneuron in een verborgen laag en een uitvoerneuron in de uitvoerlaag.
/i/2001747173.png?f=imagenormal)
Een neuraal netwerk kun je dan ook zien als een grote rekensom. Een groot neuraal netwerk heeft navenant meer rekenkracht nodig, niet zozeer meer transistors om een neuron te simuleren. Meer hardware tegen een neuraal net aangooien heeft zin, want het trainen en berekenen van uitvoer is rekenintensief. Als architectuur bestaat een neuraal netwerk uit een laag inputneuronen, een verborgen of hidden laag die uit een of meer lagen neuronen bestaat, en een uitvoerlaag. Een netwerk kan tientallen lagen bevatten, maar vooralsnog zijn de neuronen in die lagen nog in de honderd- of duizendtallen te tellen.
Hoe werkt een neuraal netwerk?
Een van de eenvoudigste neurale netwerken, in de ruime zin van het begrip, is een netwerk dat handgeschreven cijfers kan herkennen. Uiteraard is input nodig, in dit geval een afbeelding die een raster van 28 bij 28 pixels naar het neurale netwerk stuurt. Niet geheel toevallig bevatten de grootste datasets voor het trainen van neurale netwerken op handschriften ook cijfers in afbeeldingen van 28 bij 28 pixels. Elke pixel heeft een grijswaarde en wij mensen herkennen zonder problemen elke variatie van een cijfer. Ons neurale netwerk moet echter gaan rekenen en dat doet het allereerst door alle inputs, 28 maal 28, dus 784 grijswaarden, een waarde tussen 0 en 1 te geven. Let op dat een neuraal net dus niet binair is, maar analoog; een neuron is niet 1 of 0, maar een willekeurige waarde tussen 1 en 0.
/i/2001747195.png?f=imagenormal)
Die data wordt naar een tweede laag 'neuronen' gestuurd. Die tweede laag bestaat uit een veel kleiner aantal, zeg vijftien, neuronen en elk neuron krijgt input van elk neuron uit de eerste laag. Daarbij wordt de data, de grijswaarde, dus, een weging gegeven. De data van de tweede laag neuronen, ook weer waarden tussen 0 en 1, wordt weer naar de uitvoerneuronen gestuurd, opnieuw met een weging. Het neuron dat het dichtst bij waarde 1 komt, geeft aan welk cijfer het neurale net heeft 'gezien'. We moeten overigens opmerken dat een neuraal net meestal verschillende lagen heeft, maar voor de eenvoud houden we het op een enkele tussenlaag.
Die wegingen kun je je misschien makkelijker voorstellen als je je een neural net inbeeldt dat je wellicht dagelijks toepast: autorijden. Bij het autorijden kun je de wegingen, of hoeveel belang je hecht aan de verschillende inputs, laten variëren. Dat heeft steeds andere outputs, of rijsnelheden, tot gevolg. Met de juiste parameters of wegingen kom je veilig thuis, met de verkeerde krijg je een ongeluk. Zo kun je een neuraal netwerk ook fijn afstemmen om het succesvol te laten zijn of te laten falen.
De grote vraag is: hoe zorg je ervoor dat alle wegingen die nodig zijn om een cijfer te herkennen, aan je algoritme worden meegegeven? Om dat met de hand te programmeren is bijna onbegonnen werk. Een neuraal netwerk zoals we dat hier beschrijven, met één tussenlaag en 28 bij 28 pixels input, heeft al 784 maal 15 plus 15 maal 10 wegingen. Bovendien kan aan elk neuron nog een extra weging worden gegeven, dus dat zijn nog eens 15 plus 10 wegingen, voor een totaal van 11.935 variabelen die je moet bedenken en fijn afstemmen.
Voor een complexer neuraal net wordt het aantal variabelen vanzelfsprekend nog groter. Dus laat je het neurale netwerk zichzelf leren hoe het dingen moet herkennen, vandaar de term machinelearning, want de machine leert zichzelf. Dat is overigens niet de enige vorm van machinelearning, maar in deze context is dit wat we bedoelen.
