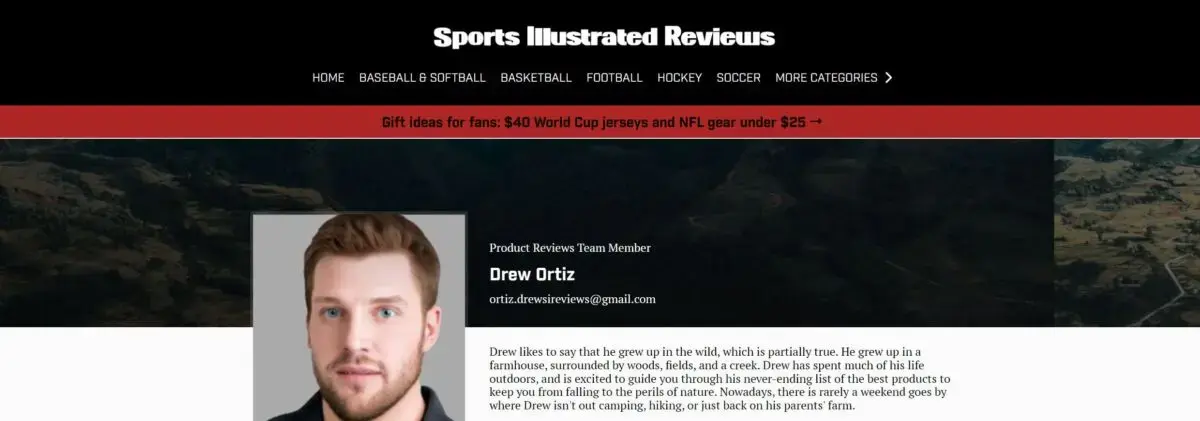
Sommige 'redacteuren' die content zouden hebben gepubliceerd op de website van Sports Illustrated bestonden niet echt. Dat meldt de uitgeverij achter de website na een ontdekking van Futurism. De profielfoto’s van deze auteurs waren gegenereerd door kunstmatige intelligentie.
De redactie van Futurism merkte op dat bepaalde redacteuren van Sports Illustrated niet terug te vinden zijn op sociale media en dat er ook nergens anders op internet werk van de schrijvers terug te vinden was. De redactie ontdekte bovendien dat de profielfoto's van sommige redacteuren te koop werden aangeboden op een website waar AI-profielfoto’s verkocht worden.
Futurism sprak ook met een anonieme bron die bekend is met de zaak. Die stelde dat er ‘veel’ valse auteurs op de website van Sports Illustrated terug te vinden zijn. Volgens een tweede bron zou sommige content op die website ook door kunstmatige intelligentie gegenereerd zijn. Futurism vermoedt ook dat er gebruik is gemaakt van kunstmatige intelligentie en verwijst naar een bepaalde tekst over volleybal waarin te lezen stond dat de sport soms moeilijk te beoefenen is, 'zeker als je geen bal hebt om mee te oefenen'.
Arena Group, de uitgever achter Sports Illustrated, vertelde aan CNN dat de desbetreffende artikelen geschreven zijn door werknemers van een derde partij: AdVon Commerce. Sommige auteurs van AdVon Commerce hebben volgens Arena Group een pseudoniem gebruikt om hun eigen privacy te kunnen waarborgen, een praktijk die Arena Group naar verluidt niet toestaat. De uitgever heeft daarom besloten om al deze artikelen te verwijderen. De artikelen zijn volgens Arena Group wel geschreven en gecontroleerd door mensen. De vakbond van Sports Illustrated heeft zich ondertussen ook uitgesproken over de kwestie. De bond betreurt het geassocieerd te worden met kunstmatige intelligentie en vindt dat de praktijken van AdVon indruisen tegen de journalistieke principes van de bond.
Update, 11.45 uur: inleiding aangepast. Die luidde eerst als volgt: ‘Er is content op de website van Sports Illustrated verschenen waarbij foto's van redacteuren door AI zijn gegenereerd en er een pseudoniem is gebruikt. De uitgever achter de website heeft de artikelen verwijderd, maar beweert dat de teksten wel door mensen zijn geschreven.’ Ook een passage over het vermoedelijke gebruik van AI toegevoegd aan de broodtekst.

:strip_exif()/i/2007590628.jpeg?f=fpa)
:strip_exif()/i/2005682890.jpeg?f=fpa)
:strip_exif()/i/2006076688.jpeg?f=fpa)
:strip_exif()/i/2006018352.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_icc():strip_exif()/u/178804/crop5c0f9b7d77913.jpeg?f=community)
:strip_icc():strip_exif()/u/88719/crop624ccd84437db_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/48297/diamond-2.jpg?f=community)
:strip_icc():strip_exif()/u/343266/zwaard.jpg?f=community)
/u/383195/crop5e1cb535ad912.png?f=community)
:strip_icc():strip_exif()/u/262333/crop55e7812829401.jpeg?f=community)
:strip_icc():strip_exif()/u/98843/tmpgeel601.jpg?f=community)
/u/88794/dj_henk4b.png?f=community)
:strip_icc():strip_exif()/u/789283/crop65b0dfe4af024_cropped.jpg?f=community)
/u/102469/crop60633f8b439f1_cropped.png?f=community)
:strip_icc():strip_exif()/u/25528/crop6262b474a9363_cropped.jpg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
/u/366944/Mondays2.JPG?f=community)
/u/151149/crop5fde11d32f663_cropped.png?f=community)
/u/581347/crop64beea7e7f624_cropped.png?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/580143/crop57d5827ebf8db_cropped.jpeg?f=community)
/u/678946/crop6516cce7d5a19_cropped.png?f=community)
/u/111174/sachiel-small.png?f=community)
:strip_icc():strip_exif()/u/249917/jaapschaap.jpg?f=community)
:strip_icc():strip_exif()/u/122141/ic.tweakimg.net2.jpg?f=community)
:strip_icc():strip_exif()/u/452253/crop6432e4afa5c59_cropped.jpg?f=community)
/u/153650/2women60x60a.JPG?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/142848/crop631b73f49acc6_cropped.png?f=community)
:strip_icc():strip_exif()/u/57655/SuperTeamLogo.jpg?f=community)
:strip_icc():strip_exif()/u/335350/crop61a63ee1f224f.jpg?f=community)
:strip_exif()/u/591794/crop61a251d10f7b3.gif?f=community)
:strip_icc():strip_exif()/u/637339/crop633ae976c5979_cropped.jpg?f=community)
/u/314906/crop68a5aa8bdd674_cropped.png?f=community)
{kind=link}