Ieder jaar beginnen er in de lage landen tientallen techstart-ups, die grootse dromen hebben, maar technische hobbels moeten overwinnen om die waar te maken. In dit artikel bespreken we waar DuckDB Labs tegenaan liep bij het ontwikkelen van zijn databasemanagementsysteem.
Hannes Mühleisen en Mark Raasveldt werken al zo’n tien jaar bij CWI-onderzoeksgroep Database Architectures aan allerlei databasemanagementsystemen. Zo hebben ze in de loop der jaren een aardig beeld gekregen van wat er momenteel beschikbaar is. Ze ontdekten een gat in de markt voor datamanagementsoftware, specifiek voor datascience. Een database draait normaliter namelijk op een los systeem, terwijl de gebruiker op een andere computer met die database loopt te praten; een client-server connection. Voor de meeste usecases werkt zoiets prima, maar voor datasciencetoepassingen werkt het vreselijk. Volgens de CWI-onderzoekers zit je dan heel lang te wachten op de transfer van de data tussen de database en je applicatie.
Voor datascience moeten immense hoeveelheden data in korte tijd worden geanalyseerd. Hiervoor bestond nog geen goede software, ontdekten Mühleisen en Raasveldt. Er was data-analysesoftware nodig die kon draaien op dezelfde computer als die van de gebruiker. De twee vonden het gebrek daaraan een dusdanig gemis dat ze besloten om voor het eerst in hun carrière zelf van begin tot eind een datamanagementsysteem op te zetten.
- Bedrijf: DuckDB Labs
- Opgericht: 2021, Amsterdam
- Initiatiefnemers: Hannes Mühleisen en Mark Raasveldt
- Product: databasemanagementsysteem voor het sneller en efficiënter maken van data-analyses
- Productiefase: de DuckDB-software verscheen in 2018 op GitHub en wordt regelmatig geüpdatet
- Prijs: software is gratis, gepersonaliseerde begeleiding kost wel een afgepast bedrag
:strip_exif()/i/2004900832.jpeg?f=imagenormal)
Mühleisen en Raasveldt willen er met DuckDB voor zorgen dat de database een integraal onderdeel kan worden van het programma waar ook de datascience plaatsvindt. Daardoor moet er een snelle overdracht komen van data tussen de gebruiker en de database. Het gaat hier specifiek om analytische vraagstukken, verduidelijkt Mühleisen. Als het voor een programma nodig is om een hele tabel met miljarden regeltjes door te gaan, dan kunnen softwareontwikkelaars DuckDB gebruiken.
Softwaremakers gebruiken systemen als DuckDB diep in hun datacenters als onderdeel om hun product te bouwen. DuckDB is dus geen opzichzelfstaand product dat je als gebruiker ziet, of waar je directe interactie mee hebt. Raasveldt: "Wij zijn de backend van de backend. Wij werken met de daadwerkelijke bits zoals ze op de computer op de harde schijf staan, of in het geheugen zitten. Daar kun je vervolgens als softwareontwikkelaar allemaal dingen op bouwen."
:strip_exif()/i/2004900834.jpeg?f=imagegallery)
Datavisualisatieprogramma’s als Tableau kunnen DuckDB bijvoorbeeld gebruiken om uit een reusachtige dataset van miljoenen datapunten met aankoopinformatie trends te ontdekken en conclusies te trekken. Bijvoorbeeld dat er in de maand juli de meeste rode jurken verkocht worden of dat mensen vaak bier en chips samen kopen. "Interessante punten vinden dus", vat Raasveldt samen. "Superabstract, maar je kunt er veel mee. DuckDB is dus een fundamentele bouwsteen van die andere programma’s."
Volgens de twee onderzoekers was dergelijke data-analyse al eerder mogelijk, maar maakt DuckDB datascienceanalyses simpeler en, vooral, veel sneller. "Data die voorheen twaalf uur duurde om te analyseren, zou met deze software slechts twee minuten kunnen duren", beweert Mühleisen. Raasveldt vult aan: "Je draait dus niet meer ’s nachts een programmaatje waar ’s ochtends een grafiekje uit komt rollen, maar je hebt meteen een grafiekje en zodra er nieuwe data komt, wordt dat meteen geüpdatet."
