
Twee onderzoeksgroepen van het Massachusetts Institute of Technology hebben technologie ontwikkeld om een van de beperkende factoren in rekenkracht, de communicatie tussen processor en geheugen, te verwijderen.
De eerste toepassing richt zich op klassieke computerarchitecturen en dan met name op de processors zelf. Om te kunnen rekenen aan data heeft een processorcore zowel instructies als data nodig en moet de verwerkte data weer worden weggeschreven. In het verleden hadden processors geen caches en moesten instructies en data uit het werkgeheugen worden gehaald maar naarmate kloksnelheden omhoog gingen, kon data niet snel genoeg worden aangevoerd uit het ram. De oplossing was om caches, of kleine stukjes geheugen, dichtbij de rekenkernen in de processor in te bouwen. Die caches bestaan niet uit dram, maar veel sneller, en duurder, sram en worden in kilobytes of megabytes gemeten in plaats van gigabytes zoals bij werkgeheugen.
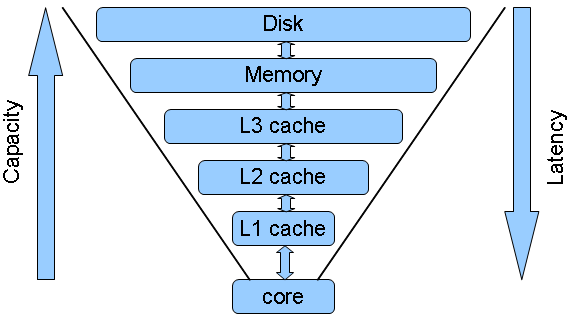
Processorontwerpers hebben de afgelopen jaren steeds meer cachegeheugen in processors ingebouwd en inmiddels hebben processors drie lagen of levels cache, die afhankelijk van de laag steeds groter maar ook steeds trager worden. Het L1-cache is het snelste en zit het dichtst tegen te cores aan, zowel letterlijk als figuurlijk. Dat geheugen is echter vrij beperkt qua capaciteit en wordt alleen ingezet voor instructies en data die direct gebruikt moeten worden. Het L2-cache is groter maar iets trager en sinds enkele generaties hebben consumentenprocessors ook L3-cache, dat flink groter is, maar ook weer trager. Bij processors met meer dan één core zijn de L1-caches opgedeeld in een instructie- en datacache en heeft elke core zijn eigen L1-cache. Ook heeft elke core zijn eigen L2-cache, dat niet is opgedeeld in data- en instructiecaches. Het L3-cache ten slotte, wordt gedeeld door de verschillende cores.
De grootte van de verschillende caches kan worden aangepast aan de toepassingen waarvoor de processor ontworpen is. Zo hebben serverprocessors grote L3-caches, maar zouden sommige werklasten profiteren van grotere L2-caches of juist van nog grotere L3-caches, bijvoorbeeld voor multithreaded toepassingen, aangezien het L3-cache gedeeld wordt. Een groep onderzoekers van het Massachusetts Institute of Technology heeft software ontwikkeld waarmee gesimuleerd kan worden hoe de cachehiërarchie geoptimaliseerd kan worden voor toepassingen. Vooralsnog bestaat de techniek alleen als simulatie, maar het zou gebruikt kunnen worden om processorontwerpen te optimaliseren.

In de simulaties die de MIT-onderzoekers uitvoerden konden ze een chip met 36 cores simuleren. De prestaties van die chip namen met twintig tot dertig procent toe met geoptimaliseerde cache-architecturen ten opzichte van standaardprocessorontwerpen. Bovendien nam het energieverbruik met dertig tot vijfentachtig procent af. Dat komt omdat de cores enerzijds minder kloktikken hoeven te wachten op data van de caches, maar ook omdat de data efficiënter uit de caches kan worden gehaald. Door relevante data namelijk in caches dichter bij de cores die de data nodig hebben op te slaan, kunnen latencies omlaag.
De onderzoekers hebben een algoritme ontwikkeld dat ze Jenga noemen. Jenga zet latencies tegen cache-grootte voor applicaties af en berekent paden over het oppervlak van die verhouding die de minste latency opleveren. Door slechts samples van de curve of het oppervlak van de functie te nemen in plaats van het helemaal door te rekenen, kan Jenga heel snel de optimale latency-paden berekenen en de cachetoewijzingen elke 100ms verversen. Om de latency bij wegschrijven van data te minimaliseren berekent Jenga bovendien de optimale locaties om data weg te schrijven, zodat ook daar geen bottlenecks ontstaan.
/i/2001566885.png?f=imagenormal)
:strip_icc():strip_exif()/i/2001550947.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001450379.jpeg?f=fpa_thumb)
:strip_icc():strip_exif()/i/2001385603.jpeg?f=fpa_thumb)
/i/2003162792.png?f=fpa)
/i/1297430422.png?f=fpa)
/i/1235034622.png?f=fpa)
/i/1160648189.png?f=fpa)
/i/1383492957.png?f=fpa)
/i/2000627474.png?f=fpa)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/317237/crop56bd78333e0b1_cropped.png?f=community)
:strip_icc():strip_exif()/u/26427/YyRIk.jpg?f=community)
:strip_exif()/u/129150/crop5f45153e440b9_cropped.gif?f=community)
:strip_icc():strip_exif()/u/192015/crop609667eb665d7_cropped.jpg?f=community)