OpenAI heeft ChatGPT Plus naar het zich laat aanzien een update gegeven, waardoor het pdf's kan analyseren. Ook zitten alle tools nu ingebouwd, waardoor klanten niet meer hoeven te wisselen in de interface om een tool te gebruiken.
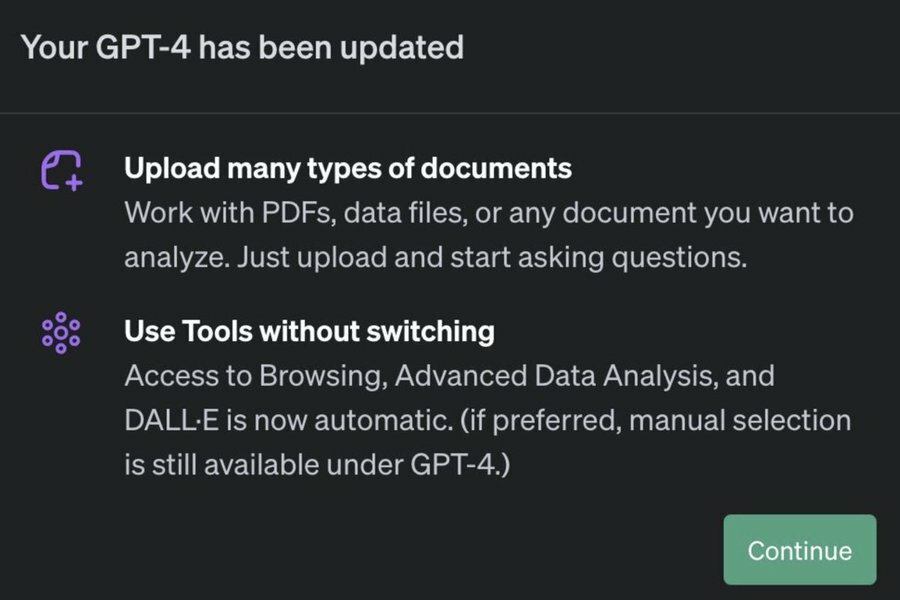
OpenAI lijkt de update voor sommige gebruikers al live te hebben gezet. Niet alle klanten hebben toegang tot de nieuwe versie. Ook is er nog geen aankondiging op de site van OpenAI zelf. Met de update kan ChatGPT pdf's analyseren. Die kunnen klanten uploaden via de chatbox van de dienst.
Daarnaast is het mogelijk geworden om afbeeldingen die klanten uploaden aan te passen. Een klant laat in een demo zien dat ChatGPT Plus de prompt 'make an image like this dog but then running' begrijpt en op basis van de foto die de klant had geüpload Dall-E een afbeelding laat genereren. Dall-E 3 zit al sinds eerder deze maand in ChatGPT. De nieuwe functies vereisen het betaalde abonnement ChatGPT Plus.

:strip_exif()/i/2005545080.jpeg?f=fpa)
/i/2005490828.png?f=fpa)
/i/2006228326.webp?f=fpa)
:strip_icc():strip_exif()/u/432714/crop6287e94322cf6_cropped.jpg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/262645/Waldorf.jpg?f=community)
/u/251602/crop5d47e8d90f819_cropped.png?f=community)
/u/93853/lostworld_thumb_small.JPG?f=community)
/u/24735/crop6112615003fcf_cropped.png?f=community)
/u/155722/Looneytunes.png?f=community)
:strip_icc():strip_exif()/u/75667/crop621790ae3049f_cropped.jpg?f=community)
/u/881941/crop5ecc33f4ab8c1_cropped.png?f=community)
/u/357567/crop5dfcfaa04d0e8_cropped.png?f=community)
:strip_exif()/u/57096/crop64cbdcb3776f4_cropped.gif?f=community)
/u/111174/sachiel-small.png?f=community)
/u/10064/leuk_he.png?f=community)
/u/153650/2women60x60a.JPG?f=community)
:strip_icc():strip_exif()/u/621125/crop65cd0fde312bc_cropped.jpg?f=community)
/u/28892/flo.png?f=community)
:strip_icc():strip_exif()/u/63255/crop62861790abf81_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/480597/crop68b03d247d9ac_cropped.jpg?f=community)
/u/142011/crop65b383c6c6c2f_cropped.png?f=community)
:strip_icc():strip_exif()/u/403133/crop55f6a82e900d9_cropped.jpeg?f=community)
:strip_exif()/u/109857/ico2.gif?f=community)
:strip_exif()/u/1009013/crop5c88cd129b2df_cropped.gif?f=community)
:strip_exif()/u/300751/crop5df8fe05b9775_cropped.gif?f=community)