In steen gebeiteld
Hoewel DuckDB from scratch is gebouwd, stond veel vanaf het begin al vast. Aangezien het een datamanagementsysteem betreft, zijn veel specificaties namelijk al zo’n 50 jaar in steen gebeiteld. Raasveldt: "Over het algemeen weet je al heel goed hoe je systeem moet functioneren, je hoeft niet eerst met klanten te praten om een idee te krijgen wat ze willen zien. Er zijn ISO-standaarden op de interface, dus je weet eigenlijk al hoe het eruit gaat zien."
De standaarddatamanipulatietaal voor databasesystemen is bijvoorbeeld al vrijwel sinds het begin SQL. "Die taal wordt ook gesproken door elk ander systeem. Het is een krachtige taal die tegelijk simpel is. Iedereen die met data werkt, kent die taal. Als je vanuit dat oogpunt begint heb je al een groot voordeel, want iedereen kan er meteen mee werken." Ook C++ gebruiken als programmeertaal is vanaf het begin eigenlijk al een gegeven.
In vergelijking met de ontwikkeling van andere techproducten is het begin van de ontwikkeling van een databasesysteem relatief eenvoudig. In de voorbereidende fase ben je namelijk weinig tijd kwijt aan specificaties vaststellen en validatie zoeken vanuit klanten. Raasveldt noemt het echter wel een double-edged sword. Volgens hem zijn de verwachtingen van een databasesysteem wat stabiliteit betreft veel hoger dan bij andere applicaties. "Als het om data gaat, zijn mensen snel boos als jij hun data verliest of vervormt en verkeerde resultaten geeft. Als eindgebruiker kom je dan in nare situaties terecht waar je verkeerde conclusies gaat trekken uit data die 'Het opbouwen van een databasemanagementsysteem vereist jaren puzzelwerk'
compleet verkeerde dingen laat zien door een bug in de database. Stel, ik maak een app op de iPhone en af en toe crasht die. Dan start je hem gewoon weer opnieuw op. Het is niet het eind van de wereld. Met een databasesysteem is dat dus wel zo."
Daarnaast hebben gebruikers al vanaf het begin hoge verwachtingen van wat een databasesysteem allemaal moet kunnen, stelt Mühleisen. "Je moet in je eerste versie al veel hebben van wat andere databasesystemen in die 50 jaar in elkaar geknutseld hebben, want al die functionaliteiten zijn gebruikers al gewend. Je moet er dus meteen al helemaal voor gaan. Het kostte ons veel tijd om dat van nul op te bouwen en die drempel voor wat een databasesysteem minimaal moet kunnen, over te gaan."
Testen, testen en nog eens testen
Het opbouwen van een databasemanagementsysteem vereist jaren puzzelwerk, aldus Mühleisen. "Je hebt een idee van wat je wilt dat het programma doet, maar het kost veel werk om het conceptueel door te ontwikkelen. Ik wil dat het dit doet, maar wat betekent dat voor die andere componenten? Hoe moet het precies werken? Wat zijn de algoritmen? Wat zijn de datastructuren? Dat is veel conceptueel werk, met een whiteboard. Daarnaast is een groot deel natuurlijk implementatie, dus programmeren, wat ontzettend veel tijd vreet."
Aangezien de systemen heel precies moeten zijn, moet elk stapje en elke kleine toevoeging uitvoerig getest worden op mogelijke bugs. "We hebben een testing framework gebruikt, dat is overgenomen van SQLite, waarin je die bugtests heel makkelijk kunt schrijven. We draaien veel continuous integration tests, dus elke verandering die we maken aan het databasesysteem, draait honderden miljoenen SQL-queries, die kijken of alles klopt in verschillende scenario’s", vertelt Raasveldt. Als er vervolgens een bug wordt gedetecteerd, moet er code geschreven worden om de bug te fixen en specifieke tests worden ontwikkeld die kunnen aantonen dat de fix daadwerkelijk de bug heeft verholpen. Er zijn uiteindelijk honderdduizenden tests gebruikt, waarvan er meer dan tienduizend zelfgeschreven zijn. DuckDB bevat meer regels tests dan daadwerkelijke code.