Het trainen van het netwerk
Je hoort of leest vaak over het trainen van een neuraal netwerk. Nu zijn er verschillende soorten neurale netwerken en verschillende methodes om ze te trainen. We kijken eerst naar het trainen van het eenvoudige feed-forward-netwerk waar we het tot dusver over hebben gehad. Dat trainen we met een methode die supervised learning wordt genoemd. Simpel gezegd geef je het neurale netwerk een grote hoeveelheid voorbeelden, in dit geval dus cijfers, met een gewenst ofwel bekend resultaat. De eerder genoemde dataset voor cijferhandschriftherkenning bevat een trainingsset van zestigduizend plaatjes van cijfers met de gewenste uitkomst. Je begint met willekeurig gekozen parameters en kijkt welke uitvoer dat oplevert: waarschijnlijk gewoon ruis.
Elke keer dat het neurale netwerk een output geeft, vergelijk je die met het gewenste resultaat. Hoe meer dat afwijkt, hoe sterker variabelen moeten worden aangepast. Elke parameter kan een positieve of negatieve vector krijgen, die aangeeft hoeveel de parameter moet worden aangepast om de gegeven uitvoer met de gewenste uitvoer overeen te laten komen. Een veelgebruikte wiskundige methode daarvoor is optimalisatie. Bij een eenvoudige functie is dat makkelijk, maar met meer variabelen moet met afgeleide functies gewerkt worden, waarbij in kleine stapjes de minima worden opgezocht. Voor die minima geldt dat het neurale netwerk een uitkomst geeft die zo min mogelijk afwijkt van de bekende, gegeven waarde. Het trainen van een netwerk is dus feitelijk een optimalisatie of het zoeken van de lokale minima van een multivariabele functie. Met grote trainingssets kunnen deze parameters steeds beter afgesteld worden, zodat betrouwbare resultaten worden geleverd.
/i/2001747209.png?f=imagenormal) Optimalisatie van variabelen bij het trainen van neurale netwerken
Optimalisatie van variabelen bij het trainen van neurale netwerken
Het trainen van het neurale netwerk, in dit geval het aanpassen van de parameters om de verschillen tussen de cijfers die het neurale netwerk waarneemt, en de correcte cijfers te minimaliseren, wordt ook wel backpropagation genoemd. Het optimalisatiealgoritme moet immers van de gewenste toestand terugwerken naar alle lagen in het neurale netwerk, door steeds de wegingen en andere parameters aan te passen. Uiteraard moet zo'n aanpassing voor alle afbeeldingen in de trainingsset worden berekend en vervolgens moeten al die aanpassingen gemiddeld worden, omdat je neurale netwerk anders maar één uitkomst oplevert. En je mag ook weer niet te veel trainen, want dan krijgt je netwerk alleen de trainingsafbeeldingen goed en kan het niets met nieuwe data.
Soorten neurale netwerken en training
We hebben net een voorbeeld bekeken van een heel eenvoudig neuraal netwerk. Er zijn echter veel verschillende soorten neurale netwerken, waarvan twee typen vaak genoemd worden: deep neural nets en convoluted neural nets.
In het netwerk voor handschriftherkenning hadden we één tussenlaag tussen invoer en uitvoer. Je kunt je voorstellen dat die laag de lijntjes van de cijfers herkent, door randen te detecteren. In de praktijk zul je extra lagen nodig hebben, die aan de hand van de gedetecteerde randjes weer vormen herkennen en zo de juiste output kunnen aansturen. Als je neurale netwerk complex wordt, met meer dan twee tussenlagen, dan spreek je van deep neural networks. Elke laag heeft een specifieke taak, waardoor een vraagstuk in steeds eenvoudigere deelvragen kan worden opgesplitst. Denk aan gezichtsherkenning. Dat kan worden opgesplitst in het zoeken naar een oog, neus en mond, en dat kan weer onderverdeeld worden in zoeken naar een neusgat, een wenkbrauw of een lip. Zo kun je zeer complexe taken onderverdelen in eenvoudige taken, die door de eerder beschreven neurale netten kunnen worden uitgevoerd, met diepere lagen die een steeds hoger abstractieniveau mogelijk maken.
