Chatbot ChatGPT van OpenAI kreeg in juni elf procent minder bezoekers dan in mei, zegt analist Justin Post van Bank of America. Het zou voor het eerst zijn dat het bezoek aan de chatbot maand op maand terugloopt.
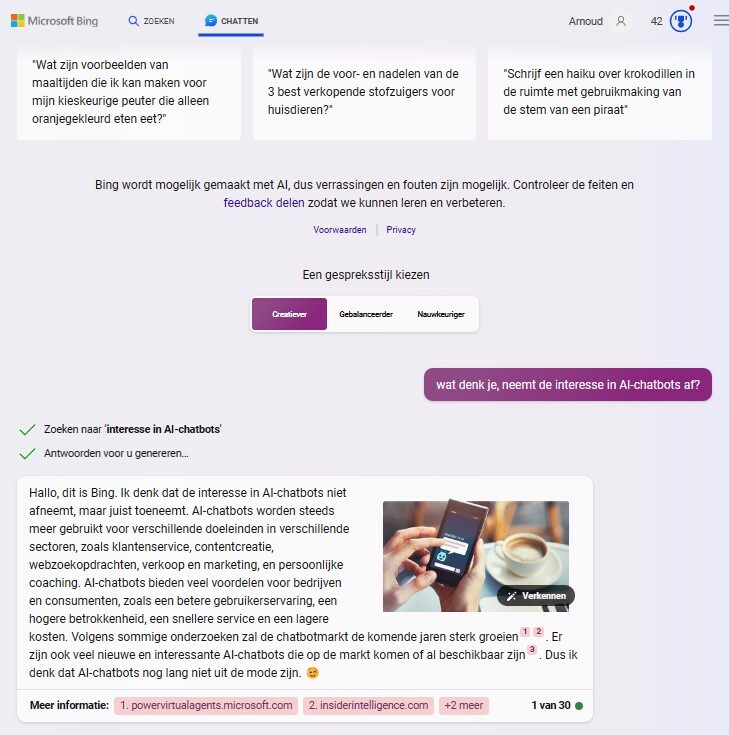
Post schat volgens CNBC dat ChatGPT ongeveer 51 miljoen unieke bezoekers had in juni, elf procent minder dan in de maand ervoor. Post noemt geen oorzaak van de daling, maar merkt op dat het erop lijkt dat ChatGPT voorlopig geen geduchte concurrent zal worden voor de Google-zoekmachine, die naar schatting vijftig keer zoveel bezoekers heeft. Ook Similarweb meldde al een daling van bezoekers bij ChatGPT.
Het aantal downloads van de apps van ChatGPT en Bing is in beide gevallen met 38 procent afgenomen in juni, schat Post. Dat was vooral bij ChatGPT te verwachten, omdat de app in mei is uitgekomen en alleen nog voor iOS beschikbaar is. OpenAI heeft niet gereageerd op de cijfers van de analist.

:strip_exif()/i/2006076688.jpeg?f=fpa)
:strip_exif()/i/2005545080.jpeg?f=fpa)
:strip_exif()/i/2005547492.jpeg?f=fpa)
:strip_exif()/i/2004677808.jpeg?f=fpa)
:strip_exif()/i/2005763778.jpeg?f=fpa)
:strip_exif()/u/865/bj.gif?f=community)
:strip_icc():strip_exif()/u/310341/invo.jpg?f=community)
:strip_icc():strip_exif()/u/1772618/crop62b1ff9fb4126_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
:strip_icc():strip_exif()/u/204061/crop591d528256d44.jpeg?f=community)
:strip_exif()/u/119419/candc-60px.gif?f=community)
:strip_icc():strip_exif()/u/40077/cartman.jpg?f=community)
:strip_icc():strip_exif()/u/745575/crop5de1181b59fc4_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/22888/bee-1-Photo-P-Perry2-70x70.jpg?f=community)
:strip_icc():strip_exif()/u/19522/crop6124d729ee8a5_cropped.jpg?f=community)
:strip_exif()/u/1417624/crop5ef9d1ffc9c03_cropped.gif?f=community)
:strip_icc():strip_exif()/u/90301/crop57d02ccab5f24.jpeg?f=community)
/u/151149/crop5fde11d32f663_cropped.png?f=community)
:strip_icc():strip_exif()/u/299039/dv3.jpg?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/411101/crop636bd3ebad62b_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/76569/garfield14.jpg?f=community)
/u/28892/flo.png?f=community)
:strip_icc():strip_exif()/u/22588/472892.jpg?f=community)
/u/30346/crop6571ad31b4cbc_cropped.png?f=community)
/u/899747/crop63da6c85c8086_cropped.png?f=community)
:strip_icc():strip_exif()/u/63255/crop62861790abf81_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/23091/cyberspin.jpg?f=community)
/u/308442/DRUNKEN%2520SAILOR%2520forum.JPG?f=community)
:strip_icc():strip_exif()/u/480597/crop68b03d247d9ac_cropped.jpg?f=community)
/u/271228/crop66d5c43884a5a_cropped.png?f=community)
/u/11917/cheshirecat.png?f=community)
:strip_icc():strip_exif()/u/320289/crop59885e9c557f6_cropped.jpeg?f=community)
/u/142011/crop65b383c6c6c2f_cropped.png?f=community)
:strip_icc():strip_exif()/u/1943882/crop64ae90d489d0f_cropped.jpg?f=community)
:strip_exif()/u/28986/javaone6666.gif?f=community)
:strip_icc():strip_exif()/u/253641/crop686f9cec6f8b1_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/327784/02723_vanishingbridge_60x60.jpg?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
/u/99142/crop62758e978b3e3_cropped.png?f=community)