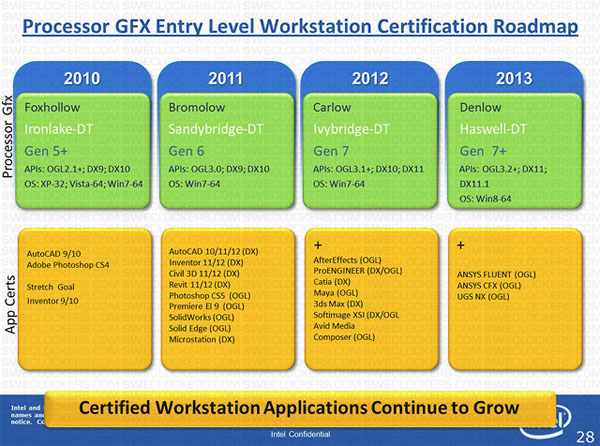
Intels Haswell-cpu's, die in 2013 moeten verschijnen, krijgen ondersteuning voor het nog onaangekondigde Microsoft DirectX 11.1. Daarnaast moet de nieuwe grafische chip overweg kunnen met versie 3.2 van de OpenGL-api.
Dat blijkt uit een uitgelekte roadmap, die is gericht op de ingebouwde grafische chips van Intels processors en de applicaties waarvoor ze gecertificeerd zijn. Van Intels Ivy Bridge-cpu's, die in 2012 uitkomt, was al bekend dat de igp's ondersteuning voor DirectX 11 krijgen. De huidige Sandy Bridge-chips komen niet verder dan versie 10.1 van DirectX.
Intels Hasswell-processors zouden nog verder gaan dan Ivy Bridge door ook versie 11.1 van DirectX te ondersteunen. Dit zou ook de eerste igp zijn waarmee het bedrijf compleet op Windows 8 mikt. Het is daarom aannemelijk dat DirectX 11.1 de versie is die samen met Windows 8 wordt geleverd.
Mocht Windows 8 met DirectX 11.1 worden geleverd, dan zou dat de frequentie waarmee Microsoft nieuwe DirectX-versies aflevert verlagen. Windows Vista en Windows 7 werden met respectievelijk DirectX 10 en 11 geleverd. Tussen Windows 7 en 8 zou dan enkel een point release van DirectX zitten. Of de verschillen tussen DirectX 11 en 11.1 zo klein zijn als de versienummers suggereren, is nog niet bekend.

:strip_icc():strip_exif()/i/1347734972.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/1316954761.jpeg?f=fpa_thumb)
/i/1347385226.png?f=fpa)
/i/1242207182.png?f=fpa)
/i/1340793687.png?f=fpa)
:strip_exif()/i/1035733687.gif?f=fpa)
/i/1293792521.png?f=fpa)
/i/1294416060.png?f=fpa)
/i/1315951086.png?f=fpa)
/i/1306834994.png?f=fpa)
/i/1273064433.png?f=fpa)
/i/1212928088.png?f=fpa)
/u/27299/hoofd.png?f=community)
:strip_exif()/u/142654/crop5c640fd9c01a7_cropped.gif?f=community)
:strip_icc():strip_exif()/u/58139/uglycat.jpg?f=community)
/u/42648/crop635863345e4c0.png?f=community)
:strip_icc():strip_exif()/u/297796/Cryptum60.jpg?f=community)
:strip_icc():strip_exif()/u/292832/Aladdin-surprised2.jpg?f=community)
/u/401159/crop55ef036501bc8.png?f=community)
/u/9258/killbill.png?f=community)
:strip_icc():strip_exif()/u/299339/anonpict.jpg?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/122141/ic.tweakimg.net2.jpg?f=community)