Daarmee gepaard gaat deep learning, het trainen van een deep neural network of dnn. Als zo'n netwerk net als een neuraal netwerk met één tussenlaag moet worden getraind met backpropagation en het zoeken naar lokale minima, zou dat erg veel tijd kosten. Daar komt bij dat niet alle lagen zich even snel laten trainen, zodat bijvoorbeeld de eerste lagen veel langzamer getraind worden dan de diepere lagen. Soms gebeurt het tegenovergestelde; de eerste lagen worden veel sneller getraind dan de diepere. Oorzaak is dat de leersnelheid van de eerste lagen het product is van de snelheid van de diepere lagen. Als die klein is, dooft de leersnelheid uit, en als die groot is, explodeert de leersnelheid. Die instabiliteit is dus een intrinsiek probleem van neurale netwerken met veel lagen.
Convolutional neural net
We hebben het tot dusver over volledig verbonden neurale netwerken gehad en voor kleine afbeeldingen werken die prima. Voor visuele taken, zoals objecten op foto's herkennen, heb je echter niet veel aan een input van 28 bij 28 pixels, zoals bij de handschriftherkenning. Een foto is immers veel groter en er staan vaak verschillende objecten op. Als je dat met dezelfde methode zou benaderen als het herkennen van cijfers, dus alle neuronen met elkaar verbonden, dan zou je een absurd complex neuraal netwerk krijgen. Voor een foto van 600 bij 400 pixels met laten we zeggen één tussenlaag van vijftig neuronen, zou je al twaalf miljoen variabelen voor de eerste laag moeten doorrekenen. Dan hebben we het nog niet over diepere lagen en de uitvoer gehad; dan zou het netwerk nog veel complexer worden.
De oplossing die hiervoor ontwikkeld is, wordt een convolutional neural network genoemd. De naam komt van bepaalde wiskundige bewerkingen die op de benodigde vergelijkingen worden uitgevoerd, die convoluties genoemd worden. Bij een convolutie worden twee functies gecombineerd tot een nieuwe functie.
/i/2001747211.png?f=imagenormal)
Eigenlijk is een convolutional neural net, kortweg cnn, een type deep neural network waarin niet alle neuronen met elkaar zijn verbonden. Dat reduceert de complexiteit en maakt het netwerk geschikter voor zijn taak. Over het algemeen heeft een pixel linksboven in een foto immers weinig te maken met een pixel rechtsonder. Bij cnn's worden afbeeldingen opgedeeld in kleine rasters van goed behapbare stukjes. Zo worden de eerder gebruikte vierkantjes van 28 bij 28 pixels verder opgedeeld in gebiedjes van 5 bij 5 pixels, die local receptive fields worden genoemd. Die 25 pixels staan in verbinding met slechts één neuron in de eerste verborgen laag neuronen en delen bovendien de parameters voor de weging van de input. Voor elk volgend neuron in de eerste verborgen laag schuift het local receptive field één pixel op en vormt zo een eerste detectielaag van 24 bij 24 neuronen.
Zo'n detectielaag zoekt specifiek naar één eigenschap in de afbeelding en vormt zo een featuremap, bijvoorbeeld om naar een horizontale lijn te zoeken. Om zinvolle herkenning mogelijk te maken moet je natuurlijk ook naar andere features kijken, dus heb je verscheidene featuremaps nodig in de eerste laag neuronen. Dan heb je nog steeds vele malen minder parameters nodig. Als we het voorbeeld van plaatjes van 28 bij 28 pixels aanhouden en een local receptive field van 5x5 pixels hanteren en geen drie, maar twintig featuremaps gebruiken, komen we op slechts 520 parameters. Dat is nogal een verschil met het eerdere voorbeeld van een volledig verbonden neuraal net van 28 bij 28 pixels, dat met veel minder neuronen in de verborgen laag al meer dan tienduizend parameters had. Zo kun je met cnn's dus grotere afbeeldingen verwerken zonder een explosie in het aantal parameters en wordt het resultaat bovendien beter.
