AMD ontwikkelt technieken voor het stapelen van dram en sram op processors met through-silicon-via-kanaaltjes voor de verbindingen tussen de die's. De techniek voor 3d-stacking moet compenseren voor het feit dat de Wet van Moore ten einde is.
Dat AMD bezig is met 3d-stacking van processorlagen maakte general manager Forrest Norrod volgens Tom's Hardware bekend tijdens de Rice Oil and Gas HPC-conferentie. Fabrikanten stapelen al chiplagen, maar dan gaat het om package-on-packagetechnologie waarbij de bovenste geheugenlagen met standaard-bga-connecties verbonden zijn. Dit maakt efficiënt gebruik van de ruimte mogelijk, maar levert niet veel snelheidswinst op.
Volgens Norrod levert het verkleinen van chipstructuren geen frequentieverbeteringen meer op. "Met de volgende node, als we geen bijzondere dingen doen, krijgen we minder frequentie", zegt hij zelfs. Traditiegetrouw gaat het overstappen op kleinere productieprocedé's gepaard met zowel een lager verbruik als hogere kloksnelheden. Dit uitvloeisel van de Wet van Moore staat echter onder druk.
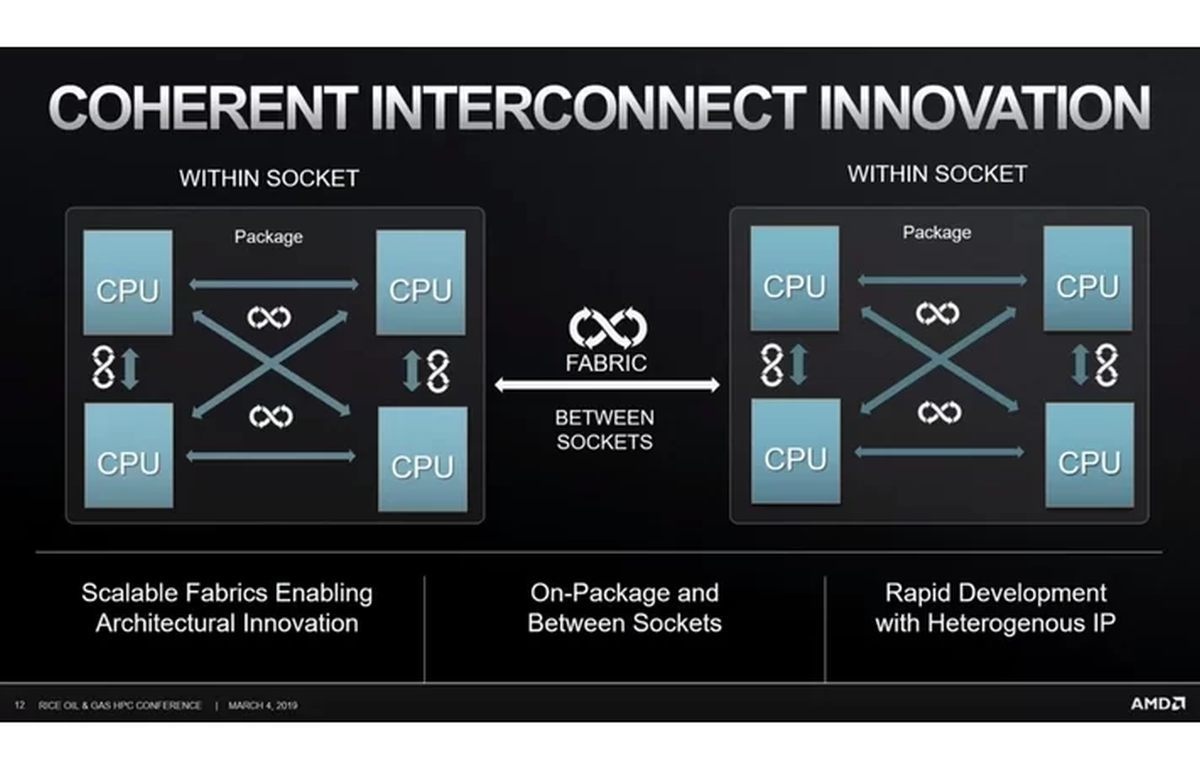
AMD wil daarom gestapelde dies met elkaar verbinden met through-silicon-via's. Dit zijn microkanaaltjes voor snelle dataverbindingen tussen de lagen. Intel werkt aan vergelijkbare technieken die het vorig jaar presenteerde onder de naam Foveros. Intel gebruikt de technieken onder andere om chiponderdelen gemaakt met verschillende productieprocedés met elkaar te combineren, zoals een 14nm-i/o-die met een 10nm-core-die. Ook AMD werkt eraan om zijn processors modulair te maken. Het bedrijf bouwt chiplets op door onderdelen te verbinden met zijn CCIX- Gen-Z-interconnects.







:strip_icc():strip_exif()/i/2002421862.jpeg?f=fpa_thumb)
/i/1240844012.png?f=fpa)
/i/2001665377.png?f=fpa)
/i/2001393753.png?f=fpa)
:strip_exif()/i/2002158313.jpeg?f=fpa)
/u/27299/hoofd.png?f=community)
:strip_exif()/u/28263/Frieschevlag70x70.gif?f=community)
:strip_icc():strip_exif()/u/5677/crop60a67856c31dd_cropped.jpg?f=community)
/u/683924/crop6494a6b36612d_cropped.png?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_icc():strip_exif()/u/413995/crop5daf4ad59bbb8.jpeg?f=community)
:strip_icc():strip_exif()/u/412306/crop5b6bf995b8b39_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/109168/crop5c6ad3dc9bc0f_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/895361/crop5c8e9e5578153_cropped.jpeg?f=community)
/u/186071/crop58bc21e8285fa.png?f=community)
:strip_icc():strip_exif()/u/405084/ESI.jpg?f=community)