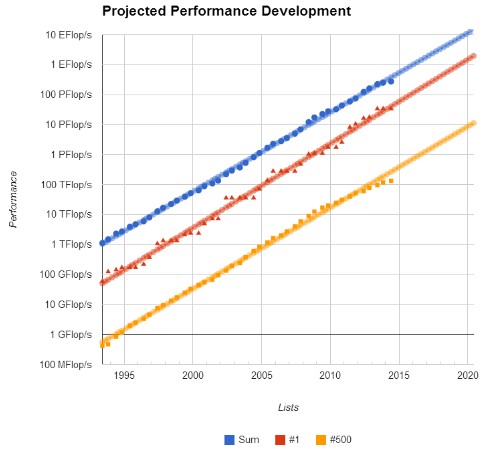
De groei in prestaties van de 500 snelste computers ter wereld is aan het afnemen. Dat blijkt uit de top 500-lijst van dit halve jaar. De Chinese supercomputer Tianhe-2 is met zijn 33,9 petaflops voor de derde maal op rij de snelste supercomputer ter wereld.
Volgens de organisatie achter de lijst, is de totale gecombineerde groei van de pieksnelheden voor het eerst sinds de introductie ervan in 1993 zo laag. De organisatie noemt de krachtige computers bovenaan de lijst als de belangrijkste reden voor het afnemen van de totale groei. Het neerzetten van deze grote supercomputers zou de groei aan de bovenkant van de lijst vooral doen afnemen. Aan de onderkant van de lijst, waar over het algemeen supercomputers van klein- en middelgroot formaat staan, vond juist wel een grotere groei plaats.
Vergeleken met de vorige lijst, die in november 2013 uitkwam, is binnen de top 10 alleen de laatste plaats gewijzigd. De Duitse SuperMUC verloor met zijn pieksnelheid van 2,9 petaflops de tiende plaats aan de Amerikaanse Cray XC30 met pieksnelheden van 3,1 petaflops. De totale gecombineerde snelheid van de lijst steeg in vergelijking met een half jaar geleden van 250 naar 274 petaflops. Snelheden van de supercomputers voor de top 500 worden gemeten via de Linpack-benchmark.
Intel blijft ook nog steeds hofleverancier van processors voor de computers van de top 500; 85,4 procent van alle computers beschikt over een processor van de Amerikaanse fabrikant. Het aandeel aan AMD-processors nam af: dat zakte van negen procent naar zes procent. Het aantal computers op de lijst dat beschikt over een processor van IBM bleef met acht procent gelijk.
IBM is wel terrein aan het winnen op de lijst aangezien 176 systemen op de lijst afkomstig zijn van de fabrikant. Het aandeel in computers van HP daalde in vergelijking met zes maanden terug van 196 systemen naar 182 maar bleef desondanks wel hoofdleverancier.


/i/1371467923.png?f=fpa)
/i/1226912359.png?f=fpa)
/i/1289644242.png?f=fpa)
/i/1275218511.png?f=fpa)
:strip_exif()/i/1260173599.gif?f=fpa)
/i/1340023128.png?f=fpa)
/u/26227/amdklein.JPG?f=community)
/u/98401/crop57b85f51b147a.png?f=community)
:strip_icc():strip_exif()/u/451182/crop60bfe36fd5954_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/174878/SCKnightMicro.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
/u/35505/flx_70x70.png?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
/u/242701/crop5e107244d1e57_cropped.png?f=community)
:strip_icc():strip_exif()/u/449812/qrchickie.jpg?f=community)
:strip_icc():strip_exif()/u/259705/AC.jpg?f=community)
:strip_icc():strip_exif()/u/446655/crop56d1a1e8e1f57_cropped.jpeg?f=community)
:strip_exif()/u/69029/crop5cac7b8ae8078.gif?f=community)