De output van die feature maps wordt weer in de volgende laag verwerkt. In poolinglayers worden featuremaps vereenvoudigd, waarbij voor elke feature map een reeks poolingneuronen nodig is. Misschien zijn nog extra lagen in de 'hidden layer' nodig, maar het principe van het cnn blijft hetzelfde. Uiteraard staat de laatste laag neuronen weer in contact met de uitvoerneuronen. Voor de pooling- en andere lagen bestaan weer diverse methodes die elk voor specifieke doeleinden ontwikkeld zijn, en vaak is een mix van verschillende methodes nodig om de beste resultaten te halen. Vaak is zelfs flink wat geëxperimenteer nodig en dan nog is niet altijd duidelijk waarom de ene architectuur betere resultaten oplevert dan de andere.
Neurale netwerken in de praktijk
We hebben aan de hand van de voorbeelden van neurale netwerken net gezien dat neurale netwerken, en dan vooral cnn's, geschikt zijn voor beeldherkenning als handschriftherkenning, maar ook voor complexere afbeeldingen. Dat is echter niet de enige toepassing van neurale netwerken, want zoals we al op de eerste pagina zagen, worden ze in bijna alle moderne toepassingen gebruikt. Zo wordt een speciaal type neurale netwerken, recurrent neural networks genoemd, gebruikt voor stemherkenning, bijvoorbeeld in je Google Home of voor Siri. Een ander type wordt gebruikt voor het aanbevelen van producten als je gaat kopen. Met de kennis over neurale netwerken op zak is het iets makkelijker om te bedenken hoe dat werkt. De inputneuronen krijgen bepaalde producten te zien en zijn getraind met de aankopen van andere klanten. Zo kunnen ze voorspellen wat je nog meer zou willen bekijken of kopen op grond van wat anderen al kochten.
Zo werkt een dienst als Spotify of Netflix natuurlijk ook. De trainingsdata wordt gevormd door het kijk- en luistergedrag van alle andere abonnees en jij krijgt de output van de neurale netwerken te zien. En als je dit jaar een AMD-processor met Zen-cores gekocht hebt, heeft de branch prediction, het stuk in de cpu dat gokt welke operatie op een voorgaande bewerking volgt, een neuraal net aan boord om betere prestaties te bieden.
De foto's op je telefoon worden automatisch ingedeeld naar categorie. Vrienden en familie worden volautomatisch herkend en getagd. Er is een steeds grotere kans dat je telefoon een neuraal netwerk aan boord heeft voor dat soort taken. Zo heeft Apple een neural engine om Siri te verbeteren en om de telefoon met gezichtsherkenning te ontgrendelen. Huawei heeft in zijn Mate 10 een npu of neural processing unit ingebouwd, die onder meer vertalingen met Microsoft Translator moet versnellen en die veelgebruikte taken moet versnellen doordat de telefoon leert wat de gebruiker wil.
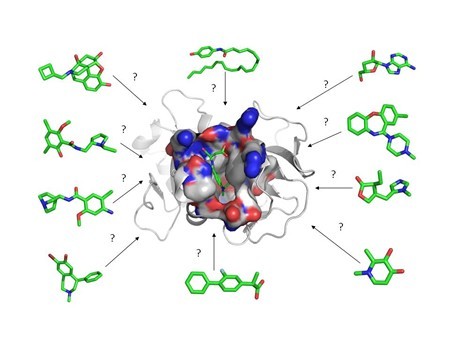
 Dat zijn lang niet alle toepassingen voor neurale netwerken. Ook in datasets die voor mensen lastig te doorgronden zijn, kunnen neurale netwerken inzichten bieden. Zoals bekend wordt big data steeds belangrijker, voor toepassingen van het analyseren van dna tot het speculeren op aandelenmarkten, bijvoorbeeld op basis van het verwerken van grote hoeveelheden aandelen die verhandeld worden. Maar ook in de gezondheidszorg kunnen neurale netwerken ingezet worden, om bijvoorbeeld een tumor in een mri te herkennen. Cnn's zouden dat met kleinere foutpercentages kunnen doen dan zelfs geoefende artsen. Ook het zoeken naar medicijnen kan door neurale netwerken worden gedaan; die kunnen dan op zoek naar moleculen die de gewenste eigenschappen hebben.