Om bugs te vinden is ook gebruikgemaakt van speciale bugsopsporingsprogramma’s. "Er is een programma genaamd SQLancer, dat SQL Statements genereert om bugs te kunnen vinden in het systeem. Zo zijn er aardig wat bugs gevonden. Het programma wordt ook in nagenoeg elk databasesysteem gebruikt. Google heeft ook een OSS-Fuzz, eveneens een programma dat probeert je systeem kapot te maken. Dat genereert willekeurige inputs met een bepaalde richtlijn en probeert op verschillende manieren bugs te ontdekken."
Vectorized-processing
Om ervoor te zorgen dat het databasesysteem alle datapunten op een enkele computer kan analyseren, is gebruikgemaakt van een engine met een aangepaste versie van relatief nieuwe technologie: vectorized processing. Hoewel dit niet ontworpen is door Mühleisen en Raasveldt, is het 15 jaar geleden wel gemaakt door andere CWI-onderzoekers in dezelfde onderzoeksgroep. "Een traditioneel systeem, zoals SQLite of Postgres, verwerkt datasets op een row-by-rowbasis", legt Raasveldt uit. "Dus hij kijkt eerst naar de eerste rij in de dataset, daar doet hij alle operaties op, en dan pas kijkt hij naar de volgende rij. Dan pakt hij die rij, gaat hij weer door, et cetera. Dat werkt goed met gelimiteerde geheugensettings. Dat is ook waar die systemen voor zijn ontworpen, want ze zijn al 25 tot 30 jaar oud. In die tijd hadden computers niet veel geheugen."
Nu systemen veel geheugen bevatten, kost het dataverwerken via dat row-by-rowsysteem een hoop tijd door de grote hoeveelheid context switches die uitgevoerd moeten worden. Daarom hebben CWI-onderzoekers het vectorized-processingsysteem ontworpen. "In plaats van dat je één rij tegelijk verwerkt, verwerk je er duizenden. Omdat je op die manier veel minder context switches hebt, heb je een systeem dat vele malen sneller door de dataset heengaat. Het kan alleen al daardoor honderd keer sneller. Het kost alleen een beetje meer geheugen."
Hoewel vectorized processing dus al 15 jaar bestaat, heeft DuckDB wel aan het systeem gesleuteld. Mühleisen: "We hebben bijvoorbeeld compressie toegevoegd. Soms heb je namelijk een vector van data, zeg duizend verschillende waarden van datakolommen. Stel, ze zijn allemaal hetzelfde. Het is dan natuurlijk zonde van je tijd als je zegt: ik ga toch duizend keer mijn berekeningen doen op die nummers als die allemaal hetzelfde zijn. Dan weet je dat de resultaten ook allemaal hetzelfde zijn. Dus wat wij hebben veranderd aan vectorized processing, is dat wij kunnen omgaan met compressie."
Data die hetzelfde is, kan dus door die compressietechniek voorspeld worden en hoeft niet telkens opnieuw berekend te worden. Ook is het mogelijk gemaakt om minder bits te gebruiken voor data als dat nodig is, terwijl voorheen een vaste hoeveelheid bits werd gebruikt voor elk stukje data. "Dus we hebben een goede toevoeging gedaan aan dat model. Je moet het zo zien: vectorized processing is een paradigma. Daar zijn verschillende implementaties van en de onze is op dit moment de nieuwste en beste implementatie van dit paradigma."
