Het wordt mogelijk om de toon van ChatGPT verder aan te passen. OpenAI heeft daarvoor een update uitgerold. Gebruikers kunnen zo meerdere 'karaktertrekken' van de chatbot finetunen, zoals hoe warm of enthousiast deze is.
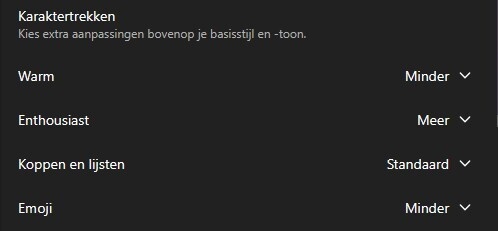
OpenAI stelde de update op vrijdagavond beschikbaar voor ChatGPT-gebruikers, meldt het bedrijf op sociale media. De nieuwe opties zijn te vinden in de instellingen van ChatGPT, onder 'personalisatie'. Gebruikers krijgen vier verschillende karaktertrekken om aan te passen, ieder met drie niveaus: 'minder', 'standaard' of 'meer'.
Met 'warm' kunnen gebruikers instellen of de chatbot vriendelijk of juist zakelijk is, met 'enthousiast' kan ChatGPT energieker of juist kalmer communiceren, en met 'koppen en lijsten' zal ChatGPT meer of juist minder tussenkopjes en lijstjes met bulletpoints gebruiken. Tot slot is er ook een optie die het emojigebruik van de AI-dienst regelt.
Naast die opties heeft de chatbot al mogelijkheden om de 'algemene' persoonlijkheid van de chatbot in te stellen. Dat is mogelijk sinds de release van GPT-5.1. Ook die optie is te vinden onder de personalisatieopties en biedt keuzes als 'professioneel', 'oprecht', 'nerdy' en 'cynisch'.

/i/2007970612.webp?f=fpa)
/i/1348829391.png?f=fpa)
:strip_exif()/i/2007853496.jpeg?f=fpa)
/i/2006829312.png?f=fpa)
:strip_exif()/i/2004698112.jpeg?f=fpa)
:strip_exif()/i/2007654988.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2007919110.webp?f=fpa)
:strip_exif()/u/4143/crop673c629560e43_cropped.gif?f=community)
:strip_icc():strip_exif()/u/439769/crop5a510243ea2e3_cropped.jpeg?f=community)
/u/217510/crop660db19c1cf7b_cropped.png?f=community)
:strip_icc():strip_exif()/u/227665/th_petey_rawrs.jpg?f=community)
/u/151149/crop5fde11d32f663_cropped.png?f=community)
/u/424053/crop5b545bb664b6d.png?f=community)
:strip_exif()/u/25859/test2.gif?f=community)
:strip_icc():strip_exif()/u/99162/crop5fbeb65712858_cropped.jpeg?f=community)
/u/176086/crop5f0823fa5e8d6_cropped.png?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
/u/436258/crop5f9a9829255a1_cropped.png?f=community)
/u/1957000/crop696cfa35c73d9_cropped.png?f=community)
/u/12436/p1_normal.png?f=community)
:strip_icc():strip_exif()/u/6694/crop62e546fe108c4.jpg?f=community)