Dat zijn lang niet alle toepassingen voor neurale netwerken. Ook in datasets die voor mensen lastig te doorgronden zijn, kunnen neurale netwerken inzichten bieden. Zoals bekend wordt big data steeds belangrijker, voor toepassingen van het analyseren van dna tot het speculeren op aandelenmarkten, bijvoorbeeld op basis van het verwerken van grote hoeveelheden aandelen die verhandeld worden. Maar ook in de gezondheidszorg kunnen neurale netwerken ingezet worden, om bijvoorbeeld een tumor in een mri te herkennen. Cnn's zouden dat met kleinere foutpercentages kunnen doen dan zelfs geoefende artsen. Ook het zoeken naar medicijnen kan door neurale netwerken worden gedaan; die kunnen dan op zoek naar moleculen die de gewenste eigenschappen hebben.
/i/2001747221.jpeg?f=imagenormal) Een van de toepassingsgebieden waarop machinevision een grote en cruciale rol moet gaan spelen, is het verkeer, in zelfrijdende auto's. Daarbij zijn diverse factoren uiteraard van groot belang. Het systeem moet objecten, personen en situaties, goed classificeren, en dat moet zeer snel gebeuren. Bovendien is een complicerende factor dat het systeem geen statische plaatjes te zien krijgt die zorgvuldig zijn geprepareerd, maar met snel bewegende beelden in sterk wisselende omstandigheden moet omgaan. Een deel van die data kan dankzij 5g-verbindingen wellicht in krachtige clouds worden verwerkt, maar neurale netwerken of alternatieve technieken zullen ook in auto's moeten zitten.
Een van de toepassingsgebieden waarop machinevision een grote en cruciale rol moet gaan spelen, is het verkeer, in zelfrijdende auto's. Daarbij zijn diverse factoren uiteraard van groot belang. Het systeem moet objecten, personen en situaties, goed classificeren, en dat moet zeer snel gebeuren. Bovendien is een complicerende factor dat het systeem geen statische plaatjes te zien krijgt die zorgvuldig zijn geprepareerd, maar met snel bewegende beelden in sterk wisselende omstandigheden moet omgaan. Een deel van die data kan dankzij 5g-verbindingen wellicht in krachtige clouds worden verwerkt, maar neurale netwerken of alternatieve technieken zullen ook in auto's moeten zitten.
Hardware en software
Neurale netwerken en machine vision hebben in de afgelopen jaren enorm aan populariteit gewonnen. Toch zijn neurale netwerken niet nieuw. Al in de jaren zestig en zeventig van de vorige eeuw werden ze beschreven en ontwikkeld, maar computers waren destijds natuurlijk stukken minder krachtig. Tegenwoordig kunnen de complexe berekeningen, en dan vooral de enorme hoeveelheid herhalingen bij trainen, binnen een acceptabele tijd voltooid worden.
Het gebruik van een neuraal net hoeft niet eens zo rekenintensief te zijn, want eigenlijk is zowel het gebruik als het trainen gewoon een grote matrixberekening. Juist daar zijn computers goed in, zo goed dat neurale netwerken inmiddels ook op een Raspberry Pi of je telefoon kunnen draaien. Je telefoon is echter niet toereikend voor een complex neuraal netwerk en zelfs een krachtige desktop- of serverprocessor heeft moeite de vele berekeningen in een realistische tijd te volbrengen.
Gelukkig zijn vectorberekeningen, waaruit de matrixberekeningen voor het trainen en draaien van neurale netwerken grotendeels bestaan, de specialiteit van grafische processors. Die kunnen bovendien de werklast prima parallelliseren, waardoor complexe neurale netwerken vaak op videokaarten of acceleratorkaarten gedraaid worden.