/i/2004907380.png?f=imagenormal)
Trade-off
Een andere techniek om het data-analyseproces te versnellen en te versimpelen was het efficiënt in SQL kunnen berekenen van de subqueries. Dat bleek een van de grootste uitdagingen te zijn in het ontwikkelproces, want dat was slechts één iemand eerder gelukt: Thomas Neumann, een Duitse hoogleraar. Die had gelukkig een paper geschreven over hoe het hem was gelukt, dus aan Raasveldt de taak om die lastige stof tot zich te nemen en het werkend te krijgen in zijn databasemanagementsysteem. "Ik zat echt te twijfelen of hem dat ooit zou lukken, want ik heb die paper bekeken en dacht: dit is te veel voor mij, dit kan ik echt niet aan", blikt Mühleisen terug. "Mark zat wekenlang in zijn kantoortje. Ik hoorde helemaal niks van hem, tot hij op een gegeven moment naar me toekwam en riep: 'Ik heb het! Ik heb het! Het werkt!' Ik ben nog steeds onder de indruk dat dat gelukt is. Ik zie veel dingen zitten, maar dit zag ik echt níét zitten."
Mühleisen en Raasveldt concluderen dat het ontwikkelproces eigenlijk heel soepel verliep. Toch zijn ze tijdens het ontwikkelproces ook op problemen gestuit en moesten ze soms terugkomen op eerdere beslissingen: "Toen we begonnen, hadden we bijvoorbeeld nog niet nagedacht over hoe we dingen met meerdere cores zouden kunnen doen, zoals parallellisme", aldus Raasveldt. "De eerste versie had daar geen ondersteuning voor, die was compleet singlethreaded. Na een jaar beseften we dat multithreading cruciaal was, dus toen zijn we toch teruggegaan en hebben we dat moeten toevoegen. Toen hebben we best veel code moeten herschrijven."'Met de domme oplossing werd veel tijd bespaard'
Toch zegt hij geen spijt te hebben van die initiële keuze. "Het is een beetje een trade-off als je programmeert. Als je al begint met een ingewikkelde oplossing, heb je aan de ene kant dan al een ingewikkeld probleem opgelost, maar aan de andere kant is het veel lastiger om die initiële oplossing te maken. Het is soms makkelijker om te zeggen: ik begin met een heel domme oplossing en dan verbeter ik die naarmate ik meer dingen wil toevoegen." Soms, stelt Raasveldt, bleek de domme oplossing achteraf eigenlijk een prima oplossing te zijn, waar helemaal niks aan veranderd hoefde te worden. Daarmee werd veel tijd bespaard die anders in een onnodig ingewikkelde oplossing gestoken moest worden. DuckDB heeft er tijdens het ontwikkelproces dus bewust voor gekozen om een simpele oplossing te gebruiken die op dat moment werkte. Als ze later iets tegenkwamen wat niet werkte, veranderden ze de oplossing.
Opensource-overwegingen
Er is voor gekozen om DuckDB volledig open source te maken. Dat heeft voordelen, maar er kleven ook wat nadelen aan, vertelt Mühleisen. "Aan de ene kant is het heel mooi, want we hebben hierdoor mensen leren kennen die zich aan de andere kant van de wereld bevinden en goede ideeën hebben en er veel werk in stoppen om DuckDB beter te maken. Aan de andere kant heb je, omdat het open source is, veel gebruikers, en dan vinden ze ook meer bugs. Als drie zakenlui je systeem gebruiken, doen ze nooit zoveel gekke dingen als duizenden opensourcegebruikers bij elkaar."
Dat heeft als gevolg dat Raasveldt en Mühleisen veel tijd kwijt zijn met communiceren met gebruikers die problemen melden. "Ik zit elke dag op GitHub vragen te beantwoorden. Het is het eerste wat je doet als je opstaat, en het laatste als je naar bed gaat." Door de grote hoeveelheid meldingen die de twee op dagelijkse basis ontvangen, kan niet elk probleem gefikst worden. "We moeten telkens goed de afweging maken in hoeverre de gemelde problemen echt onze fout zijn, en of ze kritiek zijn, of misschien ook wel over twee jaar opgelost kunnen worden." De problemen zijn soms heel specifiek, vertelt Mühleisen, waardoor de verwachting van gebruikers dat elk probleem wordt opgelost, onrealistisch is.