/i/2001747227.png?f=imagenormal) Voor het trainen van een cnn zijn grote databases met gelabelde afbeeldingen nodig
Voor het trainen van een cnn zijn grote databases met gelabelde afbeeldingen nodig
Een van de grootste uitdagingen is echter het trainen van een neuraal netwerk. Bij de trainingmethodes die we tot dusver besproken hebben, zijn zeer grote datasets nodig die correct zijn gelabeld, zodat de parameters gecorrigeerd kunnen worden. Er zijn diverse publieke databases met onder meer afbeeldingen die zijn onderverdeeld in duizend klassen, maar in de echte wereld zijn complexere problemen, die nog geen grote trainingsset hebben. Dan werkt de methode die we tot dusver geïllustreerd hebben voor cnn's niet goed.
Sommige neurale netten maken dan ook gebruik van unsupervised learning, waarbij niet veel meer dan een paar algemene regels worden gedefinieerd en het algoritme uit de gepresenteerde data moet opmaken wat gewenst is en wat niet. Een ander voorbeeld is Googles DeepMind, die zich onlangs schaken leerde door tegen zichzelf te spelen en niet veel meer had meegekregen dan de basisregels. Een paar uur later wist DeepMind met deze vorm van reinforcement learning een van de beste schaakprogramma's te verslaan.
Tot dusver hebben we alleen neurale netwerken bekeken die speciaal worden ingericht voor een specifieke taak. De architectuur en algoritmes worden afgestemd op de taak en het neurale net wordt getraind met data, waarna het met echte samples aan de slag kan. Inmiddels worden ook neurale netwerken en zelfs chips ontwikkeld die blijven leren en dus met nieuwe situaties kunnen omgaan. Daarmee lijken ze nog sterker op de manier waarop hersenen werken. Zo kunnen recurrent neural networks, of rnn's ingezet worden om te leren en te blijven leren. Daarbij worden de parameters van de neuronen niet na het trainen vastgelegd, maar kunnen ze aangepast blijven worden, waarbij eerdere activaties van een neuron de latere activaties beïnvloeden. Ze veranderen dus in de loop van de tijd en kunnen meeveranderen met veranderende data.

Nog een stapje verder gaan neuromorfe chips. Ook hun architectuur is geënt op neuronen. Zo zijn er chips waarvan onderlinge verbindingen fysiek veranderen naarmate die verbindingen vaker geactiveerd worden. Onder meer Intel heeft dergelijke chips ontwikkeld, waarbij geheugencellen geëmuleerd worden. Dergelijke oxramcellen, zo genoemd omdat een hafniumoxideverbinding dikker of dunner gemaakt kan worden en zo van geleidbaarheid kan veranderen, fungeren als neuron-analogen en gebruiken net als biologische neuronen zeer weinig energie. Met zulke geheugencellen kunnen ook weer cnn's gemaakt worden.
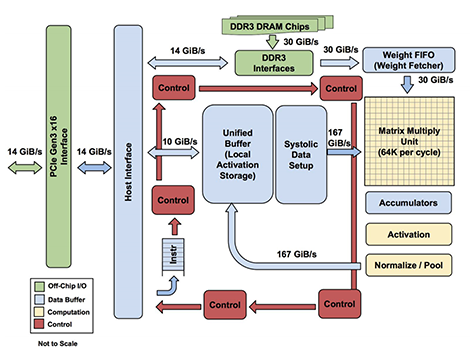
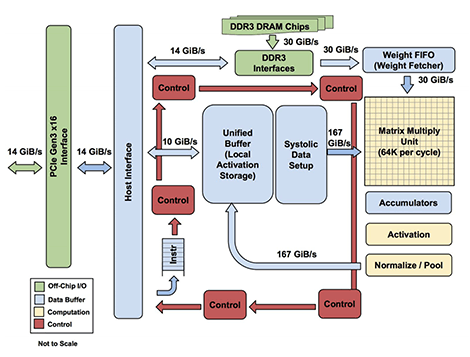 Andere fabrikanten kiezen voor een architectuur die is geoptimaliseerd voor het type berekeningen dat voor neurale netwerken wordt gebruikt. Zo zijn gpu's dankzij hun vele kleine processors al erg geschikt voor de vele parallelle berekeningen die nodig zijn om een neuraal netwerk te trainen, maar fabrikanten als Nvidia hebben dat voor bepaalde acceleratorkaarten verder geoptimaliseerd. De nieuwste generatie Tesla- en Titan-kaarten van dat bedrijf hebben zogeheten Tensor-cores aan boord die geoptimaliseerd zijn voor matrix-bewerkingen. De naam komt van een wiskundige term die relaties tussen variabelen aangeeft. Naast de Tensor-cores van Nvidia heeft ook Google speciale processors ontwikkeld die toegespitst zijn op dergelijke berekeningen.