CWI-spin-off
Mühleisen en Raasveldt plaatsten de software in 2018 gratis op GitHub en hebben sindsdien al meer dan een miljoen downloads gehad. Volgens de twee is ze dat voornamelijk gelukt door al vanaf het beginstadium contacten te leggen met datascientists en ze enthousiast te maken voor het idee. Ook hadden ze al door hun eerdere CWI-werkzaamheden goede contacten met 'techinfluencers', zoals Mühleisen invloedrijke figuren in de datascienceindustrie als Hadley Wickham en Wes McKinney noemt. Sindsdien is het balletje via mond-tot-mondreclame gaan rollen.
/i/2004900852.png?f=imagegallery) Ondanks de populariteit was DuckDB lange tijd geen commerciële onderneming. Raasveldt: "Dat we besloten het probleem van datascience op te lossen was meer vanaf de academische kant dan dat we geld wilden verdienen. Dat gebeurde gewoon toen mensen tegen ons zeiden: 'dit is geweldig, we willen jullie geld geven'. Op een gegeven moment zeg je dan: 'oké, kom maar door'." Daarom besloten ze vorig jaar over te gaan van opensourceproject vanuit een onderzoeksgroep naar een commercieel spin-offbedrijf van het CWI.
Ondanks de populariteit was DuckDB lange tijd geen commerciële onderneming. Raasveldt: "Dat we besloten het probleem van datascience op te lossen was meer vanaf de academische kant dan dat we geld wilden verdienen. Dat gebeurde gewoon toen mensen tegen ons zeiden: 'dit is geweldig, we willen jullie geld geven'. Op een gegeven moment zeg je dan: 'oké, kom maar door'." Daarom besloten ze vorig jaar over te gaan van opensourceproject vanuit een onderzoeksgroep naar een commercieel spin-offbedrijf van het CWI.
DuckDB is nog steeds open source, maar klanten die betalen – louter Amerikaanse deeptechbedrijven – krijgen persoonlijke begeleiding vanuit het bedrijf en hebben zeggenschap om specifieke toevoegingen in DuckDB te laten inbouwen. Volgens hen zit er weinig verschil tussen het zijn van een spin-offbedrijf en het zijn van een opzichzelfstaand bedrijf. Ze krijgen van het CWI kantoorplekken om te gebruiken en het instituut heeft een klein aandeel in het bedrijf, maar wat beslissingen die ze maken betreft, garanderen ze onafhankelijk te zijn van de rest van het CWI.
'SQLite voor analytics'
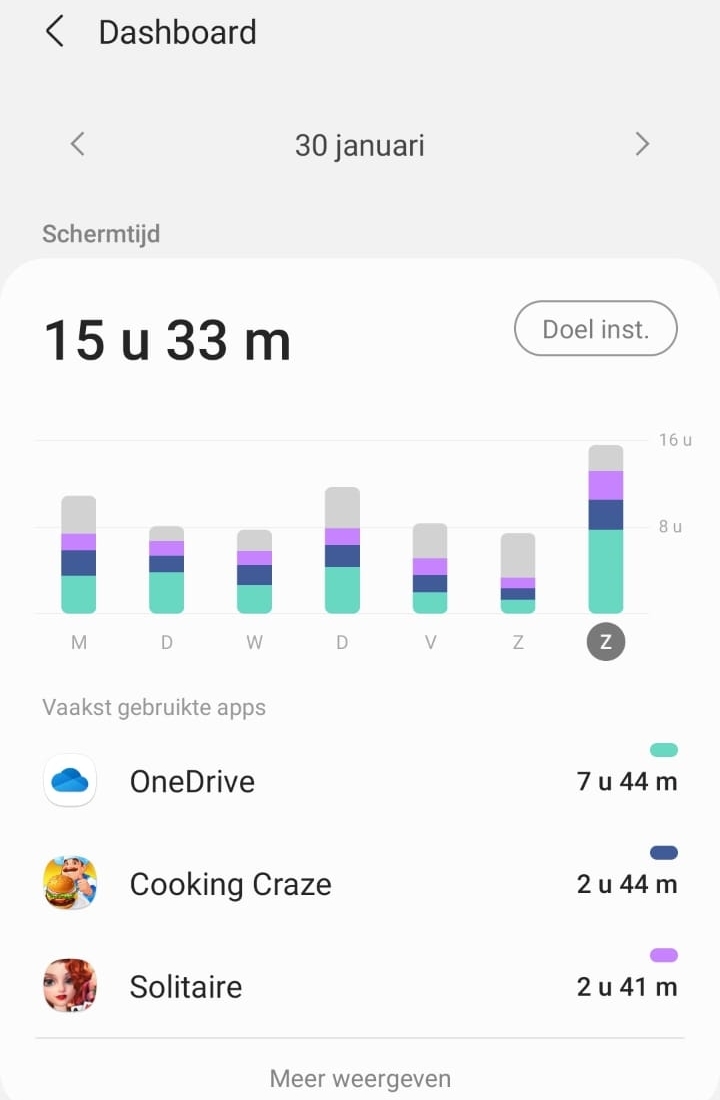
Volgens de ontwikkelaars is DuckDB het eerste en vooralsnog enige analytische-datamanagementsysteem dat geïntegreerd kan worden in een programma. Voorheen moesten ontwikkelaars intern software schrijven om grote hoeveelheden data in programma’s te kunnen analyseren, stellen de CWI-onderzoekers. Bepaalde telefoonapplicaties kunnen bijvoorbeeld bijhouden wat de schermtijd is van gebruikers verdeeld over de verschillende apps, die met allerlei statistieken en grafieken gepresenteerd wordt aan de gebruiker. Een ander voorbeeld is games, die vaak een menu met statistieken bevatten met prestaties van spelers.
Dergelijke data wordt volgens Mühleisen en Raasveldt momenteel voornamelijk gegenereerd met een intern ontwikkeld datamanagementsysteem. Ze hopen dat ontwikkelaars in de toekomst DuckDB zullen integreren in plaats van dat ze zelf software gaan schrijven. Zo hoopt het bedrijf uiteindelijk nagenoeg onmisbaar te worden, net als het grote voorbeeld SQLite. Dat is namelijk de meestgebruikte database in de wereld en wordt door iedereen met een pc of smartphone gebruikt, terwijl de gebruikers het niet doorhebben. "Op een gemiddelde computer draait 50 tot 100 keer SQLite. Het zit in elk programma, in je browser, e-mailclient, base-OS: het draait overal. Ze hebben echt miljarden deployments", aldus Mühleisen.
SQLite is echter bedoeld voor het beheren van data, maar niet voor het maken van analyses van data. Daarom gebruikt DuckDB ook de ambitieuze tagline 'SQLite voor analystics'. "We willen uiteindelijk overal zitten waar analyses uitgevoerd worden. De droom is dat iedereen DuckDB uiteindelijk gebruikt, zonder het te weten."

/i/2005502398.png?f=fpa)
:strip_exif()/i/2005446296.jpeg?f=fpa)
/i/2005404740.png?f=fpa)
/i/2005336324.png?f=fpa)
:strip_exif()/i/2005307400.jpeg?f=fpa)
:strip_exif()/i/2005286214.jpeg?f=fpa)
:strip_exif()/i/2005191018.jpeg?f=fpa)
/i/2005108500.png?f=fpa)
/i/2005018320.png?f=fpa)
/i/2004847438.png?f=fpa)
:strip_exif()/i/2004714976.jpeg?f=fpa)
:strip_icc():strip_exif()/u/31472/Vader2.jpg?f=community)
:strip_icc():strip_exif()/u/75667/crop621790ae3049f_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/437469/crop5826cadd562f6_cropped.jpeg?f=community)
/u/945/motorola_mpx300_3.GIF?f=community)