Andere fabrikanten kiezen voor een architectuur die is geoptimaliseerd voor het type berekeningen dat voor neurale netwerken wordt gebruikt. Zo zijn gpu's dankzij hun vele kleine processors al erg geschikt voor de vele parallelle berekeningen die nodig zijn om een neuraal netwerk te trainen, maar fabrikanten als Nvidia hebben dat voor bepaalde acceleratorkaarten verder geoptimaliseerd. De nieuwste generatie Tesla- en Titan-kaarten van dat bedrijf hebben zogeheten Tensor-cores aan boord die geoptimaliseerd zijn voor matrix-bewerkingen. De naam komt van een wiskundige term die relaties tussen variabelen aangeeft. Naast de Tensor-cores van Nvidia heeft ook Google speciale processors ontwikkeld die toegespitst zijn op dergelijke berekeningen.
Tot slot
De grootste spelers op het vlak van neurale netwerken, zoals Google met Tensorflow, de Tensor Processing Unit en DeepMind, of IBM met zijn Watson-ai en Microsoft en Facebook, zijn eigenlijk de bekende grote technologiebedrijven. Iedereen is druk met ai en neurale netwerken bezig en 'de sector' denkt dat dit in de toekomst een nog grotere rol gaat spelen.
Vooralsnog lijken neurale netwerken en afgeleiden daarvan als neuromorfe chips een in ieder geval veelbelovende techniek, die kunstmatige intelligentie een grote sprong voorwaarts heeft laten maken. Dat wil niet zeggen dat we over enkele jaren ook een echte kunstmatige intelligentie, een zelfbewust systeem, kunnen realiseren met deze techniek. Neurale netten, machineleren en machinevision laten sterke staaltjes slimme techniek zien, maar of dat zich ooit laat vertalen in een omnipotent Skynet, is nog maar de vraag.


/i/2001747227.png?f=imagegallery)

:strip_icc():strip_exif()/i/2005085684.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2005044680.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004968122.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2004042342.jpeg?f=fpa_thumb)
/i/2001567875.png?f=fpa)
/i/1348829391.png?f=fpa)
/i/2001005299.png?f=fpa)
:strip_exif()/i/2001734105.jpeg?f=fpa)
/i/2000593550.png?f=fpa)
/i/1332429553.png?f=fpa)
/i/1349425400.png?f=fpa)
/i/2000632587.png?f=fpa)
:strip_exif()/i/1398151713.jpeg?f=fpa)
/i/2000589235.png?f=fpa)
/i/2001673275.png?f=fpa)
:strip_icc():strip_exif()/u/221341/crop59db8f647e0a8_cropped.jpeg?f=community)
:strip_exif()/u/26289/ahxp68H.gif?f=community)
:strip_icc():strip_exif()/u/379747/crop63c134ecd1988_cropped.jpg?f=community)
/u/441020/crop577ad2276cade.png?f=community)
:strip_icc():strip_exif()/u/604726/crop5f3b635b14ae7_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/227038/samsungapple1.jpg?f=community)
:strip_icc():strip_exif()/u/614228/crop6023bf71e398d_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
:strip_exif()/u/464616/wvo-porsch-gif.gif?f=community)
:strip_exif()/u/505097/crop569fc8a07efd1.gif?f=community)
/u/27299/hoofd.png?f=community)
/u/142848/crop631b73f49acc6_cropped.png?f=community)
/u/12528/crop69c02af1d5945_cropped.png?f=community)
/u/401155/crop5835f8151697d_cropped.png?f=community)
:strip_icc():strip_exif()/u/834105/crop5c0e89629dc7e_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/72765/home60.jpg?f=community)
/u/247151/moppersmurf-60px.png?f=community)